基于概念词的文本聚类方法
文献发布时间:2023-06-19 11:29:13
技术领域
本发明涉及自然语言处理技术领域,特别涉及基于概念词的文本聚类方法。
背景技术
文本聚类(Text clustering)主要是依据的是著名的聚类假设:同类的文档(即文本)相似度较大,而不同类的文档相似度较小。作为一种无监督的机器学习方法,由于聚类不需要训练过程,以及不需要预先对文档进行类别的手工标注,因此具有一定的灵活性和较高的自动化处理能力,聚类已经成为对文本进行有效地组织、摘要以及导航的重要手段。
常规的文本聚类方法通过将文本映射成向量后,再进行相似度比较,这样聚类出来的文本类别存在不好解释的问题,缺乏说服力。
发明内容
本发明的目的在于对需要聚类的文本进行高效的聚类,让聚类结果更有解释性,提高聚类说服力,提供一种基于概念词的文本聚类方法。
为了实现上述发明目的,本发明实施例提供了以下技术方案:
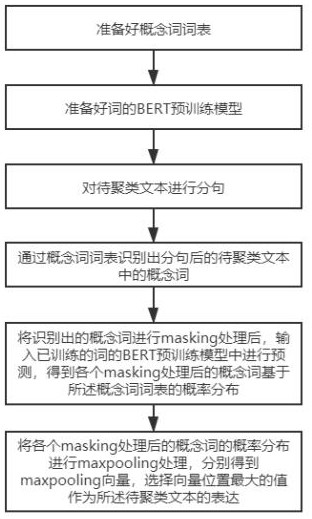
基于概念词的文本聚类方法,包括以下步骤:
对待聚类文本进行分句,通过概念词词表识别出分句后的待聚类文本中的概念词;所述概念词词表中包含若干概念词和若干类别,所述类别的数量小于等于所述概念词的数量;
将识别出的概念词进行masking处理后,输入已训练的词的BERT预训练模型中进行预测,得到各个masking处理后的概念词基于所述概念词词表的概率分布;
将各个masking处理后的概念词的概率分布进行maxpooling处理,分别得到maxpooling向量,选择位置最大值的向量作为所述待聚类文本的表达。
在上述方案中,依据概念词对聚类结果进行解释,使得聚类更有解释性,提高说服力。
所述待聚类文本为文字表达的信息,包括文章、新闻、文字材料、文字作品。
所述概念词词表通过人工添加、参考维基百科title的方式整理而成。
所述对待聚类文本进行分句的步骤,包括:根据标点符号对待聚类文本进行分句;所述标点符号包括句号、感叹号、问号。
所述通过概念词词表识别出分句后的待聚类文本中的概念词的步骤,包括:分别对分句后的每一句待聚类文本匹配概念词词表,若待聚类文本中具有与概念词词表中相同的概念词,则将该概念词识别出来。
在对所述待聚类文本进行概念词识别时,可将待聚类文本中不属于所述概念词词表的名词作为概念词添加至概念词词表中。
所述将识别出的概念词进行masking处理后,输入已训练的词的BERT预训练模型中进行预测,得到各个masking处理后的概念词基于所述概念词词表的概率分布的步骤,包括:
将识别出的概念词进行masking处理后,得到概念词对应的符号;
将符号输入已训练的词的BERT预训练模型中进行预测,得到该符号在所述概念词词表中的概率分布;
根据待聚类文本识别出的概念词在所述概念词词表中的概率分布,概率大的部分概念词则为该待聚类文本的概率描述。
将向量位置最大的值的向量进行K-means聚类,完成对所述待聚类文本的聚类。
与现有技术相比,本发明的有益效果:
本方案通过人工经验和利用维基百科整理好的概念词对聚类结果进行解释,让文本的聚类结果更有解释性。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍, 应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
图1为本发明文本聚类方法流程图。
具体实施方式
下面将结合本发明实施例中附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。同时,在本发明的描述中,术语“第一”、“第二”等仅用于区分描述,而不能理解为指示或暗示相对重要性,或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。
实施例1:
本发明通过下述技术方案实现,如图1所示,一种基于概念词的文本聚类方法,包括以下步骤:
步骤S1:准备好概念词词表。
所述概念词词表通过人工添加、参考维基百科title的方式整理而成。
比如根据当前任务的需求,通过人工添加概念词,这些概念词用来描述文本的主题概念。由于人工添加概念词不完整或有缺失,同时对维基百科上的中文标题(即title)进行选择,从而将人工添加的概念词和选择的维基百科title整理为概念词词表,因此所述概念词词表中包含了若干概念词。
作为举例,例如维基百科中有一句“小明买了特斯拉”,其中“特斯拉”有专门的页面对其进行描述,则将“特斯拉”这个title加入在概念词词表中。在选择维基百科title时,也要根据当前任务的需求进行选择。
在比如“特斯拉”、“奔驰”等概念词属于“汽车品牌”的类别,因此所述概念词词表中还包括若干类别,类别和概念词为相互对应的关系。在概念词词表中一个类别可以对应一个或多个概念词,因此类别的数量小于等于概念词的数量。
维基百科(Wikipedia)又称为“百科全书”,由世界各地的不同语言创建而成,基于wiki技术,提供了一个动态、可自由访问和编辑的全球知识库。
步骤S2:准备好词的BERT预训练模型。
