一种基于大数据的企业信用评价指标系统
文献发布时间:2023-06-19 11:32:36
技术领域
本发明属于数据处理技术领域,特别涉及一种基于大数据的企业信用评价指标系统。
背景技术
国内目前主流的中小微企业信用评价模型技术主要采用在原有针对国有企业、大型企业的信用评级体系中加入新的指标变量的途径建立模型,例如舒歆(2015)通过Logistic模型回归分析小微企业违约状况与影响小微企业违约的各个因素之间的因果关系,建立了由偿债能力、盈利能力营运能力、创新能力、成长能力、法人治理、信用情况等七大类反应中小微企业资信状况的指标体系。并且已有技术在数据的选择上受到我国中小微企业数据封锁等限制,主要以资产负债率等传统用于大中企业的评价指标搭建模型,得到的结果难以真实反应中小微企业的生产经营状况与信用水平,在以大数据技术破解中小微企业首贷难问题上实用价值较低。
发明内容
本发明的目的在于提供一种基于大数据的企业信用评价指标系统,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:
一种基于大数据的企业信用评价指标系统,包括数据获取模块,用于获取企业客群数据信息,所述企业客群数据信息包括授信企业客群数据信息和非授信企业客群数据信息;数据处理模块,用于对获取的授信企业客群数据信息进行分层采样,获取建模分析样本;数据清洗模块,用于发现并纠正建模分析样本/非授信企业客群数据信息中可识别的数据错误,得到第一数据/预测数据;特征工程模块,用于对第一数据/预测数据进行处理,获得第二数据/模型指标;应用模块,用于接收第二数据/模型指标,并依据逻辑回归算法,从而验证授信企业客群数据信息的信用评价的特征指标/预测非授信企业客群的信用评分。
进一步地,所述特征工程模块包括特征衍生模块、特征分箱模块和特征筛选模块;其中,特征衍生模块,用于将企业各维度数据通过多项式变换计算、时间窗口统计汇总等方式获取更多表征企业行为的新特征,特征分箱模块,用于对连续特征离散化,特征筛选模块,根据特征重要度、线性相关性等指标来选择更重要且更能反应企业还款能力和还款意愿的特征,提高模型泛化能力的同时降低计算复杂度。
进一步地,所述特征分箱模块通过特征IV值衡量特征在系统中的重要度与贡献度,采用如下公式:
其中,B
进一步地,所述模型指标为覆盖企业基本信息、资产行为状况、经营收入指标以及社会信用表现四大数据维度中的一种或多种。
进一步地,所述数据清洗模块具体的工作步骤如下:
S1:对数据中的无效值进行处理;
S2:处理数据中的缺失值;通过计算每个字段的缺失率,结合字段的重要性,进行缺失补充;
S3:根据检查数据中变量的合理取值范围和相互关联性,对数据的一致性的检查;
S4:其他缺陷进行修正。
进一步地,步骤S4中的其他缺陷包括格式内容处理以及去重记录处理等。
进一步地,所述建模分析样本包括训练样本和验证样本,具体划分的工作步骤如下:
SS1:将数据获取模块获取的授信企业数据按照授信情况划分成好样本G和坏样本B;
SS2:分别抽取50%的好样本G和坏样本B成为训练样本,即0.5G+0.5B,样本总数中剩余的均划分成验证样本中。
与现有技术相比,本发明的有益效果是:能够有效预测中小微企业的贷款行为表现,并对违约客群与非违约客群产生明显的区分度,在解决中小微企业首贷准入以及银行首贷获客方面破解了已有方法的阻碍,具有相当的可行性和落地应用价值。
附图说明
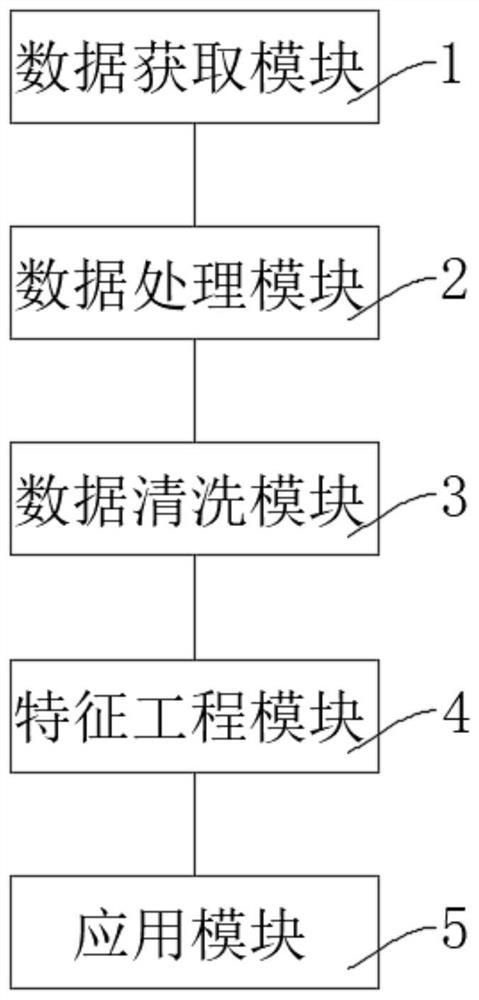
图1是本发明整体流程示意图;
图2是本发明中特征工程模块的架构示意图;
图3是本发明中补充策略组合图。
图中:1-数据获取模块;2-数据处理模块;3-数据清洗模块;4-特征工程模块;40-特征衍生模块;41-特征分箱模块;42-特征筛选模块;5-应用模块。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚,完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部实施例。
实施例:
本实施例中关于企业客群数据信息的主体以中小微企业为例,如图1所示的一种基于大数据的企业信用评价指标系统,包括:
包括数据获取模块1,用于获取企业客群数据信息,所述企业客群数据信息包括授信企业客群数据信息和非授信企业客群数据信息;
数据处理模块2,用于对获取的授信企业客群数据信息进行分层采样,获取建模分析样本;
