基于BERT-A-BiLSTM的多特征专利自动分类算法
文献发布时间:2023-06-19 11:32:36
技术领域
本发明属于专利自动分类技术领域,具体涉及基于BERT-A-BiLSTM的多特征专利自动分类算法。
背景技术
现有的专利自动分类算法进行文本向量化时大都采用Word2vec、GloVe等静态词向量技术,不能根据上下文的变化动态的改变词向量解决一词多义问题,Word2vec模型训练的词向量不能跟随文本中上下文语境的变化而动态的改变,无法解决一词多义的问题,并且专利摘要文本具有专业领域相关词汇多、文本长度短的特点,仅通过语义特征难以对专利类别进行准确的划分,从而影响整体算法的分类性能。同时,处理专利文本序列数据时,双向长短时记忆神经网络进行文本特征提取,使用最后一个时序输出的结果作为最终特征提取的结果,但该特征难以包含文本的全部信息以导致丢失文本的部分信息,影响最终的分类效果的问题。
发明内容
本发明的目的在于提供基于BERT-A-BiLSTM的多特征专利自动分类算法,以解决上述背景技术中提出的问题。
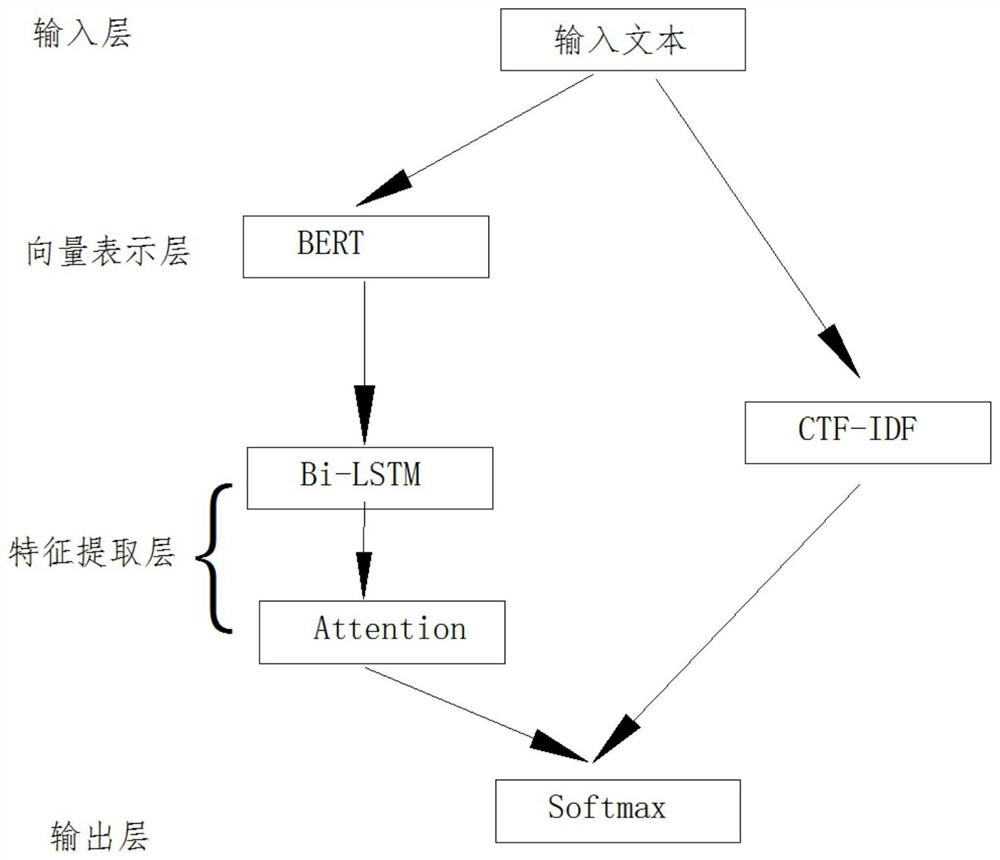
为实现上述目的,本发明提供如下技术方案:基于BERT-A-BiLSTM的多特征专利自动分类算法,包括BERT-A-BiLSTM的多特征分类算法模型构建、实验设计与对比分析,其特征在于:所述BERT-A-BiLSTM的多特征分类算法模型构建包括“文本向量化表示层”、“文本特征提取层”、“输出层”,所述“文本向量化表示层”的输入数据中的字符映射为“字向量”,“段向量”,“位置向量”,三个向量输入Transformer编码器中,Transformer编码器由多个“注意力机制层(Multi-Head Attention)”、前馈神经网络层(Feed Forward)和“LayerNormalization层”连接而成,所述“文本特征提取层”由“BiLSTM-Attention的语义特征提取模块”和“CTF-IDF的统计特征提取模块”组成,并通过所述“输出层”进行分类,并通过实验设计,将SVM、Word2vec-BiLSTM、BERT-BiLSTM、BERT、BERT-A-BiLSTM作为对比试验进行对比分析,并通过与SVM、Word2vec-BiLSTM、BERT-BiLSTM、BERT、BERT-A-BiLSTM等算法进行对比试验,分析本发明的优越性。
作为一种优选的实施方式,所述“Multi-Head Attention特征提取”公式为MultiHead(Q,K,V)=Concat(head
作为一种优选的实施方式,所述“BiLSTM-Attention的语义特征提取模块”通过“长短期记忆神经网络(LSTM)”进行语义特征的提取,所述“记忆神经网络(LSTM)”内部公式为输入门:i
作为一种优选的实施方式,所述LSTM最终输出的向量集合
作为一种优选的实施方式,Attention机制为BiLSTM每个时刻的输出分配权重,公式为S
作为一种优选的实施方式,所述“CTF-IDF的统计特征提取模块”,通过定义CTF的词频,进而提取类别文件中关键词出现的次数,并通过IDF对为本中的关键词权重“V
作为一种优选的实施方式,所述“输出层”由“全连接层加Softmax函数”组合而成,通过所述“全连接层加Softmax函数”将语义特征提取层中的输出和统计特征提取层的输出拼接作为本层的输入,Softmax函数为
作为一种优选的实施方式,所述实验设计与对比分析包括“实验环境”、“实验数据”、“试验参数”、“对比实验”、“实验结果与分析”。
作为一种优选的实施方式,所述“实验环境”采用TensorFlow作为Keras的后端,使用Keras对网络层、优化器、激活函数等进行调用。
作为一种优选的实施方式,所述“实验数据”采用IPC分类体系。
与现有技术相比,本发明的有益效果是:
通过BiLSTM算法和Attention机制提取专利文本语义特征,将提取的语义特征与本文改进型TF-IDF算法提取的文本统计特征进行融合,最后将文本的融合特征输入到Softmax分类器中得到分类结果,该算法可以有效地提升专利的分类效果。
附图说明
图1为本发明模型结构示意图;
图2为本发明LSTM结构图;
图3为本发明BiLSTM模型结构图;
图4为本发明BERT结构示意图;
具体实施方式
下面结合实施例对本发明做进一步的描述。
