具有种子/加入机制的视听协作系统和方法
文献发布时间:2023-06-19 11:35:49
技术领域
本发明总地涉及对视听表演的捕获和/或处理,尤其涉及适合于利用非线性捕获、重新捕获、加录或口形同步的选项来捕获和操纵对音频和/或视觉表演进行编码的媒体片段以供在种子和加入协作机制中使用的用户界面技术。
背景技术
移动电话、个人媒体播放器和便携式计算设备以及媒体串流器和电视机顶盒的安装基数每天在绝对数量和计算能力上都在增长。在世界各地的人们的生活方式中无处不在且根深蒂固,这些设备中的许多设备超越了文化和经济障碍。在计算上,这些计算设备提供了可与不到十年前的工程工作站或工作组计算机相当的速度和存储能力,并且通常包括强大的媒体处理器,从而使其适合于实时声音合成和其他音乐应用。确实,某些现代设备(诸如
诸如可从Smule公司获得的Smule Ocarina
发明内容
已经发现,尽管移动设备平台和媒体应用执行环境强加了实际限制,但是包括声乐在内的视听表演可以被捕获并且以创造引人注目的用户体验的方式与包括其他用户的表演在内的视听内容进行协调。在一些情况下,在与伴奏曲的可听呈现相对应的对歌词的卡拉OK风格呈现的背景下,在移动设备上(与表演同步的视频一起)捕获单独用户的人声表演。例如,可以使用用户界面设计来促进表演捕获,由此在视觉上为用户歌手呈现歌词和音高提示,并由此提供音频伴奏曲的时间同步可听呈现。
在这些和相关技术的基础上,构想出用户界面改进,以便为用户歌手提供用于播种(seeding)其他用户(例如,加入者)的随后表演的机制。在一些情况下,种子可以是全长种子,全长种子跨越大部分或全部预先存在的音频(或视听)作品,并且为了进一步播种一个或多个加入者的贡献而针对音频(或视听)作品的至少一些部分混合用户的捕获媒体内容。在一些情况下,可以采用短种子,短种子跨越少于全部(并且在一些情况下,远少于全部)的音频(或视听)作品。例如,在一些情况或实施例中,音频(或视听)作品的主歌、副歌、反复(refrain)、叠句或其他有限的“块”可以构成种子。无论种子的程度或范围如何,播种用户都可以要求(或召唤)其他人加入。通常,召唤邀请其他用户通过跟唱、唱特定的人声部分或音乐部分、唱和声或其他二重唱部分、说唱、说话、鼓掌、录制视频、添加来自相机胶卷的视频片段等来加入全长种子或短篇种子。可以在社交网络中张贴、直播或以其他方式散布由此产生的团体表演,无论是全长的还是仅一块。
播种用户可以使用拖动(scrubbing)技术来选择种子或种子部分,这些拖动技术允许在录制时、在编辑期间和/或在回放中向前和向后遍历视听内容,该视听内容可选地包括音高提示、波形型或包络型表演时间线、歌词、视频和/或其他时间上同步的内容。以这种方式,所选择的表演部分的重新捕获、团体部分的协调以及加录都可被促进。直接滚动到表演时间线、歌词、音高提示和其他时间上同步的内容中的任意点允许用户方便地在捕获或视听编辑会话中移动。对于涉及短种子的选择或实施例,可以采用拖动技术来定义起点和终点,这些起点和终点界定了特定的种子部分或块。同样,在全长种子的情况下,可以采用拖动技术来定义起点和终点,这些起点和终点界定了邀请加入者向其做出贡献的表演时间线的各部分。在一些情况下,诸如在针对二重唱引导的短篇捕获中,可以与团体部分信息相对应地在表演时间线、歌词、音高提示和其他在时间上同步的内容中引导用户歌手。在一些或所有情况下,拖动器允许用户歌手方便地在时间上同步的内容中向前和向后移动。在一些情况下,还结合拖动器来支持时间上同步的视频捕获和/或回放。注意,虽然可以为多个媒体线(例如,伴奏音频、人声、歌词、音高提示和/或团体部分信息)的同步遍历提供拖动,但是也设想到单媒体拖动。
不需要在所有情况或实施例中都采用拖动技术。在一些情况或实施例中,表演时间线的各部分(常常是对应于音乐部分的部分)可以被标明和标记以供用户选择。标明/标记可以基于人力或自动来源。例如,特定部分可以由最初上传曲目或对应歌词的用户来标明或标记,或者由媒体内容管理者来标明或标记。以补充方式或可替代地,特定部分可以由被训练为识别部分和边界(例如,根据音频伴奏或人声轨道、歌词,或者基于源自大众的数据,诸如用户倾向于在哪里唱得最多或最大声)的机器学习机器人来标明或标记。
除了被设计为促进非线性媒体片段捕获和编辑的用户界面和平台特征之外,还设想到可以提供协作特征,以允许用户向演进的表演时间线贡献媒体内容和/或其他时间同步的信息。为了促进内容的协作和/或添加,共享的服务平台可以将媒体内容和表演时间线数据公开为多用户并发访问数据库。可替代地或附加地,特别是一旦已经用种子音频或视频至少部分地定义了表演时间线,就可以通过(例如,经由共享的服务平台或否则以对等方式)张贴表演时间线以供其他用户加入来促进协作,这些用户可以继而捕获、编辑以及向表演时间线添加其他媒体片段、歌词信息、音高轨道、人声部分指定和/或基于媒体片段或表演/风格/流派映射的音频或视频效果/过滤器。在一些情况下,使用本文描述的用户界面和平台特征来完成对表演时间线的附加捕获、编辑和添加,以促进对卡拉OK风格表演的视听内容和数据的非线性媒体片段捕获和编辑。
结合视听表演捕获系统的其他方面,受益于本公开的本领域技术人员将理解这些以及其他用户界面改进。可选地,在一些情况或实施例中,可以在移动设备处(或者更一般地,在诸如移动电话、个人数字助理、膝上型计算机、笔记本计算机、平板型计算机或上网本之类的便携式计算设备处)或者在内容或媒体应用服务器上根据音高校正设置实时地对人声音频进行音高校正。在一些情况下,音高校正设置针对人声表演或针对其各部分编码特定的调或音阶。在一些情况下,音高校正设置包括与歌词和伴奏曲一起提供或供与歌词和伴奏曲相关联的乐谱编码的旋律和/或和声序列。如果需要,可以将和声音符或和弦编码为明确的目标,或者相对于乐谱编码的旋律乃至由歌手发出的实际音高来编码和声音符或和弦。
