一种基于相互分歧学习的域自适应行人重识别方法
文献发布时间:2023-06-19 11:14:36
技术领域
本发明应用深度学习和互学习来实现无监督域自适应的行人重识别,属于计算机视觉领域。
背景技术
行人重识别(re-ID)旨在在不同摄像机之间建立身份对应关系,判断不同相机的图像,或者视频序列中是否存在特定行人的技术,通常被认为是图像检索的子问题。在过去的十年中引起了极大的关注,并取得了令人瞩目的进展。行人重识别技术广泛应用于在一个较大区域内跟踪一个人的轨迹,在机器人技术、智能视频监控、照片自动标注等领域也有着很高应用价值。
目前相较于成熟的人脸识别技术,行人重识别依然是计算机视觉领域的难题。其主要挑战是同一目标在不同摄像头下受视角变化、光照变化、姿态变化、行人遮挡和背景噪声干扰等影响,使得不同视角下的特征表示存在一定程度的偏差。现有行人重识别方法一般都是基于深度学习,本质上是计算图像之间的相似度或者距离,然后根据它们的相似度或者距离对样本进行排序,最后找到与要查询的行人图像属于同一个人的图像。但是由于监控视频的分辨率等限制,在实际监控领域的应用中很难直接通过人脸来寻找同一目标,然而利用行人穿着外形等外在特征来检索行人是一种替代的方法。
目前研究行人重识别的大多数的工作都集中在有监督的学习方法上,这些方法极大地依赖于大规模数据集的获取和准确的手工标注,这通常是一项耗时且繁琐的任务。尽管在这种大规模数据集的监督下,re-ID方法取得了非常不错的结果,但是由于域差异的存在,当我们将训练好的reid模型直接应用于新的相机系统时,它们经常会遇到灾难性的性能下降。因此,目前的研究重点已转移到无监督域自适应(UDA),它试图将在有标签的源域数据集上训练的模型转移到无标签的目标域数据集上。尽管基于聚类的UDA方法取得了令人瞩目的进展,但是由于源域特征的可传递性有限、目标域图像标签的不可知性以及聚类结果的不完善性等原因导致的不可避免的伪标签噪声仍然是性能提高的障碍因素。
参考文献:
[1].LIN,Yutian,et al.A bottom-up clustering approach to unsupervisedperson re-identification[C].Proceedings of the AAAI Conference on ArtificialIntelligence,2019.p.8738-8745.
[2].Wang,Zhongdao,Zheng,Liang,Li,Yali,等.Linkage Based FaceClustering via Graph Convolution Network[J].
[3].Yixiao Ge,Dapeng Chen,and Hongsheng Li,“Mutual mean-teaching:Pseudo label refinery for unsupervised domain adaptation on person re-identification,”in International Conference on Learning Representations,2020.
[4].Yunpeng Zhai,Shijian Lu,Qixiang Ye,Xuebo Shan,Jie Chen,RongrongJi,and Yonghong Tian,“Ad-cluster:Augmented discriminative clustering fordomain adaptive person re-identification,”in Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition,2020,pp.9021–9030.
