多尺度火灾目标识别方法及系统
文献发布时间:2023-06-19 11:32:36
技术领域
本发明涉及人工智能图像处理领域,具体地,涉及一种多尺度火灾目标识别方法及系统。
背景技术
火在我们人类发展的长河中,起着举足轻重的作用,不仅燃尽了茹毛饮血的历史,也点燃了现代社会的辉煌。但火是双刃剑,既可以带来温暖光明,也会导致痛苦分离。随着社会的不断进步,城市规模的扩大和人口密度的增加,火灾已成为最经常、最普遍地威胁公众安全和社会发展的主要灾害之一。近年来,我国发生了很多火灾事件。据国家消防局发布的2019年全国火灾情况:全年共接报火灾23.3万起,亡1335人,伤837人,直接财产损失36.12亿元。根据上述数据分析发现,火灾主要集中在人员密集场所、仓储物流及高大建筑物内,造成了极大的人员和经济损失,社会影响也越来越大。因此在火灾发生早期,能够发现火灾并及预警,可以极大程度上减少人身财产安全损失,提升人民生活安全感和幸福感。
目前市面上最成熟的火灾探测仍然以感温型、感烟型、感光型等传统的探测技术为主,虽然在一定程度上起到了很好的预警作用,但仍受限于传感器探测的有效距离及环境的复杂性等因素,在火灾发生早期有时难以及时发现并预警。随着人工智能相关技术和理论的迅猛发展,结合模式识别、机器学习等技术,火灾的目标检测也由机器学习取代了传统的概率模型,实现了火灾的多特征融合。近年来,随着深度学习的发展,火灾的特征提取也不再依靠人工进行选择。同时,目标检测领域出现了很多优秀的算法,像SSD(SingleShot MultiBox Detector)、YOLOv4等被相继提出,提升了目标检测的速度。
目前目标检测算法主要分为two-stage和one-stage两种。Two-stage检测算法将检测问题划分为两个阶段,首先产生候选区域(region proposals),然后对候选区域分类,一般还需要对位置精修。而one-stage算法其主要思路是利用CNN(Convolutional NeuralNetworks)提取特征后,均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和不同长宽比的先验框,物体的分类与预测框的回归同时进行,整个过程只需要一步,所以其优势是速度很快。One-stage算法以YOLO(You Look Only Once)系列为代表,尤其是在2020年,Alexey Bochkovskiy等人利用YOLOv4算法论证了目标检测的最佳速度和准确性。YOLOv4目标检测算法使用了Mosaic数据增强、PANet(Path Aggregation Network)结构等来增强数据和特征提取过程。最后利用Yolo Head(You Look Only Once Head)将提取到的不同大小特征层的目标特征进行预测,实现了目标的多尺度识别。然而,在火灾的实际应用中,由于YOLOv4的参数量较大,仍不便于在嵌入式等设备上应用。
针对上述问题,同时为满足火灾实时检测的需求,急需新的方法,能够实现尽可能不降低火灾目标检测的识别准确率同时降低YOLOv4模型的参数量,保证更快的检测速度和更便捷的应用。
发明内容
针对现有技术中的缺陷,本发明的目的是提供一种多尺度火灾目标识别方法及系统。本发明在兼顾现有YOLOv4算法的基础上,有效降低其参数量,保证更快的检测速度和更便捷的应用。
根据本发明提供的多尺度火灾目标识别方法,包括如下步骤:
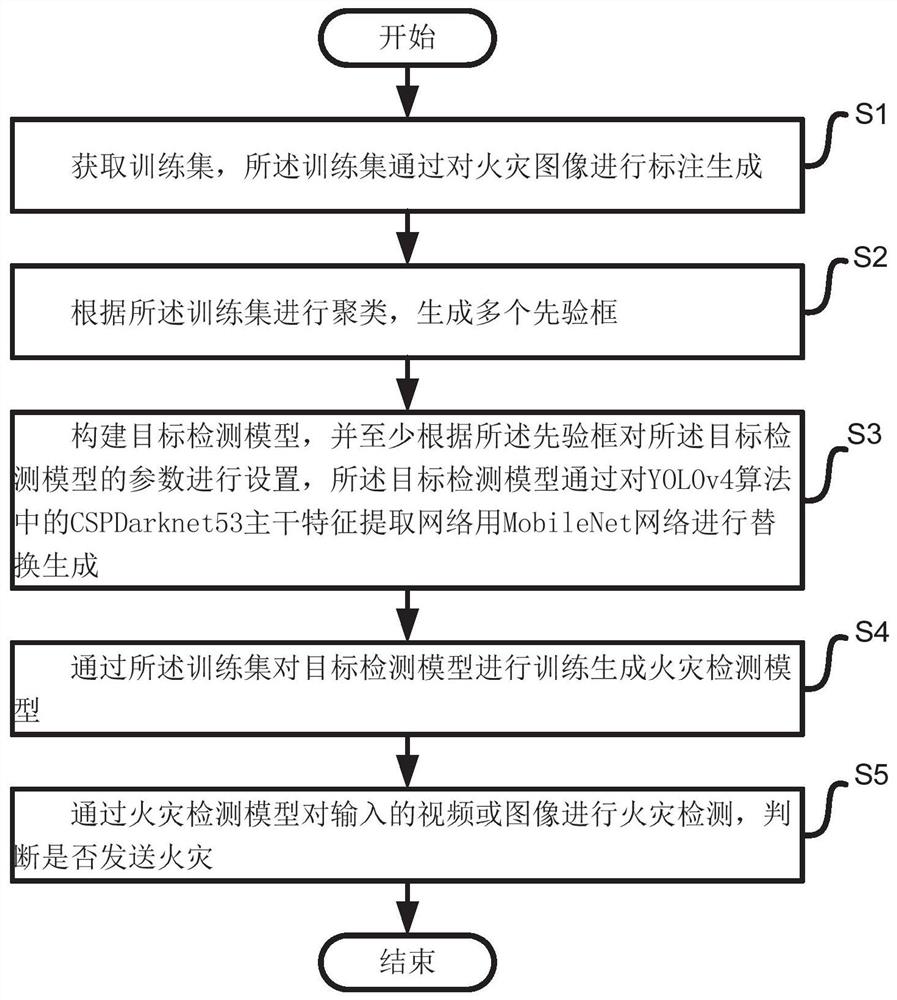
步骤S1:获取训练集,所述训练集通过对火灾图像进行标注生成;
