一种小样本文本分类方法、装置、计算机设备和存储介质
文献发布时间:2023-06-19 11:29:13
技术领域
本发明涉及自然语言处理的技术领域,更具体地,涉及一种小样本文本分类方法、装置、计算机设备和存储介质。
背景技术
目前,自然语言处理技术通过大量数据训练深度模型,在各个领域上均取得了不错的结果。文本分类任务由传统机器学习步入深度学习时代,以CNN和RNN为基础拓展出来的大量模型,均取得了很好的效果。领域数据充斥在互联网的方方面面,但具有正确标签的数据少之又少,并且文本标注又是一件费时费力的工作。如何弱化模型对大量标注数据的依赖,同时保持模型高的分类精度,变得十分必要。
随着小样本学习在图像领域的兴起和流行,小样本学习也逐渐引入到自然语言处理任务。小样本学习模型大体分为三种:基于度量、基于模型和基于优化。小样本学习方法不会依赖大规模的训练样本,从而避免了某些特定应用中数据准备的高昂成本,实现低成本,快速的模型部署。
2021年3月19日公开的中国专利CN112528029A提供了一种文本分类模型处理方法、装置、计算机设备及存储介质,方法包括:获取有标签文本、无标签文本以及各初始分类器;根据有标签文本训练各初始分类器,得到各初始文本分类器;对于每个初始文本分类器,通过其他初始文本分类器对无标签文本进行标注,得到文本标签;根据文本标签对无标签文本进行筛选,得到初始文本分类器的补充训练集;基于预设的迭代算法,通过补充训练集对初始文本分类器进行训练,得到文本分类器,实现对文本的分类,但该方法需要依赖大量的、准确的标注数据,才能对文本分类器进行训练,进而实现对文本的分类,数据成本高昂,不利于快速部署。
发明内容
本发明为克服上述现有技术对文本进行分类时需要大量训练数据的缺陷,提供一种小样本文本分类方法、装置、计算机设备和存储介质,可以在少量样本数据中实现快速学习,对新样本进行分类,数据成本低,分类结果准确,稳定性强,。
为解决上述技术问题,本发明的技术方案如下:
本发明提供一种小样本文本分类方法,所述方法包括以下步骤:
S1:获取文本数据集,对文本数据集进行处理,获得小样本文本数据集;
S2:对小样本文本数据集中的文本数据进行预处理;
S3:用向量形式表征预处理后文本数据中的单词和句子;
S4:以句子为单元划分句子节点,计算句子节点间的权重;
S5:遍历所有句子节点,计算每个句子节点的累加权重,直到每个句子节点的累加权重都收敛;
S6:按照累加权重的数值从大到小对句子节点进行排序,提取前n位的句子节点对应的句向量作为文本摘要;
S7:对文本摘要的句向量中每个词向量加权,获得最终句向量;
S8:选定分类器,利用最终句向量对分类器进行训练,利用文本数据集中的文本数据对分类器进行性能测试,实现分类。
优选地,获得小样本文本数据集的具体方法为:
将文本数据集分为训练集、测试集和验证集;将训练集、测试集和验证集每个集合分为支撑集和查询集,对支撑集中的每个类别抽取定量文本数据,组成小样本文本数据集。
优选地,所述S2中,对文本预处理的具体方法为:
文本分句:根据标点符号对文本分句;
句子分词:对中文词语根据语义分词,英文跟换有空格切割单词;
去除停用词:去除对分类无明显帮助的停用词汇、标点符号及数字。
优选地,所述S3中,利用Glove算法,生成预处理后文本中的单词s的词向量vector(s);句向量表示为:v
优选地,所述S4中,计算句子节点间的权重w
构建有向有权图G=(V,E,W),V表示句向量集合,E表示句子节点间的边,W表示句子节点间的权重集合;V、E和W分别表示为:
V={v
E={(v
W={w
则句子节点间的权重w
w
其中,w
优选地,所述S5中,计算各句子节点的累加权重的具体方法为:
其中,WS(v
根据迭代的累加权重WS的数值从大到小对句子节点进行排序,累加权重越大的句子节点表示该句子节点所代表的句子在文本中更为重要,包含更多的文本信息。
