基于全连接网络的实时真假运动判断方法
文献发布时间:2023-06-19 11:11:32
技术领域
本发明涉及数据识别技术领域,特别是涉及基于全连接网络的实时真假运动判断方法。
背景技术
随着国家和社会对中小学生的体质的重视,以及人工智能的快速发展,那么人工智能进入体育领域成为必然。目前的运动是否该运动计算方法大致。
1、传统图像差帧法
通过摄像头传入的图像与上一帧传入的图像进行差异比较,有差异的地方就是运动的部位。
缺点:是成本高、性能差、对环境要求高、不能判断是否真正的在做该运动。
2、深度学习分类法(classification)
通过摄像头传入的图像分类出人体运动的阶段,各级阶段的循环次数计算运动是否该运动。
常用的准确度高模型有VGG,MobileNet,ResNet等。
缺点:是成本高、性能差。
3、深度学习语义分割法(Semantic segmentation)
通过摄像头传入的图像分类出属于人体的像素和属于背景的像素,通过人体像素的变化进行判断。常用的准确度高模型有unet,deeplab等。
缺点:是成本高、性能差、对环境要求高、不能判断是否真正的在做该运动。
4、深度学习物体检测法(Object detection)
通过摄像头传入的图像框出人所在的位置,根据外接框的变化进行运动判断。常用的高性能模型有SSD,YOLO等。
缺点:不能判断是否真正的在做该运动。
发明内容
本发明的目的在于提供基于全连接网络的实时真假运动判断方法
为实现上述目的,本发明提供如下技术方案:
基于全连接网络的实时真假运动判断方法,包括模型训练阶段:
获取数据集:将运动视频以单帧图像的形式输入人体关键点检测模型中,输出人体的关键点数据,形成数据集样本;
以当前运动为正样本,采用过采样的方式采样,其他运动为负样本采用欠采样的方式采样,形成采样样本;
从采样样本中选取训练集,输入到全连接神经网络,最后计算Loss并更新;
还包括实施判断阶段:将待检测数据作为模型输入,输出判断结果。
优选的,从人体关键点检测模型中输出的数据集进行归一化处理,归一化的结果为关键点的X/图像的宽,关键点的Y轴/图像的高。
优选的,训练机在输入全连接神经网络之前做数据增强处理,数据增强处理包括数据平移增强、数据缩放增强以及数据左右翻转增强。
优选的,将所有正样本的随机25%作为正样本验证集,将所有负样本的随机25%作为负样本验证集,其余的作为训练集。
优选的,计算Loss采用二分类交叉熵损失函数:
更新包括全连接网络的反向传播和梯度下降过程:
δ
与现有技术相比,本发明的有益效果是:本发明基于人体关键点检测模型,利用人体关键点数据组建模型,经拟合后的模型,以识别视频中人体运动种类以及是否该运动。
另外,在数据集采样上,正样本采用过采样,负样本采用欠采样的方式,解决了数据不平衡的问题,并用于该领域,极大提高了准确率。
附图说明
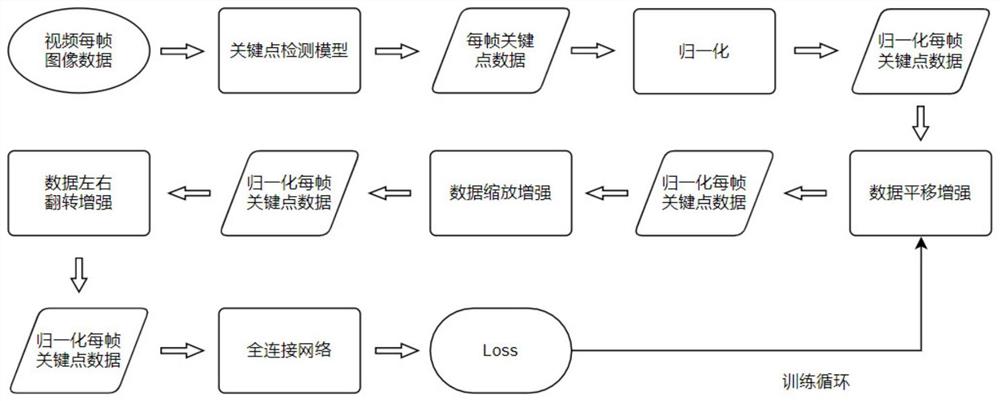
图1为本发明实施例模型训练方法的流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本实施例是建立在人体关键点检测模型之上的,将视频的每一帧图像输入到人体关键点模型(如PoseNet,OpenPose,Pose Proposal Networks)中,检测出人体关键点,把关键点保存成数值数据,通过该数据进行运动真假判断。
具体的,基于全连接网络的实时真假运动判断方法,先进行判断模型的训练,上述的模型(PoseNet,OpenPose,Pose Proposal Networks)输出便是模型训练的数据集来源。模型训练包括如下步骤:
数据集采集与处理
(1)将收集来的20类单人运动视频,进行有效部分截取分类。
20类单人运动:
1.跳绳、2.散步、3.跳舞、4.高抬腿、5.波比跳、6.引体向上、7.平板支撑、8.仰卧起坐、9.立位体前屈、10.坐位体前屈、11.开合跳、12.非标准跳绳、13.非标准高抬腿、14.非标准波比跳、15.非标准引体向上、16.非标准平板支撑、17.非标准仰卧起坐、18.非标准立位体前屈、19.非标准坐位体前屈、20.非标准开合跳。
有效部分截取分类的方法是将视频中的杂质(非该运动)的部分删除,最后将不同的运动视频进行各自存放。
