对抗样本的生成方法和装置
文献发布时间:2023-06-19 11:29:13
技术领域
本说明书一个或多个实施例涉及电子信息技术,尤其涉及对抗样本的生成方法和装置。
背景技术
对抗样本指的是经过微小调整就可以让机器学习算法输出错误结果的一种输入样本。比如,在图像识别中,原始图像为数字“7”的图像,经过添加噪声扰动后,识别模型对扰动后的图像错误地分类为“2”,这个添加噪声扰动后的图像就是对抗样本。
对抗样本可用于模型的增强训练,以提升模型的鲁棒性。因此,需要一种更为有效地对抗样本的生成方法。
发明内容
本说明书一个或多个实施例描述了对抗样本的生成方法和装置,能够更为有效地生成对抗样本。
根据第一方面,提供了一种对抗样本的生成方法,包括:
获取原始样本;
根据所述原始样本,得到至少两个原始向量;
从所述至少两个原始向量中选择出待扰动向量;
对待扰动向量添加对抗扰动,得到扰动向量;
在预先设置的向量池中检索与扰动向量相近似的向量;其中,所述向量池中包括根据各历史原始样本得到的各历史原始向量;
根据检索到的相近似的向量,得到对抗样本。
其中,所述样本对应于指定业务类型;
所述向量池中包括的各历史原始向量是根据对应所述指定业务类型的各历史原始样本得到的。
其中,所述对待扰动向量添加对抗扰动,包括:
得到待扰动向量在一个维度上对应的扰动值;
将待扰动向量在该维度上的数值增加或者减少预定倍数的该维度对应的扰动值。
其中,得到待扰动向量在一个维度上对应的扰动值,包括如下中的至少一项:
随机生成待扰动向量的一个维度对应的扰动值;
得到模型所使用的梯度函数的方向向量,将该方向向量在一个维度上的数值作为所述待扰动向量在该维度上对应的扰动值;其中,所述模型为所述原始样本和所述对抗样本训练的模型。
其中,所述在预先设置的向量池中检索与扰动向量相近似的向量包括:
利用simHash算法,KNN算法或KDTree算法,在预先设置的向量池中检索与扰动向量相近似的向量。
其中,所述与扰动向量相近似的向量满足如下中的至少一种:
与扰动向量的欧式距离小于预设距离值;所述预设距离值为正整数;
与扰动向量的余弦距离大于预设角度值;
与扰动向量的杰卡德相似系数大于预设系数值;
不等于待扰动向量。
其中,所述根据检索到的相近似的向量得到对抗样本,包括:
利用本次检索到的相近似的向量,得到相似样本;
将所述相似样本输入模型中,得到第一识别结果;
判断所述第一识别结果与将所述原始样本输入所述模型时得到的第二识别结果之间的差异是否满足对抗要求;
如果否,返回执行所述对待扰动向量添加对抗扰动的步骤至所述判断的步骤,直至判断结果为是;
如果是,则将本次检索到的向量确定为对抗向量;
利用对抗向量生成对抗样本。
其中,
所述样本为文本数据;
所述向量对应的文本数据的粒度为:字符、n-gram片段、词或者句子。
根据第二方面,提供了一种对抗样本的生成装置,包括:
输入模块,被配置为获取原始样本;
向量转换模块,被配置为根据所述原始样本,得到至少两个原始向量;
扰动处理模块,被配置为从所述至少两个原始向量中选择出待扰动向量;对待扰动向量添加对抗扰动,得到扰动向量;
对抗样本确定模块,被配置为在预先设置的向量池中检索与扰动向量相近似的向量;其中,所述向量池中包括根据各历史原始样本得到的各历史原始向量;根据检索到的相近似的向量,得到对抗样本。
其中,所述扰动处理模块被配置为执行:
得到待扰动向量在一个维度上对应的扰动值;
将待扰动向量在该维度上的数值增加或者减少预定倍数的该维度对应的扰动值。
其中,所述扰动处理模块被配置为执行如下中的至少一项:
随机生成待扰动向量的一个维度对应的扰动值;
得到模型所使用的梯度函数的方向向量,将该方向向量在一个维度上的数值作为所述待扰动向量在该维度上对应的扰动值;其中,所述模型为所述原始样本和所述对抗样本训练的模型。
