一种N-乙酰氨基葡萄糖的大肠杆菌工程菌及发酵生产方法
文献发布时间:2023-06-19 11:13:06
技术领域
本申请涉及农业生物技术领域,具体涉及一种N-乙酰氨基葡萄糖的大肠杆菌工程菌及发酵生产方法。
背景技术
氨基葡萄糖是由葡萄糖分子的羟基被氨基所取代后的化合物。通常以N-乙酰基衍生物或N-硫酸酯和N-乙酰-3-O-乳酸醚形式存在于细胞壁结合多糖和动物结缔组织中。工业生产的氨基葡萄糖已被广泛应用于饲料、医药、食品、日化等诸多行业。其中,N-乙酰氨基葡萄糖能够修复人体受损软骨细胞组织,增加关节间的润滑,在医药领域尤其是治疗和预防关节炎方面发挥着重要作用。
目前,我国的N-乙酰氨基葡萄糖多以壳聚糖作为原料,通过水解反应进行生产。这不仅使原料来源受到很大限制,而且会造成体质敏感的人群发生过敏反应等。随着合成生物学的发展,生物合成N-乙酰氨基葡萄糖的方法已经被建立起来。但目前的发酵大多仅利用葡萄糖作为唯一碳源,存在产量低、转化效率低、副产物(乙酸、谷氨酸等)含量较高的缺陷。这不仅造成了因生产成本高而难以产生良好经济效益的工业生产困境,而且副产物的大量产生会使能源严重浪费并进一步造成环境污染。因此,建立一种能够在提升葡萄糖原料的转化率的同时能够将代谢副产物回收进行利用,从而避免能源浪费和环境污染,进而提高N-乙酰氨基葡萄糖的产量的生产策略无疑极具吸引力。
发明内容
为解决现有N-乙酰氨基葡萄糖制备技术中存在的转化效率低、能源浪费等问题,本发明的目的是提供一种产N-乙酰氨基葡萄糖的大肠杆菌工程菌。
本发明的再一目的是提供一种高效发酵生产N-乙酰氨基葡萄糖的方法。
根据本发明的产N-乙酰氨基葡萄糖的大肠杆菌工程菌,所述工程菌为外源表达N-乙酰氨基葡萄糖合成相关基因和混合碳源共利用酶基因的敲除了糖酵解途径和磷酸戊糖途径中关键基因的突变型大肠杆菌,
其中,被敲除的糖酵解途径关键基因为ATP依赖性6-磷酸果糖激酶同工酶1的编码基因
所述N-乙酰氨基葡萄糖合成相关基因为
所述混合碳源共利用酶基因为
根据本发明的构建产N-乙酰氨基葡萄糖的大肠杆菌工程菌的方法,包括以下步骤:
敲除糖酵解途径和磷酸戊糖途径中关键基因,构建突变型大肠杆菌底盘细胞;
导入表达N-乙酰氨基葡萄糖合成相关基因和混合碳源共利用酶基因,
其中,被敲除的糖酵解途径关键基因为ATP依赖性6-磷酸果糖激酶同工酶1的编码基因
所述N-乙酰氨基葡萄糖合成相关基因为
所述混合碳源共利用酶基因为
根据本发明的构建产N-乙酰氨基葡萄糖的大肠杆菌工程菌的方法,其中,将所述
根据本发明的构建产N-乙酰氨基葡萄糖的大肠杆菌工程菌的方法,其中,所述启动子均为P
本发明另一个目的是提供一种发酵生产N-乙酰氨基葡萄糖的方法,包括如下步骤:摇瓶发酵上述的产N-乙酰氨基葡萄糖的大肠杆菌工程菌株,得到N-乙酰氨基葡萄糖。
根据本发明的发酵生产N-乙酰氨基葡萄糖的方法,其中,利用混合碳源培养基进行摇瓶发酵。
根据本发明的发酵生产N-乙酰氨基葡萄糖的方法,其中,发酵培养基的配方为:磷酸氢二钠 6.78 g、磷酸二氢钾 3 g、氯化钠 1.5 g、氯化铵1 g、葡萄糖10 g、氯化钙 0.011g、七水合硫酸镁 0.493 g、5 g甘油、酵母提取物0.5 g、蛋白胨1 g,以水作为溶剂定容至1L。
根据本发明的发酵生产N-乙酰氨基葡萄糖的方法,其中,所述发酵培养基中添加氨苄抗生素终浓度为50 µg/mL。
根据本发明的发酵生产N-乙酰氨基葡萄糖的方法,其中,所述摇瓶发酵条件为温度37℃,转速200 rpm,发酵108小时。
本申请的技术方案的优点:
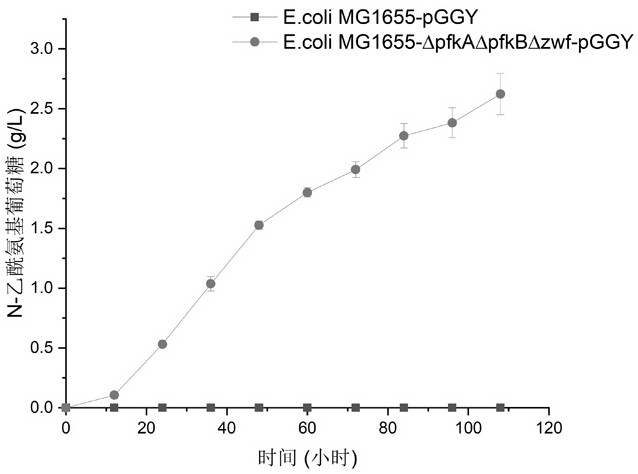
1. 本发明通过截断糖酵解途径和磷酸戊糖途径对N-乙酰氨基葡萄糖合成前体6-磷酸果糖的分流,提高了突变型大肠杆菌底盘细胞中的产物前体供应,再利用游离的高拷贝质粒在底盘细胞内表达了N-乙酰氨基葡萄糖合成途径的关键酶,利用混合碳源培养基发酵生产N-乙酰氨基葡萄糖,N-乙酰氨基葡萄糖的产量达到2.8 g/L。
2. 根据本申请的技术方案,被敲除的糖酵解途径关键基因为ATP依赖性6-磷酸果糖激酶同工酶1的编码基因
3. 根据本申请的技术方案,为了解决上述问题,在上述突变型大肠杆菌底盘细胞中表达特异性的述N-乙酰氨基葡萄糖合成相关基因、混合碳源共利用酶基因的基因组合,选用的N-乙酰氨基葡萄糖合成相关基因为
通过表达
4. 大肠杆菌发酵的主要副产物是乙酸,而乙酸的积累会严重抑制菌株的生长,且会降低产物的产率(产物量/发酵底物量)。根据本申请的技术方案,并未对乙酸代谢途径进行改造,但是,试验数据表明,本申请的阻断糖酵解和磷酸戊糖途径的工程菌株的乙酸产量显著降低,并在发酵后期被重吸收,因此在发酵结束时基本没有乙酸的积累。一方面,本申请的工程菌株的乙酸产量降低,可减少乙酸对菌体生长的影响,并提高产物产率。另一方面,乙酸在大肠杆菌中通过乙酰辅酶A合成酶(ACS)催化被重吸收后可生成乙酰辅酶A,可为葡萄糖胺6-磷酸N-乙酰转移酶提供用于合成N-乙酰基-D-葡糖胺6-磷酸的乙酰基,提高了产物合成的能力。
