一种张量数据的数据载入装置及方法
文献发布时间:2023-06-19 11:29:13
技术领域
本发明属于计算机硬件、人工神经网络算法部署硬件加速的领域,数字集成电路设计领域,具体涉及一种深度卷积神经网络硬件加速芯片的输入系统的架构设计方法、及其装置。
背景技术
深度卷积神经网络算法由多层具体的神经元算法层、隐藏层组成,主要包含有卷积层,主要算子为矩阵或向量的卷积计算。该计算任务的主要特点为输入的数据量大、输入数据具有空间特征信息的耦合,且每次卷积计算的数据往往与已经计算过的数据发生重叠,输入数据往往为从张量格式的数据中以一定空间规律抽取所需要的计算数据。
近年来在终端部署人工神经算法已经成为广泛需求,但在相关场景下,加速芯片的性能、成本因素成为制约需求的主要因素。专利文件1(公开号CN105488565A)公开了一种加速深度神经网络算法的加速芯片的运算装置及方法,为克服大量的中间值被生成并需要存储,从而所需主存空间增加的问题,其运算装置中均设置有中间值存储区域,这些区域被配置为随机存储器,以减少对主存储器的中间值读取和写入次数,降低加速器芯片的能量消耗,避免数据处理过程中的数据缺失和替换问题。专利文件2(申请公布号CN107341544A)公开了一种基于可分割阵列的可重构加速器及其实现方法,设计了便笺式存储器缓存区,用于实现数据重用。专利文件3(公开号USB0170103316A1)公开了一种卷积神经网络加速器的方法、系统及装置,在其中设计了Unified Buffer。专利文件4(公开号US20180341495A1)公开了一种卷积神经网络加速器及方法,其中采用cache装置来提供并行加速所需数据。这些发明都非常优秀,已开展在服务器、数据中心以及高端智能手机上的应用,但在终端的应用还有问题。
在终端部署人工神经算法,其需求特征为,由于加速芯片的硬件资源有限,必需要将数据进行分割处理,并尽量减少数据的膨胀;而对于不同领域和产业场景所常用的人工神经网络算法不同,这种处理应为一套简单、便于实现的方法,否则仍难以“落地”。在专利文件1和3所述发明中,由于不同神经网络算法层尺寸不一、数据重用度不同而导致加速器资源的浪费,以至于需要配合其他异构处理器来帮助解决数据相关的问题,要么就是依靠更深亚微米高成本先进工艺来提升性能;专利3所述的存储方式需要备份更多数据,导致Buffer尺寸太大;专利2的方法采用可重构计算思想,虽然极为注重节省资源浪费,但其数据分割和排布方法很复杂,需配合先进的计算任务部署编译器来辅助应用;专利4的发明与中央处理器的设计过于耦合,同时设计实现复杂度过高。
发明内容
本发明提供一种对深度卷积神经网络计算加速的、结合主存储器的数据载入装置的硬件电路设计及方法,
以降低硬件电路设计的复杂度、降低芯片的面积和功耗,同时还能提供高吞吐率、高性能的并行数据带宽,提高芯片的计算资源与内存带宽利用率,降低应用的复杂度与成本。
为实现上述目的,本发明结合可伸缩的并行数据载入装置,提供了一种再结合主存储器的数据载入装置,该数据载入装置包括:
张量型随机访问控制器,对来自主存储器或/和其他存储器的输入数据进行融合、排布以及数据格式转化,再分发到输入缓存单元的分割区域中,所述工作模式可通过软件重配置;
可分割输入缓存单元,是本发明所述的数据载入装置的本地缓存,由多个存储页组成,设计及存储方法与输入数据的维度以及并行输入寄存阵列相对应,支持所述软件重配置带来的数据格式的改变;
张量型数据载入装置,通过改变对可分割输入缓存单元各个存储页的访问格式,完成对张量数据的融合或重排,同时还具有数据补齐(padding)功能,再将处理后的数据载入到并行输入寄存阵列;
并行输入寄存阵列,向对深度卷积神经网络并行加速计算单元阵列进行高带宽的数据输入。
对于主存储器或/和其他存储器中存储的关于深度卷积神经网络算法层所输出的特征图,该装置提供数据重排布的缓存及快速寄存区域,简化了输入数据排布的难度;其中的可分割输入缓存单元可以被反复访问,被再访问的数据格式更为规整;当其中的数据已经作废时,可重新从主存储器或/和其他存储器中高效的写入新数据。
本发明提供一种数据载入装置设计方法,将本地缓存单元分割为多个存储页,可由张量型输入缓存随机访问控制器并行访问多个页;存储页及张量型数据载入装置的设计与并行输入寄存阵列的伸缩性相对应,满足特定的设计公式。该设计方法能够化简该装置中的硬件电路复杂度,降低面积和功耗。
本发明的效果在于:
1、简化了硬件并行计算单元阵列与输入装置之间的连接复杂度
2、简化了输出装置与主存储之间排布数据的空间复杂度
3、简化了软件排布数据、划分数据宏块的地址计算复杂度
