一种视频多目标人脸表情识别方法和系统
文献发布时间:2023-06-19 11:29:13
技术领域
本发明属于人工智能领域,具体涉及一种视频多目标人脸表情识别方法和系统。
背景技术
人脸表情是最直接、最有效的情感识别模式。在过去的几十年里,人脸表情识别技术得到了越来越多的关注,其应用包括:增强现实(AR)、人机交互、驾驶员疲劳检测、虚拟现实等相关领域。其中表情类别主要包括:生气,害怕,厌恶,开心,悲伤,惊讶以及平静。
目前主流的基于图像的表情识别方法流程为先从图像中找出人脸关键区域,然后提取人脸关键区域的有效特征,最后利用模型对特征进行分类以实现具体表情分类。现阶段,随着深度学习的飞速发展,人脸关键区域提取、关键区域特征提取以及特征分类均可以使用模型进行实现。而针对视频表情识别的方法为将视频解析成帧序列,然后利用图像表情识别方法对每一帧分别进行表情识别然后将单帧识别结果拼接成动态识别结果,或者对帧序列依次进行人脸区域检测和人脸区域特征提取,最后利用时序相关深度学习模型对时序帧进行特征融合及分类得到表情识别结果。
针对上述两种视频表情识别方法,存在以下问题:对于第一种方法,有较快的运行效率,但是由于是对视频中单帧分别进行识别,所以存在表情识别结果不连贯的问题;对于第二种方法,通过综合多帧进行表情识别,有不错的表情连贯性,但是对于计算机资源有非常大的要求,不适用于工业应用。同时,上述两种方案均不能适用于视频中多目标表情动态识别。
发明内容
为了解决现有技术中存在的上述技术问题,本发明提供了一种视频多目标表情识别方法和系统,以解决现有视频表情识别方法中表情识别结果不连贯,模型训练复杂且不能解决视频中多目标表情识别的问题,其具体技术方案如下:
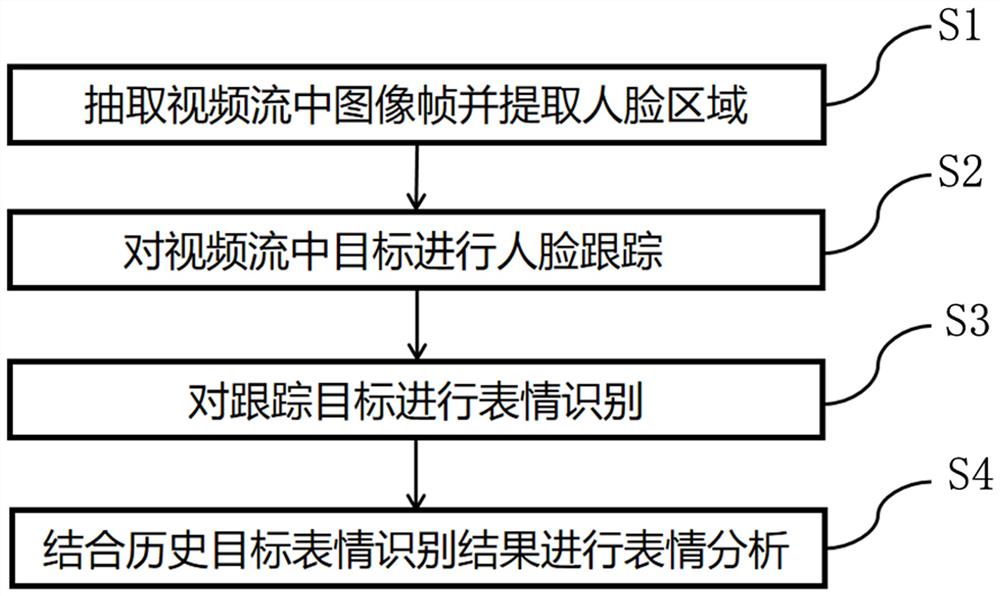
一种视频多目标表情识别方法,包括如下步骤:
S1、获取视频流中任一时刻
S2、将步骤S1中人脸区域
S3、将步骤S2中跟踪区域
S4、利用步骤S3中识别结果
进一步的,所述步骤S1具体为:
利用深度学习目标检测算法对视频流中的图像帧进行人脸检测,对应当前帧的检 测结果为
进一步的,所述步骤S2具体包括:
步骤S2.1、假定
步骤S2.2、然后遍历计算序列
步骤S2.3、新建一个跟踪序号集合
进一步的,所述步骤S2.2具体为:
计算边框重叠率
其中,
设定一个阈值
计算像素内容相似度,如果最终内容相似度大于设定阈值,则表明
针对元素
将所述
计算特征向量
同样,设定阈值
进一步的,所述步骤S3具体为:
针对步骤S2更新的目标跟踪区域元素的位置集合
进一步的,所述卷积神经网络模型为预先训练好的VGG-16网络模型。
进一步的,所述步骤S4具体为:
已知步骤S3计算出的当前帧识别结果
先新建一个包含与
遍历集合
遍历所述生成的容器集合
一种视频多目标表情识别系统,包括:
视频信号采集模块,用于采集用户视频数据;
视频信号预处理模块,用于将采集到的视频数据进行预处理,对视频数据进行抽帧处理;
视频表情识别模块,用于通过设计的网络模型和流程,预测用户面部的情感类型;
数据存储模块,用于利用 MySQL 数据库,存储用户的视频数据和情感标签数据。
进一步的,所述视频信号采集模块采用高清晰广角摄像头用于获取到更多的和清晰的人脸目标。
进一步的,所述预处理,包括:视频抽帧、人脸检测,首先摄像头获取视频数据有固定的帧率,根据等时间间隔进行抽帧处理,针对人脸检测将采用深度学习模型对视频帧中的人脸目标进行截取。
本发明的优点如下:
本发明提出了一种基于目标追踪的方法来保证目标在视频流中的连续性的方式,实现了多目标场景下的视频表情识别。
