基于多区域注意力机制的人脸伪造检测方法
文献发布时间:2023-06-19 11:32:36
技术领域
本发明涉及人脸伪造检测技术领域,尤其涉及一种基于多区域注意力机制的人脸伪造检测方法。
背景技术
人脸伪造指使用计算机技术对图像或视频等媒体中的人脸区域进行篡改,包括身份替换和表情编辑,人脸伪造技术可以应用于影视后期处理中。随着深度学习技术在图像生成领域的巨大发展,生成对抗网络以及自编码器被应用于人脸伪造领域以生成人眼难以辨别的人脸伪造图片或视频,例如Deepfakes、FSGAN、FaceShifter等。许多人脸伪造程序可以在互联网上获取,使得任何人经过简单的学习就可以使用个人计算机合成出以假乱真的伪造视频。这些伪造视频现在已经广泛出现在互联网上。如果这种技术被用于散播谣言,伪造证据等非法活动,则会造成非常严重的社会危害。因此,人脸伪造视频检测技术的研究取得了学术界的广泛关注。目前主流的人脸伪造检测算法是使用基于深度神经网络的人脸检测器和伪造人脸分类器。
神经网络模型通过在大规模的伪造人脸数据集上训练可以捕捉能有效区分真实人脸和伪造人脸的特征。通用的图像分类网络在检测伪造人脸的任务中的效果有一定的局限性,尤其是在检测经过压缩的视频以及未在训练集中出现过的伪造方法时。高质量的伪造人脸中只有较小的区域具有明显的判别性,因此Dang等人提出了使用注意力机制增强人脸伪造检测网络的准确性,在计算机视觉中,注意力机制是一个广泛的概念,此处指的是基于位置的柔性注意力,为特征图中的每个位置乘一个权重;但是,该方案:1)仅使用深层特征忽视了纹理信息;2)只有一个注意力区域,忽视了局部特征;,因此检测结果的准确性还有待提升。
发明内容
本发明的目的是提供一种基于多区域注意力机制的人脸伪造检测方法,该方法具有多个注意力区域,每个区域能够提取彼此独立的特征以使网络更加关注局部纹理信息,从而提升检测结果的准确性。
本发明的目的是通过以下技术方案实现的:
一种基于多区域注意力机制的人脸伪造检测方法,包括:
将待检测的人脸图像输入至卷积神经网络,获得浅层、中间层和深层特征图;
对浅层特征图进行纹理增强操作,获得纹理特征图;对中间层特征图通过多注意力机制生成多区域注意力图;使用多区域注意力图对纹理特征图进行注意力池化,得到局部纹理特征,以及将多区域注意力图相加后对深层特征图进行注意力池化得到全局特征;将全局特征与局部纹理特征融合后进行分类,获得人脸伪造检测结果。
由上述本发明提供的技术方案可以看出,一方面,可以与传统卷积神经网络主干联合使用,以提高在人脸伪造检测任务中的准确率。另一方面,利用不同区域的局部纹理特征以及全局的深层特征对输入的人脸图像进行分类,能够提升分类结果的准确性。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他附图。
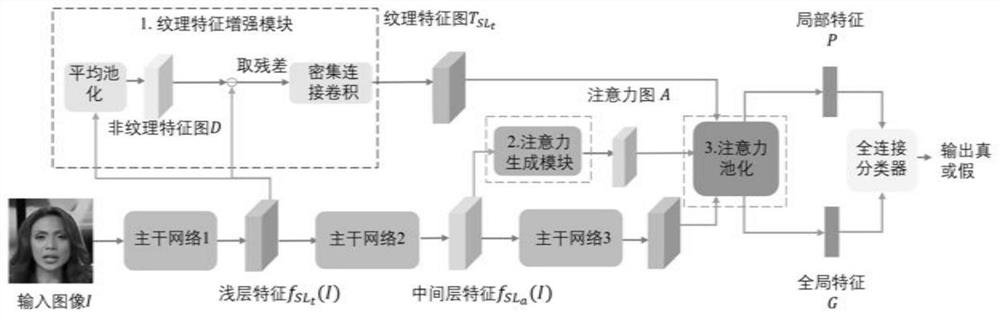
图1为本发明实施例提供的一种基于多区域注意力机制的人脸伪造检测方法的网络整体结构图;
图2为本发明实施例提供的注意力生成模块与注意力池化模块的示意图;
图3为本发明实施例提供的通过弱监督学习得到的各判别性区域的可视化示例。
具体实施方式
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明的保护范围。
本发明实施例提供一种基于多区域注意力机制的人脸伪造检测方法,与传统方法相比,本发明提出的方法具有多个注意力区域,每个区域能够提取彼此独立的特征以使网络更加关注局部纹理信息。如图1所示,该方法主要包括:将待检测的人脸图像输入至卷积神经网络,获得浅层、中间层和深层特征图;对浅层特征图进行纹理增强操作,获得纹理特征图;对中间层特征图通过多注意力机制生成多区域注意力图;使用多区域注意力图对纹理特征图进行注意力池化,得到局部纹理特征,以及将多区域注意力图相加后对深层特征图进行注意力池化得到全局特征;将全局特征与局部纹理特征融合后进行分类,获得人脸伪造检测结果。