其中,所述对抗样本确定模块被配置执行:
利用本次检索到的相近似的向量,得到相似样本;
将所述相似样本输入模型中,得到第一识别结果;
判断所述第一识别结果与将所述原始样本输入所述模型时得到的第二识别结果之间的差异是否满足对抗要求;
如果否,返回执行所述对待扰动向量添加对抗扰动的步骤至所述判断的步骤,直至判断结果为是;
如果是,则将本次检索到的向量确定为对抗向量;
利用对抗向量生成对抗样本。
根据第三方面,提供了一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现本说明书任一实施例所述的方法。
本说明书实施例提供的对抗样本的生成方法和装置,预先设置有向量池,该向量池中包括各历史原始向量,且该各历史原始向量是根据历史实际存在的各原始样本得到的,因此,向量池中的向量能对应出一个实际存在的文本数据,比如一个实际存在的词汇,而不会对应一个不存在的文本数据,这样,在对原始向量进行扰动得到了扰动向量之后,不是直接利用扰动向量来得到对抗样本,而是在向量池中检索出该扰动向量相近似的向量,该检索出的向量因为与扰动向量相近似,因此满足对抗要求,同时,该检索出的向量因为能对应出一个实际存在的文本数据,因此,也满足真实性要求,即可能会在后续的攻击行为中出现,利用此种检索到的相近似的向量则能够更为有效地得到对抗样本。
附图说明
为了更清楚地说明本说明书实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本说明书的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本说明书一个实施例中对抗样本的生成方法的流程图。
图2是本说明书一个实施例中对抗样本的生成方法的示意图。
图3是本说明书一个实施例中对抗样本生成装置的结构示意图。
具体实施方式
在现有技术中,在生成对抗样本时,通常都是采用梯度扰动的对抗方案。即为了训练一个模型,朝该模型的损失函数梯度下降的方向调整参数,以便不断优化模型。对应的,对抗样本则是通过朝损失函数梯度上升的方向微调原始样本,从而起到以微小的扰动造成对模型结果较大的影响,达到对抗目的。
然而,现有技术采用上述梯度扰动的方式来生成对抗样本时,所产生的对抗样本的有效性较差,从而无法对模型进行更好的增强训练。
以训练的样本为文本数据为例,来说明现有技术方法的缺点。比如,因为文本空间与图像连续的像素空间不同,一个原始样本比如一个文章的一个词“转账”在转换为向量A后,在向量空间是离散的、没有连续性,对原始样本转换出的向量A进行梯度扰动后,扰动得到的扰动向量A’可能会无法还原到文本空间,即扰动向量A’无法对应出一个真实存在的词汇,可见,利用此种方式生成对抗样本,无法满足真实性要求,不会出现在实际的攻击行为中,因此无法更好地对模型进行增强训练。
为了解决现有技术的问题,就需要让生成的对抗样本满足真实性的要求,可能会出现在实际的攻击行为中。
下面描述以上构思的具体实现方式。
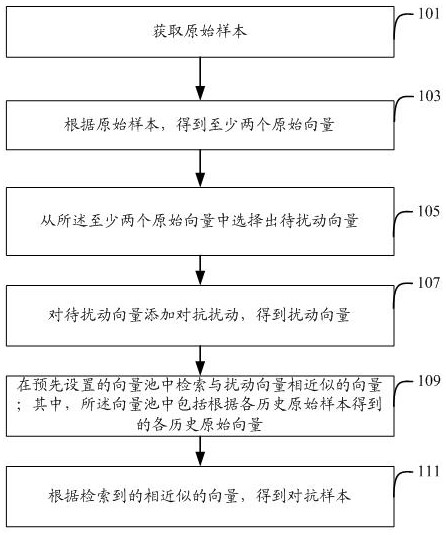
图1示出了本说明书一个实施例中对抗样本的生成方法的流程图。该方法的执行主体为对抗样本的生成装置。可以理解,该方法也可以通过任何具有计算、处理能力的装置、设备、平台、设备集群来执行。参见图1和图2,该方法包括:
步骤101:获取原始样本。
步骤103:根据原始样本,得到至少两个原始向量。
步骤105:从所述至少两个原始向量中选择出待扰动向量。
步骤107:对待扰动向量添加对抗扰动,得到扰动向量。
步骤109:在预先设置的向量池中检索与扰动向量相近似的向量;其中,所述向量池中包括根据各历史原始样本得到的各历史原始向量。
步骤111:根据检索到的相近似的向量,得到对抗样本。