附图说明
图1显示大肠杆菌野生株和本申请构建的工程菌株产N-乙酰氨基葡萄糖的结果;
图2显示大肠杆菌野生株和本申请构建的工程菌株利用甘油的结果;
图3显示大肠杆菌野生株和本申请构建的工程菌株利用葡萄糖的结果;
图4显示大肠杆菌野生株和本申请构建的工程菌株利用自身产生的乙酸的结果;
图5 显示大肠杆菌野生株和本申请构建的工程菌株
图6显示大肠杆菌野生株和本申请构建的工程菌株在对比实施例1混合发酵培养基中产N-乙酰氨基葡萄糖的结果;
图7 显示大肠杆菌野生株和本申请构建的工程菌株在对比实施例2混合发酵培养基中产N-乙酰氨基葡萄糖的结果。
具体实施方式
下述实施例中所使用的实验方法如无特殊说明,均为常规方法。所用的材料、试剂等,如无特殊说明,均可从商业途径得到。
实施例1构建大肠杆菌MG1655-
突变型大肠杆菌底盘细胞为敲除糖酵解途径和磷酸戊糖途径中关键基因的大肠杆菌宿主,被敲除的糖酵解途径关键基因为ATP依赖性6-磷酸果糖激酶同工酶1的编码基因
一、构建大肠杆菌MG1655-∆
将pRed_cas9_recA_poxb300质粒和
1. 构建带有启动子P23119、
根据组成型启动子P23119和
2. 构建带有pfkB基因上下游同源臂的敲除质粒p∆
在
3. 构建大肠杆菌MG1655-∆
将pRed_cas9_recA_poxb300和p
二、构建大肠杆菌MG1655-∆
将
1. 构建带有启动子P23119、
根据组成型启动子P23119和
2. 构建带有
在
2. 构建大肠杆菌MG1655-
将pRed_cas9_recA_poxb300和p
将成功构建的菌株接种于LB液体培养基(卡那霉素50 µg/mL)中,于42℃下200rpm培养16 h,并连续培养5代。将菌体进行梯度稀释至10
三、构建大肠杆菌MG1655-
将
1. 构建带有启动子P23119、
根据组成型启动子P23119和
2.构建带有
在
2. 构建大肠杆菌MG1655- ∆
将pRed_cas9_recA_poxb300和p
表1
实施例2 构建产N-乙酰氨基葡萄糖的大肠杆菌MG1655-
一、构建含N-乙酰氨基葡萄糖合成相关基因的表达质粒pGGY-1
将
扩增获得约1800bp的核苷酸序列如SEQ ID NO:4的谷氨酰胺果糖-6磷酸转氨酶基因
将质粒pGlms-T3使用
二、构建甘油激酶基因高表达质粒pGGY-T3
分别以
三、构建可以同时利用多种碳源进行生长和合成N-乙酰氨基葡萄糖的大肠杆菌MG1655-∆
将pGGY-T3质粒电转导入大肠杆菌MG1655-
实施例3 利用产N-乙酰氨基葡萄糖的大肠杆菌MG1655-
将产N-乙酰氨基葡萄糖的大肠杆菌MG1655-
制备混合碳源发酵培养基:准确称取磷酸氢二钠 6.78 g、磷酸二氢钾 3 g、氯化钠 1.5 g、氯化铵1 g、葡萄糖10 g、氯化钙 0.011 g、七水合硫酸镁 0.493 g、5 g甘油、酵母提取物0.5 g、蛋白胨1 g,以水作为溶剂定容至1 L,115℃高压湿热灭菌灭菌30分钟,得到混合碳源发酵培养基。
将大肠杆菌MG1655-
菌液OD
葡萄糖浓度、甘油浓度、乙酸浓度以及N-乙酰氨基葡萄糖的浓度测定:使用高效液相色谱仪对样品中N-乙酰氨基葡萄糖、甘油、葡萄糖、乙酸同时检测。高效液相色谱仪为岛津20A;色谱柱为AminexHPX-87H Column (300 mm×7.8 mm);流动相:5 mM H
实施例4 产N-乙酰氨基葡萄糖的大肠杆菌MG1655-
将产N-乙酰氨基葡萄糖的大肠杆菌工程菌株MG1655-
制备混合碳源发酵培养基:准确称取磷酸氢二钠 6.78 g、磷酸二氢钾 3 g、氯化钠 1.5 g、氯化铵1 g、葡萄糖10 g、氯化钙 0.011 g、七水合硫酸镁 0.493 g、5 g甘油、酵母提取物0.5 g、蛋白胨1 g,以水作为溶剂定容至1 L,115℃高压湿热灭菌灭菌30分钟,得到混合碳源发酵培养基。
将产N-乙酰氨基葡萄糖的大肠杆菌工程菌MG1655-
对比实施例1
除不含组分“酵母提取物0.5 g、蛋白胨1 g”,并且添加100 mg/L丙酮酸替换外,其与组分与实施例3的混合碳源发酵培养基配方相同。发酵84小时后,N-乙酰氨基葡萄糖产量达到最高值,为0.12 g/L。结果如图6所示。丙酮酸为糖酵解途径下游的代谢中间产物,其添加是为了补充糖酵解和磷酸戊糖途径阻断后菌体生长所需中间代谢产物的不足,然而相比于酵母提取物和蛋白胨,丙酮酸的添加对菌体的生长提升不大,菌体最终未能到达与野生株相同的生物量,N-乙酰氨基葡萄糖产量仅为实施例3的4%。
对比实施例2
除不含组分“酵母提取物0.5 g、蛋白胨1 g”,并且添加“2 g/L柠檬酸”外,其与组分与实施例3的混合碳源发酵培养基配方相同。发酵60小时后,N-乙酰氨基葡萄糖产量达到最高值,为0.033 g/L。结果如图7所示。柠檬酸为三羧酸循环途径中的代谢中间产物,其添加是为了补充糖酵解和磷酸戊糖途径阻断后菌体生长所需中间代谢产物的不足,然而,相比于酵母提取物和蛋白胨,柠檬酸的添加未提高产N-乙酰氨基葡萄糖工程菌株的生长速率和生物总量,N-乙酰氨基葡萄糖的产量为实施例3的1%。