本发明实施例所提供的上述方案,可以与传统卷积神经网络主干联合使用,以提高在人脸伪造检测任务中的准确率;而且利用不同区域的局部纹理特征以及全局的深层特征对输入的人脸图像进行分类。与现有技术相比,本方法在多种公开的Deepfake检测数据集取得了更高的准确度和迁移性。
为了便于理解,下面针对本发明实施例上述方案做详细的介绍。
一、整体网络及其组成。
图1示出了整个网络结构,主要包括:卷积神经网络的主干、以及纹理增强模块、注意力生成模块、注意力池化模块以及全连接分类器。主要介绍如下:
1、卷积神经网络。
卷积神经网络可以为传统方案中用于人脸伪造检测任务的卷积神经网络,主干部分主要是指特征提取部分。卷积神经网络的主干部分提取的浅层、中间层和深层特征图,将对应的输入至纹理增强模块、注意力生成模块及注意力池化模块。
本领域技术人员可以理解,卷积神经网络一般由相似的N层堆叠而成,由于本发明的方法不局限于使用特定的卷积神经网络为主干,因此,浅层、中间层和深层是相对而言的概念。由于特征提取部分为多层结构,因此,浅层、中间层和深层表示层次逐渐加深,举例来说,浅层可以是第一层或者第二层,深层可以是最后一层或者倒数第二层,中间层则是位于浅层与深层之间的任一层。如后文实验中提供了以EfficientNet为主干的一种具体示例,浅层指第二个block,中间层指第五个block,深层指第七个(即最后一个)block。
2、纹理增强模块。
纹理增强模块,主要是通过提取卷积神经网络特征图的残差,增强特征图对人脸伪造的纹理特征的敏感性,可以使用密集连接的卷积层来提取和增强纹理信息。
观察到由伪造方法引起的轻微伪影往往保留在浅层特征的纹理信息中。这里,纹理信息代表浅层特征的高频成分,类似于RGB图像的残差信息。因此,浅层特征应该得到关注和增强。如图1所示,通过纹理增强模块对浅层特征图进行纹理增强操作,主要步骤包括:对浅层特征图进行局部平均池化,得到非纹理特征图D;将浅层特征图与非纹理特征图D的残差输入至密集连接的卷积层,得到纹理特征图。
本领域技术人员可以理解,密集连接是本领域的专用术语,英文为denseconnection,具体来说,它是DenseNet网络提出的结构,与常规卷积网络区别于:常规的卷积神经网络处理流程是多层串行的,在密集连接的结构中,每一层的输入包含之前所有层的输出。
3、注意力生成模块。
真实与伪造人脸的差异通常在不同面部区域表现为不同的特征,不容易被单注意力结构捕获。因此,使用多区域注意力代替全局平均池化可以提高人脸伪造检测网络的判别性。
如图2所示,通过注意力生成模块对中间层特征图通过多注意力机制生成多区域注意力图;所述注意力生成模块包括依次设置的卷积层(具体可以为1×1卷积层)、批归一化层和非线性激活层(ReLU)。中间层特征图将通过注意力生成模块,可以获得大小为Ht×Wt的M个区域注意力图A。
4、注意力池化模块。
本发明实施例中,注意力池化模块使用多区域注意力图对纹理特征图进行注意力池化,得到局部纹理特征,以及使用多区域注意力图相加后对深层特征图进行注意力池化得到全局特征。
本发明实施例中,使用双线性注意力池化(BAP)代替了全局平均池,将BAP应用于浅层和深层特征图从浅层收集纹理特征并保留更深层的语义特征。具体来说:如果多区域注意力图的分辨率与纹理特征图的分辨率不匹配,则将多区域注意力图映射到与纹理特征图相同的分辨率;然后,将纹理特征图分别与每个区域注意力图相乘,得到多个部分纹理特征图;将所有的部分纹理特征图做全局平均池化后进行L
本发明实施例中,具有多个注意力图,一般来说每个注意力图在特定区域强度高,其他区域强度低;因此,每一个区域注意力图与纹理特征图相乘后,得到的部分纹理特征图是指,仅保留了相应注意力区域纹理信息的特征图。