可见,在上述图1所述的流程中,预先设置了向量池,该向量池中包括各历史原始向量,且该各历史原始向量是根据历史实际存在的各原始样本得到的,因此,向量池中的向量能对应出一个真实存在的样本数据,比如一个实际存在的词汇,而不会对应一个不存在的样本数据,这样,在对原始向量进行扰动得到了扰动向量之后,不是直接利用扰动向量来得到对抗样本,而是在向量池中检索出该扰动向量相近似的向量,该检索出的向量因为与扰动向量相近似,因此满足对抗要求,同时,该检索出的向量因为能对应出一个真实存在的样本数据如一个文本的词汇或句子,因此,也满足真实性要求,即可能会在后续的攻击行为中出现,利用此种检索到的相近似的向量则既能够满足对抗性要求又能够满足真实性要求,可以更为有效地得到对抗样本。
下面对图1所示的每一个步骤进行说明。
首先在步骤101,获取原始样本。
在机器学习技术领域中,通常都会使用样本对模型进行训练。原始样本是需要输入到训练的模型中的样本,且模型会针对该原始样本输出识别结果,比如记为第一识别结果。
在本说明书一个实施例中,图1所示的对抗样本的生成方法可以应用于图像领域的模型训练,这样,本步骤101中的原始样本是图像数据。
在本说明书另一个实施例中,图1所示的对抗样本的生成方法可以应用于文本领域的模型训练,这样,本步骤101中的原始样本是文本数据,比如一段文字或者一篇文章等。
接下来在步骤103,根据原始样本得到至少两个原始向量。
以原始样本为文本数据为例,本步骤103的过程可以包括:
步骤1031:对原始文本进行预处理。
预处理可以包括对原始文本进行清洗和分词,分词的粒度可以是词汇级、字符级或n-gram级。
步骤1033:将预处理后的文本映射到向量空间,得到对应该原始文本的至少两个原始向量。
比如通过如word2vec,glove等方式自监督训练获得词向量,如果原始向量对应的文本数据的粒度就是词,则获取的词向量就是本步骤中的原始向量;如果原始向量对应的文本数据的粒度是句子或者文章级别,则进一步通过文本特征抽取模型,如TextCNN,LSTM,Transformer,BERT等模型结合文本分类等具体文本任务学习得到句子或文章级的表征向量,将得到的该句子或文章级的表征向量作为本步骤中的原始向量。
接下来在步骤105中,从至少两个原始向量中选择出待扰动向量。
通常,在进行扰动时,不会对原始样本对应的所有原始向量进行扰动,而是选择其中少量的原始向量进行扰动,从而满足以微小的扰动改变模型识别结果的对抗目的。
比如,以原始样本为图像数据为例,在将图像中的各个像素映射到向量空间,得到对应各像素的各原始向量比如有300万个原始向量,为了满足对抗目的,可以从该300万个原始向量中选择出1万个原始向量作为待扰动向量。
再如,以原始样本为文本为例,在将文本映射到向量空间,得到1万个词汇对应的1万个原始向量,为满足对抗目的,可以从1万个原始向量中选择出50个词汇对应的原始向量作为扰动向量。
接下来在步骤107中,对待扰动向量添加对抗扰动,得到扰动向量。
本步骤107的具体过程包括:
步骤1071:得到待扰动向量的至少一个维度分别对应的扰动值。
步骤1073:对于该至少一个维度中的每一个维度,将待扰动向量在该维度上的数值增加或者减少预定倍数的该维度对应的扰动值。
可以理解,从原始向量中选择出的待扰动向量是一个多维度的数据,比如待扰动向量A{3,1,5},该待扰动向量A包括在维度1上的数值3,在维度2上的数值1,在维度3上的数值5,因此,添加扰动的方式可以是对其中一个或多个维度上的数值进行改变,比如得到维度1对应的扰动值为1,维度3对应的扰动值为2,对其中维度1上的数值3加上一倍的扰动值1即3+1*1=4,对其中维度3上的数值5减去0.25倍的扰动值2即5-0.25*2=4.5,从而得到待扰动向量A的扰动向量A’ {4,1,4.5}。
