一种基于多核投影NMF的快速高光谱图像像元解混方法
文献发布时间:2023-06-19 11:14:36
技术领域
本发明属于图像处理技术领域,涉及一种基于多核投影NMF的快速高光谱图像像元解混方法。
背景技术
高光谱图像光谱存在光谱分辨率高、表达地面信息精细以及图谱合一等特点,因此高光谱图像在农业、矿产、军事等多方面得到了广泛应用。但是受到成像原理和光学器件的限制,高光谱图像存在空间分辨率不高的问题,导致高光谱图像中混合像元的存在较为普遍,为高光谱图像的高精度地物分类、图像分辨率提升等应用带来了障碍。
像元是构成遥感影像的基本单元,若其中包含多种覆盖类型,称为混合象元。而每个混合像元的基本组成单元被称为端元,相应的每个端元在其所在像元中所占的比例称为丰度。由于遥感器的空间分辨率有限,以及自然界地物的复杂多样性,混合像元普遍存在于遥感图像中,成为遥感图像获取高精度信息的一大障碍。因此,在像元内部把混合像元分解成为不同的端元,并求得各组分的信息及其所占比例(丰度)的过程,即为像元解混。
非负矩阵分解(Non-negative Matrix Factorization,NMF)是当前广泛使用的一种高光谱图像解混方法,把高光谱数据近似地分解为基矩阵和系数矩阵的乘积形式。由于NMF算法非凸、容易陷入局部最优解,算法的效率较低且结果精度不高。相比于普通NMF算法,投影非负矩阵分解(Projective NMF,PNMF)通过寻找一个投影矩阵将数据映射到低维的投影空间中,将NMF中的基矩阵和系数矩阵两个变量转换为用投影矩阵一个变量进行表示,提高了参数算法的迭代速度。由于NMF和PNMF对对低维线性不可分数据解混精度不高,有学者提出了核投影非负矩阵分解(Kernel PNMF,KPMF),通过核方法将原低维空间线性不可分的数据投影到高维空间实现线性可分。因为不同核函数的特性不同、适用场景不同,所以KPNMF存在核函数的选择问题。
多核学习(Multiple Kernel Learning,MKL)方法采用将多个核函数进行组合的形式,通过为不同核函数设定权重参数的,避免了核函数选择的问题。MKL方法相比于单核方法能够实现核函数的自动选择和加权,获得更好的映射能力。多核非负矩阵方法(Multiple Kernel NMF,MKNMF)将MKL方法引入NMF,提高了算法精度。由于在基矩阵和系数矩阵外还需要对核函数进行求解,MKNMF算法的时间性能较差。
发明内容
本发明的目的在于克服上述现有技术的缺点,提供了一种基于多核投影NMF的快速高光谱图像像元解混方法,该方法能够较为准确的实现高光谱图像像元解混,且处理时间较短。
为达到上述目的,本发明所述的基于多核投影NMF的快速高光谱图像像元解混方法包括以下步骤:
1)构建多核模型,初始化核函数的权系数β=[β
2)利用PCA方法确定端元的个数,同时利用VCA方法初始化基矩阵W;
3)利用公式G=Tr(K)-2Tr(WW
4)根据公式
5)根据公式
6)当满足最大迭代次数或者满足收敛阈值时,则将当前的基矩阵W作为分解后的基矩阵,完成基于多核投影NMF的快速高光谱图像像元解混;否则,则转至步骤3)。
步骤1)中构建的多核模型为:
其中,k
利用MKL方法,将式(4)优化为:
令λ=(λ
G=Tr(K)-2Tr(WW
对式(9)的两端同时对W求导,得
由Kuhn-Tucker条件λ
