人机对抗分布式训练系统和方法
文献发布时间:2023-06-19 11:29:13
技术领域
本申请涉及多智能体人机对抗领域,尤其涉及人机对抗分布式训练系统和方法。
背景技术
人机对抗作为人工智能的试金石,已经成为国内外智能领域的研究热点。随着AlphaGo、AlphaStar、OpenAI Five等人机对抗系统的成功,深度强化学习技术成为一种有希望实现认知智能的关键技术,在决策领域将发挥重要的作用。考虑到目前博弈对抗系统多以红蓝双方进行对抗,如兵棋推演,且深度强化学习过程往往没有高水平人类数据作为指导,如何进行红蓝博弈人机对抗训练成为迫切需要解决的关键问题。
公开号为CN108921298A,公开了一种强化学习多智能体沟通与决策方法,包括:根据各个智能体的观测状态信息通过神经网络提取相应的状态特征;将所有智能体的状态特征作为沟通信息输入至VLAD层中进行软分配与聚类,得到聚类后的沟通信息;将聚类后的沟通信息分发给各个智能体,由各个智能体将自身的状态特征与接收到的聚类后的沟通信息进行聚合,并通过智能体内部的全连接神经网络进行动作决策。
公开号为CN112132263A,公开了一种基于强化学习的多智能体自主导航方法,属于多智能体强化学习领域。本发明通过长短时记忆网络将环境历史状态编码为系统的隐状态特征向量,并将编码后的系统隐状态作为智能体的策略网络以及动作评价网络的输入,从而使得智能体的策略网络和动作评价网络都能基于环境全局的信息工作,使得智能体的策略更加鲁棒。
目前,通过红蓝自博弈不断迭代成为一种解决人机对抗中深度强化学习训练的有效手段,然而如何针对博弈对抗环境,设计大规模分布式训练系统与方法,进而完成红蓝博弈人机对抗中的智能体训练仍然是一个亟需解决的关键问题。
发明内容
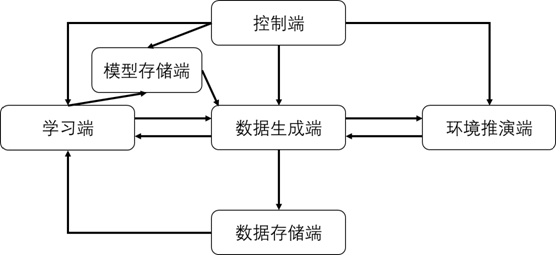
有鉴于此,本发明第一方面提供人机对抗分布式训练系统,包括:控制端、训练端、数据生成端、环境推演端、数据存储端以及模型存储端,所述系统可以同时进行红方智能体与蓝方智能体的分布式训练;
所述控制端负责启动训练、对手模型选择、终止训练;系统配置初始化后,则可以由控制端发出命令,启动训练,选择对手模型,所述终止训练时间提前设定;设定所述终止训练时间的具体方法为:设置运行固定时间段或通过设定模型存储端存储红方智能体与蓝方智能体的模型代数上界实现;
所述训练端负责从所述数据存储端提取训练数据并基于强化学习算法进行决策网络的训练和参数更新;所述训练端负责将训练更新的参数传递给所述数据生成端;所述训练端负责将待保存的参数传递给所述模型存储端;所述决策网络的训练和参数更新采用强化学习算法actor-critic算法进行训练参数更新;所述训练参数包括:决策网络参数与值网络参数,决策网络和值网络结构相同,由卷积神经网络、全连接神经网络与长短期记忆网络组成;应用所述值网络的输出值构成损失函数,采用策略梯度下降算法进行策略网络参数更新;
所述数据生成端负责从所述训练端和所述模型存储端提取决策网络参数,从所述环境推演端提取状态特征,并基于所述决策网络的参数生成动作;所述数据生成端负责将训练数据传递给数据存储端;
所述环境推演端负责接收所述数据生成端传递的动作进行仿真环境推演;所述环境推演端负责将仿真环境推演产生的状态特征以及奖赏信息传递给数据生成端;所述环境推演端由大量并行运行的仿真环境组成;奖赏信息为仿真环境进行推演后由仿真环境返回,代表环境执行完动作到下一个状态后环境对该动作的反馈;
所述数据存储端负责保存从所述数据生成端传递的数据和将数据传递给所述训练端;