当然,为了简化处理,也可以使得各个维度对应同一个扰动值,并使得各维度上的数值同时增加该扰动值或者同时减小该扰动值。
在本说明书的一个实施例中,在步骤1071中,在得到待扰动向量在某一个维度对应的扰动值时,具体实现方式包括:
方式一、随机生成。
在该方式一中,可以随机生成一个维度对应的扰动值。
方式二、利用方向向量。
在该方式二中,因为考虑到模型所使用的梯度函数本身就具有方向向量,该方向向量的维度与待扰动向量的维度相同,因此,可以将该方向向量在一个维度上的数值作为待扰动向量在该维度上对应的扰动值;其中,该模型为原始样本和对抗样本训练的模型。
接下来在步骤109中,在预先设置的向量池中检索与扰动向量相近似的向量;其中,所述向量池中包括根据各历史原始样本得到的各历史原始向量。
对于步骤109的解释,首先对向量池进行说明。
向量池中包括根据各历史原始样本得到的各历史原始向量。历史原始样本是历史上在实际业务过程中产生或出现过的真实样本,比如一篇论文之前被用于作为原始样本训练一个文本相似度的识别模型,该文章在历史过程中会被转换为多个向量,则会将该多个向量加入向量池,以此不断执行,向量池中则不断加入新的原始向量。可见,首先,向量池中包括历史过程累积的大量的原始向量,数量众多,便于后续检索,其次,向量池中的每一个原始向量是根据历史实际业务过程中的原始样本产生的,因此,每一个原始向量都能够还原到样本空间,比如,每一个原始向量都能还原出一个真实存在的词汇。
在本说明书的实施例中,可以针对不同的业务类型只建立一个向量池,这样,向量池中的历史原始向量可以对应于不同的业务类型。比如,针对文本相似度识别这个业务场景1,在该业务场景1中历史产生的所有原始向量都加入向量池中,针对转账业务的风险识别这个业务场景2,在该业务场景2中历史产生的所有原始向量都加入向量池中,使得向量池中的向量的数量及类型都更为丰富。
在本说明书的另一个实施例中,可以针对每一个不同的业务类型分别建立一个向量池。这样,在一个向量池中包括的各历史原始向量是根据对应指定业务类型的各历史原始样本得到的。比如,针对文本相似度识别这个业务场景1,在该业务场景1中历史产生的所有原始向量都加入向量池1中,针对转账业务的风险识别这个业务场景2,在该业务场景2中历史产生的所有原始向量都加入向量池2中,每一个向量池都只保存本业务类型历史过程中产生的原始向量,这样,则可以进一步保证后续过程中针对样本对应的业务类型,只检索该业务类型的向量池中历史上出现过的该业务类型的向量,从而得到解释性更好的相近似的向量,即符合在特定业务类型下的相似性要求,使得检索到的结果更为准确。
在步骤109中,可以采用simHash算法,KNN算法或KDTree算法在向量池中检索与扰动向量相近似的向量。
在步骤109中,与扰动向量相近似的向量需要满足如下中的至少一种要求:
第一种:与扰动向量的欧式距离小于预设距离值;所述预设距离值为正整数。
两个向量之间的欧式距离越小,则说明两个向量越相似。
第二种:与扰动向量的余弦距离大于预设角度值。
两个向量之间的余弦距离越大,则说明两个向量越相似。
第三种:与扰动向量的杰卡德相似系数大于预设系数值。
两个向量之间的杰卡德相似系数越大,则说明两个向量越相似。
如果向量池中的一个向量与当前检索的扰动向量的欧式距离为0(或者余弦距离为360度或者杰卡德相似系数为1),则说明检索到的向量正好等于扰动向量,在之前步骤中得到的扰动向量可以还原到一个真实存在的样本数据比如一个真实存在的词汇。如果向量池中的一个向量与当前检索的扰动向量的欧式距离不等于0但是只要满足小于预设距离值比如小于0.2(或者余弦距离不等于360度但是只要满足大于预设角度值比如大于180度;或者杰卡德相似系数不等于1但是只要满足大于预设系数值比如大于0.8),则说明虽然在之前步骤中得到的扰动向量可能无法还原到一个真实存在的样本数据比如一个真实存在的词汇,但是因为该扰动向量与检索到的向量相近似,因此,可以用检索到的向量(能够还原到真实存在的样本数据)来表征该扰动向量。