2(KW)
则W由式(12)进行迭代得到
迭代过程中,当||φ(x)-WW
步骤2)中利用PCA方法确定端元的个数的具体过程为:
对于高光谱图像,其第i个端元z
因此,对于一个给定的ρ∈(0,1),存在一个k>0,使得
寻找前k个端元,使得其能够包含该高光谱图像的信息比例大于等于ρ,其中,k为端元个数。
本发明具有以下有益效果:
本发明所述的基于多核投影NMF的快速高光谱图像像元解混方法在具体操作时,通过引入多核学习方法,将高光谱数据映射到高维空间,以实现线性可分,提高解混的精度,同时利用PCA方法确定端元的个数,同时利用VCA方法初始化端基矩阵W,以提高迭代的效率,缩短解混的处理时间,操作方便、简单,便于推广及应用。
附图说明
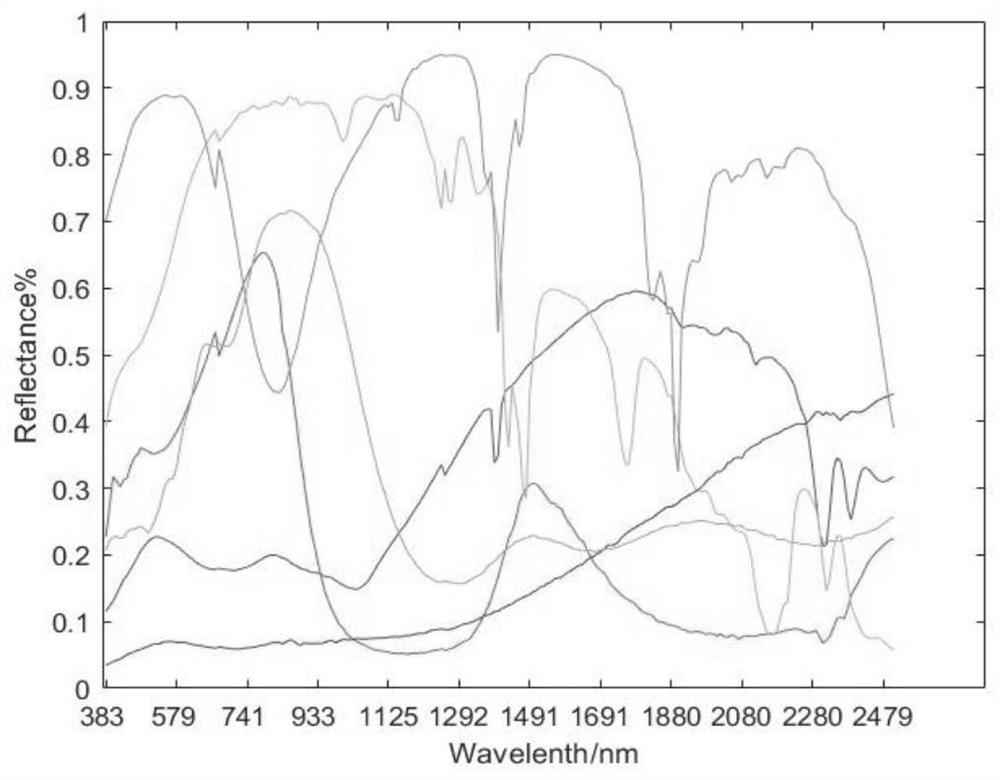
图1为USGS光谱库选择的六种光谱图;
图2为图1中六种光谱图像各端元对应的丰度图;
图3为验证试验中3种算法提取的端元光谱曲线与真实光谱曲线比较图;
图4为验证试验中3种算法解混后丰度与真实丰度比较图;
图5为验证试验中3种算法对Urban图像解混后丰度图和参考丰度图对比图;
具体实施方式
下面结合附图对本发明做进一步详细描述:
非负矩阵分解与核投影非负矩阵分解
NMF是一种基分解方法。对于任意给定的一个非负矩阵V,NMF旨在寻找到两个非负矩阵W及非负矩阵H,使得V≈WH,其中,V为原始数据,W为分解后的基矩阵,H为系数矩阵,显然,对于NMF算法,其所求参数W和H的个数需大于公式的个数,具有明显的非凸性,存在大量局部最优值,得到的结果不具有唯一性,而导致解混结果精度较低。同时,由于NMF的计算量较大,迭代收敛速度缓慢,当处理的数据规模较大时,NMF算法运算效率低。
为了提高NMF效率,Yuan等提出了投影非负矩阵分解(PNMF)算法。PNMF算法的基本思想是:对于n
其中,基矩阵W≥0,投影矩阵P=WW 相对于普通NMF算法,PNMF算法只有一个变量W,减少了每次迭代的计算量。由于PNMF方法依然是非凸的,PNMF方法仍在不能获得全局最小。在处理非线性数据时,存在性能下降的问题。 利用核映射 φ:x∈V 可以把非线性数据从低维空间非线性地映射到高维空间,以达到数据线性可分的目的。KPNMF方法将原始非线性数据映射到高维空间,再利用核非负矩阵分解的方式进行分解: φ:x∈V 其中,K=φ(x) 但是对于高光谱图像这一类的多维度以及数据特征空间分布差异较大的数据集时,如何恰当选取核函数,对于KPNMF仍是一个问题。 为解决上述问题,本发明所述的基于多核投影NMF的快速高光谱图像像元解混方法包括以下步骤: 1)构建多核模型,初始化核函数的权系数β=[β 2)利用PCA方法确定端元的个数,同时利用VCA方法初始化基矩阵W; 3)利用公式G=Tr(K)-2Tr(WW 4)根据公式 5)根据公式 6)当满足最大迭代次数或者满足收敛阈值时,则将当前的基矩阵W作为分解后的基矩阵,完成基于多核投影NMF的快速高光谱图像像元解混;否则,则转至步骤3)。 1、总体设计 构造多核模型,其中,多核模型为:
其中,k
结合MKL方法,将式(4)优化为:
令k
利用线性规划求解式(7),得核函数的权系数β。 将核函数的权系数β代入式(6)对W进行求解,得
令λ=(λ G=Tr(K)-2Tr(WW 对式(9)的两端同时对W求导,得
