一种基于噪声建模的盲去噪方法
文献发布时间:2023-06-19 11:29:13
技术领域
本发明属于图像处理与识别方法技术领域,涉及一种基于噪声建模的盲去噪方法。
背景技术
图像是人类获取信息的主要介质。然而,图像在生成和传输阶段会由于种种因素导致含有噪声从而质量变差,这对信息的处理、传输和存储造成极大的影响。噪声的种类有很多,如:白噪声、加性噪声、乘性噪声等等。为了抑制噪声,改善图像质量,以便于后续处理,必须对图像进行去噪。
目前在噪声去除领域已经有许多高效的方法,不过这些方法大都建立在噪声类型、噪声水平已知的基础上。但是在真实图片中,噪声类型以及水平都是未知的,噪声在理论上可以定义为“一种不可预测,只能用概率统计方法来认识的随机误差”,这极大的影响了噪声的去除。因此关于图像的盲去噪成为了一个迫在眉睫的问题。
发明内容
本发明的目的是提供一种基于噪声建模的盲去噪方法,该方法通过将含未知类型、未知强度噪声的真实图片输入深度神经网络进行处理以得到不含噪声的干净图像。
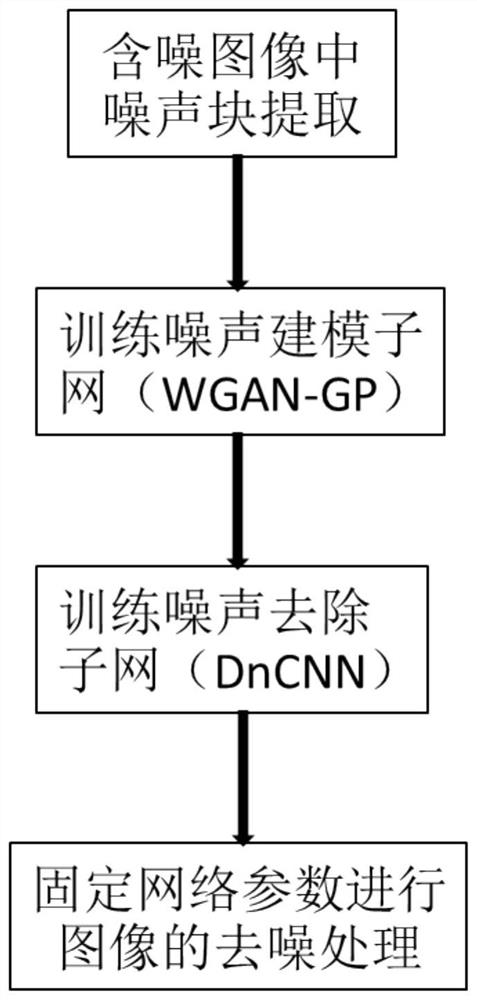
本发明所采用的技术方案是,一种基于噪声建模的盲去噪方法,具体包括如下步骤:
步骤1,提取噪声图像上的噪声块,并根据噪声块训练噪声建模子网生成噪声样本;
步骤2,根据步骤1生成的噪声样本构造成对的训练数据集,然后再利用生成的训练数据集训练去噪子网;
步骤3,通过固定训练好的噪声建模子网和去噪子网的网络参数,将含噪声的图像输入到去噪子网中进行处理,从而得到不含噪声的图像。
本发明的特点还在于:
步骤1的具体过程为:
步骤1.1,提取噪声图像上的噪声块;
假设所处理的图像都具有相同未知类型的零均值噪声,步骤1.1的具体过程为:
步骤1.1.1,假设p
步骤1.1.2,利用步长S
步骤1.1.3,通过如下公式(1)、(2)判断m个全局块p
|Mean(q
|Var(q
式中,Mean(q
当同时满足公式(1)、(2)时,则视全局块p
V
其中,S
步骤1.1.4,令i∈(1,t),得到噪声块V
步骤1.2,利用步骤1.1所提取出的噪声块集合训练噪声建模子网生产噪声样本,具体过程为:
步骤1.2.1,搭建噪声建模子网WGAN-GP;
步骤1.2.2,利用步骤1.2.1搭建好的噪声建模子网对步骤1得到的噪声块集合V进行训练,得到训练后的噪声块集合V′。
步骤1.2.1中噪声建模子网WGAN-GP的网络结构包括生成器网络和判别器网络。
步骤1.2.2的具体过程为:
设WGAN-GP网络的损失函数如下公式(4)所示:
其中,p
步骤2的具体过程为:
步骤2.1,建立训练去噪子网的数据集,具体为:
将一组无噪图像分割成大小为d×d的图像块,形成集合X={x
步骤2.2,利用步骤2.1建立好的数据集对去噪子网进行训练。
步骤2.1中,集合X与集合V′的结合方式为,利用加性噪声的产生公式,如下公式(5)所示:
y
其中,y
步骤2.2中去噪子网的网络结构为:输入为含噪图像y
十七个单元的具体结构为:输入第一个单元,采用3×3的卷积核进行卷积处理,然后生成64个特征映射,然后利用ReLU激活函数进行激活输入下一单元;第二至第十五单元结构相同,具体为:首先将输入使用3×3的卷积核进行卷积处理,然后进行批量归一化,最后利用ReLU激活函数进行激活输入下一单元;最后一个单元仅使用3×3的卷积核进行卷积处理,进行重建输出;
其中,ReLU激活函数的具体形式为:max(0,x)。