第四种:不等于扰动向量添加扰动之前的待扰动向量。
举例说明。根据原始样本得到了待扰动向量,比如A{3,1,5},对该待扰动向量进行扰动后,得到了扰动向量A’ {4,1,4.5}。为了避免A’ {4,1,4.5}无法还原到样本空间,因此会在向量池中检索与扰动向量A’相近似的向量,比如可能会检索到一个相似的向量A’’{4,1,4}。然而,向量池中有可能已经包括了历史存在的向量A{3,1,5},并且,根据检索可能会将向量池中的A{3,1,5}作为与扰动向量A’ {4,1,4.5}相近似的向量。但是根据我们生成对抗样本的目的,该检索到的相近似的向量不能与待扰动向量相同,否则,利用该检索到的相近似的向量得到的样本就会与原始样本相同,无法作为对抗样本,因此,为了避免此种情况发生,与扰动向量相近似的向量不能等于该扰动向量添加扰动之前的待扰动向量。
接下来,在步骤111根据检索到的相近似的向量,得到对抗样本。
本步骤111的过程可以包括:
步骤1111:利用本次检索到的向量,得到相似样本。
以原始样本为图像数据为例,比如在步骤105中得到对应图像中各像素的各原始向量比如有300万个原始向量,并选择出1万个原始向量作为1万个待扰动向量,那么在本步骤1111中,是用针对该1万个原始向量在向量池中检索到的1万个向量来替换该1万个原始向量,并与其他未被选择为待扰动向量的各向量一起,还原出一个图像,该图像与作为原始样本的图像存在差异及相似性,此处还原出的图像即为相似样本。
以原始样本为文本数据为例,比如在步骤105中一段文本得到1万个词汇,对应1万个原始向量,从1万个原始向量中选择出50个词汇对应的50个原始向量作为50个扰动向量,那么在本步骤1111中,是用针对该50个原始向量在向量池中检索到的50个向量来替换该50个原始向量,并与其他未被选择为待扰动向量的各向量一起,还原出一个文本,该文本与作为原始样本的文本存在差异及相似性,此处还原出的文本即为相似样本。
步骤1113:将所述相似样本输入模型中,得到第一识别结果;
步骤1115:判断所述第一识别结果与将所述原始样本输入所述模型时得到的第二识别结果之间的差异是否满足对抗要求,如果是,执行步骤1117。否则返回执行步骤107至步骤1115中判断的步骤,直至判断结果为是。
步骤1117:将本次检索到的向量确定为对抗向量。
步骤1119:利用对抗向量生成对抗样本。
作为对抗样本,其需要满足模型针对该对抗样本的识别结果与模型针对原始样本的识别结果不同,且此种不同需要满足对抗要求,比如模型输出的识别结果如评分的分值差异要大于一个设定值,再如一个识别结果为是而另一个识别结果为否,此时才能作为对抗样本。对于上述步骤中检索到的相近似的向量,还需进一步验证是是否满足对抗要求,因此,通过本步骤1115的处理则可以筛选出满足对抗要求的向量。
文本空间与图片连续的像素空间不同,文本空间的离散性导致表征空间的连续扰动难以对应到文本空间的扰动或者对应的扰动幅度过大,因此,本说明书实施例提供的方法对于文本类对抗样本的生成具有更好的效果。
在本说明书一个实施例中,向量对应的文本数据的粒度可以为:字符、n-gram片段、词或者句子。
在生成了对抗样本之后,则可以利用对抗样本对模型进行增强训练。
在本说明书一个实施例中,提出了一种对抗样本的生成装置,参见图3,该装置300包括:
输入模块301,被配置为获取原始样本;
向量转换模块302,被配置为根据所述原始样本,得到至少两个原始向量;
扰动处理模块303,被配置为从所述至少两个原始向量中选择出待扰动向量;对待扰动向量添加对抗扰动,得到扰动向量;
