一种基于逻辑回归模型的群控设备识别方法
文献发布时间:2023-06-19 11:19:16
技术领域
本发明属于设备识别技术领域,具体涉及一种基于逻辑回归模型的群控设备识别方法。
背景技术
随着移动技术的发展,移动应用已经渗透到人们生活的各个层面,给生活带来极大便利的同时,随之而来的应用安全隐患也对风控行业提出了新的挑战。近年来,在利益的驱使下,不法分子通过群控设备模拟人类操作行为,通过不当方式获取营销利益、或者通过机器频繁登陆试取用户账户信息,或单纯操作机器进行流量攻击,都给商家机构的移动应用运营造成了重大的安全隐患。因此,需要及时识别群控设备,实现对黑产源头的打击,以提高运营的安全性。
群控设备的识别方法主要包括基于设备信息和基于聚类模型的两类。基于设备信息的群控设备识别方法包括:通过设备指纹技术生成设备唯一标识并收集设备信息,对设备关键信息过于相似的设备群进行拦截。基于聚类模型的群控设备识别方法包括:通过无监督聚类算法对设备指纹进行直接分析,对聚集程度过高的设备群体进行识别拦截,实现对群控设备的识别。
但是,以上所述的群控设备的识别方法过于依赖风控规则的质量,无法应对新兴的设备群控技术,只能对已知的黑产技术手段进行防控,面对瞬息万变的风控大环境缺乏快速适应的能力。并且,由于无监督算法本身缺乏标签的指导,准确率较低,很难实现复杂业务场景下群控设备的准确识别;且聚类算法计算效率低,在大数据量级下无法实现实时的模型计算,方法时效性差。
发明内容
本申请提供了一种基于逻辑回归模型的群控设备识别方法。以解决现有的群控设备的识别方法适应性差,准确率低,识别效率低和时效性差的问题。
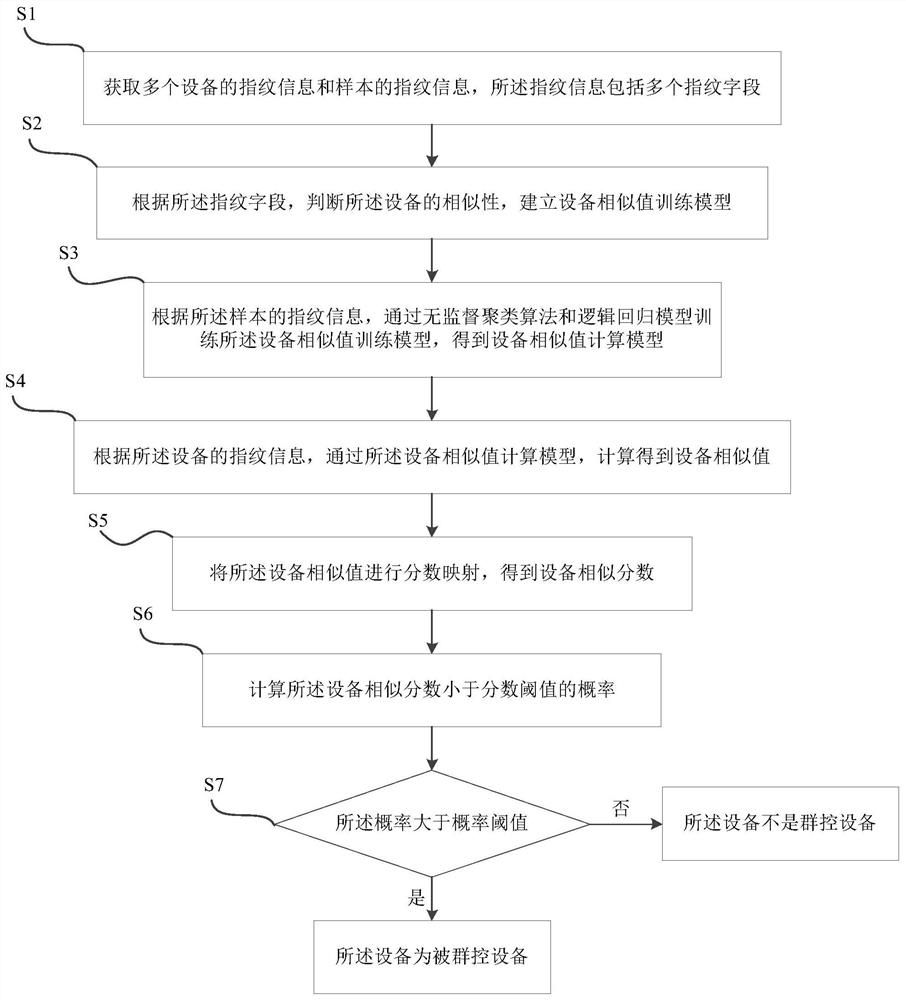
本申请提供一种基于逻辑回归模型的群控设备识别方法,包括:
获取多个设备的指纹信息和样本的指纹信息,所述指纹信息包括多个指纹字段;
根据所述指纹字段,判断所述设备的相似性,建立设备相似值训练模型;
根据所述样本的指纹信息,通过无监督聚类算法和逻辑回归模型训练所述设备相似值训练模型,得到设备相似值计算模型;
根据所述设备的指纹信息,通过所述设备相似值计算模型,计算得到设备相似值;
将所述设备相似值进行分数映射,得到设备相似分数;
计算所述设备相似分数小于分数阈值的概率;
如果所述概率大于概率阈值,则所述设备为被群控设备。
可选的,所述根据所述指纹字段,判断所述设备的相似性的方法包括:使用Levenshtein算法计算两个所述指纹字段的编辑距离。
可选的,所述建立设备相似值训练模型的公式为:
Score=W
其中,Score为两个设备的相似值,W为权重,A为一个设备的指纹字段,B为另一个设备的指纹字段,n为设备数量,Similarity()为采用Levenshtein算法计算两个指纹字段的编辑距离。
可选的,所述根据所述样本的指纹信息,通过无监督聚类算法和逻辑回归模型训练所述设备相似值训练模型,得到设备相似值计算模型的步骤包括:
根据所述样本的指纹信息,获取每一个指纹字段预设的第一基线值;
根据Levenshtein算法计算所述样本到所述第一基线值的编辑距离,得到多个第一多维数组;
通过无监督聚类算法对所述第一多维数组进行聚类分析,聚类数量最多的一组为第一聚类组;
从所述第一聚类组选取第二基线值,根据Levenshtein算法计算所述样本到所述第二基线值的编辑距离,得到多个第二多维数组;
通过所述逻辑回归模型,对所述第二多维数组进行训练,得到设备相似值计算模型。