基于音高校正后的人声、表演同步的视频和乐谱编码的和声混合的引人注目性和变革性,用户/歌手可以克服与共享其人声表演相关联的原本自然的害羞或焦虑。相反,甚至在地理上分散的歌手也被鼓励与朋友和家人进行共享,或者作为社交音乐网络的一部分进行合作并贡献人声表演。在一些实施方式中,通过社交网络和/或电子邮件介导(mediate)的表演共享以及对参加团体表演的邀请来促进这些交互。在一些实施方式中,可以支持直播。客厅风格的大屏幕用户界面可以促进这些交互。使用所上传的在诸如前述便携式计算设备之类的客户端处捕获的人声,内容服务器(或服务)可以通过操纵和混合多个贡献歌手的上传视听内容来介导这样协调的表演。取决于特定系统的目标和实施方式,除了视频内容之外,上传还可包括音高校正后的人声表演(有和声或没有和声)、干(即未经校正的)人声和/或用户调和/或控制轨道和/或音高校正选择等。
社交音乐可以多种方式中的任一种进行介导。例如,在一些实施方式中,在便携式计算设备处相对于伴奏曲而捕获的并且通常根据乐谱编码的旋律和/或和声提示而进行音高校正的第一用户的人声表演作为种子被提供给其他潜在的人声表演者。表演同步的视频也被捕获,并且可被与音高校正后的捕获人声一起提供。所提供的人声被与伴奏乐器/人声混合,并形成用于捕获第二用户的人声的伴奏曲。经常,连续的人声贡献者在地理上是分离的,并且对于彼此可能是未知的(至少是先验的),但是人声的亲密感以及协作体验本身往往使这种分离最小化。随着连续的人声表演和视频被捕获(例如,在相应的便携式计算设备处)并且被共生作为社交音乐体验的一部分,相对于其捕获各个人声的伴奏曲可以演变为包括其他贡献者的先前捕获的人声。
在一些情况下,完整表演或特定人声部分(例如,二重唱中的A部分或B部分)的完整表演可以构成社交音乐协作的种子。然而,使用本文描述的技术,即使是对整体表演的甚至小的或孤立的部分(例如,反复、叠句、序曲、终曲、二重唱或团体部分、主歌或其他有限部分、更大表演的部分或选中片段)的捕获也可以被方便地捕获、重新捕获或编辑,以用作协作种子,无论它是否构成完整的表演时间线。在一些情况下,选择的部分、位置或预先标明/标记的片段边界可以对应于音乐结构的元素。结果,根据一个或多个本发明的实施例可以促进在地理上分散的表演者在社交音乐网络中的“小种子”协作机制。
在一些情况下,和与伴奏乐器和/或人声混合的人声表演(例如,在另一类似配置的移动设备处捕获并进行音高校正)的可听呈现相关联地提供迷人的视觉动画和/或用于听众评论和排名功能的设施以及二重唱、合唱团或合唱组的形成或添加逻辑。合成的和声和/或其他人声(例如,从其他位置处的另一歌手捕获的并被可选地进行音高移位以与其他人声进行和声的人声)也可以被包括在混合中。在捕获后可以应用或重新应用音频或视觉过滤器或效果,以散布或张贴内容。在一些情况下,散布或张贴的内容可以采取对其他歌手的协作请求或公开召唤的形式。对捕获的人声表演(或对组合表演的个人贡献)和/或听众反馈的地理编码可以通过如下方式来促进动画或显示伪像:该方式暗示出自用户可操纵的地球仪上的特定地理位置的表演或认可。以这些方式,所描述的功能的实现可以将原本平凡的移动设备和客厅或娱乐系统转变为培养全球连接、协作和社区的独特感觉的社交工具。
在根据本发明的一些实施例中,一种系统包括第一和第二媒体捕获设备,第一和第二媒体捕获设备经由相应的网络通信接口通信地耦合以相对于音频作品的基线媒体编码进行多表演者协作。第一媒体捕获设备向其第一用户提供用于选择音频作品的种子部分的用户界面,并且被配置为至少捕获人声音频,该人声音频是针对第一用户对着该音频作品的至少一部分在第一媒体捕获设备上的可听呈现而表演的。第二媒体捕获设备被配置为:(i)经由其网络通信接口接收对第一用户在第一媒体捕获设备处选择的种子部分的指示,以及(ii)捕获第二用户的媒体内容,该媒体内容是针对与所捕获的第一用户的人声音频混合在一起的种子部分在第二媒体捕获设备上的可听呈现而表演的。
在一些情况或实施例中,第一媒体捕获设备的用户界面还允许第一用户指定要从第二用户的表演中捕获的媒体内容一个或多个类型,第二用户的表演针对与所捕获的第一用户的人声音频混合在一起的种子部分在第二媒体捕获设备上的可听呈现。在一些情况或实施例中,所指定的要捕获的媒体内容的一个或多个类型是从包括以下各项的集合中选择的:人声音频、人声和声、或人声二重唱部分;说唱、说话、鼓掌、或打击乐;以及视频。在一些情况或实施例中,第一媒体捕获设备的用户界面还允许第一用户将种子部分作为协作请求而张贴到包括第二用户在内的其他在地理上分散的用户和媒体捕获设备,用于捕获和添加其他人声音频、视频或表演同步的视听内容。
在一些实施例中,该系统还包括服务平台,该服务平台通信地耦合到第一和第二媒体捕获设备,该服务平台被配置为:提供对至少第一用户和第二用户的多表演者协作的媒体编码用于至少在通信地耦合的第三设备上的可听呈现或视听呈现,该媒体编码基于音频作品但在时间上限于其由第一用户选择的所述种子部分。
在一些实施例中,该系统还包括在第一媒体捕获设备上的媒体内容拖动器,第一用户通过该媒体内容拖动器在表演时间线中注明起点和终点,以界定并从而选择种子部分。在一些情况或实施例中,媒体内容拖动器向第一用户呈现以下各项中的两项或更多项的时间上同步的表示:伴奏音频和/或人声的音频包络;歌词;一个或多个音高轨道;以及二重唱或其他团体部分符号。
在一些实施例中,系统还包括在第一媒体捕获设备上的用户界面,第一用户通过该用户界面从音频作品的预先标明或标记的部分中选择种子部分。在一些情况或实施例中,音频作品的预先标明或标记的部分是由与第一和第二媒体捕获设备通信地耦合的服务平台提供的,预先标明或标记的部分已经基于以下各项中的一项或多项而被标明或标记:为音频作品编码的音乐结构;机器学习算法,该机器学习算法应用于音频作品的伴奏音频、人声音频或歌词或者与音频作品相对应的伴奏音频、人声音频或歌词;源自大众的数据;以及由音频作品的用户上传者或由其第三方管理者提供的数据。