对抗样本确定模块304,被配置为在预先设置的向量池中检索与扰动向量相近似的向量;其中,所述向量池中包括根据各历史原始样本得到的各历史原始向量;根据检索到的相近似的向量,得到对抗样本。
在本说明书提供的装置的一个实施例中,所述样本应用于指定业务类型;
所述向量池中包括的各历史原始向量是根据对应所述指定业务类型的各历史原始样本得到的。
在本说明书提供的装置的一个实施例中,所述扰动处理模块303被配置为执行:
得到待扰动向量在一个维度上对应的扰动值;
将待扰动向量在该维度上的数值增加或者减少预定倍数的该维度对应的扰动值。
在本说明书提供的装置的一个实施例中,所述扰动处理模块303被配置为执行如下中的至少一项:
随机生成待扰动向量的一个维度对应的扰动值;
得到模型所使用的梯度函数的方向向量,将该方向向量在一个维度上的数值作为所述待扰动向量在该维度上对应的扰动值;其中,所述模型为所述原始样本和所述对抗样本训练的模型。
在本说明书提供的装置的一个实施例中,对抗向量确定模块304被配置为执行:利用simHash算法,KNN算法或KDTree算法,在预先设置的向量池中检索与扰动向量相近似的向量。
在本说明书提供的装置的一个实施例中,所述与扰动向量相近似的向量满足如下中的至少一种:
与扰动向量的欧式距离小于预设距离值;所述预设距离值为正整数;
与扰动向量的余弦距离大于预设角度值;
与扰动向量的杰卡德相似系数大于预设系数值;
不等于待扰动向量。
在本说明书提供的装置的一个实施例中,对抗样本确定模块304被配置执行:
利用本次检索到的相近似的向量,得到相似样本;
将所述相似样本输入模型中,得到第一识别结果;
判断所述第一识别结果与将所述原始样本输入所述模型时得到的第二识别结果之间的差异是否满足对抗要求;
如果否,返回执行所述对待扰动向量添加对抗扰动的步骤至所述判断的步骤,直至判断结果为是;
如果是,则将本次检索到的向量确定为对抗向量;
利用对抗向量生成对抗样本。
本说明书一个实施例提供了一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行说明书中任一个实施例中的方法。
本说明书一个实施例提供了一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现执行说明书中任一个实施例中的方法。
可以理解的是,本说明书实施例示意的结构并不构成对对抗样本生成装置的具体限定。在说明书的另一些实施例中,对抗样本生成装置可以包括比图示更多或者更少的部件,或者组合某些部件,或者拆分某些部件,或者不同的部件布置。图示的部件可以以硬件、软件或者软件和硬件的组合来实现。
上述装置、系统内的各模块之间的信息交互、执行过程等内容,由于与本说明书方法实施例基于同一构思,具体内容可参见本说明书方法实施例中的叙述,此处不再赘述。
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于装置实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
本领域技术人员应该可以意识到,在上述一个或多个示例中,本发明所描述的功能可以用硬件、软件、挂件或它们的任意组合来实现。当使用软件实现时,可以将这些功能存储在计算机可读介质中或者作为计算机可读介质上的一个或多个指令或代码进行传输。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的技术方案的基础之上,所做的任何修改、等同替换、改进等,均应包括在本发明的保护范围之内。
- 基于生成对抗网络的黑盒恶意软件检测对抗样本生成方法及装置
- 一种基于生成对抗网络的对抗攻击样本的生成方法