一种跨模态图文检索方法
文献发布时间:2023-06-19 11:16:08
技术领域
本发明涉及多媒体信息检索技术领域,具体来说,涉及一种跨模态图文检索方法。
背景技术
当前的移动互联网时代,由于智能移动终端的普及,每个人可以随时随地的发布与接收包括文本、图片、视频、音频等在内的多种模态信息,这带来了丰富的内容。然而,丰富的内容给我们带来更多的往往是选择的痛苦,获取真正需求的信息变得愈发困难。在当前的Web3.0时代,丰富的信息需要经过精准的筛选呈现在用户面前,对于检索系统,需要以用户为中心提供精准化的检索与服务。而当前的检索仅仅停留在单模态阶段,当前主流搜索引擎,比如Google,可以做到用户输入文本返回系列图片,但这种检索依赖的是图片本身标注好的文本信息,所以本质上仍然是以文本搜索文本的单模态检索。在面向Web3.0时代的今日,传统的单模态信息检索已经不能满足用户对个性化信息的需求,我们希望做到“盲人摸象”,一个盲人摸到一个大耳朵,搜索一下便可知道摸的是头大象。跨模态信息检索实际应用性很强,比如,找到最匹配给定图像的文本,给一段描述找到最适合的插图等。因此,跨模态信息检索技术有着重要的研究意义。
现有技术通过线性投影矩阵将不同模态的多媒体数据映射到统一子空间,然后在这个学习到的子空间里度量不同模态的多媒体之间的相似性,以此来实现跨模态检索。但在当前如此复杂的数据背景下,线性投影直接刻画映射空间并在此空间上度量相似度是不太现实的。
名词解释:跨模态检索:跨模态检索是对一种模态的查询词,返回与之相关的其他不同模态检索结果的新型检索方法。
针对相关技术中的问题,目前尚未提出有效的解决方案。
发明内容
针对相关技术中的问题,本发明提出一种跨模态图文检索方法,能够获取相关图片和文本之间的关联,不仅提高了在图片和文本相互之间检索的精确度,而且兼顾准确性和匹配速度,且降低了运营成本,以克服现有相关技术所存在的上述技术问题。
本发明的技术方案是这样实现的:
一种跨模态图文检索方法,包括以下步骤:
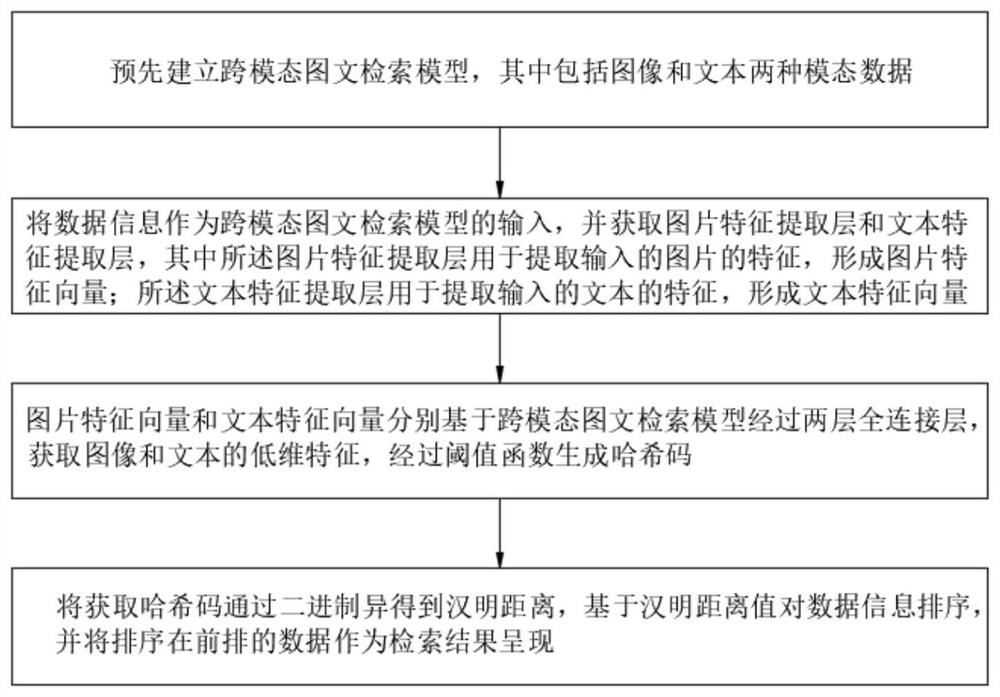
步骤S1,预先建立跨模态图文检索模型,其中包括图像和文本两种模态数据;
步骤S2,将数据信息作为跨模态图文检索模型的输入,并获取图片特征提取层和文本特征提取层,其中所述图片特征提取层用于提取输入的图片的特征,形成图片特征向量;所述文本特征提取层用于提取输入的文本的特征,形成文本特征向量;
步骤S3,图片特征向量和文本特征向量分别基于跨模态图文检索模型经过两层全连接层,获取图像和文本的低维特征,经过阈值函数生成哈希码;
步骤S4,将获取哈希码通过二进制异得到汉明距离,基于汉明距离值对数据信息排序,并将排序在前排的数据作为检索结果呈现。
进一步的,所述跨模态图文检索模型,包括以下步骤:
预选获取图文数据集,其中图文数据集包括文本数据和图像数据;
基于图文数据集分别采用LDA主题模型提取文本数据的特征向量和采用卷积神经网络特征提取方法和提取图像数据的特征向量,分别获取文本数据的特征向量集和图像数据的特征向量集;
基于CAA算法将获取的文本数据的特征向量集和图像数据的特征向量集映射到同个特征空间,确定文本数据和图像数据相似度,并构建跨模态图文检索模型。
进一步的,所述跨模态图文检索模型,包括第一层全连接层的激活函数是tanh函数;第二层全连接层的激活函数是sigmoid函数;第三层基于layer-wise训练策略的嵌入层。
进一步的,所述第三层基于layer-wise训练策略的嵌入层,包括通过图片特征提取层和文本特征提取层获取嵌入层,该嵌入层作为可跨模态图文检索模型内不同模态数据相似度的统一空间。
进一步的,所述并将排序在前排的数据作为检索结果呈现,包括以下步骤:
预先设定配对排序方式,并将获取的数据信息进行配对,获取相应的文字特征和图片特征;