以下实施例用于说明本发明,但不能用来限制本发明的保护范围。实施例中的条件可以根据具体条件做进一步的调整,在本发明的构思前提下对本发明的方法简单改进都属于本发明要求保护的范围。
请参阅图1-4,本发明提供基于BERT-A-BiLSTM的多特征专利自动分类算法,基于BERT-A-BiLSTM的多特征专利自动分类算法,包括BERT-A-BiLSTM的多特征分类算法模型构建、实验设计与对比分析,其特征在于:所述BERT-A-BiLSTM的多特征分类算法模型构建包括“文本向量化表示层”、“文本特征提取层”、“输出层”,所述“文本向量化表示层”的输入数据中的字符映射为“字向量”,“段向量”,“位置向量”,三个向量输入Transformer编码器中,Transformer编码器由多个“注意力机制层(Multi-Head Attention)”、前馈神经网络层(Feed Forward)和“Layer Normalization层”连接而成,所述“Multi-Head Attention特征提取”公式为MultiHead(Q,K,V)=Concat(head
在本实施例中,BERT-A-BiLSTM的多特征分类算法模型构建包括“文本向量化表示层”、“文本特征提取层”、“输出层”,“文本向量化表示层”的数据中的字符映射为“字向量”,“段向量”,“位置向量”,三个向量输入Transformer编码器中,并通过“注意力机制层(Multi-Head Attention)”和“Layer Normalization层”进行连接,并通过“Multi-HeadAttention特征提取”进行特征提取,“文本特征提取层”由“BiLSTM-Attention的语义特征提取模块”和“CTF-IDF的统计特征提取模块”组成,并通过“输出层”进行特征提取的输出并通过实验设计与对比分析进行SVM、Word2vec-BiLSTM、BERT-BiLSTM、BERT、BERT-A-BiLSTM作为对比试验。
其中,“Multi-Head Attention特征提取”公MultiHead(Q,K,V)=Concat(head
其中,“BiLSTM-Attention的语义特征提取模块”通过“长短期记忆神经网络(LSTM)”进行语义特征的提取,“长短期记忆神经网络(LSTM)”内部公式为输入门:i
LSTM最终输出的向量集合
其中,Attention机制为BiLSTM每个时刻的输出分配权重,公式为S
其中,“CTF-IDF的统计特征提取模块”,通过定义CTF的词频,进而提取类别文件中出现的次数,并通过IDF对为本中的关键词权重“V
其中,“输出层”由“全连接层加Softmax函数”组合而成,通过“全连接层加Softmax函数”将语义特征提取层中的输出和统计特征提取层的输出拼接作为本层的输入,Softmax函数为
其中,实验设计与对比分析包括“实验环境”、“实验数据”、“试验参数”、“对比实验”、“实验结果与分析”,通过“实验结果与分析”有效提高算法的稳定性。
其中,所述“实验环境”采用TensorFlow作为Keras的后端,使用Keras对网络层、优化器、激活函数等进行调用。
其中,“实验数据”采用IPC分类体系,通过IPC分类标准包括部、大类、小类、大组和小组五个等级,由部到小组,其内容划分越来越详细,专利之间的相似性也越来越高。
本发明的工作原理及使用流程:首先将文本数据通过BERT模型转化为深度神经网络可识别的向量形式,用BERT模型训练出来的词向量可以根据上下文的语境实现动态改变从而更好的完成下游的文本分类任务;其次将经过向量化的文本数据输入BiLSTM神经网络中,BiLSTM对序列化的文本数据信息从前后两个方向进行语义特征的提取,通过“注意力机制层(Multi-Head Attention)”和“Layer Normalization层”进行连接,并通过“Multi-Head Attention特征提取”进行特征提取,“文本特征提取层”由“BiLSTM-Attention的语义特征提取模块”和“CTF-IDF的统计特征提取模块”组成,并通过“输出层”进行特征提取的输出并通过实验设计与对比分析进行SVM、Word2vec-BiLSTM、BERT-BiLSTM、BERT、BERT-A-BiLSTM作为对比试验,最后将特征提取层的结果输入到Softmax分类层得到分类结果。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 基于BERT-A-BiLSTM的多特征专利自动分类算法
- 一种基于专利数据库的企业专利年费缴纳自动提醒系统