发明内容
为了解决以上方案的不足,本发明的目的是提出一种基于相互分歧学习的域自适应行人重识别方法,以缩小源域和目标域之间的分布差异。
为实现上述目的,本发明采用的技术方案为:
一种基于相互分歧学习的域自适应行人重识别方法,包括以下步骤:
步骤S1,准备行人数据集,行人数据集包括有标签的源域数据集和无标签的目标域数据集;
步骤S2,在源域数据集上进行预训练,在目标域数据集上提取图片的特征向量;
步骤S3,对目标域数据集的图像进行基于密度的聚类,将簇的编号作为伪标签;
步骤S4,使用对抗性的策略将离群点加入到训练样本中;
步骤S5,将步骤S3得到已聚类的样本和步骤S4得到的离群点混合,一起送入网络,采用相互分歧学习来校正伪标签的噪声,将待查询的行人图像输入到训练好的行人重识别模型中,得到待识别的行人特征向量,并将它与候选库中的属性特征进行相似度比较并排序,得到行人重识别的结果。
所述步骤S2中,利用ResNet-50模型在源域数据集上进行有监督的预训练,然后用预训练的模型来初始化训练目标域数据集,提取目标域数据集中图片的特征。
所述步骤S2中,使用预训练的模型进行初始化,并且去除ResNet-50模型的最后一个分类层;在目标域数据集上提取图片的特征向量表示为X={x
所述步骤S2中,使用的损失函数为交叉熵损失和三元组损失对预训练后的模型进行优化。
所述步骤S3包括:
步骤S31,计算目标域数据集中每张图像与其它所有图像之间的距离;
步骤S32,对每张图像之间的距离使用基于密度的聚类算法(DBSCAN),将高密度区域中的样本分组为簇,并将低密度区域中的样本保持为离群点;
步骤S33,对于已经聚类为簇的图像,使用它们所在的簇的编号作为它们的伪标签,然后对伪标签进行优化训练。
所述步骤S4中,使用一个额外的辅助网络,先将部分已聚类的图像送入辅助网络中进行学习,这样辅助网络就能获得聚类样本的普遍特征;然后将离群点送入辅助网络中,这样就能够提取出一些小损失的离群点。
所述步骤S5中,采用相互分歧学习来纠正伪标签,对伪标签的训练和优化交替进行:在训练的早期阶段,通过输入相同的图像但分别进行随机擦除,裁剪和翻转以及进行不同的参数初始化的方式来维持两个网络的差异;在训练的中期和后期,采用分歧策略来减缓两个网络达成共识的速度,并保持两个网络之间的持续分歧;执行每个网络以进行自己的预测,并选择两个网络之间存在预测差异的样本;基于这些样本,每个网络都进一步训练了这些分歧样本并更新了其参数。
所述步骤S5中,为每个对等网络提出基于动量的移动平均模型。
本发明采用以上技术方案与现有技术相比,具有以下有益效果:
(1)本发明提出了一种基于相互分歧学习的无监督域自适应行人重识别方法,缩小了源域和目标域之间的分布差异,有效地利用源域的知识,最终本发明的框架能学习到具有鲁棒性和鉴别性的特征。
(2)本发明采用对抗性策略逐步将聚类结果中的离群值附加到训练过程中,从而增加了训练样本的多样性和可靠性。
(3)在三个大型数据集上的实验结果证明了本发明提出的框架与其他最新方法相比的优越性。
附图说明
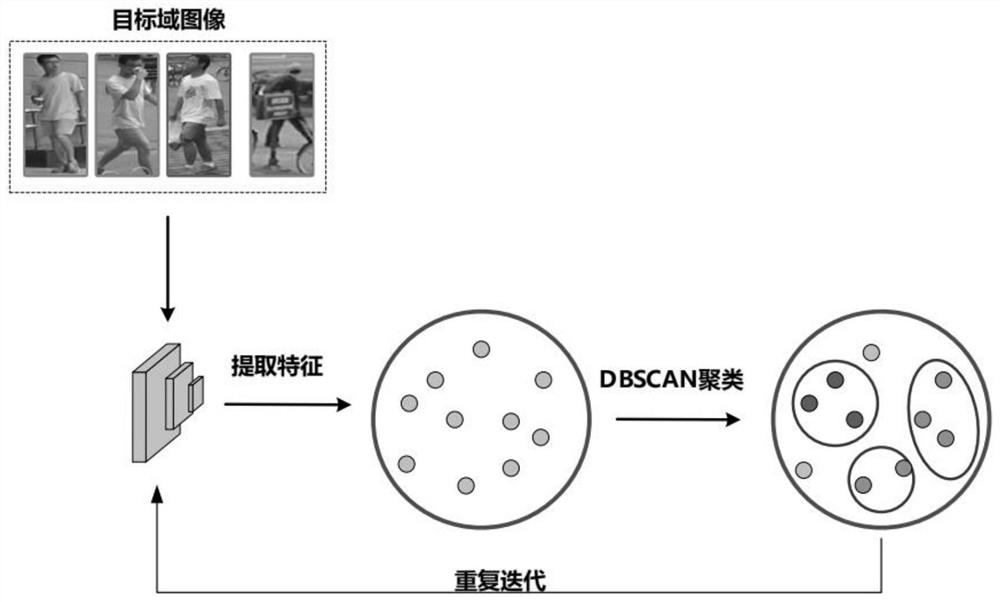
图1为本发明提出的一种基于相互分歧学习的域自适应行人重识别的流程图。
具体实施方式
下面对本发明做更进一步的解释。
如图1所示,本发明的一种基于相互分歧学习的域自适应行人重识别方法,包括如下步骤:
步骤1,数据集的准备及预处理:
数据集包括有完整标注信息的源域数据集和不使用任何手工标注信息的目标域数据集。