数据清洗模块3,用于发现并纠正建模分析样本/非授信企业客群数据信息中可识别的数据错误,得到第一数据/预测数据;
特征工程模块4,用于对第一数据/预测数据进行处理,获得第二数据/模型指标;
应用模块5,用于接收第二数据/模型指标,并依据逻辑回归算法,从而验证授信企业客群数据信息的信用评价的特征指标/预测非授信企业客群的信用评分;
其中,所述建模分析样本包括训练样本和验证样本,具体划分的工作步骤如下:
SS1:将数据获取模块1获取的授信企业数据按照授信情况划分成好样本G和坏样本B;
SS2:分别抽取50%的好样本G和坏样本B成为训练样本,即0.5G+0.5B,样本总数中剩余的均划分成验证样本中;
其次,所述模型指标为覆盖企业基本信息、资产行为状况、经营收入指标以及社会信用表现四大数据维度中的一种或多种。
通过上述的方案,能够有效预测中小微企业的贷款行为表现,并对违约客群与非违约客群产生明显的区分度,在解决中小微企业首贷准入以及银行首贷获客方面破解了已有方法的阻碍,具有相当的可行性和落地应用价值。
在本实施例中,所述应用模块5的训练步骤包括如下内容:
(1)将筛选的特征放入logistic模型进行训练,通过调试正则化罚项、好坏样本权重对模型进行调整,使其输出违约概率ln(odds);
ln(odds)=β
其中,[x
(2)然后对logistic模型输出的违约概率ln(odds)进行线性映射;如下公式:
score=A-B×ln(odds);
其中,A表示基准信用分数,B表示信用分数缩放权重。
在本实施例中,所述数据清洗模块4具体的工作步骤如下:
S1:对数据中的无效值进行处理;其中,无效值即不需要的字段,例如:无用的自增序号、主管机构、记录人员信息等,在本步骤中,直接将其删除;
S2:处理数据中的缺失值;通过计算每个字段的缺失率,结合字段的重要性,进行缺失补充,补充策略参考图3;
S3:根据检查数据中变量的合理取值范围和相互关联性,对数据的一致性的检查;例如本实施例的数据源中法定代表人年龄、销售收入出现了负值,应视为超出正常值域范围,另外,本实施例的数据源中企业注册资本和实缴资本同时来自于企业基本信息表、登记信息表两个表,而且两张表中的取值不一样,经过分析发现企业基本信息表的更新时间大于登记信息表的更新时间,并且和业务人员确认是因为登记信息表的更新频率滞后,因此本系统取企业基本信息表的注册资本和实缴资本数据为最新数据;
S4:其他缺陷进行修正。
其中,S3的工作过程具体来说,例如数据源中法定代表人年龄、销售收入出现了负值,应视为超出正常值域范围,由于数据库中这样的样本较少,因此采取直接删除方式,针对同一个变量有多个数据来源的情况进行关联性验证:例如本技术数据源中企业注册资本和实缴资本同时来自于企业基本信息表、登记信息表两个表,而且两张表中的取值不一样,经过分析发现企业基本信息表的更新时间大于登记信息表的更新时间,并且和业务人员确认是因为登记信息表的更新频率滞后,因此本体系取企业基本信息表的注册资本和实缴资本数据为最新数据。
结合图2可知,所述特征工程模块4包括特征衍生模块40、特征分箱模块41和特征筛选模块42;所述特征衍生模块40、特征分箱模块41和特征筛选模块42依次信号连接。
其中,特征衍生模块40,用于将企业各维度数据通过多项式变换计算、时间窗口统计汇总等方式获取更多表征企业行为的新特征,特征分箱模块41,用于对连续特征离散化,特征筛选模块42,根据特征重要度、线性相关性等指标来选择更重要且更能反应企业还款能力和还款意愿的特征,提高模型泛化能力的同时降低计算复杂度。
值得注意的是,在本实施例中,采用卡方分箱算法对特征进行离散化处理,所述特征分箱模块41通过特征IV值衡量特征在系统中的重要度与贡献度,采用如下公式:
其中,WOE
在本实施例中,步骤S4中的其他缺陷还包括格式内容处理以及去重记录处理等;例如:多张原始表的存储日期以及格式都不一致,通过时间转换格式将所有日期格式进行统一。
本发明的描述中,需要理解的是,术语“中心”、“横向”、“上”、“下”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明的描述中,除非另有说明,“若干个”的含义是两个或两个以上。另外,术语“包括”及其任何变形,意图在于覆盖不排他的包含。
本发明按照实施例进行了说明,在不脱离本原理的前提下,本发明还可以作出若干变形和改进。应当指出,凡采用等同替换或等效变换等方式所获得的技术方案,均落在本发明的保护范围内。
- 一种基于大数据的企业信用评价指标系统
- 一种基于大数据分析的企业信用评价系统