在一些情况或实施例中,音频作品的基线媒体编码还对同步的视频内容进行编码。在一些情况或实施例中,第一媒体捕获设备还被配置为捕获表演同步的视频内容。在一些情况或实施例中,第一和第二媒体捕获设备是执行应用软件的移动电话型便携式计算设备,该移动电话型便携式计算设备在其至少一个操作模式下在其多点触摸敏感显示器上与音频作品的可听呈现在时间上对应的方式提供包括歌词在内的表演时间线的卡拉OK风格的呈现,并且该移动电话型便携式计算设备经由相应移动电话型便携式计算设备的机载音频和视频接口来捕获相应的第一或第二用户的人声和/或表演同步的视频。
在根据本发明的一些实施例中,一种方法包括使用便携式计算设备,结合在其多点触摸敏感显示器上的表演时间线的卡拉OK风格的呈现,来进行媒体片段捕获,该表演时间线包括与音轨同步的歌词和音高轨道。该方法还包括:响应于多点触摸敏感显示器上的手势控制,将歌词的子集指定给加入者;以及将表演时间线与歌词子集指定一起张贴为协作请求,以便加入的远程用户在第二远程便携式计算设备上捕获和添加进一步的人声音频内容,第二远程便携式计算设备被配置为结合表演时间线进行进一步的媒体片段捕获。在一些情况或实施例中,便携式计算设备配置有用户界面组件,这些用户界面组件可执行来提供:(i)媒体片段捕获的开始/停止控制和(ii)针对表演时间线内的时间位置控制的拖动交互。
在一些实施例中,该方法还包括:从表演时间线中的拖动到的第一位置开始,将至少一个媒体片段添加到表演时间线,第一位置既不是表演时间线的开始,也不是表演时间线内的最近的停止或暂停位置。在一些实施例中,该方法还包括:从表演时间线中的拖动到的第一位置开始,并且与至少同步歌词和音高轨道在多点触摸敏感显示器上的卡拉OK风格的呈现相对应地,在便携式计算设备处捕获人声音频,其中,所添加的至少一个媒体片段包括所捕获的人声音频。
在一些情况或实施例中,所添加的至少一个媒体片段包括以下各项中的一项或多项:视频或静止图像;从表演时间线中的拖动到的第一位置开始,并且与歌词和音高轨道在多点触摸敏感显示器上的卡拉OK风格呈现以及音轨的同步可听呈现相对应地,在便携式计算设备处捕获的视频;以及在便携式计算设备处捕获的表演同步的音频和视觉媒体内容。
在一些实施例中,该方法还包括将包括所添加的至少一个媒体片段在内的表演时间线保存到与网络耦合的服务平台。在一些实施例中,该方法还包括从与网络耦合的服务平台中检索先前保存的版本的表演时间线。
在一些情况或实施例中,经由与网络耦合的服务平台为加入的远程用户张贴表演时间线。在一些情况或实施例中,对歌词子集的指定响应于多点触摸敏感显示器上的第一用户手势控制,第一用户手势控制为加入者选择特定的人声部分。在一些情况或实施例中,对歌词子集的指定响应于多点触摸敏感显示器上的第二用户手势控制,第二用户手势控制界定了所述歌词中与加入者的进一步媒体片段相对应的歌词子集。
在根据本发明的一些实施例中,一种方法包括使用第一便携式计算设备结合在其多点触摸敏感显示器上的表演时间线的卡拉OK风格的呈现来进行媒体片段捕获,该表演时间线包括与音轨同步的歌词和音高轨道,其中,该表演时间线包括由先前用户在第二远程计算设备上指定的歌词的子集,对歌词子集的指定至少部分地参数化协作请求,该协作请求用于捕获和添加由加入表演时间线的用户在第一便携式计算设备上进行的其他人声音频内容。在一些情况或实施例中,第一便携式计算设备配置有用户界面组件,这些用户界面组件可执行来提供:(i)媒体片段捕获的开始/停止控制和(ii)针对表演时间线内的时间位置控制的拖动交互。
在一些实施例中,该方法还包括:从表演时间线中的拖动到的第一位置开始,捕获至少一个人声音频媒体片段,第一位置既不是表演时间线的开始,也不是表演时间线内的最近的停止或暂停位置。在一些实施例中,该方法还包括:更新表演时间线以包括所捕获的至少一个人声音频媒体片段;以及经由与网络耦合的服务平台为加入的远程用户张贴更新后的表演时间线。
在一些情况或实施例中,对歌词子集的指定对于特定的人声部分是选择性的。在一些情况或实施例中,对歌词子集的指定为加入表演时间线的用户的进一步人声音频内容界定了歌词的子集。
在根据本发明的一些实施例中,一种方法包括:使用便携式计算设备以捕获媒体内容,用于同步的歌词、音高和音轨的卡拉OK风格呈现;使用便携式计算设备在其多点触摸敏感显示器上捕获至少一个音频片段,便携式计算设备配置有用户界面组件,这些用户界面组件可执行来提供:(i)媒体片段捕获的开始/停止控制和(ii)针对表演时间线内的时间位置控制的拖动交互;输入歌词的一个或多个片段,并且响应于多点触摸敏感显示器上的第一用户手势控制而将输入的歌词片段与表演时间线对齐;响应于多点触摸敏感显示器上的第二用户手势控制,在表演时间线在多点触摸敏感显示器上的视觉上同步的呈现中向前或向后移动;以及在移动之后,捕获至少一个音频片段,并对所捕获的音频片段进行音高检测以产生音高轨道的至少一部分。
在一些情况或实施例中,至少一个音频片段的捕获是自由式的,没有歌词或音高轨道的滚动。在一些情况或实施例中,所捕获的自由式音频片段包括表演同步的视频。在一些情况或实施例中,所捕获的自由式音频片段包括以下两者中的任一者或两者:器乐伴奏音频;以及人声音频。
在一些实施例中,该方法还包括:响应于多点触摸敏感显示器上的第三用户手势控制,在表演时间线在多点触摸敏感显示器上的视觉上同步的呈现中向前或向后移动;以及在移动之后,将歌词的子集指定给第一人声部分。在一些实施例中,该方法还包括:将表演时间线张贴为协作请求,该协作请求捕捉和添加一个或多个歌手在远程便携式计算设备上的人声音频内容。
附图说明
参考附图,通过示例而非限制的方式示出了本发明,在附图中,相似的附图标记通常指示类似的元件或特征。