由Kuhn-Tucker条件λ 2(KW) 则W由式(12)进行迭代得到
迭代过程中,当|φ(x)-WW 2、基于PCA的端元个数确定和基于VCA的端元矩阵初始化 2a)常用的判定端元个数的方法包括:主成分分析法(Principal ComponentsAnalysis,PCA)、拟维数(Virtual Dimensionality,VD)、最小误差信号子空间识别(Hyspectral Signal Identification By Minimum Error,HySime)以及特征值似然最大法(Eigenvalue Likelihood Maximization,ELM)等方法。本发明选用PCA方法进行端元个数确定。 对于高光谱图像,其第i个端元z
因此,对于一个给定的ρ∈(0,1),存在一个k>0,使得
寻找前k个端元,使得其能够包含该高光谱图像的信息比例大于等于ρ,其中,k为端元个数。 2b)采用顶点成分分析法(Vertex Component Analysis,VCA)对端元矩阵的初始化,VCA法以线性光谱混合模型为基础,通过反复寻找正交子空间,并计算图像矩阵在正交子空间中的投影向量2范数逐次进行端元提取。 初始端元为:
在实际操作时,当已经提取k个端元,由k个端元对应的k维空间E E 则E
第k+1个端元为:
其中,
验证试验 为验证本发明的性能,在本发明的基础上进行解混实验,并从解混精度以及时间性能两个方面进行实验比较及分析。 模拟数据采用选择部分光谱进行合成的方式进行。从美国地址调查局(UnitedStates Geological Survey,USGS)发布的第7版光谱库splib07a中选择一部分光谱合成模拟高光谱图像。首先从splib07a中AVIRIS 1995光谱库中抽取所有矿物质的光谱特征,去除受干扰严重的光谱特征后,按照任意两光谱之间的光谱角距离从大到小进行排列,形成实验光谱库。然后从实验光谱库中,抽取任意六种物质光谱,如图1所示。最后,基于线性光谱混合模型生成模拟高光谱图像。模拟高光谱图像大小为169×169,包括224个光谱特征,满足丰度非负和和为一约束,图2为六个光谱端元所对应的丰度图,模拟高光谱图像包括36个方块区域,每个区域尺寸为13×13。其中,第一行的六个方块为纯像元区域,每个方块对应区域只包括一个光谱端元。第二行至第六行为混合像元区域,由两个至六个数目不等的端元等比进行混合。背景区域由六个端元随机比例进行混合。为模拟传感器噪声以及其他可能出现的误差,添加独立同分布的高斯白噪声,SNR为20dB。 对于解混精度,分别采用光谱角距离(Spectral Angel Distance,SAD)及均方根误差(Root Mean Square Error,RMSE)进行评价。SAD用于度量真实端元与解混后提取的端元之间的相似程度,SAD值越小,则说明本发明解混得到的光谱与真实地物光谱的差距越小。RMSE用于度量地物真实丰度与解混后计算丰度之间的相似程度,RMSE值越小,则说明本发明解混得到的地物丰度越接近于真实地物丰度。
其中,A为光谱库中的真实端元光谱,A′为解混后提取的端元光谱。
