一种基于稠密边界时空网络的时序行为检测方法
文献发布时间:2023-06-19 11:29:13
技术领域
本发明属于计算机视觉和模式识别技术领域,具体涉及一种基于稠密边界时空网络的时序行为检测方法。
背景技术
随着目前信息数据爆炸式增长,视频数据成为当代社会的主流数据,特别地,视频大多数是人体的行为活动,为了有效地解释这些数据,人体时序行为检测成为计算机视觉领域中非常重要的课题。时序行为检测作为视频理解的基石,其目的是在一段未剪辑的视频中找到动作的开始时间点和结束时间点。目前时序行为检测技术已应用于多个领域,例如教育、社交、娱乐、短视频等多个场景。以短视频领域为例,用户在上传一段原始视频后,可以通过时序行为检测算法功能接口完成动作视频的提取,并且进行智能剪辑,帮助用户自动生成更加专业的视频。
时序行为检测分为两个步骤:首先,尽可能多的生成动作开始时间与结束时间提名;其次,通过对提取出的开始时间、结束时间提名进行评估,最终得到高精度、高召回率的动作提名。现阶段主流的时序行为检测方法是滑动窗口法(sliding-windows)和片段级别的动作概率法(snippet-level actionness score)。但是,这两种检测方法对时序行为检测的精度普遍偏低。
发明内容
本发明的目的是提供一种基于稠密边界时空网络的时序行为检测方法,解决现有技术中检测方法对时序行为检测的精度普遍偏低的缺点。
为了达到上述目的,本发明的技术方案是:
一种基于稠密边界时空网络的时序行为检测方法,包括以下步骤:
步骤1:采用two-stream提取待检测视频的时空特征,生成RGB特征和光流特征;
步骤2:将RGB特征和光流特征分别通过堆叠的两层一维卷积,然后融合得到融合特征;将3路特征序列再分别通过LSTM网络与一维卷积网络,产生3路增强特征序列,然后将3路增强特征序列进行融合,得到动作概率特征;
步骤3:将动作概率特征和融合特征输入候选特征生成层,将这两类特征转化为特征序列,输入到稠密边界提取模块。动作概率特征序列通过3层二维卷积得到动作完整性置信度图,融合特征序列通过1个三维卷积和2个二维卷积得到边界置信度图;
步骤4:采用Soft-NMS方法对提取出的若干候选片段进行筛选,去除视频中的冗余片段。
进一步的,步骤2中,针对视频上下文信息的时序性,使用长短期记忆网络,增强上下文信息信息的特征,获得动作概率特征和融合特征。
进一步的,步骤3中,所述稠密边界提取模块采用稠密动作概率生成子模块和稠密边界生成子模块,得到动作完整性置信度图与边界置信度图。
一种基于稠密边界时空网络的时序行为检测系统,包括:
特征提取模块,采用two-stream提取待检测视频的时空特征,得到时空特征图;
时序增强模块,采用LSTM学习视频信息中的长期依赖关系,增强上下文信息的特征,获得多尺度的稠密边界特征。
稠密边界提取模块,采用稠密动作概率生成子模块和稠密边界生成子模块,得到尽可能多地选提议时序片段,并预测所述候选提议时序片段的置信度得分;
后处理模块,采用Soft-NMS方法对提取出的若干候选片段进行筛选。
与现有技术相比,本发明的有益效果:
本发明提供的稠密边界时空网络(Dense boundary Space-Time Network,DBST)的时序行为检测方法,采用two-stream提取待检测视频的时空特征,生成两种更具区分性的特征。同时利用LSTM学习视频信息中的长期依赖关系,增强上下文信息的特征,获得多尺度的稠密边界特征。然后,采用稠密动作概率生成子模块(DBE-A)来预测精准的时间边界,并采用稠密边界生成子模块(DBE-B)来得到候选提议时序片段的动作置信度得分,在activitynet-1.3数据集上进行了综合实验,有效提高了时序行为检测的召回率和AUC值,结果表明了本方法与目前最先进的方法相比具有优越性。
附图说明
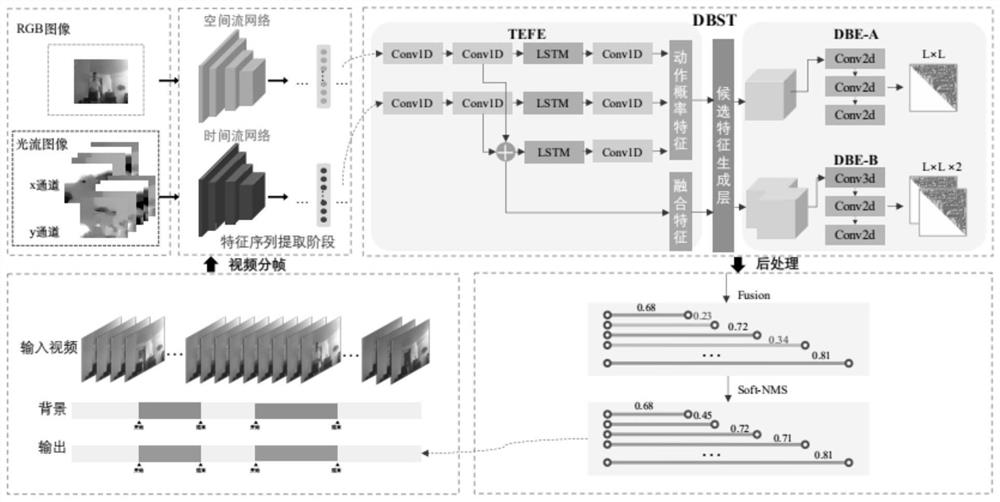
图1为本发明实施例中于稠密边界时空网络的时序行为检测方法框架图;
图2为本发明实施例中用于特征提取的two-stream网络结构图;
图3为本发明实施例中TEFE模块结构图;
图4为本发明实施例中产生时序上下文特征的关键模块示意图;
图5为本发明实施例中IOU阈值对平均召回率的影响图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面将结合实施例对本发明作进一步地详细描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
如图1所示,本发明提供的基于稠密边界时空网络的时序行为检测方法包括以下步骤:
步骤1:采用two-stream提取待检测视频的时空特征,得到时空特征图;
步骤2:采用LSTM学习视频中的长期依赖关系,增强上下文信息特征,获得多尺度的稠密边界特征;
步骤3:采用稠密边界提取模块(Dense boundary extraction,DBE),得到尽可能多的候选提议时序片段,并预测所述候选提议时序片段的置信度得分;
步骤4:采用Soft-NMS方法对提取出的若干候选片段进行筛选。
本发明提供的基于稠密边界时空网络的时序行为检测方法由三部分组成:two-stream特征提取阶段、时序稠密边界生成阶段和后处理阶段。时序稠密边界生成阶段分为时序增强特征提取模块和稠密边界提取模块。
为了实现端到端的训练,将动作概率特征和融合特征输入候选特征生成层(Proposalfeaturegenerationlayer,PFG),转化为特征序列,再输入到稠密边界提取模块,该模块分为稠密动作概率生成子模块(DBE-A)和稠密边界生成子模块(DBE-B),分别得到动作完整性置信度图与边界置信度图。
在上述实施例的基础上,作为本发明的一个实施例,如给定一段视频序列,我们使用two-stream提取丰富的时空特征来表示视频。two-stream的网络结构如图2所示,会生成RGB特征和光流特征。时序增强模块框架图如图3所示,将RGB特征和光流特征通过堆叠的两层一维卷积处理再通过融合得到的融合特征,将三种特征分别通过LSTM网络与一维卷积网络,产生3路增强特征序列,然后将3路增强特征序列进行融合,产生动作概率特征。如图3所示,是特征提取阶段的结构表,融合特征和动作概率特征的特征图大小均为L×128。
具体地,
s
t
d
式中,采用两层一维卷积处理RGB特征和光流特征,将RGB特征的输出表示为空间流特征s
P
P
P
A
式中,s
表1时序特征增强阶段结构表
在上述实施例中,我们采用稠密边界生成模块,使得模型能够得到尽可能多的候选片段。候选特征生成层(Proposal feature generation layer,PFG)的输入是动作概率特征和融合特征,将这两类特征转化为特征序列,再输入到稠密边界提取模块,该模块分为稠密动作概率生成子模块(DBE-A)和稠密边界生成子模块(DBE-B),分别得到动作完整性置信度图与边界置信度图。
PFG模块是实现端到端网络、产生时序上下文特征的关键模块。PEG模块图如图4所示,此模块的输入是L*C,经过PFG模块后产生的特征维度为L*L*N*C,其中,L为特征长度,N为采样点数,C为通道数。如表2所示,是稠密边界生成阶段的结构表。
表2稠密边界生成阶段结构表
为了使用较少的候选片段得到较高的召回率,本发明使用Soft-NMS对提取出的若干候选片段进行筛选。具体步骤如下:
(1)根据所有候选提议的置信度得分进行排序;
(2)选择置信度最高的候选提议框并添加到最终输出列表中;
(3)计算所有候选提议框的面积;
(4)计算置信度最高的候选提议框与其它候选框的IoU;
(5)删除IoU大于阈值的候选提议框,即将该候选提议框对应的置信度分数设为0;
(6)重复上述过程,直至将所有候选提议框均进行处理。
采用常用数据集ActivityNet来验证本发明提供的时序行为检测方法的有效性。本文采用的1.3版本包含19994个带有5个动作大类,200个动作小类标注的视频。下面对实验细节和设置进行简单介绍如下:我们将所有视频划分为三部分,其中10024个训练视频,4926个验证视频,5044个测试视频,使模型得到最优的参数设置。由于GPU显存有限,我们batch size设置为8,使用RMSProp优化器,在前8个时期,学习速率被设置为10
本发明提供的稠密边界时空网络的时序行为检测方法,采用two-stream提取待检测视频的时空特征,得到RGB特征和光流特征;采用LSTM学习视频信息中的长期依赖关系,增强上下文信息的特征,获得多尺度的稠密边界特征。采用稠密动作概率生成子模块(DBE-A)和稠密边界生成子模块(DBE-B),得到尽可能多的候选提议时序片段,并预测所述候选提议时序片段的置信度得分;采用Soft-NMS方法对提取出的若干候选片段进行筛选;可见,本发明方法能够提高特征的多样性,保证时序定位的精度,生成精准的时间边界候选,从而提升时序行为检测的召回率和AreaUnder Curve(AUC)大小。
以上应用了具体个例对本发明进行阐述,只是用于帮助理解本发明,并不用以限制本发明。任何熟悉该技术的人在本发明所揭露的技术范围内的局部修改或替换,都应涵盖在本发明的包含范围之内。
- 一种基于稠密边界时空网络的时序行为检测方法
- 基于时序保留性时空特征的人体行为分类检测方法及系统