可选的,所述逻辑回归模型的公式为:
其中,所述W为权重,x为多维数组,b为截距。
可选的,所述通过所述逻辑回归模型,对所述第二多维数组进行训练包括:根据所述逻辑回归模型,得到所述设备相似值计算模型的最佳权重值。
可选的,使用最小化损失函数计算所述设备相似值计算模型的最佳权重值。
可选的,所述通过无监督聚类算法对所述第一多维数组进行聚类分析包括:使用DBSCAN聚类算法对所述第一多维数组进行聚类分析。
可选的,所述第一基线值设置为null。
可选的,所述分数阈值设置为10,所述概率阈值设置为50%。
由以上技术方案可知,本申请提供一种基于逻辑回归模型的群控设备识别方法,包括:获取多个设备的指纹信息和样本的指纹信息,所述指纹信息包括多个指纹字段;根据所述指纹字段,判断所述设备的相似性,建立设备相似值训练模型;根据所述样本的指纹信息,通过无监督聚类算法和逻辑回归模型训练所述设备相似值训练模型,得到设备相似值计算模型;根据所述设备的指纹信息,通过所述设备相似值计算模型,计算得到设备相似值;将所述设备相似值进行分数映射,得到设备相似分数;计算所述设备相似分数小于分数阈值的概率;如果所述概率大于概率阈值,则所述设备为被群控设备。
本方法提供的基于逻辑回归模型的群控设备识别方法将无监督聚类算法和逻辑回归模型结合。通过无监督聚类算法对样本进行预分类和标签制定,为逻辑回归建模提供必要的有标签样本支持,通过对样本进行采样比对并输出相似分数,对分数列表进行分析,实现对样本中群控设备的识别。本方法提供的群控设备识别方法不依赖专家风控规则,可以对未知的黑产技术手段进行有效防控,并且群控设备识别的准确率和计算效率高。
附图说明
为了更清楚地说明本申请的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本申请提供的一种基于逻辑回归模型的群控设备识别方法的一个实施例的流程示意图;
图2为本申请提供的一种基于逻辑回归模型的群控设备识别方法中通过无监督聚类算法和逻辑回归模型训练设备相似值训练模型,得到设备相似值计算模型的一个实施例的流程示意图。
具体实施方式
下面将详细地对实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下实施例中描述的实施方式并不代表与本申请相一致的所有实施方式。仅是与权利要求书中所详述的、本申请的一些方面相一致的系统和方法的示例。
请参阅图1,图1为本申请提供的一种基于逻辑回归模型的群控设备识别方法的一个实施例的流程示意图。
本申请提供一种基于逻辑回归模型的群控设备识别方法,包括:
S1:获取多个设备的指纹信息和样本的指纹信息,所述指纹信息包括多个指纹字段。
设备指纹是指可以用于唯一标识出该设备的设备特征或者独特的设备标识。设备指纹包括一些固有的、较难篡改的、唯一的设备标识。例如,设备的硬件ID,像手机在生产过程中都会被赋予一个唯一的IMEI(International Mobile Equipment Identity)编号,用于唯一标识该台设备。像电脑的网卡,在生产过程中会被赋予唯一的MAC地址。这些设备唯一的标识符我们可以将其视为设备指纹。
同时,设备的特征集合可以用来当做设备指纹。我们将设备的名称、型号、形状、颜色、功能等各个特征结合起来用于作为设备的标识。这就类似于我们在记忆人的时候,通常是通过人的长相、面部特征来记忆。
在本实施例中,所述样本的指纹信息用于训练模型,所述设备的指纹信息用于判断设备是否是群控设备,所述每个指纹信息包括多个指纹字段,每一个指纹字段表示一个可识别的信息,例如,设备名称、设备的型号和硬件ID等。