步骤S2:根据所述训练集进行聚类,生成多个先验框;
步骤S3:构建目标检测模型,并至少根据所述先验框对所述目标检测模型的参数进行设置,所述目标检测模型通过对YOLOv4算法中的CSPDarknet53主干特征提取网络用MobileNet网络进行替换生成;
步骤S4:通过所述训练集对目标检测模型进行训练生成火灾检测模型;
步骤S5:通过火灾检测模型对输入的视频或图像进行火灾检测,判断是否发送火灾。
优选地,所述步骤S1包括如步骤:
步骤S101:搜集、拍摄和整理火灾和烟雾图像,形成一个多场景、多尺度、多角度的火灾图像数据集;
步骤S102:利用VOC2007数据集格式,建立文件夹来存放标注后的火灾图像数据;
步骤S103:通过标注工具对所述火灾图像数据集中的火焰和烟雾进行数据标注生成所述训练集。
优选地,所述步骤S2包括如下步骤:
步骤S201:随机选取了9个框作为聚类中心,然后计算其他所有的框和该9个框的距离;
步骤S202:根据所述距离将所有的框划分成9个区域,然后对这9个区域的所有的框之间的距离取平均,重新作为聚类中心;
步骤S203:重复执行步骤S201至步骤S202,直到所述聚类中心不再改变为止。
优选地,所述目标检测模型的参数进行设置时包括如下步骤:
步骤M1:将公开的VOC2007数据集的训练好的权重作为所述目标检测模型的预训练权重;
步骤M2:采用Mosaic数据增强模块实时对火灾图像数据增强的随机预处理;
步骤M3:通过标签平滑模块对所述目标检测模型的过拟合进行控制。
步骤M4:采用CIOU作为回归损失函数,且根据先验框调整后得到的预测框与真实框的距离、尺度确定所述回归损失函数。
优选地,在步骤M4中:
其中,S
ρ
公式中v的表达式如下:
通过1-CIOU就可以得到的归损失函数:
优选地,所述随机预处理包括调整大小、图像分割、放置图片、翻转图片、色域变换以及调整坐标。
优选地,在步骤M1之后,还包括学习率余弦退火衰减的步骤。
优选地,在所述目标检测模型训练的时候,冻结网络训练250个迭代,之后全解冻训练150个迭代,并保存每一次迭代后模型的权值文件。
优选地,在步骤M1中,预训练时,采取冻结一半训练和全解冻一半的训练方式。
根据本发明提供的多尺度火灾目标识别系统,包括如下模块:
图像获取模块,用于获取训练集,所述训练集通过对火灾图像进行标注生成;
先验框生成模块,用于根据所述训练集进行聚类,生成多个先验框;
模型构建模块,用于构建目标检测模型,并至少根据所述先验框对所述目标检测模型的参数进行设置,所述目标检测模型通过对YOLOv4算法中的CSPDarknet53主干特征提取网络用MobileNet网络进行替换生成;
模型训练模块,用于通过所述训练集对目标检测模型进行训练生成火灾检测模型;
火灾检测模块,用于通过火灾检测模型对输入的视频或图像进行火灾检测,判断是否发送火灾。
与现有技术相比,本发明具有如下的有益效果:
1、本发明中目标检测模型采用改进的YOLOv4目标检测算法构建,延用了原有YOLOv4算法的Mosaic数据增强、PANet(Path Aggregation Network)结构等方式来增强数据和特征提取过程,使其在火灾的识别精确性上能基本达到原有YOLOv4算法的效果,在原有YOLOv4目标检测算法中,火焰图像的AP(Average Precision)值为84.61%,烟雾图像的AP值为75.97%。在改进后的算法中,火焰图像的AP值为83.91%,烟雾图像因其本身特征的因素,AP值稍低,但也达到了74.64%;
2、本发明中火灾检测模型的参数量大大得到简化,训练后的模型由原来的244MB缩小为51MB,能够满足嵌入式设备和实时性的要求,对于视频火灾目标的检测,拥有更快的识别速度,更高的检测帧率;