图1描绘了根据本发明的一些实施例的在团体视听表演的准备中用于非线性视听捕获和/或编辑的说明性移动电话型便携式计算设备之间的信息流。
图2更详细地描绘了与便携式计算设备上的人声捕获会话有关的示例性用户界面,该示例性用户界面具有歌词、音高提示和拖动器的视觉同步呈现。
图3示出了与人声捕获滚动行为有关的示例性用户界面,其中表演时间线和歌词的呈现中的当前点与用户在便携式计算设备的触摸屏上的手势相对应地向前或向后移动。
图4示出了与人声捕获中的暂停有关的示例性用户界面。
图5示出了具有拖动器的另一示例性用户界面,该拖动器用于与用户在便携式计算设备的触摸屏上的手势相对应地向前或向后移动。
图6示出了根据本发明的一些实施例的时间索引遍历机制。
图7示出了参考一些前述附图介绍的(一个或多个)拖动机制上的一些说明性变化。
图8示出了使用所捕获的人声表演作为音频种子,用户向该音频种子添加视频,并最终更新表演时间线以添加或改变流或人声部分选择。
图9描绘了包括附加的多用户协作方面的说明性序列。
图10描绘了具有多用户协作的说明性序列,涉及由用户创建或捕获的视频作为初始种子表演。
图11描绘了示例性的特殊邀请选项,其包括用户对特定人声部分的指定,加入者被引导为针对该特定人声部分歌唱或提供音频。
图12描绘了根据本发明的一些实施例的安排的自由式创建。
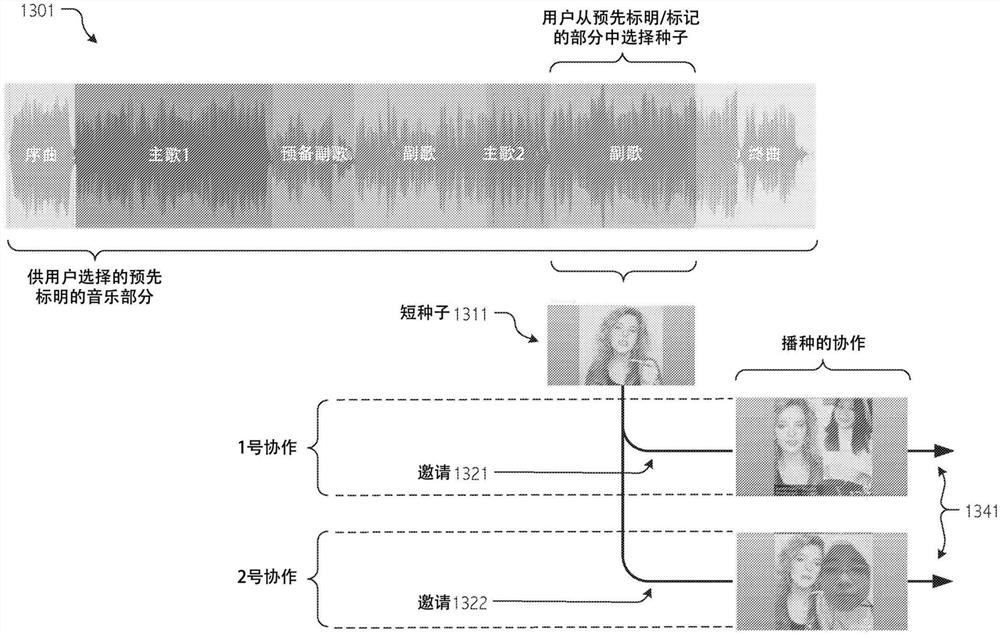
图13示出了根据本发明的一些实施例的短种子协作流程。
图14和图15示出了用于对视听内容进行捕获、协调和/或混合的示例性技术。
图16示出了移动电话型设备的特征,该移动电话型设备可以用作用于执行根据本发明的一些实施例的软件实现的平台。
图17示出了一种系统,其中设备和相关服务平台可以根据本发明的一些实施例进行操作。
技术人员将认识到,附图中的元件或特征是为了简单和清楚而示出的,并且不一定按比例绘制。例如,为了改善对本发明的实施例的理解,一些示出的元件或特征的尺寸或重要性可能相对于其他元件或特征而被夸大。
具体实施方式
已经开发出用于促进视听表演的捕获、音高校正、合成、编码和呈现的技术。人声音频连同表演同步的视频可被捕获并与其他用户的视听贡献进行协调,以形成多表演者、二重唱风格或合唱团风格的视听表演。对表演时间线的各个片段或部分的非线性捕获和/或编辑允许进行多个贡献者的自由形式协作,通常利用独立的和在地理上分散的音频和/或视频捕获。在一些情况下,音频和视频可被分别捕获并在捕获后相关联。在一些情况下,在与伴奏曲或人声表演的可听呈现相对应的歌词的卡拉OK风格呈现的背景下,在移动设备、电视型显示器和/或机顶盒设备上捕获单独用户的表演(音频、视频、或者在一些情况下是音频连同表演同步的视频)。所捕获的一个贡献者的音频、视频或视听内容可用作团体表演的种子。
图1描绘了根据本发明的一些实施例的说明性移动电话型便携式计算设备(101A、101B)和内容服务器110之间的信息流。在所示出的流程中,歌词102、音高提示105和伴奏曲107被提供给便携式计算设备(101A、101B)中的一个或多个以促进人声(并且在一些情况下是视听的)捕获。各个设备的用户界面提供了拖动器(103A、103B),给定的用户歌手由此能够使用触摸屏上的手势控制在时间同步的内容(例如,音频、歌词、音高提示等)中向前和向后移动。在一些情况下,拖动器控制还允许在表演同步的视频中向前和向后移动。
尽管本发明的实施例不限于此,但是使用移动电话类型的音高校正、卡拉OK风格的人声捕获提供了有用的描述性上下文。例如,在与图1所示的实施例一致的一些实施例中,可从苹果公司获得的iPhone
示出了对两部分表演的捕获(例如,作为二重唱,其中从单独歌手分别捕获视听内容106A和106B);然而,受益于本公开的本领域技术人员将认识到,也可以在独唱和在更大的多部分表演中采用本发明的技术。一般而言,响应于协作请求,视听内容可被张贴、流式传输,或者可以发起或被捕获。在所示出的实施例中,内容选择、团体表演和所捕获的视听表演的散布全部都经由内容服务器110进行协调。内容服务器110的内容选择和表演添加模块112在所示出的设计中执行音频混合和视频拼接,而视听呈现/流控制模块113将团体视听表演混合111提供给下游观众。在其他实施例中,对等通信可用于所示出的流程中的至少一些。
在一些情况下,无线局域网可以支持便携式计算设备101A实例、视听和/或机顶盒设备和广域网网关(未具体示出)之间的通信,广域网网关继而与远程设备101B和/或内容服务器110进行通信。尽管图1描绘了其中内容服务器110在便携式计算设备101A和101B之间扮演中间角色的配置,但是受益于本公开的本领域技术人员将认识到便携式计算设备101A和101B之间的对等通信或主机对访客通信也可以被支持或者替代地被支持。本领域技术人员将认识到,包括802.11Wi-Fi、Bluetooth(蓝牙)
作为卡拉OK风格的应用程序(诸如可从Smule公司获得的Smule应用程序)的典型特征,乐器和/或人声的伴奏曲可以被可听地呈现,以供用户/歌手对着唱。在这种情况下,可以与本地可听呈现相对应地显示歌词(102A、102B),以促进给定用户的卡拉OK风格的人声表演。注意,一般而言,单独用户可以在团体表演中表演相同或不同的部分,并且音频或视听捕获不需要是且通常不是同时的。在一些实施例中,表演者贡献的音频或视听捕获可以是独立且异步的,常常跨越时区和大洲。然而,在一些实施例中,可以采用直播技术。在图1的图示配置中,歌词、定时信息、音高和和声提示、伴奏曲(例如,乐器/人声)、表演协调视频等都可以源自与网络连接的内容服务器110。在一些情况或状况下,可以从诸如音乐库之类的媒体存储装置中呈现伴奏音频和/或视频,该媒体存储装置驻留在手持设备、机顶盒、内容服务器等中或者可以从手持设备、机顶盒、内容服务器等访问。