优选地,所述S7中,获得最终句向量v
计算词频:
计算逆文本频率:
计算TF-IDF权值:
TF
则最终句向量表示为:
v
其中,Avg(·)表示求均值操作,TF
TF-IDF算法用于评估一个单词对于一个文件集或一个语料库中的一份文件的重要程度,如果某个单词在一份文件中出现的频率高,且在其他文件中出现的频率低,则认为此单词具有很好的区别能力。
本发明还提供一种小样本文本分类装置,所述装置包括:
获取分类模块,用于获取文本数据集,对文本数据及进行分类,获得小样本文本数据集;
预处理模块,用于对小样本文本数据集中的文本数据预处理,获得文本数据的词向量和句向量表征形式;
划分计算模块,用于划分句子节点,计算句子节点间的权重;
累加排序模块,用于计算句子节点的累加权重,并按照累加权重的数值从大到小对句子节点进行排序,获得最终句向量;
训练测试模块,选定分类器,利用最终句向量对分类器进行训练,利用文本数据集中的文本数据对分类器进行性能测试。
本发明还提供一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述一种小样本文本分类方法的步骤。
本发明还提供一种计算机可读的存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述一种小样本文本分类方法的步骤。
与现有技术相比,本发明技术方案的有益效果是:
本申请提供一种小样本文本分类方法,对文本数据集处理组成小样本文本数据,预处理后获得文本数据的词向量和句向量表征;以句子为单元划分句子节点后,计算句子节点间的权重和累加权重,按照累加权重的数值从大到小对节点进行排序,将前n位的句子节点对应的句向量作为文本摘要;对文本摘要的句向量中每个词向量加权,获得最终句向量,利用最终句向量对分类器进行训练;通过该方法可以在少量样本数据中选出包含更多文本信息的文本摘要,选取文本摘要中的词向量并对其加权,利用最终句向量对分类器训练,使分类器学习更迅速,训练结果更优秀,分类效果更准确,稳定性更强,数据成本更低。
附图说明
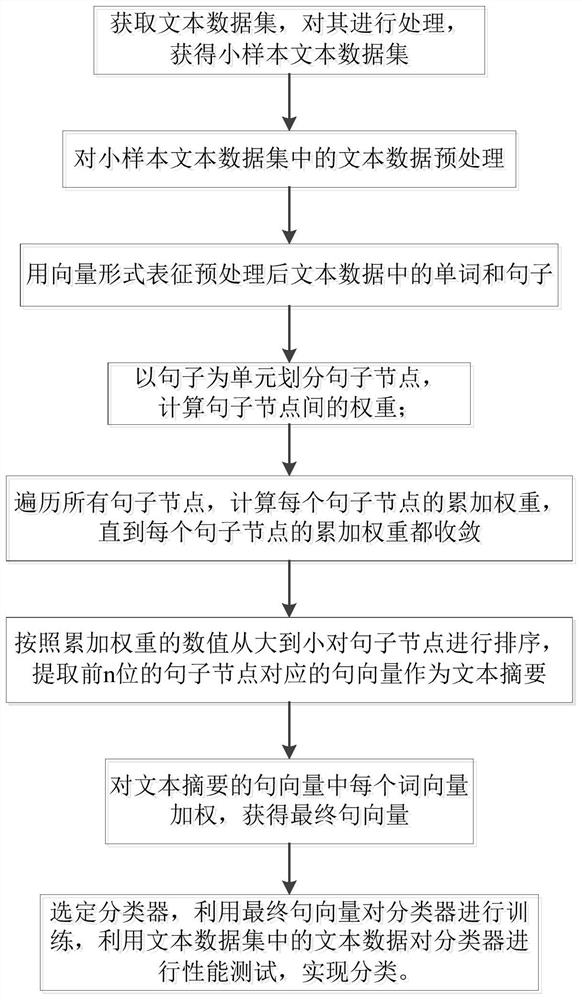
图1为实施例1所述的一种小样本文本分类方法的流程图;
图2为实施例1所述的对分类器训练的示意图;
图3为实施例2所述的一种小样本文本分类装置的示意图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
本实施例提供一种小样本文本分类方法,如图1所示,所述方法包括以下步骤:
S1:获取文本数据集,对文本数据集进行处理,获得小样本文本数据集;
S2:对小样本文本数据集中的文本数据进行预处理;
S3:用向量形式表征预处理后文本数据中的单词和句子;
S4:以句子为单元划分句子节点,计算句子节点间的权重;
S5:遍历所有句子节点,计算每个句子节点的累加权重,直到每个句子节点的累加权重都收敛;收敛的含义为每个句子节点的累加权重都趋于稳定;
S6:按照累加权重的数值从大到小对句子节点进行排序,提取前n位的句子节点对应的句向量作为文本摘要;
S7:对文本摘要的句向量中每个词向量加权,获得最终句向量;
S8:选定分类器,利用最终句向量对分类器进行训练,利用文本数据集中的文本数据对分类器进行性能测试,实现分类。
获得小样本文本数据集的具体方法为:
将文本数据集分为训练集、测试集和验证集;将训练集、测试集和验证集每个集合分为支撑集和查询集,对支撑集中的每个类别抽取定量文本数据,组成小样本文本数据集;
在具体实施方式中,从训练集、测试集和验证集中分别随机选取N个不同类别,从每类别中选取K张带标签的文本数据组成支撑集,用于进行N类K样本训练,将剩余的文本数据组成查询集;如图2所示,从训练集、测试集和验证集中均选取2个不同类别,训练集中选取10张带标签的文本数据组成支撑集S,测试集和验证集中选取1个带标签的文本数据组成支撑集S1和S2;训练集练集、测试集和验证集剩余的10个文本数据组成查询集Q、Q1和Q2。
