一种基于并行改进人工蚁群算法的RNA二级结构预测方法
文献发布时间:2023-06-19 11:14:36
技术领域
本发明涉及路径规划领域,尤其涉及一种基于CUDA改进人工蚁群算法的RNA二级结构预测方法。
背景技术
核酸序列是生物信息学主要研究的对象之一,它分为DNA核酸序列和RNA核酸序列,DNA携带合成RNA和蛋白质所必要的遗传信息,是生物体发育和正常运作必不可少的生物大分子。RNA存在于生物细胞以及部分病毒中,分为编码RNA和非编码RNA(ncRNA),前者负责编码蛋白也称为信使RNA(mRNA),后者为功能性RNA负责调控细胞的生长,发育和凋亡,其中比较常见的是核糖体RNA(rRNA)和运转RNA(tRNA)这两种RNA负责细胞的基础代谢,因此在多种组织和器官中均有连续表达;microRNA(miRNA)一般是长度为21-23个碱基对的发夹结构,在肿瘤的发生过程中有调控作用;除此之外还有核仁小分子RNA(snoRNA),小干扰RNA(siRNA)负责不同的功能。DNA的核酸是脱氧核糖,而RNA的核酸是核糖。与RNA相比,DNA的脱氧核糖缺少一个氧分子。组成DNA的核苷酸(nucleotide)包括A(腺嘌呤,adenine)、G(鸟嘌呤,guanine)、C(胞嘧啶,cytosine)和T(胸腺嘧啶,thymine),而RNA核苷酸有A,G,C和U(尿嘧啶,uracil)。在真核细胞(eukaryotic cells)中,DNA的结构是双螺旋的,而RNA的结构是各种形式的单链结构,RNA的单链结构允许RNA在必要的时候进行自身折叠,从而形成各种稳定的二级结构。
RNA的二级结构有两个重要的作用,第一,它可以帮助解释与RNA功能,RNA的功能常常与RNA的结构有关,二级结构是RNA所有结构中(一级结构、二级结构和三级结构)中最至关重要的,RNA一旦形成,会经过变化,形成特定的三级结构。三级结构的形成依赖于二级结构中碱基对之间的匹配。第二,对于二级结构的了解,也可以用来探究RNA的新功能。
发明内容
本发明的目的在于解决现有技术中存在的不足,提供一种基于改进人工蚁群算法的路径规划方法,从技术改进层面讲,通过CUDA的多线程技术,提高并行能力和计算效率。从而大幅度提升程序的运行速度。从算法改进层面讲,改进了RNA的子结构的区分算法。在使用自由能公式计算子结构能量之前,还需要对序列的各个子结构进行识别、区分,本文提出一种新的子结构区分算法,相比其它的子结构区分算法执行起来花费更少的时间复杂度和空间复杂度,并且适用于CUDA中的自由能的计算。
附图说明
为了使本发明的内容更容易被清楚地理解,下面根据具体实施例并结合附图,对本发明作进一步详细的说明:
附图1为茎区矩阵图
附图2为茎区示例图
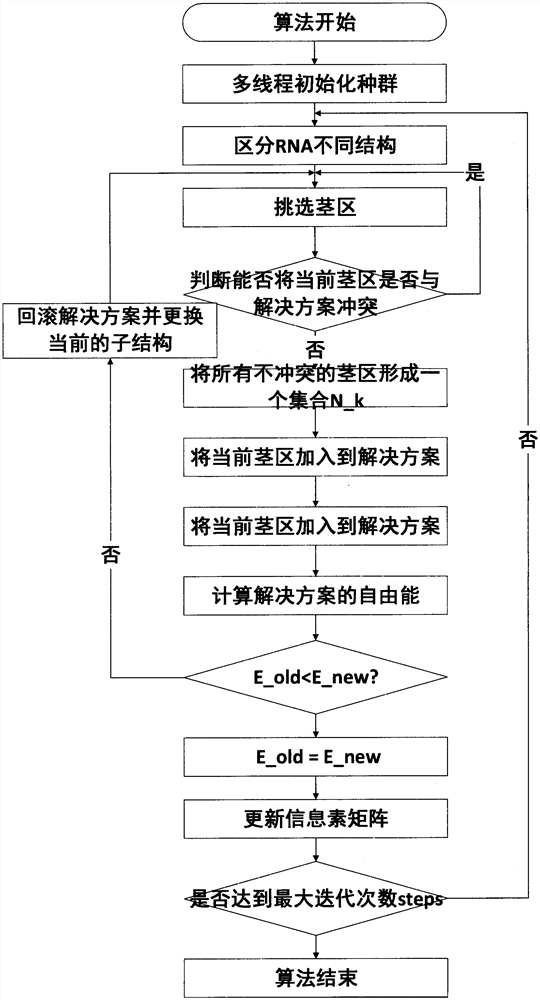
附图3为本发明流程图。
具体实施方式
为更加了解本发明的技术内容,特举具体实施方式配合图例进行说明如下。
实现本发明目的的技术方案是:一种基于CUDA改进人工蚁群算法的RNA二级结构预测方法,包括如下步骤:
步骤一:构建RNA二级结构茎区池;
步骤二:基于并行改进的人工蚁群进行计算最小自由能并构建相应的二级结构,避免陷入局部最优以获得全局最优解;
步骤三:对构建好的RNA二级结构进行可视化,生物信息学的工作人员可以更加直观的对RNA序列进行分析;
进一步的,所述步骤一的具体过程如下:
(1.1)根据图1所示,RNA序列S的长度N,构建N*N大小的茎区矩阵,并将序列字幕按次序放在首行的上一行,首列的前一列,然后在下三角矩阵中,根据碱基对匹配的规则,将矩阵中匹配碱基的对应位置设为1,将矩阵中不匹配碱基的对应位置设为0。碱基的种类包括A(腺嘌呤,adenine)、G(鸟嘌呤,guanine)、C(胞嘧啶,cytosine)和U(尿嘧啶,uracil)。根据Watson-Crick和GU摇摆碱基对配对法有六种配对方法:“AU”、“UA”、“CG”、“GC”、“GU”、“UG”。以RNA序列CGCCCAGCGAAAUGCAAAGUC为例,其茎区矩阵如图1所示。
(1.2)茎区矩阵建立好之后,在茎区矩阵中寻找连续的碱基对,其过程如下
a)从矩阵的左上角第i(0≤i≤N)行第j(0≤j≤N)开始,向矩阵右上(i+1,j-1)的方向搜索连续的碱基对,并在首个连续处停下。
b)计算连续碱基的长度是否大于茎区最小长度n,如果连续碱基的长度大于n则将此段连续的碱基保存起来,反之,则不保存。
c)继续向茎区矩阵的右上方寻找连续的碱基对,如果遇到匹配的碱基则执行b)。
d)如个寻找的位置到了矩阵的边缘,判断的条件为i=N或j=N,就将i和j重置为原来的位置,并将i设置为i+1。以RNA序列CGCCCAGCGAAAUGCAAAGUC,n=3为例,其茎区矩阵中连续如图1中所圈出碱基。
(1.3)完成茎区的寻找后,需要将寻找到的茎区作为茎区池保存,并作为下一步的输入。
(2.1)步骤二的过程如附图2所示,设置人工蚁群算法的参数,控制算法的参数包括种群大小colony_size、最大迭代次数steps,信息素蒸发的常数p,信息素初始值initial_pheromone,信息素的权重α,启发函数的权重β,启发函数η(l),线程数量m。信息素矩阵初始化全部为initial_pheromone。信息素矩阵的大小为与茎区池中茎区数量一致。将每只人工蚂蚁分配到不同的线程上。每只人工蚂蚁内部通过存储一个bitmap结构,判断对应位置的茎区是否被访问,初始化时,将所有的bitmap设为false。当访问过某一个节点后设为true。设置为true之后不再重复访问。
(2.2)判断两个茎区是否存在冲突和假结,对茎区A和茎区B而言冲突的判读如公式1所示
对于假结的判断如公式2所示
i<i′<j<j′(i,i′∈Stem
(2.3)判断茎区i是否与解决方案S冲突的三个条件
1.茎区i与解决方案S中每一个茎区都不冲突。
2.茎区i与解决方案S中每一个茎区都不构成假结(如果有需要)。
3.茎区i没有被蚂蚁k访问过。
(2.4)将所有符合(2.3)要求的茎区构造集合N