所述模型存储端负责保存所述训练端保存的决策网络参数,构成模型集合和将决策网络参数传递给数据生成端。
优选的,所述对手模型选择的具体方法为:针对红方智能体则以等概率方式选择蓝方智能体模型集合中的模型,针对蓝方智能体则以等概率方式选择红方智能体模型集合中的模型,当对手模型集合的模型数量发生变化时,对选择的概率进行对应调整;等概率方式即对手模型集合中的模型以相等的概率进行采样作为当前仿真环境的对手模型。
优选的,所述训练数据的基本形式为:
优选的,所述状态特征包括:智能体的属性值和地图信息。
地图信息为录入了以智能体为中心的所在环境的地形信息和视野信息;所述属性值为血量、装甲类型。
优选的,所述值网络的输出值构成损失函数的具体形式为,以下以红方为例:
其中,
M:训练数据的大小。
优选的,所述策略梯度下降算法进行策略网络参数更新的具体公式为:
其中,
优选的,所述设定所述终止训练时间的具体方法为:设置运行固定时间段,以智能体训练次数为基准,所述训练次数为,10
优选的,所述数据存储端由两个队列组成,分别存储红方智能体的训练数据和蓝方智能体的训练数据;当队列存储满时,训练端进行对应红蓝智能体训练,待训练结束后对队列清空。
优选的,所述模型存储端由两个列表组成,分别存储红方智能体模型与蓝方智能体模型,依据固定时间间隔进行训练端模型拉取与存储;
所述系统配置初始化为:初始化红方智能体策略网络并设置为当前红方的策略网络、初始化蓝方智能体策略网络并设置为当前蓝方的策略网络;初始化数据存储端红方数据收集列表、蓝方数据收集列表;初始化模型存储端红方模型存储列表、蓝方模型存储列表;初始化环境推演端推演环境并将一半推演环境设定为用于红方策略训练,一半推演环境设定用于蓝方策略训练。
本发明第二方面提供人机对抗分布式训练方法,包括:
S1:训练端得到训练数据后,控制端启动红方智能体与蓝方智能体训练,选择对手模型,设定对手模型选择方式为等概率选择;设定终止训练时间;
具体地,初始化红方智能体策略网络并设置为当前红方的策略网络、初始化蓝方智能体策略网络并设置为当前蓝方的策略网络;初始化数据存储端红方数据收集列表、蓝方数据收集列表;初始化模型存储端红方模型存储列表、蓝方模型存储列表;初始化环境推演端推演环境并将一半推演环境设定为用于红方策略训练,一半推演环境设定用于蓝方策略训练;
S2:红方智能体采集训练数据、进行强化学习训练并保存模型;
S21:环境推演端依据等概率方式选择模型存储端中蓝方模型存储列表中的蓝方模型作为对手;
S22:将当前环境红方状态特征送入数据生成端的当前红方的决策网络得到红方当前状态对应的动作输出,将当前环境蓝方状态特征送入对手决策网络得到蓝方对应状态的动作输出,合并红方动作与蓝方动作构成联合动作;
S23:环境推演端接收红方与蓝方联合动作进行一步环境前向推演,并将下一步红方与蓝方状态特征以及红方奖赏返回,并传递给数据生成端;
S24:数据生成端将前环境红方状态特征、下一步红方与蓝方状态特征以及红方奖赏返回传递给数据存储端;
S25:重复步骤S22-S24 n次,得到红方智能体采集训练数据,存入数据存储端的红方数据收集列表;
S26:训练端从所述数据存储端提取训练数据,进行一次红方当前决策网络的参数更新与值网络的参数更新;
S27:清空数据存储端的红方数据收集列表;
S28:重复S22-S27过程m次完成一个版本红方策略网络的更新,并将所述红方策略网络保存至模型存储端红方模型存储列表;
S3:蓝方智能体采集训练数据、进行强化学习训练并保存模型;
S31:环境推演端依据等概率方式选择模型存储端中红方模型存储列表中的红方模型作为对手;