所述S2中,对文本预处理的具体方法为:
文本分句:根据标点符号对文本分句;
句子分词:对中文词语根据语义分词,英文跟换有空格切割单词;
去除停用词:去除对分类无明显帮助的停用词汇、标点符号及数字。
所述S3中,利用Glove算法,生成预处理后文本数据中的单词s的词向量vector(s);句向量表示为:v
所述S4中,计算句子节点间的权重w
构建有向有权图G=(V,E,W),V表示句向量集合,E表示句子节点间的边,W表示句子节点间的权重集合;V、E和W分别表示为:
V={v
E={(v
W={w
则句子节点间的权重w
w
其中,w
所述S5中,计算句子节点的累加权重的具体方法为:
其中,WS(v
根据迭代的累加权重WS的数值从大到小对句子节点进行排序,累加权重越大的句子节点表示该句子节点所代表的句子在文本中更为重要,包含更多的文本信息。
所述S7中,获得最终句向量v
计算词频:
计算逆文本频率:
计算TF-IDF权值:
TF
则最终句向量表示为:
v
其中,Avg(·)表示求均值操作,TF
TF-IDF算法用于评估一个单词对于一个文件集或一个语料库中的一份文件的重要程度,如果某个单词在一份文件中出现的频率高,且在其他文件中出现的频率低,则认为此单词具有很好的区别能力。
在具体实施过程中,
利用R2D2小样本学习模型,采用元学习算法的流程,类别标签采用one-hot方法将标签数值化,文本向量采用最终句向量均值avg(v
在现有的THUCNews数据集中分别按照100、300、500的量抽取每类的样本数量,其中Training category为训练集,Validate category为验证集,Testing category为测试集,数据及划分见下表.
为了对比起到对比作用,使用BiLSTM-ATT模型作为对照试验,实验结果见下表:其中表格第一列中N way K shot表示从训练集、测试集和验证集中分别随机选取N个不同类别,从每类别中选取K张带标签的文本数据组成支撑集;2-1表示从训练集、测试集和验证集中分别随机选取2个不同类别,从每类别中选取1张带标签的文本数据组成支撑集;表格中的分数越大,表示分类结果越准确,分数越集中,表示分类结果准确性越强。
实验结果表明,在小样本文本数据下,本实施例的分类结果分数大于BiLSTM-ATT模型的分类结果分数,且分类结果分数比较集中,说明本方法在小样本文本数据下的分类结果准确,稳定性强。
本实施例还提供一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述一种小样本文本分类方法的步骤。
本实施例还提供一种计算机可读的存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述一种小样本文本分类方法的步骤。
实施例2
本实施例提供一种小样本文本分类装置,如图3所示,所述装置包括:
获取分类模块,用于获取文本数据集,对文本数据及进行分类,获得小样本文本数据集;
预处理模块,用于对小样本文本数据集中的文本数据预处理,获得文本数据的词向量和句向量表征形式;
划分计算模块,用于划分句子节点,计算句子节点间的权重;
累加排序模块,用于计算句子节点的累加权重,并按照累加权重的数值从大到小对句子节点进行排序,获得最终句向量;
训练测试模块,选定分类器,利用最终句向量对分类器进行训练,利用文本数据集中的文本数据对分类器进行性能测试。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 一种小样本文本分类方法、装置、计算机设备和存储介质
- 文本分类方法、文本分类装置、计算机设备及存储介质