用户人声或视听内容106A、106B在相应的设备101A、101B处被捕获,可选地连续且实时地进行音高校正(在手持设备处或使用未具体示出的视听显示器和/或机顶盒设备的计算设施)并被可听地呈现,以向用户提供他/她自己的人声表演的改进音质的演绎。音高校正通常基于乐谱编码的音符集或提示(例如,音高和和声提示105),其为连续音高校正算法提供当前调或音阶中的目标音符的表演同步序列。除了表演同步的旋律目标之外,乐谱编码的和声音符序列(或集合)还为音高移位算法提供了音高移位到用户自己捕获的人声的和声版本的额外目标(通常被编码为相对于主旋律音符轨道的偏移,并且通常仅针对其选定部分进行配乐)。在一些实施例中,音符/音高目标和乐谱编码的定时信息可用于评估人声表演质量。
歌词102、旋律和和声轨道音符集105以及相关的定时和控制信息可被封装在适当的容器或对象中(例如,以乐器数字接口MIDI或Java脚本对象符号json类型格式),以便与伴奏曲107一起提供。使用这样的信息,便携式计算设备101A、101B可以与一个或多个伴奏曲的可听表演相对应地显示与目标音符、和声以及当前检测到的人声音高相关的歌词(102A、102B)乃至视觉提示(105A、105B),以促进用户的卡拉OK风格的人声表演。因此,如果有抱负的歌手选择Bruno Mars所推广的“When I Was Your Man”,则your_man.json和your_man.m4a可被从内容服务器下载(如果不是已经可用或基于先前的下载进行缓存的话),继而用于在用户歌唱的同时提供背景音乐、同步的歌词并且在一些情况或实施例中提供乐谱编码的音符轨道以进行连续且实时的音高校正。可选地,至少对于某些实施例或流派,和声音符轨道可被乐谱编码以便和声移位到所捕获的人声。
通常,所捕获的音高校正后(可能配和声)的人声表演与表演同步的视频一起作为一个或多个音频或视听文件而被本地存储在手持设备或机顶盒上,随后被压缩和编码以作为MPEG-4容器文件上传(106A、106B)到内容服务器110。尽管MPEG-4是因特网、移动网络和高级广播应用的数字多媒体内容的编码表示和传输的示例性标准,但是如果需要,则可以采用其他合适的编解码器、压缩技术、编码格式和/或容器。取决于实现方式,干人声和/或音高校正后的人声的编码可被上传(106A、106B)到内容服务器110。一般而言,这样的人声(例如以MPEG-4容器或其他方式编码的),不管是已经被音高校正还是在内容服务器110处进行音高校正,然后可以例如与伴奏音频和其他捕获的(以及可能音高移位的)人声表演混合,以产生根据特定目标或网络的能力或限制选择的质量或编码特性的文件或流。在一些实施例中,可以在诸如内容服务器110之类的服务器或服务平台处执行音频处理和混合和/或视频同步和拼接,以提供复合的、多表演者的视听作品。
图2更详细地描绘了结合便携式计算设备101A(回顾图1)上的人声捕获会话的歌词102A、音高提示105A和拖动器103A的示例性用户界面表示。在多个参考帧中(例如,在歌词102A中,在音高提示105A中以及在拖动器103A中的表演时间线的音频包络描绘中)注明(281A、281B、281C)当前的人声捕获点。可以采用多种标记技术或符号体系中的任何一种。一般而言,用户界面符号和符号体系的特定形式是设计选择的问题,但是可包括颜色提示(诸如对于歌词102A中的单词、行或音节位置281B)、垂直或水平的条形标记(参见图2的用户界面表示的音高提示105A和拖动器103A中的符号281A、281C)或其他方式。
如参考随后的附图和描述将会理解的,图2的示例性用户界面表示(及其变体)提供了一种机制,用户由此可以基于屏幕上的手势控制在表演时间线中向前或向后移动。通过在拖动器103A中向前或向后操纵当前位置281C,人声捕获点在表演时间线中相应地向前或向后移动。相应地,歌词102A和音高提示105A以视觉同步的方式前进或后退。同样,在伴奏曲和/或所捕获的音频、视频或视听内容中的位置前进或后退。以这种方式,便携式计算设备101A的用户的屏幕上的用户界面操纵向前或向后移动,并且促进表演时间线的非线性遍历。例如,用户可以在表演时间线中向前或向后移动到任意点,而不是在表演时间线的开始处开始人声、视频或视听捕获或者在最近的停止或暂停位置处重新开始。仅重新录制、加录和/或选择性地捕获表演的特定节或部分都是由所提供的非线性访问促进的。在一些实施例中,非线性访问允许音频和视频在单独的各遍中被捕获。
作为表演时间线的音频包络而被可视地呈现的拖动器103A中的当前位置281C可以用便携式计算设备101A的触摸屏显示器上的向左(时间上向后)和向右(时间上向前)滑动式手势进行横向操纵。用户界面手势约定是设计选择的问题,如果需要,则可以采用其他手势来达到类似或互补的效果。在一些实施例中,也可以(或者替代地)用显示器的音高轨道105A或歌词102A的窗格中的手势来操纵当前位置。在每种情况下,屏幕上的元素(例如,音高轨道105A、歌词102A和表演时间线的音频包络)的呈现在视觉上是同步的,以使得一者的向前或向后运动引起一个或多个它者的向前或向后运动。如果捕获被开始或重新开始,则屏幕上的元素(例如,音高轨道105A、歌词102A和表演时间线的音频包络)中的每一个从表演时间线内的一致且视觉上同步的起点以时间对应的方式向前滚动。在提供表演同步的视频的实施例或显示模式中,可以可选地在表演时间线内的视觉上同步的起点处发起视频滚动或捕获。
图3示出了与人声捕获滚动行为有关的另一示例性用户界面机制,其中歌词102A的呈现中的当前点(281B)及其在表演时间线中的对应点(281C)与用户在便携式计算设备101A(回顾图1)的触摸屏上的手势相对应地向前或向后移动。尽管在所示出的实施例中提供了歌词102A的扩展呈现并隐藏了音高提示,但是其他实施例可以以不同方式分配屏幕空间。使用便携式计算设备101A(回顾图1)的触摸屏上的向上或向下移动,用户歌手结合歌词的屏幕上呈现来表达用于在歌词中向前和向后滚动的用户界面手势。在一些情况或实施例中,利用其他显示特征(例如,拖动器103A的音频包络)的视觉上同步的遍历在歌词中进行细粒度(行级别、单词级别或音节级别)移动可以是用户歌手在捕获或重新捕获期间进行表演时间线遍历的优选机制。像以前一样,触摸屏手势提供了在歌词102A和表演时间线中的同步运动。在一些实施例中,可以采用附加或替代的手势表达。
