一种基于PYNQ框架的异构视觉目标跟踪系统及方法
文献发布时间:2023-06-19 11:29:13
技术领域
本发明属于计算机视觉目标跟踪领域,涉及一种基于PYNQ框架的异构视觉目标跟踪系统及方法。
背景技术
目标跟踪是一个融合特征提取、运动信息识别定位的交叉课题,是计算机视觉领域的重要研究方向。在图像处理分析技术、芯片技术、计算机技术快速发展的推动下,开始广泛应用于军事侦查、航天航空、公共安全等各个领域。
基于相关滤波框架的目标跟踪算法以优异的速度成为研究的热点,但由于使用HOG、CN等颜色等手工特征,对目标形变遮挡、背景复杂等场景表现不够稳健。基于深度学习的目标跟踪算法精度较高,但由于通过预训练卷积神经网络提取的深度特征,结构复杂计算量巨大,直接影响算法的实时性。
在实际研究与应用场合中,对硬件的性能资源以及软件的算法优化提出了更高的要求。传统的目标跟踪方案很难适应复杂多变场景的视频图像序列目标跟踪任务。相关滤波类算法精度较低,而深度学习类算法速度较慢,需要达到稳健性与实时性的平衡。
发明内容
本发明的目的在于克服上述技术缺陷,提出了一种基于PYNQ框架的异构视觉目标跟踪系统及方法,融合深度卷积特征的相关滤波目标跟踪算法,部署在基于PYNQ框架的ZYNQ异构加速平台,达到稳健性与实时性的平衡。
为了实现上述目的,本发明提出了一种基于PYNQ框架的异构视觉目标跟踪系统,所述系统包括设置在PS上的目标跟踪主控模块和设置在PL上的特征提取运算加速模块;PS和PL之间采用AXI接口和DMA通道实现控制流与数据流的交互通路;
所述目标跟踪主控模块,用于系统初始化配置、视频图像序列载入,对所述特征提取运算加速模块的调用与通信、响应图的显示和目标位置的输出;
所述特征提取运算加速模块,用于对目标进行特征提取,然后将特征图在频域内与目标模型进行互相关计算,进而计算最大响应,通过数据交互通路将计算结果回传至所述目标跟踪主控模块。
作为上述系统的一种改进,所述目标跟踪主控模块的具体实现过程为:
进行系统初始化配置,设定相关参数,载入视频图像序列以及第一帧目标位置,建立高斯回归标签,通过汉宁窗去除边界效应;
加载深度卷积网络预训练模型VGG-Net-19,将视频图像序列输入所述特征提取运算加速模块,提取多层深度卷积特征;
若为第一帧,频域进行核自相关计算,进而得到岭回归分类参数,进行快速训练,同时对目标模型进行更新;
若为后续帧,根据前一帧目标区域提取图像区域特征,然后将特征在频域内与目标模型进行互相关计算,进而计算最大响应;
根据所述特征提取运算加速模块返回的运算结果,通过傅里叶反变换求出当前帧相对于前一帧目标的位移,输出目标位置;
根据训练结果,计算三个置信度评估指标,根据结果判断是否有遮挡,如有遮挡,将当前模板备份,对目标位置进行自适应更新,对目标模型进行更新。
作为上述系统的一种改进,所述特征提取运算加速模块包括:一个控制单元、一组输入缓冲区、一组输出缓冲区、一组特征图缓冲区以及一组由多个处理单元构成的运算阵列;
所述控制单元,用于从外部获取指令并对其进行解码、计算前配置、记录、分发正确的信息以及运算过程各单元的信息交互;