S32:将当前环境蓝方状态特征送入数据生成端的当前蓝方的决策网络得到蓝方当前状态对应的动作输出,将当前环境红方状态特征送入对手决策网络得到红方对应状态的动作输出,合并蓝方动作与红方动作构成联合动作;
S33:环境推演端接收蓝方与红方联合动作进行一步环境前向推演,并将下一步蓝方与红方状态特征以及蓝方奖赏返回,并传递给数据生成端;
S34:数据生成端将前环境蓝方状态特征、下一步蓝方与红方状态特征以及蓝方奖赏返回传递给数据存储端;
S35:重复步骤S32-S34 n次,得到蓝方智能体采集训练数据,存入数据存储端的蓝方数据收集列表;
S36:训练端从所述数据存储端提取训练数据,进行一次蓝方当前决策网络的参数更新与值网络的参数更新;
S37:清空数据存储端的蓝方数据收集列表;
S38:重复S32-S37过程m次完成一个版本蓝方策略网络的更新,并将所述蓝方策略网络保存至模型存储端蓝方模型存储列表;
S4:进行红方智能体与蓝方智能体持续训练直至到达终止训练时间,迭代完成;
S5:控制端终止训练。
本申请实施例提供的上述技术方案与现有技术相比具有如下优点:
通过该红蓝博弈人机对抗分布式训练系统,我们进行了连级兵棋水网稻田想定下的红方与蓝方智能体训练,最终获得的红方智能体策略集合与蓝方智能体策略集合达到了优秀级人类选手兵棋推演水平。
附图说明
图1为本发明实施例提供的人机对抗分布式训练系统框架图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本发明相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本发明的一些方面相一致的装置和方法的例子。
实施例1:
如图1所示本申请实施例提供的人机对抗分布式训练系统,包括:
控制端、训练端、数据生成端、环境推演端、数据存储端以及模型存储端,所述系统可以同时进行红方智能体与蓝方智能体的分布式训练;
所述控制端负责启动训练、对手模型选择、终止训练;系统配置初始化后,则可以由控制端发出命令,启动训练,选择对手模型,所述终止训练时间提前设定;设定所述终止训练时间的具体方法为:设置运行固定时间段或通过设定模型存储端存储红方智能体与蓝方智能体的模型代数上界实现;所述对手模型选择的具体方法为:针对红方智能体则以等概率方式选择蓝方智能体模型集合中的模型,针对蓝方智能体则以等概率方式选择红方智能体模型集合中的模型,当对手模型集合的模型数量发生变化时,对选择的概率进行对应调整;等概率方式即对手模型集合中的模型以相等的概率进行采样作为当前仿真环境的对手模型;
隔一段时间会保存红方和蓝方模型,作为对手模型,因为保存了新的模型,集合大小发生变化,这个时候训练时,就要对环境中的对手模型重新选择,这样才能选到新的对手模型,选择方式可以是等概率,就是每个模型被选到的概率一样;
所述设定所述终止训练时间的具体方法为:设置运行固定时间段,以智能体训练次数为基准,所述训练次数为,10
所述训练端负责从所述数据存储端提取训练数据并基于强化学习算法进行决策网络的训练和参数更新;所述训练端负责将训练更新的参数传递给所述数据生成端;所述训练端负责将待保存的参数传递给所述模型存储端;所述决策网络的训练和参数更新采用强化学习算法actor-critic算法进行训练参数更新;所述训练参数包括:决策网络参数与值网络参数,决策网络和值网络结构相同,由卷积神经网络、全连接神经网络与长短期记忆网络组成;应用所述值网络的输出值构成损失函数,采用策略梯度下降算法进行策略网络参数更新;
所述训练数据的基本形式为:
所述状态特征包括:智能体的属性值、位置信息和地图信息;地图信息为录入了以智能体为中心的所在环境的地形信息和视野信息;所述属性值为血量、装甲类型;
所述值网络的输出值构成损失函数的具体形式为,以下以红方为例:
其中,
M:训练数据的大小;
所述策略梯度下降算法进行策略网络参数更新的具体公式为:
其中,
所述数据生成端负责从所述训练端和所述模型存储端提取决策网络参数,从所述环境推演端提取状态特征,并基于所述决策网络的参数生成动作;所述数据生成端负责将训练数据传递给数据存储端;
数据生成的时候需要拉取当前训练方的参数做前向,同时使用对手模型的参数做前向,这样才能生成红蓝双方的动作让环境推演;
所述环境推演端负责接收所述数据生成端传递的动作进行仿真环境推演;所述环境推演端负责将仿真环境推演产生的状态特征以及奖赏信息传递给数据生成端;环境每推演一步都会返回奖赏信息;所述环境推演端由大量并行运行的仿真环境组成;奖赏信息为仿真环境进行推演后由仿真环境返回,代表环境执行完动作到下一个状态后环境对该动作的反馈;
所述数据存储端负责保存从所述数据生成端传递的数据和将数据传递给所述训练端;所述数据存储端由两个队列组成,分别存储红方智能体的训练数据和蓝方智能体的训练数据;当队列存储满时,训练端进行对应红蓝智能体训练,待训练结束后对队列清空;
所述模型存储端负责保存所述训练端保存的决策网络参数,构成模型集合和将决策网络参数传递给数据生成端;
所述模型存储端由两个列表组成,分别存储红方智能体模型与蓝方智能体模型,依据固定时间间隔进行训练端模型拉取与存储;
所述系统配置初始化为:初始化红方智能体策略网络并设置为当前红方的策略网络、初始化蓝方智能体策略网络并设置为当前蓝方的策略网络;初始化数据存储端红方数据收集列表、蓝方数据收集列表;初始化模型存储端红方模型存储列表、蓝方模型存储列表;初始化环境推演端推演环境并将一半推演环境设定为用于红方策略训练,一半推演环境设定用于蓝方策略训练。
实施例2:
根据上述人机对抗分布训练系统,提供一种人机对抗分布式训练方法,包括:
S1:训练端得到训练数据后,控制端启动红方智能体与蓝方智能体训练,选择对手模型,设定对手模型选择方式为等概率选择;设定终止训练时间;
具体地,初始化红方智能体策略网络并设置为当前红方的策略网络、初始化蓝方智能体策略网络并设置为当前蓝方的策略网络;初始化数据存储端红方数据收集列表、蓝方数据收集列表;初始化模型存储端红方模型存储列表、蓝方模型存储列表;初始化环境推演端推演环境并将一半推演环境设定为用于红方策略训练,一半推演环境设定用于蓝方策略训练;
S2:红方智能体采集训练数据、进行强化学习训练并保存模型;
S21:环境推演端依据等概率方式选择模型存储端中蓝方模型存储列表中的蓝方模型作为对手;
S22:将当前环境红方状态特征送入数据生成端的当前红方的决策网络得到红方当前状态对应的动作输出,将当前环境蓝方状态特征送入对手决策网络得到蓝方对应状态的动作输出,合并红方动作与蓝方动作构成联合动作;
S23:环境推演端接收红方与蓝方联合动作进行一步环境前向推演,并将下一步红方与蓝方状态特征以及红方奖赏返回,并传递给数据生成端;
S24:数据生成端将前环境红方状态特征、下一步红方与蓝方状态特征以及红方奖赏返回传递给数据存储端;
S25:重复步骤S22-S24 n次,得到红方智能体采集训练数据,存入数据存储端的红方数据收集列表;
S26:训练端从所述数据存储端提取训练数据,进行一次红方当前决策网络的参数更新与值网络的参数更新;
S27:清空数据存储端的红方数据收集列表;