3、本发明延用了原有YOLOv4(You Look Only Once Version 4)算法多尺度检测的优点,Yolo Head模块将提取到的不同大小特征层的火焰和烟雾特征进行预测,实现了火灾的多尺度检测,并对小目标也有较好的识别率。
附图说明
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
图1为本发明实施例中多尺度火灾目标识别方法的步骤流程图;
图2为本发明实施例中多尺度火灾目标识别方法的使用步骤流程图;
图3为本发明实施例中改进后的YOLOv4的特征结构图;
图4a为现有技术中YOLOv4算法中火焰图像的PR曲线图;
图4b为现有技术中YOLOv4算法中烟雾图像的PR曲线图;
图4c本发明实施例中火灾检测模型中火焰图像的PR曲线图;
图4d为本发明实施例火灾检测模型中烟雾图像的PR曲线图;
图5a为现有技术中YOLOv4算法对一般火焰、烟雾目标的识别效果图;
图5b为现有技术中YOLOv4算法对火焰小目标的识别效果图;
图5c为本发明实施例中火灾检测模型对一般火焰、烟雾目标的识别效果图;
图5d为本发明实施例中火灾检测模型对火焰小目标的识别效果图;
图6a为现有技术中YOLOv4算法视频检测示意图;
图6b为本发明实施例中火灾检测模型的视频检测示意图;
图7为本发明实施例中多尺度火灾目标识别系统的模块示意图。
具体实施方式
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进。这些都属于本发明的保护范围。
图1为本发明实施例中多尺度火灾目标识别方法的步骤流程图,如图1所示,本发明提供的多尺度火灾目标识别方法,包括如下步骤:
步骤S1:获取训练集,所述训练集通过对火灾图像进行标注生成;
在本发明实施例中,所述步骤S1包括如步骤:
步骤S101:搜集、拍摄和整理火灾和烟雾图像,形成一个多场景、多尺度、多角度的火灾图像数据集;
步骤S102:利用VOC2007数据集格式,建立文件夹来存放标注后的火灾图像数据;
步骤S103:通过标注工具对所述火灾图像数据集中的火焰和烟雾进行数据标注生成所述训练集。
在本发明实施例中,使用目标检测常用的标注工具Labelimg对上述火灾图片中的火焰和烟雾进行数据标注,用矩形框出它们的位置并注明种类名称。在标注的时候要能用大框标注的尽量用大框标注,且尽可能地减少框内的环境噪声。Annotations文件中存放的标签文件是XML格式,在object下可以看到物体的种类和位置。利用代码将VOC格式的数据集转换成YOLO格式,生成对应的txt名称文件,之后再用代码将其生成对应的2007_train.txt,2007_test.txt文件,前四位数字是物体的位置信息,第五位数字是物体的种类信息。
步骤S2:根据所述训练集进行聚类,生成多个先验框;
在本发明实施例中,所述步骤S2包括如下步骤:
步骤S201:随机选取了9个框作为聚类中心,然后计算其他所有的框和这9个框的距离;
步骤S202:根据距离将所有的框划分成9个区域,然后对这9个区域的所有的框取平均,重新作为聚类中心;
步骤S203:重复执行步骤S201至步骤S202,直到所述聚类中心不再改变为止。
在本发明实施例中,聚类时采用K-means聚类算法,根据已标注的4523张火灾图像,生成9个不同大小的先验框,对应3个不同大小的特征层,每个特征层有3个先验框。
本发明实施例中,先验框的聚类是以416×416像素的图片尺寸来说明的。在最终得到9个先验框的尺寸后,按要求复制到YOLO预先设定的先验框中。