步骤2.2中对去噪子网进行训练的具体过程为:
首先定义目标损失函数如下公式(7)所示:
其中,θ是网络参数,N是训练数据的大小;
设置初始学习率为a,采用SGD优化器训练50个epoch,得到训练完成后的去噪子网。
步骤3的具体过程为:
通过固定训练好的噪声建模子网和去噪子网的网络参数,将需要处理的图像输入到去噪子网中,获得图像中包含的隐含噪声R,然后利用公式(6),获得干净的无噪图像。
本发明的有益效果如下:
1.本发明考虑了一种新颖的“光滑面片”提取方法,有助于从真实图片中提取噪声块;
2.本发明针对盲去噪问题难以对噪声进行建模,提出了采用一种新颖的WGAN-GP网络从而生成一定数量的噪声块,以更好的对“盲去噪”问题中的噪声进行建模;
3.本发明的网络结构由两部分组成:噪声建模子网和去噪子网。得益于噪声建模子网的引入能够使我们对未知类型的噪声进行处理,从而达到一定程度上的“盲去噪”;
4.本发明针对网络结构设置了特定的损失函数,在去除图像噪声的同时保留了一定程度的图像细节。
附图说明
图1是本发明一种基于噪声建模的盲去噪方法的流程图;
图2是本发明一种基于噪声建模的盲去噪方法的结构图;
图3是本发明一种基于噪声建模的盲去噪方法中噪声建模子网的结构图;
图4是本发明一种基于噪声建模的盲去噪方法中噪声去除子网的结构图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明一种基于噪声建模的盲去噪方法,具体包括如下步骤:在训练网络的过程中,我们采用了目前较为流行的几个数据集作为我们的样本,其中包括BSD68、DND、NIGHT等几个数据集;如图1、2所示:
步骤1,提取噪声图像上的噪声块,并根据噪声块训练噪声建模子网生成噪声样本;
步骤1的具体过程为:
步骤1.1,提取噪声图像上的噪声块;
假设所处理的图像都具有相同未知类型的零均值噪声,步骤1.1的具体过程为:
步骤1.1.1,假设p
步骤1.1.2,利用步长S
步骤1.1.3,通过如下公式(1)、(2)判断m个全局块p
|Mean(q
|Var(q
式中,Mean(q
当同时满足公式(1)、(2)时,则视全局块p
V
其中,S
步骤1.1.4,令i∈(1,t),得到噪声块V
目前,可以较为轻易地获得高分辨率图像,这些图像中含有大量符合条件的光滑区域,如:天空、墙壁等。因此我们可以通过以上算法获得足够的光滑面片从而得到足够的噪声块以用来训练我们的噪声建模子网;
步骤1.2,利用步骤1.1所提取出的噪声块集合训练噪声建模子网生产噪声样本,本发明采用GAN网络的改进版WGAN-GP作为噪声建模子网,网络的结构示意图如图3所示;将步骤1.1中获得的噪声块集合V={v
构建一个由五个单元组成的生成器网络,具体组成为:输入→第一单元(批量归一化处理后利用ReLU激活函数进行激活后输入下一层)→第二单元(利用5×5的卷积核进行跨步卷积然后进行批量归一化最后利用ReLU激活函数进行激活后输入下一层)→第三单元(利用5×5的卷积核进行跨步卷积然后进行批量归一化最后利用ReLU激活函数进行激活后输入下一层)→第四单元(利用5×5的卷积核进行跨步卷积然后进行批量归一化最后利用ReLU激活函数进行激活后输入下一层)→第五单元(利用5×5的卷积核进行跨步卷积然后利用TanH激活函数进行激活后输出)