将行人重识别研究领域常用的三个公开数据集Market-1501、DukeMTMC-ReID、MSMT17作为本次训练模型的数据集。Market-1501该数据集包含来自6个不同摄像机的1501个行人和32688张带标签的图像。在所有图像中,将751个行人的12936张图像用于训练,将另外750个行人的3368个图像用于查询,和将750个身行人的19732张图像用作gallery图库。训练图像和图库图像之间的身份是不相交的。DukeMTMC-ReID数据集由从8个摄像机在室外捕获的视频组成,其中包含1404个行人和36411张有标签图像,其中训练集有702个行人的16522张图像,用于图库的有17661张图像和用于查询的有2228张图像。MSMT17数据集是由15个摄像机拍摄的最具挑战性的数据集,其中包含126441张4101个行人的图像。
步骤2:利用在行人重识别领域特征提取效果最好的模型ResNet-50来在源域数据集上进行预训练并且提取目标域样本的特征。在有完整标签信息的源域数据集上进行有监督的预训练,然后用预训练的模型来初始化训练目标域数据集。具体而言,在源域数据集Market1501上进行有监督的训练,使用交叉熵损失和三元组损失来优化网络,最终得到一个预训练好的模型。然后将该模型用作目标域数据集学习的初始模型,并且去除ResNet-50最后一个分类层;将无标签的源域数据集送入预训练好的模型中,提取每张图片的特征向量;样本特征表示为X={x
步骤3,对于步骤2中每张图像的特征向量,计算各个图像之间的距离,然后对距离使用基于密度的聚类算法(DBSCAN),将高密度区域中的样本分组为簇,并将低密度区域中的样本保持为离群点,这样就可以把目标域数据集划分为已聚类点和离群点。对于已经聚类的点,使用它们所在的簇的编号作为它们的伪标签。对于离群点,在步骤4中使用对抗性的策略将小损失的样本加入到训练过程中。
步骤4,对于步骤3的生成的离群点,尝试使用一个辅助网络逐步将离群点中的一些小损失样本附加到训练过程中,这不仅有效地使用了这些困难的样本,而且还进一步提升了模型的性能。交替训练主要模型和辅助网络,以便可以平滑地将相对高置信度的小损失样本添加到训练过程中。这样就得到了更可靠,更多样化的训练样本,其中包含已聚类的样本和损失较小的离群点。但是,监督信息可能是有噪声的,这是由于聚类结果的不完善和离群值的加入所导致的。
步骤5,为了防止re-ID模型受到有噪声的标签的影响,提出了相互分歧学习来纠正伪标签,对伪标签的训练和优化交替进行。在训练的早期阶段,通过输入相同的图像但分别进行随机擦除,裁剪和翻转以及进行不同的参数初始化等方式来维持两个网络的差异。在训练的中期和后期,尝试采用分歧策略来减缓两个网络达成共识的速度,并保持两个网络之间的持续分歧。具体来说,执行每个网络以进行自己的预测,并选择两个网络之间存在预测差异的样本。基于这些实际上困难但有价值的硬样本,每个网络都进一步训练了这些分歧样本并更新了其参数。为了防止两个网络彼此靠近收敛,为每个对等网络提出了基于动量的移动平均模型。
最后,将待查询的行人图像输入到训练好的行人重识别模型中,得到待识别的行人特征向量,并将它与候选库中的属性特征进行相似度比较并排序,得到行人重识别的结果。
综上所述,本发明的一种基于相互分歧学习的域自适应行人重识别方法,该方法通过在无标签的数据集上使用DBSCAN进行聚类,然后使用对抗性的策略将小损失的离群点加入到训练过程中,从而学习到具有鉴别性的行人特征。该方法降低了计算的复杂度,节约了大量的人工标注成本,并且有效地提高了行人匹配检索的准确度。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 一种基于相互分歧学习的域自适应行人重识别方法
- 一种基于多粒度特征表示和域自适应学习的无监督行人重识别方法