S28:重复S22-S27过程m次完成一个版本红方策略网络的更新,并将所述红方策略网络保存至模型存储端红方模型存储列表;
S3:蓝方智能体采集训练数据、进行强化学习训练并保存模型;
S31:环境推演端依据等概率方式选择模型存储端中红方模型存储列表中的红方模型作为对手;
S32:将当前环境蓝方状态特征送入数据生成端的当前蓝方的决策网络得到蓝方当前状态对应的动作输出,将当前环境红方状态特征送入对手决策网络得到红方对应状态的动作输出,合并蓝方动作与红方动作构成联合动作;
S33:环境推演端接收蓝方与红方联合动作进行一步环境前向推演,并将下一步蓝方与红方状态特征以及蓝方奖赏返回,并传递给数据生成端;
S34:数据生成端将前环境蓝方状态特征、下一步蓝方与红方状态特征以及蓝方奖赏返回传递给数据存储端;
S35:重复步骤S32-S34 n次,得到蓝方智能体采集训练数据,存入数据存储端的蓝方数据收集列表;
S36:训练端从所述数据存储端提取训练数据,进行一次蓝方当前决策网络的参数更新与值网络的参数更新;
S37:清空数据存储端的蓝方数据收集列表;
S38:重复S32-S37过程m次完成一个版本蓝方策略网络的更新,并将所述蓝方策略网络保存至模型存储端蓝方模型存储列表;
S4:进行红方智能体与蓝方智能体持续训练直至到达终止训练时间,迭代完成;
S5:控制端终止训练。
实施例3:
步骤S1,训练端得到训练数据后,控制端启动红方智能体与蓝方智能体训练,选择对手模型,设定对手模型选择方式为等概率选择;设定终止训练时间;
具体地,初始化红方智能体策略网络并设置为当前红方的策略网络、初始化蓝方智能体策略网络并设置为当前蓝方的策略网络;初始化数据存储端红方数据收集列表、蓝方数据收集列表;初始化模型存储端红方模型存储列表、蓝方模型存储列表;初始化环境推演端推演环境并将一半推演环境设定为用于红方策略训练,一半推演环境设定用于蓝方策略训练,需要注意的是每个环境初始化后将返回红方状态特征与蓝方状态特征,即第0步;
步骤S2,红方智能体收集数据、进行强化学习训练并保存模型,具体地,
S2-1,环境推演端包含256个兵棋推演环境,其中1-128编号的连级兵棋推演环境中每一个环境都依据等概率方式选择模型存储端中蓝方模型存储列表中的蓝方模型作为对手;
S2-2,对于上述1-128编号的其中一个环境,将当前环境红方状态特征送入当前红方的决策网络得到红方当前状态对应的动作输出,将当前环境蓝方状态特征送入对手决策网络得到蓝方对应状态的动作输出,合并红方动作与蓝方动作构成联合动作;
S2-3,对于红方所有环境(1-128编号)重复S2-2过程;
S2-4,环境推演端接收红方与蓝方联合动作进行一步环境前向推演,并将下一步红方与蓝方状态特征以及红方奖赏返回,并传递给数据生成端;
S2-5,上述S2-2到S2-4过程重复128次,可以得到128个具有128轨迹长度的训练数据
S2-6,将上述数据存入数据存储端红方数据收集列表;
S2-7,上述S2-2到S2-6重复2次直到收集一定数量的训练数据,即256个具有128轨迹长度的训练数据;
S2-8,训练端从数据存储端拉取上述数据,进行一次红方当前决策网络与值网络参数更新;
所述值网络的输出值构成损失函数的具体形式为,以下以红方为例:
其中,
M:训练数据的大小;
所述策略梯度下降算法进行策略网络参数更新的具体公式为:
其中,
S2-9,清空数据存储端红方数据收集列表;
S2-10,重复S2-2到S2-9过程10
步骤S3,蓝方智能体收集数据、进行强化学习训练并保存模型,具体地,