构建一个同样由五个单元组成的判别器网络,具体组成为:输入→第一单元(用5×5的卷积核进行卷积然后利用Leaky ReLU激活函数激活后输入下一层)→第二单元(利用5×5的卷积核进行卷积然后进行批量归一化,最后利用Leaky ReLU激活函数激活后输入下一单元)→第三单元(利用5×5的卷积核进行卷积然后进行批量归一化,最后利用LeakyReLU激活函数激活后输入下一单元)→第四单元(利用5×5的卷积核进行卷积然后进行批量归一化,最后利用Leaky ReLU激活函数激活后输入下一单元)→第五单元(利用logisticregression逻辑回归单元来判断概率)
在这里,ReLU激活函数为:max(0,x);TanH激活函数为:
将生成器网络和判别器网络组合成我们的噪声建模子网WGAN-GP,然后进行训练,在该网络中将损失函数设置为,如下公式(4)所示:
其中,p
步骤2,根据步骤1生成的噪声样本构造成对的训练数据集,然后再利用生成的训练数据集训练去噪子网;
步骤2的具体过程为:
步骤2.1,建立训练去噪子网的数据集,具体为:
将一组无噪图像分割成大小为d×d的图像块,形成集合X={x
步骤2.1中,集合X与集合V′的结合方式为,利用加性噪声的产生公式,如下公式(5)所示:
y
其中,y
步骤2.2,利用步骤2.1建立好的数据集对去噪子网进行训练。
本发明中去噪子网采用与DnCNN类似的网络结构,通过输入成对的训练集{X,Y}学习X和Y之间的映射关系获取复原后的图像
具体的网络如下:该子网的输入为含噪图像y
图像去噪子网的17个子单元具体为:输入第一个单元,采用3×3的卷积核进行卷积处理,然后生成64个特征映射,然后利用ReLU激活函数进行激活输入下一单元;第二至第十五单元结构相同,具体为将输入首先使用3×3的卷积核进行卷积处理,然后进行批量归一化最后利用ReLU激活函数进行激活输入下一单元;最后一个单元只使用3×3的卷积核进行卷积处理,用于重建输出。此网络的卷积核大小都为3×3并去除了所有的池化层。在这里ReLU激活函数的具体形式为:max(0,x)。我们将目标损失函数定义为:
其中,θ是网络参数,N是训练数据的大小。
设置初始学习率为a,采用SGD优化器训练50个epoch,得到训练完成后的去噪子网。
步骤2.2中去噪子网的网络结构为:输入为含噪图像y
十七个单元的具体结构为:输入第一个单元,采用3×3的卷积核进行卷积处理,然后生成64个特征映射,然后利用ReLU激活函数进行激活输入下一单元;第二至第十五单元结构相同,具体为:首先将输入使用3×3的卷积核进行卷积处理,然后进行批量归一化,最后利用ReLU激活函数进行激活输入下一单元;最后一个单元仅使用3×3的卷积核进行卷积处理,进行重建输出;
其中,ReLU激活函数的具体形式为:max(0,x)。
步骤2.2中对去噪子网进行训练的具体过程为:
首先定义目标损失函数如下公式(7)所示:
其中,θ是网络参数,N是训练数据的大小;
设置初始学习率为a,采用SGD优化器训练50个epoch,得到训练完成后的去噪子网。
步骤3,通过固定训练好的噪声建模子网和去噪子网的网络参数,将含噪声的图像输入到去噪子网中进行处理,从而得到不含噪声的图像。
步骤3的具体过程为:
通过固定训练好的噪声建模子网(WGAN-GP)和去噪子网(DnCNN)的网络参数,将需要处理的图像输入到去噪子网中,获得图像中包含的隐含噪声R,然后利用公式(6),获得干净的无噪图像。
- 一种基于噪声建模的盲去噪方法
- 一种基于噪声注意力的高光谱遥感图像盲去噪方法