通过利用多帧识别结果对当前表情识别结果进行加权,提高了视频表情识别的鲁棒性,防止视频表情识别结果产生的单帧抖动,同时通过加权方式进行表情识别对比通过多模型融合特征识别将极大提高识别效率,可以运用到工业中。
本发明的视频表情识别系统具有表情分析结果及原始视频存储功能,能够帮助做出合理分析和建议,例如在校教育场景,智能驾驶辅助场景等。
附图说明
图1 为本发明系统的结构示意图;
图2为本发明方法的流程图;
图3为VGG-16网络结构图。
具体实施方式
为了使本发明的目的、技术方案和技术效果更加清楚明白,以下结合说明书 附图,对本发明作进一步详细说明。
参照图1所示,一种视频多目标表情识别系统,包括:
视频信号采集模块,用于采集用户视频数据,一般采用高清广角摄像头,以获取到更多的人脸数据;
视频信号预处理模块,用于将采集到的视频数据进行预处理:包含视频抽帧和人脸目标检测。由于连续视频帧存在大量重复冗余,因此对视频数据抽帧处理,减少后续情感识别处理数据量,可较大提高系统运行效率,具体为:针对一个帧率为30fps的视频,将采用1秒抽5帧;目标检测方法将采用神经网络模型SSD( Single Shot MultiBox Detector)对视频中人脸目标进行提取。
视频表情识别模块,用于通过设计的网络模型和流程,预测用户面部的情感类型;
数据存储模块,用于利用 MySQL 数据库,存储用户的视频数据和情感标签数据。
参照图2-3所示,本发明的一种视频多目标表情识别方法包括如下几个步骤:
步骤S1、抽取视频流中图像帧并提取人脸区域。
所述视频流可通过实时摄像头中获取,也可是用户已有视频数据库中的视频数据。然后将视频进行等间隔抽帧处理,考虑到相邻几帧图像内容重复性过多且表情变化不大,所以本发明优选的,针对所有不同帧率的视频都将进行1秒抽10帧进行处理,提升计算效率降低计算资源的消耗。然后对抽取的单帧图像进行人脸检测。随着深度学习的发展,目前人脸检测的方法通常采用深度学习的模型进行处理,例如用于人脸目标检测的SSD结构和MTCNN人脸检测算法;
假定,对当前抽取出的图像帧的检测结果为
步骤S2、对视频流中的目标进行人脸跟踪;
在步骤S1中提取人脸区域后,假定当前抽帧时刻为
计算边框重叠率(IOU,Intersection over Union),如果IOU重叠率大于设定阈值,则计算像素内容相似度,否则表明该两个元素不匹配;
计算像素内容相似度,如果最终内容相似度大于设定阈值,则表明该两个元素匹配,否则不匹配;
通常,计算边框重叠率中两个目标框的IOU计算方式为:假定目标跟踪区域
其中,IOU即为区域边框元素
进一步,设定一个阈值
所述元素
针对元素
将
计算特征向量
如果
针对
步骤S3、对跟踪目标进行表情识别;
针对步骤S2更新的
步骤S4、结合历史表情识别结果进行分析:
已知步骤S3计算出的当前帧识别结果
先新建一个包含与
遍历集合
遍历生成的容器集合
综上所述,本发明提供的方法,通过融合目标跟踪技术实现视频中多目标表情识别、利用前后帧结果加权提升动态表情识别结果的准确性和鲁棒性。
以上所述,仅为本发明的优选实施案例,并非对本发明做任何形式上的限制。 虽然前文对本发明的实施过程进行了详细说明,对于熟悉本领域的人员来说,其依然可以对前述各实例记载的技术方案进行修改,或者对其中部分技术特征进行同等替换。凡在本发明精神和原则之内所做修改、同等替换等,均应包含在本发明的保护范围之内。
- 一种视频多目标人脸表情识别方法和系统
- 一种基于视频图像序列的人脸表情识别方法