虽然示例性用户界面特征强调歌词和音高提示,但是诸如片段、团体部分、二重唱中的A/B部分等的音乐结构的元素也可用于标明表演时间线中的点,当前位置可以前进或后退到这些点。在一些情况或实施例中,前进可以是自动化或脚本化的。在一些情况下,用户界面可以支持“寻找”具有音乐结构重要性的下一点或前一点,寻找所选择的片段或位置,或者寻找预先标明/标记的片段边界。
图4示出了与人声捕获中的暂停有关的类似用户界面特征,其中歌词102A的呈现中的当前点(281B)及其在表演时间线中的对应点(281C)与用户在便携式计算设备101A(回顾图1)的触摸屏上的手势相对应地向前或向后移动。暂停时,在拖动器103A中呈现表演时间线的扩展呈现。像以前一样,歌词102A和时间线拖动器103A的呈现中的当前点与用户的向上或向下触摸屏手势相对应地向前或向后移动。在屏幕上呈现的特征(例如,歌词102A和表演时间线)中的向前和向后移动是时间上同步的。可以采用用户对歌词的选择来为随后的加入指定人声部分,以及为协作请求播种媒体内容(例如,音频和/或视频)。
图5示出了使用时间线拖动器103A进行的拖动,其中当前点(281C)及其在歌词102A和音高提示105A的呈现中的对应点(281B、281A)与用户在便携式计算设备101A(回顾图1)的触摸屏上的手势相对应地向前或向后移动。触摸屏手势提供了在歌词102A、音高提示105A和表演时间线中的同步移动。在一些实施例中,可以采用附加或替代的手势表达。
图6示出了音高轨道605和歌词轨道602数据的计算机可读编码的时间索引遍历,该遍历与用户在根据伴奏曲和/或所捕获的人声计算出的说明性音频信号包络的触摸屏显示上表达的向前和向后用户界面手势有关。一般而言,MIDI、json或其他合适的存储器中数据表示格式可以用于音高、歌词、音乐结构以及与给定表演或音乐安排有关的其他信息。受益于本公开的本领域技术人员将认识到使用各种数据结构索引技术中的任何一种来例如使用显示的拖动器103A、歌词102A和音高提示105A部分促进表演时间线中的位置的视觉上同步的呈现。
图7示出了参考前述附图介绍的一个或多个拖动机制的一些说明性变体。具体而言,在一个示出的变体中,基于在触摸屏的音高提示呈现部分(105A)中的左右手势,替代地(或另外地)支持拖动。像以前一样,在歌词(102A)中的移动和表演时间线(103A)的音频信号包络表示的遍历在视觉上与基于音高提示的拖动同步。可以诸如通过其他屏幕上符号体系的替代颜色在表演时间线中注明单独用户歌手的人声部分(例如,歌词701.1、702.2)。可以在用户界面的音高提示105A部分和时间线拖动器103A部分中采用类似的符号体系来标识由单独歌手演唱或要由单独歌手演唱的二重唱(A部分、B部分)或团体部分。在一些情况或实施例中,可以提供用户界面设施,其沿着表演时间线前进/后退到或选择具有音乐结构重要性的点。示例包括音乐部分边界,二重唱中的下一个A部分(或B部分)部分的连续开始,已经作为协作请求的一部分而被指派给用户歌手的特定音乐部分,等等。在加载音乐安排时,根据本发明的一些实施例的用户界面和拖动机制允许用户前进/后退到该安排中的任意或区别(demarked)的点、部分或片段,乃至选择该安排中的任意或区别(demarked)的点、部分或片段,以使用视觉上同步的呈现的表演时间线、歌词或音高部分进行人声、视频和/或视听捕获、重新捕获或回放。
图8示出了使用所捕获的人声表演作为音频种子,用户向该音频种子添加视频,并且最终更新表演时间以添加或改变流程或人声部分选择。图9描绘了包括附加的多用户协作方面的说明性序列。例如,在第一用户(用户A)捕获人声表演作为音频种子之后,第二用户(用户B)加入用户A的表演并添加音频和/或视频媒体片段。在该说明性序列中,用户B还诸如通过将特定歌词注明为二重唱的B部分来添加人声部分指定。从那里,(例如,作为公开召唤的一部分)邀请多个潜在的加入者利用添加的音频、视频并根据用户B的人声部分指定向用户A的初始音频种子中添加附加的媒体内容。
图10描绘了具有多用户协作的类似序列,但是其中由第一用户(用户A)创建或捕获的视频被提供作为初始种子表演。第二用户(用户B)加入用户A的视频并添加音频片段,在这里是捕获的人声音频。用户A继而邀请用户(例如,用户B和其他用户)添加附加的音频,在这里是主音频(旋律)和两个附加的人声和声部分。结果是作为协作添加了多个音频层的视频。
图11描绘了某些示例性特殊邀请选项,其包括用户对用于后续加入的特定人声部分的指定以及用户对歌词的选择,以将用于后续加入的人声部分指定到种子媒体内容(例如,音频和/或视频)。在每种情况下,引导加入者歌唱所指定的人声部分,或更一般地为所指定的人声部分提供音频。
还设想到自由形式和协作安排的创建过程。例如,如图12的步骤1所示,用户(用户A)可以表演和捕获自由式模式的表演,例如,具有吉他表演的表演同步视频的声学音频。用户A的初始自由形式捕获为进一步的协作提供了初始种子。接下来(在一个说明性流程中),用户(例如,用户A或另一用户B)可以输入歌词(步骤2)以伴随视听表演。本文描述的时间线编辑和拖动设施在输入歌词、操纵歌词并将输入的歌词与表演时间线中的所需点对齐时可以特别有用。接下来(在所示出的流程中),用户(用户A、B或另一用户C)可以将特定歌词部分指派(步骤3)给演唱者(例如,二重唱中的A部分对B部分)。更一般而言,可以在团体安排中指派更大数量的人声部分。