所述输入缓冲区包括:图像缓冲、权值缓冲和偏置缓冲,用于将从外部存储器中载入的图像、权值、偏置数据缓存到片上再送至运算阵列中;
所述输出缓冲区,用于将中间结果和最终运算结果传输保存到外部存储器中,供PS访问获取;
所述特征图缓冲区,用于缓存若干行图像数据;
所述运算阵列,用于实现卷积运算。
作为上述系统的一种改进,所述控制单元包括:核心配置子单元、权重地址配置子单元、偏置地址配置子单元、特征图地址配置子单元;
所述核心配置子单元,用于控制权重地址配置子单元、偏置地址配置子单元、特征图地址配置子单元之间的协同工作;
所述权重地址配置子单元,用于向所述特征提取运算加速模块发送、存储所需权重数据存放地址;
所述偏置地址配置子单元,用于向所述特征提取运算加速模块发送、存储所需偏置数据存放地址;
所述特征图地址配置子单元,用于向所述特征提取运算加速模块发送、存储所需特征图中间计算数据存放地址。
作为上述系统的一种改进,所述运算阵列由8×8个并行运算的处理单元组成,每个处理单元完成尺寸为3×3的卷积运算。
作为上述系统的一种改进,所述处理单元包括:卷积计算器组、加法器树、非线性子单元和最大池化子单元;
所述卷积计算器组,用于进行多个并行卷积计算;
所述加法器树,用于对所有的卷积结果进行求和;
所述非线性子单元,用于将非线性激活函数应用于输入数据流;
所述最大池化子单元,使用行缓冲区相同结构,用于以特定窗口输入数据流并输出最大值;
本发明还提出一种基于PYNQ框架的异构视觉目标跟踪方法,基于上述的系统实现,所述方法包括以下步骤:
所述PS使用Python调用Overlay函数完成PL的比特流动态加载与配置;
所述PS使用Python调用Xlnk函数,进行片外存储器DDR4中物理地址连续的空间锁定、图像数据、权值参数存储操作;
所述目标跟踪主控模块进行系统初始化配置,载入视频图像序列,调用所述特征提取运算加速模块;
所述特征提取运算加速模块对载入的视频图像序列进行特征提取,然后将特征图在频域内与目标模型进行互相关计算,进而计算最大响应,通过数据交互通路将计算结果回传至所述目标跟踪主控模块;
所述目标跟踪主控模块根据计算结果,通过最大响应计算出目标当前位置。
本发明的优点在于:
1、本发明的系统具有通用性强、执行效率高,便于开发与移植;
2、本发明融合深度卷积特征的相关滤波目标跟踪算法,部署在基于PYNQ框架的ZYNQ异构加速平台,达到稳健性与实时性的平衡。
附图说明
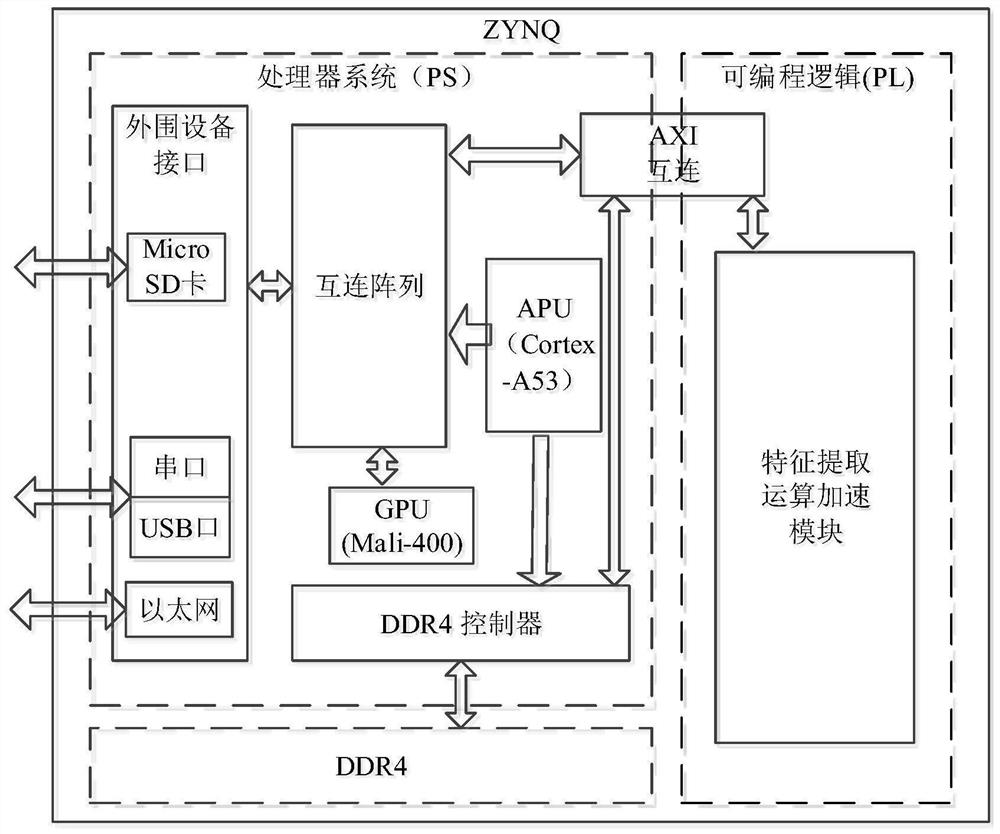
图1是本发明异构目标跟踪系统总体设计框图;
图2是本发明异构目标跟踪系统算法流程图;
图3是本发明特征提取运算加速模块的结构框图;
图4是本发明特征提取运算加速模块中运算阵列中的处理单元结构图。
具体实施方式
下面结合附图对本发明的技术方案进行详细说明。
为实现上述目的,本发明基于软硬件协同设计的思想,算法部分主要采用C/C++语言、硬件加速部分采用Verilog/VHDL语言,属于电子信息行业软硬件的实质设计标准。系统实现采用异构架构平台,在ZYNQ子系统PS部分基于PYNQ框架以软件形式运行目标跟踪算法的主体软件,在ZYNQ子系统PL部分搭建加速片上系统,执行运算密集的深度卷积特征提取环节,通过AXI总线完成控制流与数据流的交互。