序列表
<110> 中国农业科学院北京畜牧兽医研究所
<120> 一种N-乙酰氨基葡萄糖的大肠杆菌工程菌及发酵生产方法
<160> 8
<170> SIPOSequenceListing 1.0
<210> 1
<211> 963
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 1
atgattaaga aaatcggtgt gttgacaagc ggcggtgatg cgccaggcat gaacgccgca 60
attcgcgggg ttgttcgttc tgcgctgaca gaaggtctgg aagtaatggg tatttatgac 120
ggctatctgg gtctgtatga agaccgtatg gtacagctag accgttacag cgtgtctgac 180
atgatcaacc gtggcggtac gttcctcggt tctgcgcgtt tcccggaatt ccgcgacgag 240
aacatccgcg ccgtggctat cgaaaacctg aaaaaacgtg gtatcgacgc gctggtggtt 300
atcggcggtg acggttccta catgggtgca atgcgtctga ccgaaatggg cttcccgtgc 360
atcggtctgc cgggcactat cgacaacgac atcaaaggca ctgactacac tatcggtttc 420
ttcactgcgc tgagcaccgt tgtagaagcg atcgaccgtc tgcgtgacac ctcttcttct 480
caccagcgta tttccgtggt ggaagtgatg ggccgttatt gtggagatct gacgttggct 540
gcggccattg ccggtggctg tgaattcgtt gtggttccgg aagttgaatt cagccgtgaa 600
gacctggtaa acgaaatcaa agcgggtatc gcgaaaggta aaaaacacgc gatcgtggcg 660
attaccgaac atatgtgtga tgttgacgaa ctggcgcatt tcatcgagaa agaaaccggt 720
cgtgaaaccc gcgcaactgt gctgggccac atccagcgcg gtggttctcc ggtgccttac 780
gaccgtattc tggcttcccg tatgggcgct tacgctatcg atctgctgct ggcaggttac 840
ggcggtcgtt gtgtaggtat ccagaacgaa cagctggttc accacgacat catcgacgct 900
atcgaaaaca tgaagcgtcc gttcaaaggt gactggctgg actgcgcgaa aaaactgtat 960
taa 963
<210> 2
<211> 930
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 2
atggtacgta tctatacgtt gacacttgcg ccctctctcg atagcgcaac aattaccccg 60
caaatttatc ccgaaggaaa actgcgctgt accgcaccgg tgttcgaacc cgggggcggc 120
ggcatcaacg tcgcccgcgc cattgcccat cttggaggca gtgccacagc gatcttcccg 180
gcgggtggcg cgaccggcga acacctggtt tcactgttgg cggatgaaaa tgtccccgtc 240
gctactgtag aagccaaaga ctggacccgg cagaatttac acgtacatgt ggaagcaagc 300
ggtgagcagt atcgttttgt tatgccaggc gcggcattaa atgaagatga gtttcgccag 360
cttgaagagc aagttctgga aattgaatcc ggggccatcc tggtcataag cggaagcctg 420
ccgccaggtg tgaagctgga aaaattaacc caactgattt ccgctgcgca aaaacaaggg 480
atccgctgca tcgtcgacag ttctggcgaa gcgttaagtg cagcactggc aattggtaac 540
atcgagttgg ttaagcctaa ccaaaaagaa ctcagtgcgc tggtgaatcg cgaactcacc 600
cagccggacg atgtccgcaa agccgcgcag gaaatcgtta atagcggcaa ggccaaacgg 660