基于预设标签信息对文字特征和图片特征进行处理,并进行排序呈现。
本发明的有益效果:
本发明跨模态图文检索方法,通过预先建立跨模态图文检索模型,将数据信息作为跨模态图文检索模型的输入,并获取图片特征提取层和文本特征提取层,形成图片特征向量和形成文本特征向量,并分别基于跨模态图文检索模型经过两层全连接层,获取图像和文本的低维特征,经过阈值函数生成哈希码,将获取哈希码通过二进制异得到汉明距离,基于汉明距离值对数据信息排序,并将排序在前排的数据作为检索结果呈现,实现能够获取相关图片和文本之间的关联,不仅提高了在图片和文本相互之间检索的精确度,而且兼顾准确性和匹配速度,且降低了运营成本。
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是根据本发明实施例的一种跨模态图文检索方法的流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员所获得的所有其他实施例,都属于本发明保护的范围。
根据本发明的实施例,提供了一种跨模态图文检索方法。
如图1所示,根据本发明实施例的跨模态图文检索方法,包括以下步骤:
步骤S1,预先建立跨模态图文检索模型,其中包括图像和文本两种模态数据;
步骤S2,将数据信息作为跨模态图文检索模型的输入,并获取图片特征提取层和文本特征提取层,其中所述图片特征提取层用于提取输入的图片的特征,形成图片特征向量;所述文本特征提取层用于提取输入的文本的特征,形成文本特征向量;
步骤S3,图片特征向量和文本特征向量分别基于跨模态图文检索模型经过两层全连接层,获取图像和文本的低维特征,经过阈值函数生成哈希码;
步骤S4,将获取哈希码通过二进制异得到汉明距离,基于汉明距离值对数据信息排序,并将排序在前排的数据作为检索结果呈现。
其中,所述跨模态图文检索模型,包括以下步骤:
预选获取图文数据集,其中图文数据集包括文本数据和图像数据;
基于图文数据集分别采用LDA主题模型提取文本数据的特征向量和采用卷积神经网络特征提取方法和提取图像数据的特征向量,分别获取文本数据的特征向量集和图像数据的特征向量集;
基于CAA算法将获取的文本数据的特征向量集和图像数据的特征向量集映射到同个特征空间,确定文本数据和图像数据相似度,并构建跨模态图文检索模型。
其中,所述跨模态图文检索模型,包括第一层全连接层的激活函数是tanh函数;第二层全连接层的激活函数是sigmoid函数;第三层基于layer-wise训练策略的嵌入层。
其中,所述第三层基于layer-wise训练策略的嵌入层,包括通过图片特征提取层和文本特征提取层获取嵌入层,该嵌入层作为可跨模态图文检索模型内不同模态数据相似度的统一空间。
其中,所述并将排序在前排的数据作为检索结果呈现,包括以下步骤:
预先设定配对排序方式,并将获取的数据信息进行配对,获取相应的文字特征和图片特征;
基于预设标签信息对文字特征和图片特征进行处理,并进行排序呈现。
综上所述,借助于本发明的上述技术方案,通过预先建立跨模态图文检索模型,将数据信息作为跨模态图文检索模型的输入,并获取图片特征提取层和文本特征提取层,形成图片特征向量和形成文本特征向量,并分别基于跨模态图文检索模型经过两层全连接层,获取图像和文本的低维特征,经过阈值函数生成哈希码,将获取哈希码通过二进制异得到汉明距离,基于汉明距离值对数据信息排序,并将排序在前排的数据作为检索结果呈现,实现能够获取相关图片和文本之间的关联,不仅提高了在图片和文本相互之间检索的精确度,而且兼顾准确性和匹配速度,且降低了运营成本。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于文本树局部匹配的图文跨模态检索方法及系统
- 一种基于混合粒度匹配的图文跨模态检索方法