本发明提出了一种基于PYNQ框架的异构视觉目标跟踪系统,该系统包括Jupyter子系统和ZYNQ子系统以及USB接口、以太网接口、Micro SD卡等若干外设。
Jupyter子系统实现网络搭建、Jupyter笔记本的运行、顶层Python程序调用。
ZYNQ子系统集成了处理器部分PS和可编程逻辑部分PL,二者之间采用AXI接口和DMA通道实现控制流与数据流的交互通路,完成目标跟踪算法的实现。PL部分包括特征提取运算加速模块。特征提取运算加速模块包括:一个控制单元、一组输入缓冲区、一组输出缓冲区、一组特征图缓冲区以及一组由多个处理单元构成的运算阵列。USB接口实现ZYNQ比特文件的加载。以太网接口通过与Jupyter子系统的连接,完成片上系统的远程访问与显示以及数据传输。Micro SD卡加载PYNQ镜像文件,引导Linux系统正常启动,同时提供数据存储空间。在PS上设置目标跟踪主控模块,用于系统初始化配置、视频图像序列载入,对所述特征提取运算加速模块的调用与通信、响应图的显示和目标位置的输出。
PYNQ是一种开源开发框架,提供标准的可以约束芯片I/O引脚的“Overlay”比特流,利用Python对FPGA进行编程开发。本发明提出一种融合深度卷积特征的相关滤波目标跟踪算法,部署在基于PYNQ框架的ZYNQ异构加速平台。
图1为本发明的系统总体设计框图,该系统的工作流程包括以下步骤:
S01:通过Micro SD卡中的PYNQ镜像引导Linux系统启动,打开Web浏览器通过Jupyter远程登录板卡,初始化外设驱动程序;
S02:使用Python调用Overlay函数完成比特流的动态加载,配置PL结构;
S03:使用Python调用Xlnk函数在PS外搭的DDR4中锁定物理地址连续的空间来存储数据将图像数据、权值参数;
S04:PS内的目标跟踪主控模块收到图像后进行相关操作,调用PL的特征提取运算加速模块进行并行计算;
S05:PL进行并行加速运算,完毕后,将结果通过AXI返回至PS进行后续算法环节的运算;
S06:PS运行软件算法,直至跟踪结束,在Jupyter笔记本中显示系统运行的代码及其生成的图形。
图2为S04中相关的算法流程图,包括以下步骤:
S04-1)初始化:开始进行初始化配置,设定相关参数。载入视频图像序列,建立高斯回归标签,通过汉宁窗去除边界效应;
S04-2)特征提取:加载深度卷积网络预训练模型VGG-Net-19,将视频图像序列输入,提取Conv3_4、Conv4_4和Conv5_4的多层深度卷积特征;
S04-3)训练:频域进行核自相关计算,进而得到岭回归分类参数,快速训练。若为第一帧,则提供岭回归参数与特征矩阵作为目标模型。训练过程进行自相关运算生成跟踪模板;
S04-4)检测:根据前一帧目标区域提取图像区域特征,然后将特征在频域内与目标模型进行互相关计算,进而计算最大响应,通过傅里叶反变换求出当前帧相对于前一帧目标的位移,输出目标位置。检测过程则进行互相关计算完成模板匹配;