对于至少一些实施例,在图12的步骤4中示出的自由形式和协作安排创建过程的高级特征是音高线捕获机制的提供,由此相对于演进的表演时间线的卡拉OK风格滚动来捕获音轨并使用该音轨来计算音高轨道。一般而言,可以应用各种音高检测技术中的任何一种,以根据捕获的音频来计算音高轨道。人声音频和(例如来自钢琴的)乐器音频都被设想到。在每种情况下,计算出的音高轨道都被添加到表演时间线。注意,用户生成的布置不必限于歌词和音高线。作为示例(参见步骤5+),媒体片段捕获和编辑平台可被扩展,以允许用户(用户A、B、C或另一用户D)指定像以下各项一样的事物:歌曲部分(“副歌”、“主歌”等),和声部分,基于片段的视频或音频效果/过滤器等。还注意到,尽管图12的有序流程是说明性的,但是其他实施例可以改变步骤的顺序,省略步骤,或者包括适合于特定自由形式协作和特定音频或视听作品的附加步骤。
尽管大部分前述描述在完整表演时间线的上下文中展示了非线性片段捕获和编辑技术的灵活性,但是受益于本公开的本领域技术人员将认识到,协作种子可以但不需要跨越完整的音频(或视听作品)。在一些情况下,种子可以是全长种子,全长种子跨越大部分或全部预先存在的音频(或视听)作品并针对音频(或视听)作品的至少一些部分混合了播种用户的捕获媒体内容。在一些情况下,可以采用短种子,其跨越少于全部(并且在一些情况下远少于全部)的音频(或视听)作品。例如(如图13所示),音频(或视听)作品的主歌、副歌、反复、叠句或其他有限的“块”可以构成后续加入的种子。播种用户可以选择音频或视听作品1301的预标明部分(在这里是音乐部分)。由此产生的短种子1311构成了多个协作(在这里是协作#1和#2)的种子。无论其程度或范围如何,种子或种子部分都会界定协作请求(或召唤),以供其他人加入。通常,召唤邀请其他用户通过跟唱、唱特定的人声部分或音乐部分、唱和声或其他二重唱部分、说唱、说话、鼓掌、录制视频、添加来自相机胶卷的视频片段等来加入全长种子或短篇种子。在图13的短种子示例中,邀请1321和1322是说明性的。可以在社交网络中张贴、直播或以其他方式散布(1341)由此产生的团体表演,无论是全长的还是仅一块。
播种用户可以使用拖动技术来选择种子或种子部分,这些拖动技术允许在录制时、在编辑期间和/或在回放中向前和向后遍历视听内容,该视听内容可选地包括音高提示、波形型或包络型表演时间线、歌词、视频和/或其他时间上同步的内容。以这种方式,所选择的表演部分的重新捕获、团体部分的协调以及加录都可被促进。直接滚动到表演时间线、歌词、音高提示和其他时间上同步的内容中的任意点允许用户方便地在捕获或视听编辑会话中移动。对于涉及短种子的选择或实施例,可以采用拖动技术来定义起点和终点,这些起点和终点界定了特定的种子部分或块。同样,在全长种子的情况下,可以采用拖动技术来定义起点和终点,这些起点和终点界定了邀请加入者对其做出贡献的表演时间线的各部分。
在一些情况下,诸如在针对二重唱引导的短篇捕获中,可以与团体部分信息相对应地在表演时间线、歌词、音高提示和其他时间上同步的内容中引导用户歌手。拖动器允许用户歌手方便地在时间上同步的内容中向前和向后移动。在一些情况下,还结合拖动器来支持时间上同步的视频捕获和/或回放。注意,虽然可以为多个媒体行(例如,伴奏音频、人声、歌词、音高提示和/或团体部分信息)的同步遍历提供拖动,但是也设想到单媒体拖动。
不需要在所有情况或实施例中都采用拖动技术。表演时间线的各部分(常常是对应于音乐部分的部分)可被标明和标记以供用户选择。标明/标记可以基于人力或自动来源。例如,特定部分可以由最初上传曲目或对应歌词的用户来标明或标记,或者由媒体内容管理者来标明或标记。以补充方式或可替代地,特定部分可以由被训练为识别部分和边界(例如,根据音频伴奏或人声轨道、歌词,或者基于源自大众的数据,诸如用户倾向于在哪里唱得最多或最大声)的机器学习机器人来标明或标记。受益于本公开的本领域技术人员将理解这些和其他的变体。
图14和图15示出了用于为在地理分散的表演者捕获、协调和/或混合视听内容的示例性技术。具体而言,图14是示出根据本发明的一些实施例的针对所捕获的人声表演的实时且连续的乐谱编码的音高校正和和声生成的流程图。在所示出的配置中,用户/歌手随着伴奏曲以卡拉OK风格唱歌。从麦克风输入201捕获的人声(251)被连续且实时地进行音高校正(252)和配和声(255),以便与在一个或多个声换能器202上可听见地呈现的伴奏曲进行混合(253)。
音高校正和所添加的和声都被选择以对应于乐谱207,乐谱207在所示出的配置中被无线地传送(261)到(一个或多个)设备(例如,从内容服务器110到手持设备101,回顾图1,或机顶盒设备),在这一个或多个设备上,将与歌词208和伴奏曲209的音频编码一起执行人声捕获和音高校正。在本文描述的技术的一些实施例中,基于乐谱207来判定与用户/歌手所发出的音符最接近的音符(在当前音阶或调中)。虽然该最接近的音符通常可以是与乐谱编码的人声旋律相对应的主音高,但它不一定如此。实际上,在一些情况下,用户/歌手可能打算唱和声,并且所发出的音符可能更近似于和声轨道。
在一些实施例中,可以使用电视型显示器和/或机顶盒设备的设施来执行对人声音频和表演同步视频的捕获。然而,在其他实施例中,手持式设备(例如,手持式设备301)本身可支持对人声音频和表演同步视频两者的捕获。因此,图15示出了根据某些实施方式的基本信号处理流程(350),其适合于移动电话型手持设备301捕获人声音频和表演同步视频,生成音高校正后的且可选地配和声的人声以进行可听呈现(在本地和/或在远程目标设备上),以及与内容服务器或服务平台310进行通信。