gttgtcgttt ccctgggtcc acaaggagcg ctgggtgttg atagtgaaaa ctgtattcag 720
gtggtgccac caccggtgaa aagccagagt accgttggcg ctggtgacag catggtcggc 780
gcgatgacac tgaaactggc agaaaatgcc tctcttgaag agatggttcg ttttggcgta 840
gctgcgggga gtgcagccac actcaatcag ggaacacgtc tgtgctccca tgacgatacg 900
caaaaaattt acgcttacct ttcccgctaa 930
<210> 3
<211> 1476
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 3
atggcggtaa cgcaaacagc ccaggcctgt gacctggtca ttttcggcgc gaaaggcgac 60
cttgcgcgtc gtaaattgct gccttccctg tatcaactgg aaaaagccgg tcagctcaac 120
ccggacaccc ggattatcgg cgtagggcgt gctgactggg ataaagcggc atataccaaa 180
gttgtccgcg aggcgctcga aactttcatg aaagaaacca ttgatgaagg tttatgggac 240
accctgagtg cacgtctgga tttttgtaat ctcgatgtca atgacactgc tgcattcagc 300
cgtctcggcg cgatgctgga tcaaaaaaat cgtatcacca ttaactactt tgccatgccg 360
cccagcactt ttggcgcaat ttgcaaaggg cttggcgagg caaaactgaa tgctaaaccg 420
gcacgcgtag tcatggagaa accgctgggg acgtcgctgg cgacctcgca ggaaatcaat 480
gatcaggttg gcgaatactt cgaggagtgc caggtttacc gtatcgacca ctatcttggt 540
aaagaaacgg tgctgaacct gttggcgctg cgttttgcta actccctgtt tgtgaataac 600
tgggacaatc gcaccattga tcatgttgag attaccgtgg cagaagaagt ggggatcgaa 660
gggcgctggg gctattttga taaagccggt cagatgcgcg acatgatcca gaaccacctg 720
ctgcaaattc tttgcatgat tgcgatgtct ccgccgtctg acctgagcgc agacagcatc 780
cgcgatgaaa aagtgaaagt actgaagtct ctgcgccgca tcgaccgctc caacgtacgc 840
gaaaaaaccg tacgcgggca atatactgcg ggcttcgccc agggcaaaaa agtgccggga 900
tatctggaag aagagggcgc gaacaagagc agcaatacag aaactttcgt ggcgatccgc 960
gtcgacattg ataactggcg ctgggccggt gtgccattct acctgcgtac tggtaaacgt 1020
ctgccgacca aatgttctga agtcgtggtc tatttcaaaa cacctgaact gaatctgttt 1080
aaagaatcgt ggcaggatct gccgcagaat aaactgacta tccgtctgca acctgatgaa 1140
ggcgtggata tccaggtact gaataaagtt cctggccttg accacaaaca taacctgcaa 1200
atcaccaagc tggatctgag ctattcagaa acctttaatc agacgcatct ggcggatgcc 1260
tatgaacgtt tgctgctgga aaccatgcgt ggtattcagg cactgtttgt acgtcgcgac 1320
gaagtggaag aagcctggaa atgggtagac tccattactg aggcgtgggc gatggacaat 1380
gatgcgccga aaccgtatca ggccggaacc tggggacccg ttgcctcggt ggcgatgatt 1440
acccgtgatg gtcgttcctg gaatgagttt gagtaa 1476