S04-5)模型更新:根据训练结果,计算三个置信度评估指标,根据结果判断是否有遮挡,如有遮挡,将当前模板备份,对目标的位置进行自适应更新对目标模型进行在线更新。
特征提取运算加速模块的设计
由于深度特征提取涉及的网络结构庞大、参数占用空间大、计算重复性高、耗时多,为了对异构跟踪系统进行加速,使算法更高效地映射到硬件架构,需要针对影响实时因素的瓶颈进行优化,对算法实现的架构与细节反复修改、调整,最终达到与软件算法的数据结构相当的硬件电路实现结构,提取出信息丰富的多层深度卷积特征图,层次化地构造目标外观模型。
1总体设计
针对目标跟踪算法的特征提取运算加速模块主要通过PL部分实现计算,整体设计如图3所示,主要包括一个控制单元(Controller)、一组输入缓冲区(InputBuffers)、一组输出缓冲区(Output Buffers)、一组特征图缓冲区(Feature map Buffers)以及一组由多个处理单元(Processing Element)构成的运算阵列。
控制单元包括核心配置子单元、权重地址配置子单元、偏置地址配置子单元、特征图地址配置子单元。负责从外部获取指令并对其进行解码、计算前配置、记录、分发正确的信息以及运算过程中模块间的交互。
输入缓冲区包括图像、权值、偏置缓冲。由于片上资源的限制,数据从外部存储器中载入,缓存到片上缓存器再送至运算阵列中。输出缓冲区将中间结果和最终运算结果传输保存到外部存储中,供PS端访问获取。
特征图缓冲区利用FPGA能进行流水线运算的特点,使用片上BRam缓存若干行图像数据。
处理单元构成的运算阵列是整个硬件架构的核心,实现卷积运算、池化运算。为满足数据并行性设置8×8个并行PE阵列单元以及特征图缓冲区组成,单个PE完成尺寸为3×3的卷积运算。PE使能设置一些PE单元处于闲置状态,节省资源占用。
2并行模式分析
卷积计算过程需要大量的计算资源,其本质为乘累加运算。设每层的特征图维度为M
MAC=K
单层的权重参数个数为:
N
MAC的计算量繁重,权重参数以及特征图的占用空间巨大,因此需将网络拆分依次循环优化映射至FPGA实现。
由于卷积神经网络的相关性决定层与层之间存在数据依赖,底层的输出结果是上层的输入数据,这使得层间并行的开发难度大大增加,一般主要从整体架构实现上提高运算性能。而卷积层内主要有以下几种并行特征:
1、特征图释放窗口内部并行计算:选定卷积核C1,特征图I1释放一个与卷积核同样尺寸的窗口W1,则C1与W1进行卷积运算,相应的乘法计算可以并行执行;
2、特征图释放窗口之间并行计算:选定卷积核C1,特征图I1释放若干个与卷积核同样尺寸的窗口如W1、W2等,则C1与W1、W2之间的卷积运算可以并行执行;
3、卷积核之间并行计算:选定卷积核C1、C2,特征图I1释放一个与卷积核同样尺寸的窗口W1,则C1、C2与W1之间的卷积运算可以并行执行;
4、原始输入图像或者特征图之间的并行计算:选定卷积核C1、C2,特征图I1、I2,则C1与W1、C2与W2之间的卷积运算可以并行执行;
本发明采取卷积核内并行、卷积核间并行以及特征图间并行的方案,利用VGG-Net中运算相似度高的特点,将硬件资源同时实现单层卷积网络的运算,反复调用实现整个卷积模型的运算。并针对反复读取数据降低运算速度的弊端以及分布不均浪费资源的问题,提出优化方案。
