一种医疗票据图像结构化方法和装置、计算机可读介质
文献发布时间:2023-06-19 11:19:16
技术领域
本发明属于图像处理技术领域,尤其涉及一种基于均值聚类和字符识别的医疗票据图像结构化方法和装置、计算机可读介质。
背景技术
近年来,随着我国医疗信息化的不断深入发展,医疗票据电子化已然成为一种趋势。但由于报销单位无法直接获取用户的医疗详细信息,导致用户在报销时需提交原始医疗单据,然后由报销人员手工录入系统,逐项核对后按照特定的报销比例和报销金额进行报销。在手工录入过程中存在很多的弊端,一方面是人工录入会不可避免的出现漏项错项问题,另一方面需配置大量人力资源进行高度重复性工作,这不仅会给医疗工作人员带来很大的压力,导致报销流程耗时费力且效率低。
对于票据自动化识别,在OCR技术把图像中的文字信息识别出来以后。需要考虑根据票据的结构化信息把文字识别结果进行结构化处理,形成医疗票据明细结果。但是已有的表格识别技术,主要是采用表格线等特征进行切分从中得到表格结构信息。但是对于很多医疗票据,不存在表格线。因此,无法采用现有的方法完成结构化处理。
发明内容
本发明要解决的技术问题是,提供一种基于均值聚类和字符识别的医疗票据图像结构化方法和装置,可以大幅度提高票据结构化效果。
为实现上述目的,本发明采用如下的技术方案:
一种基于均值聚类和字符识别的医疗票据图像结构化方法,包括:
步骤1、对获取的医疗票据图像进行OCR字符识别,得到票据全文字符串信息;
步骤S2、对所述票据全文字符串信息进行KMeans聚类;
步骤S3、根据聚类结果确定标题位置信息,根据所述标题位置信息,提取对应列所在的条目数据;
步骤S4、对所述条目数据进行合法性校验和修正,得到所述医疗票据的结构化数据。
作为优选,步骤S1中所述得到票据全文字符串信息,包括:
对医疗票据图像进行预处理;
计算预处理后医疗票据图像的旋转角度;
根据旋转角度对预处理后医疗票据图像进行旋转校正;
对校正后的医疗票据图像进行OCR识别,得到票据全文字符串信息,票据全文字符串信息包括:字符串内容、字符串坐标位置、字符串的识别置信度以及候选字符;
对所述票据全文字符串信息进行过滤处理。
作为优选,步骤S2中所述对票据全文字符串信息进行聚类,包括:
步骤2.1、提取步骤S1得到的所有票据全文字符串信息,以每个字符串的左侧位置初始化每个字符串的向量;
步骤2.2、初始化k=10个中心点,k代表最终聚类的结果;
步骤2.3、随机选取k个点作为初始聚类中心,计算各个字符串向量到各聚类中心的距离,
其中,x、y为字符左侧位置坐标值,
步骤2.4、比较每一个字符串向量到各个聚类中心的距离,并将其划分到距离聚类中心最近的类簇中;
步骤2.5、重新计算各个聚类中心直至收敛,输出聚类结果,其目标函数公式:
其中,u
作为优选,所述步骤S3中,根据聚类结果和OCR全文识别的数据进行列切分,统计每列数据对应的属性,所述属性包含:中文字符个数、数字个数、个数之和,将所述属性进行语义解析确定标题位置信息。
作为优选,所述步骤S3中,提取对应列所在的条目数据具体为:根据标题左右边界坐标信息依次取出垂直方向数据;根据取出的项目名称位置信息匹配垂直方向最近距离的金额信息,以取出单价或者数量;将满足合并条件的项目名称换行数据进行合并,得到具体条目数据。
一种基于均值聚类和字符识别的医疗票据图像结构化装置,包括:
识别模块,用于对获取的医疗票据图像进行OCR字符识别,得到票据全文字符串信息;
聚类模块,用于对所述票据全文字符串信息进行KMeans聚类;
提取模块,用于根据聚类结果确定标题位置信息,根据所述标题位置信息,提取对应列所在的条目数据;
修正模块,用于对所述条目数据进行合法性校验和修正,得到所述医疗票据的结构化数据。
一种计算机可读介质,所述计算机可读介质上存储有指令,所述指令被处理器执行时实现用于基于均值聚类和字符识别的医疗票据图像结构化方法的步骤。
本发明首先采用OCR技术得到字符串,然后对字符串根据坐标进行聚类分析,确定列数据;同时根据医疗票据的语义特征,包括标题关键字、中文字符统计、数字统计信息,提取出医疗票据中的项目名称、单价、数量和总价四项字段。除此之外,为确保结构化输出数据准确无误,该发明还增加了多重校验规则,基于字段间的内在逻辑关联关系,自定甄别置信度较低的文字信息,并依据内在逻辑对可能出错的数据进行启发式纠正。最后,综合多种方式,能够快速完成数据的校验与纠正,为医保报销提供完整、快速、精准的数据依据。