(2)读取识破的每一帧图像通过上述的人体关键点检测模型检测出人体的关键点数据集保存成文本文件当中并打乱;
打乱数据集的作用:对于那种对随机性比较敏感的模型,典型的就是NN,打乱数据很重要。对于那种对随机性不太敏感的模型,理论上说可以不打乱。但敏感与否也跟数据量级,复杂度,算法内部计算机制都有关,目前并没有一个经纬分明的算法随机度敏感度列表。既然打乱数据并不会得到一个更差的结果,一般推荐的做法就是打乱全量数据;
(3)数据归一化
归一化的结果是关键点的x轴/图像的宽,关键点的y轴/图像的高;
(4)保留当前运动的文本文件为正样本,其他运动的文本文件为负样本;
(5)正样本采用过采样,负样本采用欠采样(解决数据集不平衡问题)。
过采样:会增加训练集中少数群体成员的是否该运动。过采样的优点是不会保留原始训练集中的信息,因为会保留少数和多数类别的所有观察结果。另一方面,它容易过度拟合;
欠采样:与过采样相反,旨在减少多数样本的是否该运动来平衡类分布。由于它正在从原始数据集中删除观察结果,因此可能会丢弃有用的信息。
正样本采用过采样:所有正样本全都采用。负样本采用欠采样:在所有负样本当中随机采用和正样本差不多的是否该运动。
此处值得一提的是,设定如上的采样方式,是为了充分符合本发明的目的即运动识别;在运动识别中,是通过单一图片去判断运动,难很大,因为各运动中的动作可能是相似度很大的;传统采样的方式,不管是过采样还是欠采样,都很难达到预估的准确度;而采样上述的采样方式,实现了数据训练集的科学性平衡,对最终结果的准确度,做出了突出的贡献。
(6)数据集的分割。
将所有正样本的随机25%数据集作为正样本验证集,将所有负样本的随机25%数据集作为负样本验证集,其他都作为训练集。
训练集:用于模型拟合的数据样本。在训练过程中对训练误差进行梯度下降,进行学习,可训练的权重参数。
验证集:是模型训练过程中单独留出的样本集,它可以用于调整模型的超参数和用于对模型的能力进行初步评估。
验证集可以用在训练的过程中,一般在训练时,几个epoch结束后跑一次验证集看看效果。这样做的第一个好处是,可以及时发现模型或者参数的问题,比如模型在验证集上发散、出现很奇怪的结果(如无穷大)、mAP不增长或者增长很慢等等情况,这时可以及时终止训练,重新调参或者调整模型,而不需要等到训练结束。另外一个好处是验证模型的泛化能力,如果在验证集上的效果比训练集上差很多,就该考虑模型是否过拟合了。同时,还可以通过验证集对比不同的模型。在一般的神经网络中,我们用验证数据集去寻找最优的网络深度,或者决定反向传播算法的停止点或者在神经网络中选择隐藏层神经元的是否该运动。
2、模型的训练
a、取出打乱的训练集当中的数据集作为网络输入。
b、采用数据增强(Data Augmentation)平移,缩放,左右翻转。
计算机视觉中的图像增强,是人为的视觉不变性(语义不变)引入了先验知识。数据增强也基本上成了提高模型性能的最简单、直接的方法了。数据增强可以带来某种正则化(Regularization)作用的,这样就可以减小模型的结构风险。数据增强能否提高模型的鲁棒性。数据增强在某方面使得模型更集中地观测那些数据总的普遍模式,而消除了某些和普遍模式无关的数据。
c、全连接分类。
将所有数据集做二分类提供全连接神经网络做logistic回归。logistic回归的最后输出激励函数为Sigmoid函数。Sigmoid函数公式定义如下:
d、计算网络输出和标签之后的差异(Loss),反向传播(Back Propagation)给网络进行梯度下降(gradient descent)权值更新。
二分类交叉熵损失函数(Binary Cross Entropy Loss Function)如下:
全连接网络的反向传播(Back Propagation)和梯度下降(gradient descent)的过程如下:
δ
模型训练完成之后,便可将待检测的视频或者图片输入模型中,得出识别结果。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
- 基于全连接网络的实时真假运动判断方法
- 基于长短期记忆网络的实时真假运动判断方法