3运算阵列设计
运算阵列是整个特征提取运算加速模块的核心部分,每个PE功能独立,结构相同。处理单元结构如图4,包括卷积计算器、加法器树、非线性子单元、最大池化子单元。
卷积计算器使用经典的行缓冲器结构。行缓冲区在输入图像上释放一个窗口选择函数,然后是乘法器和加法器树,每个周期计算一次卷积结果。
乘法操作通过DSP单元进行快速的实现,具体由定点乘法器模块DSP48E2在一个时钟周期内完成一个乘法累加算法。行缓冲处理延时固定,例如3×3进行处理,结果延时是两行图像的时间。
加法器树对所有的卷积结果进行求和。非线性子单元将非线性激活函数应用于输入数据流。最大池化子单元使用行缓冲区相同结构,以特定窗口输入数据流并输出最大值。
具体实现如下:
首先接收输入缓冲区分发的特征图、权重、参数等数据;
接着在各个处理单元内部以卷积计算器组进行特征图释放窗口内部、特征图释放窗口之间、卷积核之间、原始输入图像或者特征图之间的卷积操作;
然后通过加法器树对相应的卷积结果进行求和;
最后输入非线性子单元进行非线性激活,经由最大池化子单元输出最大值。
4计算精度优化
在FPGA上使用浮点数格式的数据参与运算会严重影响速度,需要对网络的数据进行数据量化,在保持较高的精度的前提下,可以降低模型参数文件在内存中的占用空间,同时可以优化计算资源,从而提高运行速度、降低功耗。在FPGA中一般通过三个DSP单元完成算法中权值为32浮点数的一次乘加操作。研究发现16位浮点数并未损耗权值信息,但极大地提升了网络运算速度。因此本发明硬件设计中采用16比特进行数据量化,减少位宽。
系统工作流程
异构目标跟踪系统部署在ZYNQ实现,从总体层面将系统拆分为控制与运算两大部分。控制部分涵盖配置、寻址、通信等较为复杂的操作,可以通过以ARM为核心的片内SoC(Processing System,PS)实现;而运算部分涉及数据庞大,重复性高的简单计算,可以通过并行度高的FPGA(Programmable Logic,PL)实现。二者之间采用AXI接口和DMA通道实现控制流与数据流的交互通路。
PL的主体部分为特征提取运算加速模块IP核。为了支持特征提取运算加速模块IP核的工作,需要进行片上系统的搭建。首先配置PS运行所需的硬件设备及参数;其次为IP核提供工作时钟、控制指令信号、数据输入接口等;然后实现PS-PL间高效稳定协同工作的AXI总线通信;最后完成片上系统的搭建之后,导出硬件配置文件,进行PYNQ框架应用层开发与硬件协处理器调用。
生成特征提取运算加速模块IP核后,创建比特流文件,将其集成到PYNQ架构,形成硬件协处理器。通过API提取硬件详细信息,在Jupyter中通过Python编程直接调用PL中的特征提取运算加速模块IP核,实现并行计算加速等功能。
最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
- 一种基于PYNQ框架的异构视觉目标跟踪系统及方法
- 基于生物社会力的异构无人机集群目标跟踪系统及方法