步骤S3:构建目标检测模型,并至少根据所述先验框对所述目标检测模型的参数进行设置,所述目标检测模型通过对YOLOv4算法中的CSPDarknet53主干特征提取网络用MobileNet网络进行替换生成;
如图3所示,本发明将原有YOLOv4算法的主干特征提取网络CSPDarknet53用MobileNet进行替换。原有算法的CSPDarknet53(Cross Stage Partial NetworksDarknet53)是将CSPNet(Cross Stage Partial Networks)运用到了Darknet53模块上,53代表一共是53个卷积层,而且在原本的残差块上又引入了大残差边,虽然提升了网络的学习能力,但是参数量会大大增加。因此本发明利用轻量级深层神经网络MobileNet对CSPDarknet53进行替换,主要的思想还是获得YOLOv4原有的有效特征层,这样就无需更改后续的网络算法,可以实现多尺度检测。在MobileNet网络中,依然输入416*416*3这样的图片,进过标准化卷积,深度可分离卷积等,获得52*52*256,26*26*512和13*13*1024三个不同形状大小的特征层。这些得到的特征层就是输入进来的图片特征的集合,其间不断进行下采样是为了获得更高的语义信息,因此只使用了最后三个shape的特征层进行下一步的操作。在获得最后的特征层之后,对13*13*1024的特征层进行三次有效卷积。
进行SPP(Spatial Pyramid Pooling)部分,这部分有四个分支,本质就是利用不同大小的最大池化盒对输入进来的特征进行最大池化,池化后的结果进行堆叠之后再次进行三次卷积。
PANet模块中,对之前获得的三次卷积后的特征层进行上采样(2倍上采样),经过上采样特征层变成26*26的大小,这时把上采样的特征层与主干特征提取网络MobileNet的特征层进行堆叠,这时候就实现了特征的融合,就是特征金字塔的结构。然后在5次卷积之后可以继续上采样,与52*52的特征层融合。之后利用PANet进一步加深特征的提取,再一次往下进行下采样,再一次实现特征层的堆叠。最后再次进行下采样,然后与之前一开始的输入进来的13*13的特征层实现堆叠,整个PANet大概完成了4-5次的特征融合,经过这样特征金字塔的结构就能提取到很有效的特征。
利用Yolo Head模块把提取到的特征进行结果的预测,主要就是一个3*3的卷积,一个1*1的卷积的组合。对于特征层大小为13*13*1024的特征层来讲,最后输出的YoloHead的结果是13*13*21(13*13*3*7(7可拆分成2+1+4)),Yolo Head模块将输入进来的图片划分成13*13的网格,每一个网格存在三个先验框(3表示的含义),判断先验框是否包含物体(或者理解为置信度,1表示的含义),如果真实包含物体的话,会进一步判断物体的种类(2表示的含义,本发明只有2个分类,火焰图像和烟雾图像),对先验框的中心和宽高进行调整,直至调整到正确的位置上。4表示的是用来调整先验框的参数(计算机确定图像的位置需要四个参数(中心点X轴坐标,中心点Y轴坐标,目标框的宽和目标框的高))。
所述目标检测模型的参数进行设置时包括如下步骤:
步骤M1:将公开的VOC2007数据集的训练好的权重作为所述目标检测模型的预训练权重,预训练时,采取冻结一半训练和全解冻一半的训练方式;
步骤M2:采用Mosaic数据增强模块定义实时对火灾图像数据增强的随机预处理,所述随机预处理包括调整大小、图像分割、放置图片、翻转图片、色域变换以及调整坐标,能够丰富检测物体的背景。