(2.5)茎区选择算法的公式如公式3所示:
(2.6)每个节点的信息素更新算法为公式4所示:
其中
(2.7)每个节点信息素的挥发遵从公式5:
τ(i)=(1-ρ)·τ(i) (5)
每次信息素都会在原有的基础上按照一定比例挥发。
(2.6)在RNA序列的实际折叠过程中长度更长的序列更容易被选中,启发函数的定义见公式6:
其中i表示某个茎区,i.length表示茎区序列的长度,paired_length表示所有匹配碱基的长度。
(2.7)在公式3为每个茎区生成了不同的概率,再通过轮盘赌算法返回通过概率计算得来的茎区。
(2.8)将计算得来的茎区添加到解决方案S中。
(2.9)计算解决方案S的自由能,自由能的计算如公式7所示:
E=E
RNA二级结构的自由能根据每一个部分不同计算得来。所以首先需要使用区分算法区分不同的结构。
(2.10)如果单链末梢两端碱基与同一个茎区a相邻,则这条单链s与茎区a属于同一个发夹环子结构,s属于发夹环子结构的环状单链,茎区a属于发夹环的茎区。如公式8所示。
s
(2.11)如果单链s的末梢两端所对应的碱基b
b
(2.12)对于一条单链s如果s末梢两端的碱基b
b
(2.13)从单链角度出发给出多分支环的定义,对于一条单链s
(2.14)对于假结的判断较为复杂,参照(2.2)中的方法。
(2.15)螺旋区自由能的计算方法为公式11:
E
其中内分子的初始自由能一般为常数E
(2.16)发夹茎区自由能的计算方法为公式12:
E
其中初始化自由能E
(2.17)凸环自由能的计算方法为公式13、公式14:
E
E
计算凸环的能量需要分为两个部分,如果凸环单链长度唯一,则使用公式13,否则使用公式14。E
(2.18)内环来说,计算公式为公式15
E
其中E
(2.19)多分支环来说,计算公式为公式16
E
其中a,b,c为系数,averagea symmetry代表每个螺旋茎区两侧单链碱基数量差值的平均值,number of branchinghelices是指多分支环中所有单链碱基的数量和。
(2.20)对于假结来说,如公式17,公式18,公式19所示
E
E
E
其中paired_pena,band_penalty都是惩罚项,unpairedpenalty为为匹配的惩罚项。
(2.21)使用公式7计算完自由能E之后使用公式20判断解决方案S是否接受这次添加。
S
min_energy会返回两个解决方案S中的更小者。
(2.22)如果迭代次数达到steps,则终止算法,输出最小自由能的结果,否则回到(2.3)继续循环循环;
(3.1)将(2.22)求解出最小自由能的解决方案S转换为点括号的形式。匹配的碱基中位于前面的碱基用”(”表示,匹配的碱基中位于后面的碱基用”)”表示。没有被匹配的碱基用”.”表示。
(3.2)将上一步生成的点括号表达式绘制成图形输出。
- 一种基于并行改进人工蚁群算法的RNA二级结构预测方法
- 一种基于卷积神经网络和规划动态算法的RNA二级结构生成器及其预测方法