目前的BERT预训练模型一般是基于字的,而本方案采用的BERT预训练模型是基于词的。基于词的预训练模型可以是自己训练而成的,也可以使用开源的模型,比如Wors_BERT预训练模型。
BERT预训练模型是谷歌公司发布的基于双向Transformer的大规模预训练语言模型,能够分别捕捉词语和句子级别的表示,高效抽取文本信息并应用于各种NLP任务。本方案对词的BERT预训练模型进行训练的过程属于现有技术,故不对其具体的训练过程进行赘述。
步骤S3:对待聚类文本进行分句。
所述待聚类文本为文字表达的信息,包括文章、新闻、文字材料、文字作品。
将待聚类文本按照标点符号进行分句,比如待聚类文本中有这样一段话“我们都知道,宇宙浩瀚无穷。但我们朝任何一个方向望去时,宇宙最遥远的可见区域大约在460亿光年之外。”,通过标点符号“。”、“!”、“
“我们都知道,宇宙浩瀚无穷。”
“但我们朝任何一个方向望去时,宇宙最遥远的可见区域大约在460亿光年之外。”
步骤S4:通过概念词词表识别出分句后的待聚类文本中的概念词。
分别对分句后的每一句带聚类文本匹配概念词词表,若待聚类文本中具有与概念词词表中相同的概念词,则将该概念词识别出来。比如分句后的文本“但我们朝任何一个方向望去时,宇宙最遥远的可见区域大约在460亿光年之外。”,若概念词词表中有“光年”这个概念词,则将“光年”识别出来:
“但我们朝任何一个方向望去时,宇宙最遥远的可见区域大约在460亿*光年*之外。”
作为优化的实施方式,为了弥补所述概念词词表的不足,在对待聚类文本中的概念词进行识别时,可以根据需求将待聚类文本中不属于概念词词表的名词加入概念词词表,作为概念词进行识别。比如准备的概念词词表中没有“宇宙”一词,则在识别步骤中,可以将“宇宙”加入概念词词表进行识别:
“但我们朝任何一个方向望去时,*宇宙*最遥远的可见区域大约在460亿*光年*之外。”
因此,一个待分类文本中可能存在一个或多个概念词,通常情况下,都是被识别有多个概念词。
步骤S5:将识别出的概念词进行masking处理后,输入已训练的词的BERT预训练模型中进行预测,得到各个masking处理后的概念词基于所述概念词词表的概率分布。
将步骤S4中从待聚类文本中识别出来的概念词进行masking处理后,形成概念词对应的符号,将符号输入步骤S2中已训练好的词的BERT预训练模型中进行预测,得到该符号在所述概念词词表中的概率分布,该步骤可以看做对待聚类文本的概率描述。根据待聚类文本识别出的概念词在所述概念词词表中的概率分布,概率大的概念词则为该待聚类文本的概率描述。
比如“但我们朝任何一个方向望去时,*宇宙*最遥远的可见区域大约在460亿*光年*之外。”中“宇宙”和“光年”分别以符号w1、w2表示,将符号w1、w1输入词的BERT预训练模型中,即可对这两个符号位进行概率预测,预测这两个符号位分别在所述概念词词表中的概率。假设现在概念词词表中有100个概念词,则可预测出在“宇宙”中分别出现这100个概念词的概率,即是一个100维的向量。那么可以通过概念词的概率来反应句子描述的内容,如给出的“宇宙”、“光年”这类词的概率偏大,可以看出这段话更多的在描述天文学相关的内容,因此可以对待聚类文本进行概率描述。
步骤S6:将各个masking处理后的概念词的概率分布进行maxpooling处理,分别得到maxpooling向量,选择向量位置最大值的向量作为所述待聚类文本的表达。
将待聚类文本中的所有masking处理后的概念词的概率分布进行maxpooling处理,得到代表该待聚类文本的向量。比如“但我们朝任何一个方向望去时,*宇宙*最遥远的可见区域大约在460亿*光年*之外。”在步骤S5中会生成两个100维的向量,将这两个向量进行maxpooling处理后,会根据这另个maxpooling向量选择向量位置最大的值作为该句的向量,那么整个待聚类文本中向量位置最大的值即作为该待聚类文本的表达。
步骤S7:将向量位置最大的值的向量进行K-means聚类,完成对所述待聚类文本的聚类。
通过K-means聚类算法进行聚类,聚类完成后,得到聚类文本,聚类文本中有概念词,且概念词有对应的类别,所以可以对聚类有一定的解释性。
实施例2:
作为举例,比如现有一段待聚类文本经过分句后为“|词1|词2|概念词3|词4|词5|词6|词7|名词8|词9|概念词10|词11|词12|”,通过概念词词表的识别后,可以看出其中有概念词3、概念词10,并且需要名词8,因此将概念词3、概念词10、名词8一起进行masking处理并输入词的BERT预训练模型进行预测,分别得到概率分布。然后将概率分布进行maxpooling处理,得到三个maxpooling向量,选择其中向量位置值最大的向量作为该待聚类文本的表达。
可见,本方案可以不限于文本的领域或类别,可支持若干种类别的文本聚类,从而对文字表达的信息进行聚类。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
- 基于概念词的文本聚类方法
- 一种基于同义词词林语义相似度的文本聚类方法