S3-1,环境推演端包含256个兵棋推演环境,其中129-256编号的兵棋推演环境中每一个环境都依据等概率方式选择模型存储端中红方模型存储列表中的红方模型作为对手;
S3-2,对于上述129-256编号的其中一个环境,将当前环境蓝方状态特征送入当前蓝方的决策网络得到蓝方当前状态对应的动作输出,将当前环境红方状态特征送入对手决策网络得到红方对应状态的动作输出,合并蓝方动作与红方动作构成联合动作;
S3-3,对于蓝方所有环境(129-256编号)重复S3-2过程;
S3-4,环境推演端接收蓝方与红方联合动作进行一步环境前向推演,并将下一步蓝方与红方状态特征以及蓝方奖赏返回,并传递给数据生成端;
S3-5,上述S3-2到S3-4过程重复128次,可以得到128个具有128轨迹长度的训练数据
S3-6,将上述数据存入数据存储端蓝方数据收集列表;
S3-7,上述S3-2到S3-6重复2次直到收集一定数量的训练数据,即256个具有128轨迹长度的训练数据;
S3-8,训练端从数据存储端拉取上述数据,进行一次蓝方当前决策网络与值网络参数更新;
S3-9,清空数据存储端蓝方数据收集列表;
S3-10,重复S3-2到S3-9过程10
步骤S4,进行红方智能体与蓝方智能体持续训练直至到达终止训练时间,迭代完成;
具体地,S2与S3同步进行,不区分顺序。值得注意的是,当S2与S3重复若干次如32次,可以认为红方智能体与蓝方智能体训练完成,获得红方智能体策略集合与蓝方智能体策略集合。
步骤S5,控制端终止训练。
具体地,控制端终止红方智能体与蓝方智能体训练,命令发送至训练端、数据生成端与环境推演端,关闭所有进程。
应当理解,尽管在本发明可能采用术语第一、第二、第三等来描述各种特征,但这些特征不应限于这些术语。这些术语仅用来将同一类型的特征彼此区分开。例如,在不脱离本发明范围的情况下,第一特征也可以被称为第二特征,类似地,第二特征也可以被称为第一特征。取决于语境,如在此所使用的词语“如果”可以被解释成为“在……时”或“当……时”或“响应于确定”。
虽然本说明书包含许多具体实施细节,但是这些不应被解释为限制任何发明的范围或所要求保护的范围,而是主要用于描述特定发明的具体实施例的特征。本说明书内在多个实施例中描述的某些特征也可以在单个实施例中被组合实施。另一方面,在单个实施例中描述的各种特征也可以在多个实施例中分开实施或以任何合适的子组合来实施。此外,虽然特征可以如上所述在某些组合中起作用并且甚至最初如此要求保护,但是来自所要求保护的组合中的一个或多个特征在一些情况下可以从该组合中去除,并且所要求保护的组合可以指向子组合或子组合的变型。
类似地,虽然在附图中以特定顺序描绘了操作,但是这不应被理解为要求这些操作以所示的特定顺序执行或顺次执行、或者要求所有例示的操作被执行,以实现期望的结果。在某些情况下,多任务和并行处理可能是有利的。此外,上述实施例中的各种系统模块和组件的分离不应被理解为在所有实施例中均需要这样的分离,并且应当理解,所描述的程序组件和系统通常可以一起集成在单个软件产品中,或者封装成多个软件产品。
由此,主题的特定实施例已被描述。其他实施例在所附权利要求书的范围以内。在某些情况下,权利要求书中记载的动作可以以不同的顺序执行并且仍实现期望的结果。此外,附图中描绘的处理并非必需所示的特定顺序或顺次顺序,以实现期望的结果。在某些实现中,多任务和并行处理可能是有利的。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围之内。
- 人机对抗分布式训练系统和方法
- 一种无人机机载雷达对抗模拟训练系统及训练方法