附图说明
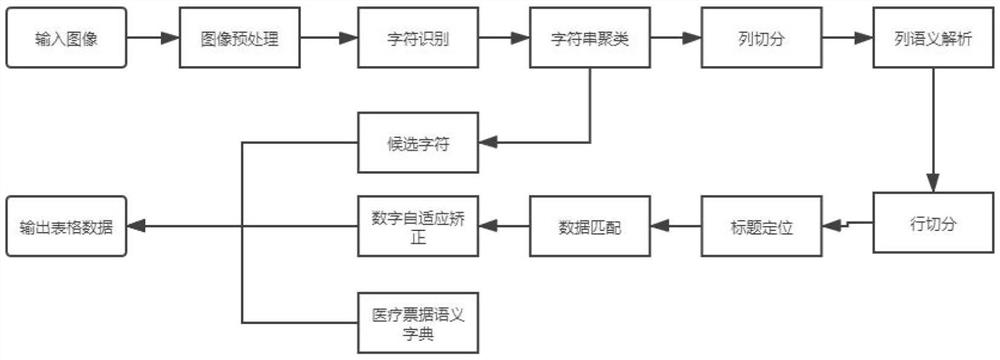
图1是本发明的医疗票据图像结构化方法的流程图;
图2是基于左侧位置X坐标的字符串聚类流程图;
图3是标题定位流程图;
图4是数字自适应校正流程图;
图5为本发明医疗票据图像结构化装置的结构示意图。
具体实施方式
为了更好的说明本发明的技术方案,下面结合附图和具体实施例对本发明做进一步详细说明。需要说明的是,此处所描述的具体实施方式仅用于说明和解释本发明,并不用于限制本发明。
如图1所示,本发明实施例提供一种基于均值聚类和字符识别的医疗票据图像结构化方法,包括以下步骤:
步骤1、对获取的医疗票据图像进行OCR字符识别,得到票据全文字符串信息;
步骤S2、对所述票据全文字符串信息进行KMeans聚类;
步骤S3、根据聚类结果确定标题位置,根据所述标题位置信息,提取对应列所在的条目数据;
步骤S4、对所述条目数据进行合法性校验和修正,得到所述医疗票据的结构化数据。
进一步,步骤S1中得到票据全文字符串信息,包括:
步骤1.1、对医疗票据图像进行预处理,包括裁剪、二值化和缩放;其中,对图像裁剪避免黑边对计算旋转角度产生的影响;对裁剪后的图像进行适应域值二值化,并将二值化后的图像进行缩放,缩放比例为裁剪后的四分之一,通过图像缩放进而提高图像处理速度;
步骤1.2、通过直方图方法,计算预处理后医疗票据图像的旋转角度;
步骤1.3、根据旋转角度对预处理后医疗票据图像进行旋转校正;
步骤1.4、对校正后的医疗票据图像进行OCR识别,得到票据全文字符串信息,票据全文字符串信息包括:字符串内容、字符串坐标位置、字符串的识别置信度以及候选字符;
步骤1.5:对票据全文字符串信息进行过滤处理,过滤处理包括:去除小计、总计、合计字符串。
进一步,步骤S2中,由于医疗票据列与列之间存在明显的特征,聚类初始化时假定k=10,即使表头存在部分干扰信息,仍能得到较好的聚类效果。聚类样本为OCR识别出的每个字符串的x中心点坐标,聚类初值为设置为10,聚类得到的结果为每个字符串所属的类标签,聚类均值为每个类对应的中心点坐标。
对票据全文字符串信息进行聚类,如图2所示,具体包括以下步骤:
步骤2.1、提取步骤S1得到的所有字符串,以每个字符串的左侧位置初始化每个字符串的向量;
步骤2.2、初始化k=10个中心点,k代表最终聚类的结果;
步骤2.3、随机选取k个点作为初始聚类中心,计算各个字符串向量到各聚类中心的距离,
其中,x、y为字符左侧位置坐标值,
步骤2.4、比较每一个字符串向量到各个聚类中心的距离,并将其划分到距离聚类中心最近的类簇中;
步骤2.5、重新计算各个聚类中心直至收敛,输出聚类结果,其目标函数公式:
其中,u
进一步,步骤S3中,根据聚类结果和OCR全文识别的数据进行列切分,即统计每列(类)数据对应的属性,属性包括中文字符个数、数字个数、个数之和。根据切分信息进行语义解析,确定标题位置信息,解析分为原始标题存在和不存在两种情况。
第一种存在标题行信息时,根据标题候选字查找标题所在位置,同时结合聚类结果进行校验,即中文字符最多的列,金额列数字比中文字符多,若关键字定位到的标题位置与聚类结果相差较大,校验对应相邻列再次进行判断;
第二种不存在标题行信息时,则根据分类属性确定项目名称和金额,其中中文字符最多的列为项目名称列,金额最大的列为金额列。另外,在进行统计时,排除小计、总计、合计带来的影响。定位出项目名称和金额位置后,对同行数据进行校验,对数字部分同行验证可得出单价或数量列。
最后,定位标题位置信息后,根据对应列信息确定标题左右边界,通过遍历对应列所有数据中最宽的条目确定,并且同时满足距离聚类中心30像素以内。
步骤S3中的确定标题位置,如图3所示,具体包括以下步骤:
步骤3.1、根据聚类结果对全文结果进行分类,并记录每类的均值;
步骤3.2、统计每类数据对应的属性,属性包括,中文字符个数、数字个数、个数之和,同时得到每列的标题关键字,用于识别该列的语义;
步骤3.3、定位全文结果的标题关键字,例如该列中包含项目名称、项目编码文字,则定义为项目名称候选列。如果该列中包含金额关键字,则定义金额候选列。通常,金额列和要远远大于单价列和。对于无法采用关键字进行语义识别的列,根据数字总和进行鉴别,区分出金额列;