5、全连接分类器。
本发明实施例中,使用多层全连接网络来融合全局特征与局部纹理特征,基于融合后的特征进行分类,输出结果表明待检测的人脸图像为真实图像或者伪造图像。
二、损失函数。
本发明实施例中,图1所示的网络模型在在训练中的损失函数包括两部分:交叉熵损失与区域独立性损失。
其中,交叉熵损失为传统损失,可参照常规技术来实现,故不再赘述。下面主要针对区域独立性损失函数做详细的介绍。
区域独立性损失为辅助训练注意力生成模块的损失,由于训练注意力生成模块可能由于缺乏标签引导而容易陷入网络性能下降的情况,即不同的注意力图倾向于集中在同一区域,这不利于网络捕获丰富的局部纹理信息。另外,对于不同的输入图片,希望每个注意力图都位于固定的语义区域,以缩小每个注意力图捕获的信息的随机性。为了实现上述目标,我们提出了区域独立性损失,这有助于减少注意力图之间的重叠并保持不同输入的一致性,区域独立性损失
其中,区域独立性损失
特征中心c为特征V的滑动平均值,更新公式为:
其中,c
在进行分类时,将局部纹理特征与深层特征连接后通过全连接层得到分类结果。本发明实施例中,训练过程使用梯度下降算法优化损失函数
三、注意力引导的数据增强方案。
为了进一步分离不同的注意力图,引入了注意力引导的数据增强,即在训练过程中,对于输入的人脸图像I中一个选中的注意力区域进行高斯模糊,以生成数据增强后的人脸图像I
其中,I
为了应证本发明实施例上述方案的效果,下面结合实验结果进行说明。
实验中,选择Efficient-Net B4作为主干网络,选择第二层特征图(浅层特征图)作为纹理增强模块的输入,第五层特征图(中间层特征图)用于提取注意力图,全局池化前的最后一层作为深层特征图。注意力区域的数量设置为4。
实验中,使用多种公开的人脸伪造检测数据集,按照标准流程对本方法的实例进行训练和测试。表1展示了本方法在FF++数据集高质量(HQ)和低质量(LQ)视频测试中准确率,从表1所示的结果可见,本方法对高质量视频的检测准确率高于其他现有方法。
表1 本方法在FF++数据集上的准确率与其他方法比较
表2展示了本方法在FF++数据集训练后,在Celeb-DF v2数据集迁移测试的准确率。
表2本方法在Celeb-DFv2数据集上的迁移能力与其他方法比较
表3展示了本方法在DFDC比赛私有测试集的测试效果(Logloss,越小表示效果越好)好于比赛中获胜的方法。
表3本方法在DFDC测试集上的Logloss与DFDC比赛获奖方法比较
以上比较结果表明:相对于现有技术,本方法在多种公开的Deepfake检测数据集取得了更高的准确度和迁移性。
图3展示通过弱监督学习得到的各判别性区域的可视化示例,区别于原有方法(Dang等人)需要额外信息来训练注意力,而本发明提供的方法不需要额外信息,因此可称为弱监督学习得到的注意力,图3中的各判别性区域是指不同的注意力区域。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例可以通过软件实现,也可以借助软件加必要的通用硬件平台的方式来实现。基于这样的理解,上述实施例的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是CD-ROM,U盘,移动硬盘等)中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将系统的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明披露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 基于多区域注意力机制的人脸伪造检测方法
- 基于多相关帧注意力机制的人脸伪造视频检测方法