4、提高了硬件并行计算单元阵列的实际应用效率
5、更适合在低成本嵌入式ASIC芯片上实现。
附图说明
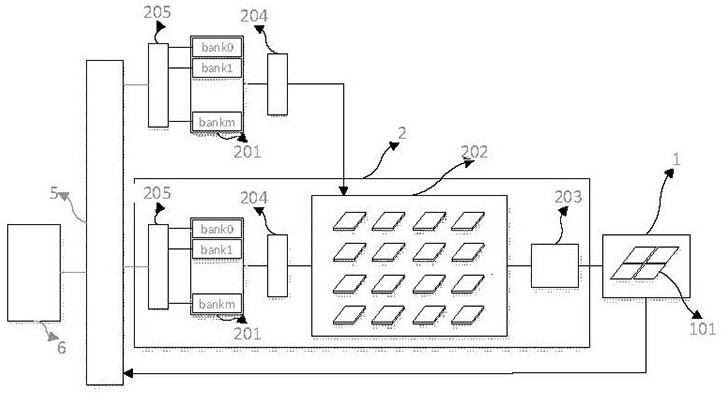
图1为本发明一种数据输入装置的结构图;
图2为本发明所述张量型数据载入装置与存储页及可伸缩并行输入寄存阵列之间的结构及设计方法图;
图3为本发明所述张量型数据载入装置与存储页及可伸缩并行输入寄存阵列之间的具体结构图;
图4为本发明结合主存储器的数据载入方法图;
附图标记说明
1并行硬件计算单元阵列(Process Elements Array,PEA)
101卷积计算单元(Process Element, PE)
2结合主存储器的数据输入装置
201可分割输入缓存单元
202可伸缩并行输入寄存阵列
204张量型数据载入装置(LDI)
205张量型输入缓存随机访问控制器
5高性能片上数据总线
6主存储器及其控制器。
具体实施方式
下面通过附图和实施例,对本发明进一步详细描述。
图1为本发明一种再结合主存储器的数据载入装置结构图,该数据载入装置2包括:
张量型输入缓存随机访问控制器205,对来自主存储器6或/和其他存储器的输入数据进行融合、排布以及数据格式转化,再分发到输入缓存单元201的分割区域中,所述工作模式可通过软件重配置;
可分割输入缓存单元201,是本发明所述的数据载入装置的本地缓存,由多个存储页组成,设计及存储方法与输入数据的维度以及并行输入寄存阵列202相对应,支持所述软件重配置带来的数据格式的改变;
张量型数据载入装置204,通过改变对可分割输入缓存单元201各个存储页的访问格式,完成对张量数据的融合或重排,同时还具有数据补齐(padding)功能,再将处理后的数据载入到并行输入寄存阵列202;
并行输入寄存阵列202,向对深度卷积神经网络并行加速计算单元阵列进行高带宽的数据输入。
对于主存储器6或/和其他存储器中存储的关于深度卷积神经网络算法层之前一隐含层所输出的特征图,该装置提供数据重排布的缓存及快速寄存区域,简化了输入数据排布的难度;其中的可分割输入缓存单元201可以被反复访问,被再访问的数据格式更为规整;当其中的数据已经作废时,可重新从主存储器6或/和其他存储器中高效的写入新数据。
本发明提供一种对应可伸缩的并行输入寄存阵列设计可分割的输入缓存的方法:假设并行输入寄存阵列202例化有行、列表示为Rh、Rw个输入寄存器,则输入缓存201的分页数目也设计为Rh个bank页;假设输入数据位宽为DW,并行输入寄存阵列202每次装填可供并行加速计算阵列1连续加速计算Bw*Bh次,则装填并行输入寄存阵列202的位宽计算方法为⌈Rw/Bw⌉*DW;依据并行加速计算单元阵列1的并行度P以及卷积核最小尺寸Kmin,可折中选定Bw*Bh;考虑到与主存储系统设计所需缓冲深度tm,每bank页的深度为tm*Rw。图2解释了本设计方法的对应关系。
图2为本发明所述张量型数据载入装置204与存储页201及可伸缩并行输入寄存阵列202之间的结构及设计方法图:张量型数据载入装置包含几组同样且并行工作的读写单元,组的数目与每个PE在IRA对应需要访问的输入数据的范围有关,为⌈2/Rh⌉+K,每一LDI读写组单元对应并行输入寄存阵列的Bh行进行操作;工作方法为先写并行输入寄存阵列的对应行,每次写⌈Rw/Bw⌉*DW、写Bw次后写完这一行,再写下一行,直到写完对应的Bh行,则当前的IRA装填完毕;该所述张量型数据载入装置204中的一个LDI读写组单元所对应的Bh行的分布,是依据IRA与PEA工作特征所决定的区域大小、采取跨区域间隔分布的;所有的LDI读写组单元并行写入IRA,当写完一行时,可供并行计算单元阵列PEA至少完成一次矩阵卷积计算的数据已被装填完毕。图3具体解释了本设计方法的对应关系。
图4为本发明结合主存储器的数据载入方法及流程图:
首先,输入数据在主存储器中按照扫描顺序正常摆放,按照2维格式进行编码,如图所示,r表示输入数据图,数字表示编址;
依据本发明装置中并行输入寄存阵列的寄存规模,将输入数据进行切块;
启动张量型输入缓存随机访问控制器205,根据切割的输入数据块的首地址与张量读取方式对其进行配置,由该访问控制器完成对输入数据的张量操作,例如融合、转置等;
配置张量型输入缓存随机访问控制器205的写入模式,按照bank分页依次写入,同时对数据进行一定规律的重排列,满足本发明所述的缓存数据排列方式。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种张量数据的数据载入装置及方法
- 基于数据载入存储空间的数据查询方法和装置