<210> 4
<211> 1830
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 4
atgtgtggaa ttgttggcgc gatcgcgcaa cgtgatgtag caaaaatcct tcttgaaggt 60
ttacgtcgtc tggaataccg cggatatgac tctgccggtc tggccgttgt tgatgcagaa 120
ggtcatatga cccgcctgcg tcgcctcggt aaagtccaga tgctggcaca ggcagcggaa 180
gaacatcctc tgcatggcgg cactggtatt gctcacactc gctgggcgac ccacggtgaa 240
ccttcagaag tgaatgcgca tccgcatgtt tctgaacaca ttgtggtggt gcataacggc 300
atcatcgaaa accatgaacc gctgcgtgaa gagctaaaag cgcgtggcta taccttcgtt 360
tctgaaaccg acaccgaagt gattgcccat ctggtgaact gggagctgaa acaaggcggg 420
actctgcgtg aggccgttct gcgtgctatc ccgcagctgc gtggtgcgta cggtacagtg 480
atcatggact cccgtcaccc ggataccctg ctggcggcac gttctggtag tccgctggtg 540
attggcctgg ggatgggcga aaactttatc gcttctgacc agctggcgct gttgccggtg 600
acccgtcgct ttatcttcct tgaagagggc gatattgcgg aaatcactcg ccgttcggta 660
aacatcttcg ataaaactgg cgcggaagta aaacgtcagg atatcgaatc caatctgcaa 720
tatgacgcgg gcgataaagg catttaccgt cactacatgc agaaagagat ctacgaacag 780
ccgaacgcga tcaaaaacac ccttaccgga cgcatcagcc acggtcaggt tgatttaagc 840
gagctgggac cgaacgccga cgaactgctg tcgaaggttg agcatattca gatcctcgcc 900
tgtggtactt cttataactc cggtatggtt tcccgctact ggtttgaatc gctagcaggt 960
attccgtgcg acgtcgaaat cgcctctgaa ttccgctatc gcaaatctgc cgtgcgtcgt 1020
aacagcctga tgatcacctt gtcacagtct ggcgaaaccg cggataccct ggctggcctg 1080
cgtctgtcga aagagctggg ttaccttggt tcactggcaa tctgtaacgt tccgggttct 1140
tctctggtgc gcgaatccgt tctggcgcta atgaccaacg cgggtacaga aatcggcgtg 1200
gcatccacta aagcattcac cactcagtta actgtgctgt tgatgctggt ggcgaagctg 1260
tctcgcctga aaggtctgga tgcctccatt gaacatgaca tcgtgcatgg tctgcaggcg 1320
ctgccgagcc gtattgagca gatgctgcct caggacaaac gcattgaagc gctggcagaa 1380
gatttctctg acaaacatca cgcgctgttc ctgggccgtg gcgatcagta cccaatcgcg 1440
ctggaaggcg cattgaagtt gaaagagatc tcttacattc acgctgaagc ctacgctgct 1500
ggcgaactga aacacggtcc gctggcgcta attgatgccg atatgccggt tattgttgtt 1560
gcaccgaaca acggtttgct ggaaaaactg aaatccaaca ttgaagaagt tcgcgcgcgt 1620
ggcggtcagt tgtatgtctt cgccgatcag gatgcgggtt ttgtaagtag cgataacatg 1680
cacatcatcg agatgccgca tgtggaagag gtgattgcac cgatcttcta caccgttccg 1740
ctgcagctgc tggcttacca tgtcgcgctg atcaaaggca ccgacgttga ccagccgcgt 1800