S2:根据所述指纹字段,判断所述设备的相似性,建立设备相似值训练模型。
在本实施例中,通过判断每一个指纹字段的相似性,从而判断所述设备的相似性。可选的,所述根据所述指纹字段,判断所述设备的相似性的方法包括:使用Levenshtein算法计算两个所述指纹字段的编辑距离。
Levenshtein算法,又称编辑距离算法,指的是两个字符串之间,由一个转换成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。在本实施例中,定义Similarity()为计算两个指纹字段编辑距离的函数,例如,Similarity(iPhone7,iPhone8)=1,即iPhone7转为iPhone8至少需要1个步骤,将“7”替换为“8”。通过计算两个指纹字段的编辑距离,可以代表两个指纹字段的相似性。两个指纹字段的编辑距离越小,则两个指纹字段越相似。
可选的,所述建立设备相似值训练模型的公式为:
Score=W
其中,Score为两个设备的相似值,W为权重,A为一个设备的指纹字段,B为另一个设备的指纹字段,n为设备数量,Similarity()为采用Levenshtein算法计算两个指纹字段的编辑距离。所述设备相似值训练模型用于计算两个设备之间的相似值。
S3:根据所述样本的指纹信息,通过无监督聚类算法和逻辑回归模型训练所述设备相似值训练模型,得到设备相似值计算模型。
请参阅图2,图2为本申请提供的一种基于逻辑回归模型的群控设备识别方法中通过无监督聚类算法和逻辑回归模型训练设备相似值训练模型,得到设备相似值计算模型的一个实施例的流程示意图。
可选的,所述根据所述样本的指纹信息,通过无监督聚类算法和逻辑回归模型训练所述设备相似值训练模型,得到设备相似值计算模型的步骤包括:
S31:根据所述样本的指纹信息,获取每一个指纹字段预设的第一基线值。
在本实施例中,首先对样本的指纹信息进行无监督聚类分类,根据所述样本指纹信息的每一个指纹字段预设第一基线值,所述第一基线值作为计算所述样本的编辑距离的基准数值。
可选的,所述第一基线值设置为null。例如,将设备的版本号设置为“0000”,将设备的型号设置为“000000”。
S32:根据Levenshtein算法计算所述样本到所述第一基线值的编辑距离,得到多个第一多维数组;即每一个设备会得到一个第一多维数组。
S33:通过无监督聚类算法对所述第一多维数组进行聚类分析,聚类数量最多的一组为第一聚类组;对所述第一多维数组进行分类、制定标签。
可选的,所述通过无监督聚类算法对所述第一多维数组进行聚类分析包括:使用DBSCAN聚类算法对所述第一多维数组进行聚类分析。DBSCAN算法是一种基于密度的聚类方法。它将簇定义为密度相连的点的最大集合,能够把具有足够密度的区域划分为簇,并可以在有噪音的空间数据集中发现任意形状的簇。
DBSCAN算法的主要目标是相比基于划分的聚类方法和层次聚类方法,需要更少的领域知识来确定输入参数;发现任意形状的聚簇;在大规模数据库上更好的效率。DBSCAN能够将足够高密度的区域划分成簇,并能在具有噪声的空间数据库中发现任意形状的簇。因此,在本实施例中采用DBSCAN算法进行聚类分析,聚类结果更加准确,效果更好。将聚类数量最多的一组标记为标签“1”,即为第一聚类组。
S34:从所述第一聚类组选取第二基线值,根据Levenshtein算法计算所述样本到所述第二基线值的编辑距离,得到多个第二多维数组。
