一种基于多级注意力机制的藏文机器阅读理解方法
文献发布时间:2023-06-19 11:26:00
技术领域
本发明涉及自然语言处理技术领域,特别涉及一种基于多级注意力机制的藏文机器阅读理解方法。
背景技术
近年来,随着信息化的快速发展,教会机器阅读和理解人类语言文本受到了越来越多的关注。机器阅读理解旨在要求机器“阅读”一篇文本内容之后,能够正确的回答出与文本相关的问题。它是衡量机器对自然语言理解程度的标准之一。机器阅读理解任务有着广泛的应用价值,例如:为搜索引擎提供更好的支持,为对话系统提供高质量的对话服务,为数字教学提供有利的问题解答服务等等。目前机器阅读理解在英语和汉语上已经取得了很大的进展,然而针对低资源语言藏文的机器阅读理解研究还处于起步阶段,其主要的原因是藏文的语法结构复杂,浅层的网络架构难以理解藏文语义信息。因此如何高效的让机器理解复杂的藏文文本是完成藏文机器阅读理解任务的主要关键。
早期由于缺乏大规模的数据集,大多数机器阅读理解系统是基于规则或统计模型,因此研究人员必须手工设计一些复杂的语法或语义规则。这些系统的精度只能达到30%-40%,因此这些成果并没有引起广泛的关注。在接下来的几十年中,随着大规模的机器阅读理解数据集的发布,基于深度学习的机器阅读理解的研究取得了一些显著的成绩。Wang等人提出Match-LSTM模型,他们分别采用长短时记忆网络对问题和短文进行编码,然后在长短时记忆网络单元中引入基于注意力的问题加权表示,较传统的特征提取方法有了一定的提升。随后,微软团队为了捕捉文章中单词之间的长期依赖关系提出了R-Net模型,这是通过引入额外的自注意力层来实现的。他们的实验结果表明通过引入自注意力机制能够提高模型的准确性。Cui等人提出了“注意力加注意力”阅读器模型,这是一种基于行和列的相结合的注意计算方法。同时为了进一步提高模型的准确性,他们采用了“N-Best”和“重新排列”的策略来验证答案。与之前的工作不同,Seo等人采用了两个方向的注意力并提出了BiDAF模型分别对文章到问题编码以及问题到文章编码两种方式去预测答案。以上研究都是基于单层的注意力机制,但是他们都忽略了藏文本身的字形和语法结构,因此在藏文机器阅读理解任务上难以有较高的表现。
发明内容
本发明的目的在于,提出将藏文的音节信息引入到词向量中,再利用多层注意力机制以精准地解决机器阅读理解问题。
为实现上述目的,本发明提供了一种基于多级注意力机制的藏文机器阅读理解方法,该方法包括以下步骤:
(1)融合藏文音节信息的文章和问题编码
为了能够融入更细粒度的藏文音节信息,同时减少藏文不正确的分词带来错误的语义信息,本发明通过对藏文文字进行音节以及词语两个不同级别的进切分,然后对音节使用高速网络进行编码,最后融入到藏文词向量中。
(2)词级别的注意力机制进行关键词搜索
为了有效的提高模型的预测答案的准确率,本发明使用一种词级别的注意力机制去关注文章中与问题相关的重点关键词。
(3)重读机制对文章的关键语义信息提取
为了预测正确答案的范围,本发明使用一种重读机制针对文章中与问题相关的关键语义信息进行搜索。
(4)自注意力机制对文章中关键信息进行再次的筛选