aacctggcaa aatcggttac ggttgagtaa 1830
<210> 5
<211> 567
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 5
atgtacgagc gttatgcagg tttaattttt gatatggatg gcacaatcct ggatacggag 60
cctacgcacc gtaaagcgtg gcgcgaagta ttagggcact acggtcttca gtacgatatt 120
caggcgatga ttgcgcttaa tggatcgccc acctggcgta ttgctcaggc aattattgag 180
ctgaatcagg ccgatctcga cccgcatgcg ttagcgcgtg aaaaaacaga agcagtaaga 240
agtatgctgc tggatagcgt cgaaccgctt cctcttgttg atgtggtgaa aagttggcat 300
ggtcgtcgcc caatggctgt aggaacgggg agtgaaagcg ccatcgctga ggcattgctg 360
gcgcacctgg gattacgcca ttattttgac gccgtcgtcg ctgccgatca cgtcaaacac 420
cataaacccg cgccagacac atttttgttg tgcgcgcagc gtatgggcgt gcaaccgacg 480
cagtgtgtgg tctttgaaga tgccgatttc ggtattcagg cggcccgtgc agcaggcatg 540
gacgccgtgg atgttcgctt gctgtga 567
<210> 6
<211> 498
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 6
atgagccata tttttgatgc gagcgtgctg gcgccgcata ttccgagcaa tctgccggat 60
aactttaaag tgcgcccgct ggcgaaagat gattttagca aaggctatgt ggatctgctg 120
agccagctga ccagcgtggg taatctggat caggaagcgt ttgaaaaacg ctttgaagcg 180
atgcgcacca gcgtgccgaa ttatcatatt gtggtgattg aagacagcaa cagccagaaa 240
gtggtggcga gcgcgtcatt agtggtggaa atgaaattta ttcacggcgc gggcagccgc 300
ggccgcgttg aagatgttgt tgttgatacc gaaatgcgcc gccagaaact gggcgcggtt 360
ttattaaaaa ccctggtgag cctgggcaaa agcctgggcg tttataaaat tagcctggaa 420
tgcgtgccgg aactgctgcc gttttatagc cagtttggct ttgtggatga tggcaacttt 480
atgacccagc gcttttaa 498
<210> 7
<211> 1866
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 7
ttaagcagtg tccttaagcc agccctttgc ctttgcaatg gcattttccc acaatctcca 60
ttcctttctt ctgacctcgt cgctcaatgt ggccttgaag tccaaagaag tgttccctgc 120
agccaagtac atcttgttac cctcaagaat ggcctcggta cattccttca aggaacccca 180
aattctatct tccttaggga caccaaaacc ggcagcaatg gcagctccca gtgcagtaca 240
ttcagggttg atggaacgtc taacagtgac acatggaccc aaaatatcag cttggatctg 300
catcatctcg tctgatttgg acatacctcc gtccacggca agaactgaca gagggttgtg 360
gccagtggcc ttggatgatt cctccaaaaa gtcagcagaa gctcctgcat cgctgatcat 420
ggccttcaaa atggctctag tttggaaaca gacaccttcc aaagcagctc tagcaatatg 480
agaagctgag gtgtattggg tcagaccgaa aatggttcct ctggagttgg aatcccagta 540