步骤3.4、对于语义识别得到的列数据,根据行位置一致性进行匹配,得到每行的项目名称、金额、单价或者数量信息。
步骤S3中提取对应列所在的条目数据具体为:首先根据标题左右边界坐标信息依次取出垂直方向数据,然后根据取出的项目名称位置信息匹配垂直方向最近距离的金额信息,以取出单价或者数量,最后对于项目名称换行的数据进行判断,对于满足合并条件的数据进行合并,得到具体条目数据。
进一步,步骤S4中对条目数据进行合法性校验和匹配修正包括:
4.1、对提取条目数据的数字进行小数点位数校验,由于每列的金额、单价、数量存在小数点一致性。因此算法首先对小数点进行后面的数字进行统计,确定每列数字的精度。如果该行没有识别出小数点,则根据数字位数增加小数点,提高识别精度。如图4所示,具体为:首先,去除中文,日期,特殊字符;其次,统计此列小数点的平均出现的次数,次数大于总列数二分之一时统计小数点在字符中出现的位置(从右到左);然后,取次数的前二分之一(从大到小)的均值作为对应列小数点的位置,对缺乏小数点的数据进行填充;
4.2、如果当前行同时识别出金额、单价和数量,则进行一致性校验;如果校验不通过,则根据该字符串的识别置信度总和选择两个置信度最高的值,反算另外一个数据,保证数据一致性;
4.3、结合医疗票据语义字典和识别结果进行匹配校验,基于医疗票据语义字典(字典包含医疗特定称谓和常用组合信息),结合OCR识别的候选字符对特定称谓的数据进行纠正。
本发明结合均值聚类与OCR技术的医疗票据结构化输出的方法,将通用OCR识别技术与均值聚类方法相结合,可准确定位出标题位置,再取出对应条目数据,最后结合多重匹配规则引擎,可准确识别出项目名称,金额,单价,数量信息。本发明可以节约医疗工作人员录入时间,避免大量重复劳动的同时提高录入速度,并且本发明识别精准度高,可避免人力录入带来的错误,进而可以提高办事效率,节约社会资源。
如图5所示,本发明实施例还提供一种基于均值聚类和字符识别的医疗票据图像结构化装置,包括:
识别模块,用于对获取的医疗票据图像进行OCR字符识别,得到票据全文字符串信息;
聚类模块,用于对所述票据全文字符串信息进行KMeans聚类;
提取模块,用于根据聚类结果确定标题位置信息,根据所述标题位置信息,提取对应列所在的条目数据;
修正模块,用于对所述条目数据进行合法性校验和修正,得到所述医疗票据的结构化数据。
本发明实施例还提供一种计算机可读介质,所述计算机可读介质上存储有指令,所述指令被处理器执行时实现本发明用于基于均值聚类和字符识别的医疗票据图像结构化方法的步骤。
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。所述计算机程序产品包括一个或多个计算机指令。在计算机加载和执行所述计算机程序指令时,全部或部分地产生按照本申请实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、获取其他可编程装置。所述计算机指令可以存储在计算机可读介质中,或者从一个计算机可读介质向另一个计算机可读介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(DSL))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,DVD)、或者半导体介质(例如固态硬盘Solid State Disk(SSD))等。
专业人员应该还可以进一步意识到,结合本发明中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令处理器完成,所述的程序可以存储于计算机可读介质中,所述存储介质是非短暂性(英文:non-transitory)介质,例如随机存取存储器,只读存储器,快闪存储器,硬盘,固态硬盘,磁带(英文:magnetic tape),软盘(英文:floppy disk),光盘(英文:opticaldisc)及其任意组合。
以上所述,仅为本申请较佳的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应该以权利要求的保护范围为准。
- 一种医疗票据图像结构化方法和装置、计算机可读介质
- 一种医疗票据图像结构化方法和装置、计算机可读介质