其中,X为地物真实丰度,为解混后的估计丰度。 对于本发明的时间性能,在同一电脑硬件配置的条件下,对于相同数据集经算法得到预期实验结果所需要的运行时间作为算法的评价指标。运行时间越短,则反映说明具有更优的时间性能。 为保障实验结果的稳健性,每个算法都进行10次计算,取其平均值进行评价。 图3为NMF、MKNMF以及本发明对模拟高光谱图像解混后所提取出的端元光谱曲线及其在数据库中的光谱曲线的比较,按照标号依次对应端元1至端元6的光谱曲线。 图4为NMF算法、MKNMF算法以及本发明对模拟高光谱图像解混后得到的丰度图与真实丰度图的比较,其中,第1行对应模拟高光谱图的真实丰度图,第2至第4行分别为NMF算法、MKNMF算法以及本发明得到的丰度图。 从图4中可以看出,NMF算法只能对6种端元中的第2种、第3种以及第5种端元进行有效提取,而MKNMF算法与本发明能够对6种光谱进行有效的提取,并且得到的端元光谱更接近于真实光谱,其端元提取效果明显优于NMF算法。 为更好地对解混结果进行评价,将每种算法解混后的SAD、RMSE以及算法运行时间等指标在表1中列出,并对于每项的最优值进行了加粗,从表1中可以看出,由于都采用了MKL方法以及相同的核函数,MKNMF与本发明得到的SAD、RMSE值相近,且解混后得到的各端元的SAD值、SAD均值明显小于NMF算法,端元提取精度更高。说明采用MKL方法能够有效提高算法对高光谱图像的解混精度。 对于算法的运行时间,虽然采用了MKL方法的本发明相较于NMF算法增加了18.79%,但是较于MKNMF算法增加了43.73%的幅度更小。说明本发明能够在提高解混精度的同时,具有更好的时间性能。 表1
真实高光谱图像数据像元解混实验基于Urban公开数据集。Urban为1997年HYDICE传感器采集到的高光谱图像。经裁剪后大小为256×256,每个像素对应一个2×2平方米的区域。共有210个波段,范围从400到2500nm,光谱分辨率为10nm。移除受密集水蒸气和大气效应影响的波段(1~4、76、87、101~111、136~153、198~210)后,保留162个波段。在这个区域中主要包括沥青路面(Asphalt Road)、草地(Grass)、树木(Tree)、屋顶(Roof)、金属(Metal)及泥土(Dirt)六类地物。 图5为NMF、MKNMF和本发明对Urban图像解混后所得到的丰度图及其参考丰度图的比较。对其中第1行为参考真实地物的丰度图,第2行至第4行依次对应NMF、NMF和本发明解混后的丰度图。图中第1至第6列依次对应沥青路面、草地、树木、屋顶、金属、泥土六类端元的丰度图。从图5中可以看出,NMF算法仅能对沥青路面、草地、树木、屋顶进行分离,而对金属、泥土的分离效果不佳。而MKNMF与本发明能够有效地对六种地物进行分离,解混效果较NMF更好。 表2为Urban地区高光谱数据实验所得结果,对于每项的最优值进行了加粗表示,对于解混精度,除了Metal这一类地物之外,本发明的SAD与RMSE均为最优,表明本发明具有良好的解混精度。对于时间性能,本发明相较于NMF算法增加了15.26%,但明显快于解混精度相近的MKNMF算法。 从解混精度和算法运行时间综合比较,真实数据实验验证了模拟数据实验结果,表明本发明相较于NMF算法能够显著提高对高光谱图像的解混精度,并且在保证解混精度的同时具有更好的时间性能。 表2
- 一种基于多核投影NMF的快速高光谱图像像元解混方法
- 一种基于复合端元的月表高光谱图像阴影区域解混方法