步骤M3:通过标签平滑模块对所述目标检测模型的过拟合进行控制。
步骤M4:采用CIOU作为回归损失函数,且根据先验框调整后得到的预测框与真实框的距离、尺度确定所述回归损失函数。
在本发明实施例中,在步骤M1之后,还可以增加判断是否使用学习率余弦退火衰减的步骤。余弦函数随着自变量的增加,余弦值首先缓慢下降,然后加速下降,又再次缓慢下降,是一种十分有效的学习方式。其原理如下所示:
其中i表示第几次运行,
本发明中标签平滑模块的参数设置为0.05。所述随机预处理能够丰富检测物体的背景。
采取冻结一半训练和全解冻一半的训练方式,可以让训练的LOSS快速下降,使得模型快速收敛,提升了算法的效率。
在步骤M4中:
其中,S
ρ
公式中α的表达式如下:
公式中v的表达式如下:
其中w
通过1-CIOU就可以得到的归损失函数:
步骤S4:通过所述训练集对目标检测模型进行训练生成火灾检测模型;
步骤S5:通过火灾检测模型对输入的视频或图像进行火灾检测,判断是否发送火灾。
在本发明实施例中,将模型参数设置好就,开始训练。训练的过程是LOSS下降的过程,同时保存每一次迭代后的模型和权值文件。读取保存好的模型权重文件,输入待检测视频和图像或者直接调用摄像头进行检测。在图像中或者视频中标记出预测框,判断火灾的发生与否。通过图像文件,将预测框与实际框进行对比,根据设定的阈值,测试模型的准确率。
在训练的时候,冻结网络训练250个迭代,之后全解冻训练150个迭代,并保存每一次迭代后模型的权值文件,得到的模型的参数量只有原始YOLOv4算法的
图2为本发明实施例中多尺度火灾目标识别方法的使用步骤流程图,如图2所示,首先计算输入进来的图片的宽高,然后对图片进行大小的调整,通过添加灰度条的方式使得主体不发生失真现象。随后把图片传入本发明的火灾目标检测模型当中,得到预测结果,在获得结果之后,利用这个预测结果对先验框进行解码,以此获得最后的预测框,并对这些先验框内部是否包含物体、物体的种类做出判断。
获得预测框之后进行非极大抑制的操作(筛选出一定区域内得分最大的框),把这个框作为最终的预测结果。通过设置的置信度,判断火灾的识别是否准确。根据分类结果,将真实框标记为蓝色,预测框标记为绿色(正样本)和红色(负样本)。得到最终基于改进YOLOv4的多尺度火灾目标识别方法的PR(Precision-Recall)曲线和实时监测的结果,如图4、图5和图6所示。
图7为本发明实施例中多尺度火灾目标识别系统的模块示意图,如图7所示,本发明提供的多尺度火灾目标识别系统,包括如下模块:
图像获取模块,用于获取训练集,所述训练集通过对火灾图像进行标注生成;
先验框生成模块,用于根据所述训练集进行聚类,生成多个先验框;
模型构建模块,用于构建目标检测模型,并至少根据所述先验框对所述目标检测模型的参数进行设置,所述目标检测模型通过对YOLOv4算法中的CSPDarknet53主干特征提取网络用MobileNet网络进行替换生成;
模型训练模块,用于通过所述训练集对目标检测模型进行训练生成火灾检测模型;
火灾检测模块,用于通过火灾检测模型对输入的视频或图像进行火灾检测,判断是否发送火灾。
本发明实施例中,本发明运用了一种改进的YOLOv4算法,将提取到的不同大小特征层的火焰和烟雾特征进行预测,实现了火灾目标的多尺度识别。同时本发明的火灾检测算法模型大小为51MB,约为原有算法模型的
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变形或修改,这并不影响本发明的实质内容。
- 多尺度火灾目标识别方法及系统
- 基于改进的多尺度深度模型的目标识别方法及装置