aggggcaaac aatcctgaaa atgctggaac aaataccaca cctccagagt tgtcaacttg 600
agaagccaat ggtccgacgt cctgagcctt ggaaatcaaa cgaaggttat ctcttaacca 660
ttgcacgaca gatccagcga cagcaatcga tccctccaaa gcatactgtg gcttagaaga 720
gtgtttgcca tcttcggact catccaaacc tgggaaccaa tatcccacag tggtcaaagc 780
accgtgctca gaaatcaaag tctgatcacc agtgttgtac agcaagaaag caccggtacc 840
atatgtacat ttggcatcac cctttctgac agccaactgt ccaaccaaag aggcagattg 900
gtcacccaga catccagcca aaggagcacc ttcaatagtt tccagaagag caagggcgtc 960
atcagtaagg taagactcaa catatccaat agactccaag tgtgggacct tgaagtgtcc 1020
gtagacttct gcggaagatc tgatttctgg aaggatgact ttggaagtat cgacgtccca 1080
gaatttcaaa agtctgtcgt catatttgtt ggtttcaatg ttcatgaagt tggttctgga 1140
ggcattggta acatcagtga cgtgggattt ttcgttagtc aagtggtaaa tcaaccaaga 1200
gtcaatagta ccaaacatta gatccccatc agcattgtca taggcctgtt tgacctcagg 1260
aacatgcttc agtaaccatc tgaacttggt tgcagaaaag taggtggaga ttggacaacc 1320
acacaaggtt cgcatttcct ctctctcctt ctcagagtac ttggcggtgt actcgtcaac 1380
aatatcgttg tttctggtat cgttccacac aataccgttg taaagaggct ttcctgtctt 1440
cttggaccaa acaaccgtgg tctctctcat gttggcaaca ccgatagata tgagcttgta 1500
tttatttttt tcatctcggt ccaagttctt gttctccatg gtgactaaac aagcagcaag 1560
acactgaacg gcgttggcca agatgtgact tggacgacat tcaacccagc ctggctgagg 1620
aaattgcaaa gttggaccag ccttattgtc aacggactca acttccaagt cgtcagaaac 1680
tgtcagggaa ataccttcgg aagagatgat ctgagaacgc tttcttttga tatcatcctg 1740
agcagaggta gagtactcga tctggtgctt ggccacttcc tgaccgtggt agtcaaaaag 1800
aatagctctg gtggaggtag taccaatatc gatggtagca actagtggtg tatagtcttt 1860
tcccat 1866
<210> 8
<211> 386
<212> DNA
<213> 人工序列(Artificial Sequence)
<400> 8
ttctggtgac aacccagggg attcagcccc tgtagccgat gatgaacgtg gccagccgtt 60
caatcacctc ggcgatgcac cccctcaggt gttatcacag gactggctcc tccaacaccg 120
ttacttgggc aacgcgcctc ttctggcctg cgctagcgca ggtagtacat ttataaataa 180
agggtgagcg gggcggttgt caacgatggg gtcatgcgga tttttcatcc actcctggcg 240
gtcagtagtt cagctaataa atgcttcact gcgctaaggg tttacactca acattacgct 300
aacggcacta aaaccatcac atttttctgt gactggcgct acaatcttcc aaagtcacaa 360
ttctcaaaat cagaagagta ttgcta 386
- 一种N-乙酰氨基葡萄糖的大肠杆菌工程菌及发酵生产方法
- 一种N-乙酰氨基葡萄糖的发酵生产方法