为了减少问题与文章之间的差异性带来的影响,本发明通过自注意力机制对编码后的文章中蕴含的答案信息进行再次搜索,从而提高模型预测答案的准确率。
(5)使用全连接网络对上述的隐变量进行解码,并对答案位置进行预测。
本发明能够解决针对藏文机器阅读理解文本信息编码中遗失音节信息的问题,以及能够精准的解决藏文机器阅读理解任务。
附图说明
图1为本发明实施例提供的一种基于多级注意力机制的藏文机器阅读理解方法流程示意图;
图2为图1所示方法的技术方案结构示意图。
具体实施例
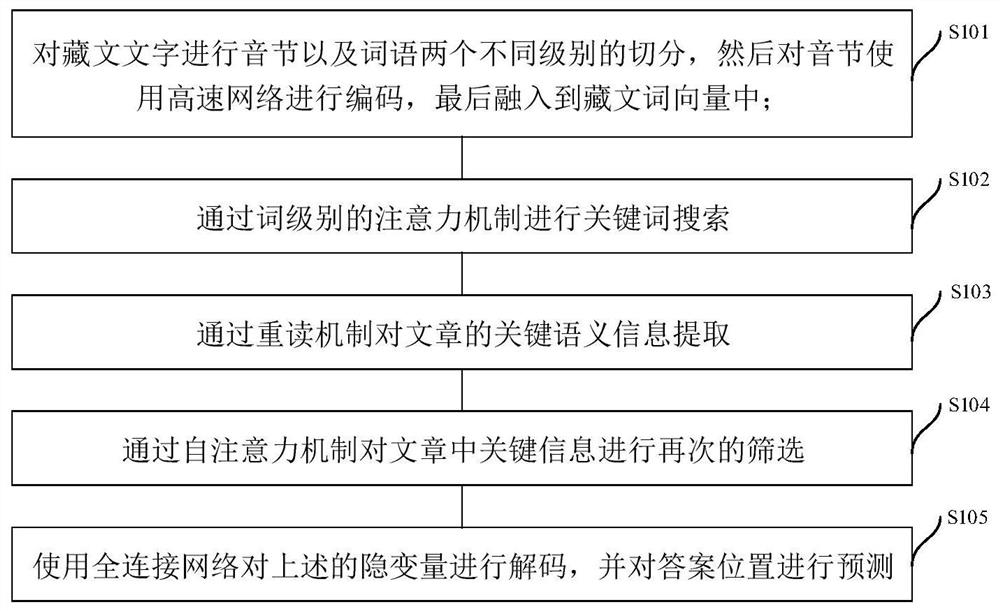
图1为本发明实施例提供的一种基于多级注意力机制的藏文机器阅读理解方法流程示意图。如图1所示,该方法包括步骤S101-S105:
步骤S101,融合音节信息的文章和问题编码
为了能够融入更细粒度的藏文音节信息,同时减少藏文不正确的分词带来错误的语义信息,本发明实施例通过对藏文文字进行音节以及词语两个不同级别的进切分,然后对音节使用高速网络进行编码,最后融入到藏文词向量中。
具体地,定义一个问题序列Q={q
步骤S102,通过词级别的注意力机制进行关键词搜索
为了有效的提高模型的预测答案的准确率,本发明实施例使用一种词级别的注意力机制(如图2所示)去关注文章中与问题相关的重点关键词。
具体地,定义通过音节编码层的文章的词嵌入表示为
a
其中,
其中,
(3)重读机制对文章的关键语义信息提取
为了预测正确答案的范围,本发明实施例使用一种重读机制针对文章中与问题相关的关键语义信息进行搜索。
具体地,重读注意力旨在计算句子级别上文章和问题之间的注意力。首先针对问题序列使用双向的长短时记忆网络去生成高级语义表示
其中
a
其中,V
这里S
其中,
(4)自注意力机制
为了减少问题与文章之间的差异性带来的影响,本发明实施例通过自注意力机制对编码后的文章中蕴含的答案信息进行再次搜索,从而提高模型预测答案的准确率。
具体地,在形式上,文章和问题不可避免地存在一些差异,这可能导致在段落和问题的交互过程中丢失部分重要的信息,从而导致答案的预测不准确。为了解决这个问题,从而引入了一种自注意机制,以便可以动态调整答案的位置。
a
其中,V
其中,
(5)答案预测
直接使用全连接网络对上述的隐变量进行解码,同时使用softmax层来实现答案位置的预测。
P
P
这里W
在一个具体的例子中,针对藏文文章段落片段(下划线
译文:植物的叶子通过
假设问题为:
植物是怎样创造氧气的?
根据上述问题及文章,基于图1所示多级注意力机制的藏文机器阅读理解方法,最终模型预测答案的起始位置P
本发明实施例的有益效果在于:
(1)能够解决针对藏文机器阅读理解文本信息编码中遗失音节信息的问题
本发明通过融合藏文音节信息,可以避免不正确的分词导致的错误语义信息,同时在编码层融入更多的藏文音节信息以提高模型的预测答案的准确率。
(2)能够精准的解决藏文机器阅读理解任务
本发明通过采用多级注意力机制使模型能够深入的理解藏文的语义信息,并在文章中查找出正确答案的起始位置。
- 一种基于多级注意力机制的藏文机器阅读理解方法
- 一种基于多头注意力机制和动态迭代的机器阅读理解方法