在本实施例中,从所述第一聚类组中任意选取一组多维数组作为第二基线值,即所述第二基线值为有标签的基线值,计算所述样本到所述第二基线值的编辑距离,得到多个第二多维数组。所述第二多维数组为逻辑回归模型提供了有标签的训练样本,可以提高群控设备识别的准确性。
S35:通过所述逻辑回归模型,对所述第二多维数组进行训练,得到设备相似值计算模型。逻辑回归模型又称logistic回归,是一种广义的线性回归分析模型,常用于数据挖掘以及数据分类中。
可选的,所述逻辑回归模型的公式为:
其中,所述W为权重,x为多维数组,b为截距。
可选的,所述通过所述逻辑回归模型,对所述第二多维数组进行训练包括:根据所述逻辑回归模型,得到所述设备相似值计算模型的最佳权重值。
可选的,使用最小化损失函数计算所述设备相似值计算模型的最佳权重值。
S4:根据所述设备的指纹信息,通过所述设备相似值计算模型,计算得到设备相似值。
通过已经完成训练得到的设备相似值计算模型,计算待识别的设备相似值,从而判断所述设备是否是群控设备。
S5:将所述设备相似值进行分数映射,得到设备相似分数。
在本实施例中,由于所述设备相似值为所有指纹字段编辑距离加权之后的总和,为了便于后续的统计分析,可以将所述设备相似值进行分数映射,映射到0-100分数区间内,得到设备相似分数。
S6:计算所述设备相似分数小于分数阈值的概率。
S7:如果所述概率大于概率阈值,则所述设备为被群控设备。
在本实施例中,考虑误杀代价和错放代价,设置所述分数阈值和所述概率阈值,误杀代价大则降低分数阈值和概率阈值;错放代价大则提高分数阈值和概率阈值。根据实际待检测设备情况,可以调整设置相应的分数阈值和概率阈值。分数阈值和概率阈值设置的越高,设备拦截的比例越大,即群控设备识别越严格。
可选的,所述分数阈值设置为10,所述概率阈值设置为50%。在本实施例中,提供了一种可以实现的,群控设备识别准确性较高的分数阈值和概率阈值具体数值,可以高效的识别出群控设备。
由以上技术方案可知,本申请提供一种基于逻辑回归模型的群控设备识别方法,包括:获取多个设备的指纹信息和样本的指纹信息,所述指纹信息包括多个指纹字段;根据所述指纹字段,判断所述设备的相似性,建立设备相似值训练模型;根据所述样本的指纹信息,通过无监督聚类算法和逻辑回归模型训练所述设备相似值训练模型,得到设备相似值计算模型;根据所述设备的指纹信息,通过所述设备相似值计算模型,计算得到设备相似值;将所述设备相似值进行分数映射,得到设备相似分数;计算所述设备相似分数小于分数阈值的概率;如果所述概率大于概率阈值,则所述设备为被群控设备。
本方法提供的基于逻辑回归模型的群控设备识别方法将无监督聚类算法和逻辑回归模型结合。通过无监督聚类算法对样本进行预分类和标签制定,为逻辑回归建模提供必要的有标签样本支持,通过对样本进行采样比对并输出相似分数,对分数列表进行分析,实现对样本中群控设备的识别。本方法提供的群控设备识别方法不依赖专家风控规则,可以对未知的黑产技术手段进行有效防控,并且群控设备识别的准确率和计算效率高。
本申请提供的实施例之间的相似部分相互参见即可,以上提供的具体实施方式只是本申请总的构思下的几个示例,并不构成本申请保护范围的限定。对于本领域的技术人员而言,在不付出创造性劳动的前提下依据本申请方案所扩展出的任何其他实施方式都属于本申请的保护范围。
- 一种基于逻辑回归模型的群控设备识别方法
- 一种基于特征向量和逻辑斯谛回归模型的结晶器漏钢预报方法