基于本文的描述,本领域普通技术人员将理解信号处理技术(采样、滤波、抽取等)和数据表示对软件的功能块(例如,(一个或多个)解码器352、数模(D/A)转换器351、捕获353、353A和编码器355)的合适分配,该软件可执行来提供图15所示的信号处理流程350。同样,相对于图14、信号处理流程250和说明性乐谱编码音符目标(包括和声音符目标),本领域普通技术人员将理解信号处理技术和数据表示对至少部分地实现为可在手持式或其他便携式计算设备上执行的软件的功能块和信号处理构造(例如,(一个或多个)解码器258、捕获251、数模(D/A)转换器256、混合器253、254和编码器257)的合适分配。
如本领域普通技术人员将认识到的,音高检测和音高校正在音乐和语音编码领域中具有丰富的技术历史。实际上,在本领域中已经采用了各种各样的特征拣选、时域甚至频域技术,并且可以在根据本发明的一些实施例中采用这些技术。在根据本发明的一些实施例中,音高检测方法计算平均幅度差函数(AMDF)并执行逻辑以拣选与音高周期的估计相对应的峰值。基于这样的估计,音高移位重叠添加(PSOLA)技术用于促进波形的重采样以产生音高移位的变体,同时减少拼接的非周期性影响。在共同拥有的标题为“COORDINATING ANDMIXING VOCALS CAPTURED FROM GEOGRAPHICALLY DISTRIBUTED PERFORMERS”并将Cook、Lazier、Lieber和Kirk指定为发明人的第8,983,829号美国专利中更详细地描述了基于AMDF/PSOLA技术的实现。
图16示出了移动设备的特征,该移动设备可以用作用于执行根据本发明的一些实施例的软件实现的平台。更具体而言,图16是移动设备400的框图,移动设备400通常与iPhone
简要地概括,移动设备400包括显示器402,该显示器402可以对与用户的触觉和/或触感接触敏感。触敏显示器402可以支持多点触摸特征,从而处理多个同时的触摸点,包括处理与每个触摸点的压力、程度和/或位置有关的数据。这样的处理促进了利用多个手指的手势和交互以及其他交互。当然,也可以使用其他触敏显示技术,例如其中使用触笔或其他定点设备进行接触的显示器。
通常,移动设备400在触敏显示器402上呈现图形用户界面,从而向用户提供对各种系统对象的访问并用于传达信息。在一些实施方式中,图形用户界面可以包括一个或多个显示对象404、406。在所示出的示例中,显示对象404、406是系统对象的图形表示。系统对象的示例包括设备功能、应用程序、窗口、文件、警报、事件或其他可识别的系统对象。在本发明的一些实施例中,应用程序在被执行时提供本文描述的数字声学功能中的至少一些。
通常,移动设备400支持包括例如移动无线电和无线网络互连功能在内的网络连接性,以使用户能够带着移动设备400及其相关的支持网络的功能旅行。在一些情况下,移动设备400可以与附近的其他设备交互(例如,经由Wi-Fi、蓝牙等)。例如,移动设备400可以被配置为与对等方或一个或多个设备的基站交互。这样,移动设备400可以授予或拒绝对其他无线设备的网络访问权限。
移动设备400包括各种输入/输出(I/O)设备、传感器和换能器。例如,扬声器460和麦克风462通常被包括以促进音频,诸如对人声表演和伴奏曲的可听呈现以及混合的音高校正后的人声表演的捕获,如本文其他地方所描述的。在本发明的一些实施例中,扬声器460和麦克风462可以为本文描述的技术提供适当的换能器。外部扬声器端口464可以被包括,以促进免提语音功能,例如扬声器电话功能。音频插孔466也可以被包括,以便使用头戴式耳机和/或麦克风。在一些实施例中,外部扬声器和/或麦克风可用作本文描述技术的换能器。
其他传感器也可以被使用或提供。接近传感器468可以被包括,以促进对移动设备400的用户位置的检测。在一些实施方式中,可以利用环境光传感器470来促进调节触敏显示器402的亮度。可以利用加速度计472来检测如方向箭头474指示的移动设备400的运动。因此,可以根据检测到的方向(例如,竖屏或横屏)来呈现显示对象和/或媒体。在一些实施方式中,移动设备400可包括用于支持位置确定能力(诸如由全球定位系统(GPS)或其他定位系统(例如,使用Wi-Fi接入点、电视信号、蜂窝网格、统一资源定位符(URL)的系统)提供的位置确定能力)的电路和传感器,以促进本文描述的地理编码。移动设备400还包括相机镜头和成像传感器480。在一些实施方式中,相机镜头和传感器480的实例位于移动设备400的正面和背面上。相机允许捕获静止图像和/或视频以便与所捕获的音高校正后的人声相关联。
移动设备400还可以包括一个或多个无线通信子系统,诸如802.11b/g/n/ac通信设备和/或Bluetooth
图17示出了诸如移动设备400之类的便携式计算设备的相应实例(501和520),其根据本文的功能描述而编程有人声音频和视频捕获代码、用户界面代码、音高校正代码、音频呈现管线和回放代码。描绘了在人声音频和表演同步视频捕获模式下运行的设备实例501,而设备实例520在针对混合视听表演的呈现或回放模式下运行。同样描绘了在呈现或回放模式下运行的电视类型的显示器和/或机顶盒设备520A,尽管如本文其他地方所描述的,这样的设备也可以作为人声音频和表演同步视频捕获设施的一部分来运行。每个前述设备都经由无线数据传输和/或居间网络504与服务器512或服务平台进行通信,该服务器512或服务平台容宿本文针对内容服务器110、210说明的存储和/或功能。使用本文描述的技术的利用表演同步视频捕获的所捕获的音高校正后的人声表演可以(可选地)在膝上型计算机511上被流传输并以视听方式呈现。
尽管参考各种实施例描述了本发明,但是将会理解,这些实施例是说明性的,并且本发明的范围不限于它们。许多变化、修改、增加和改进都是可能的。例如,尽管已经描述了根据卡拉OK风格的界面捕获的音高校正人声表演,但是将理解其他变化。另外,尽管已经在某些说明性应用的上下文中描述了某些说明性信号处理技术,但是本领域普通技术人员将认识到,修改所描述的技术以适应其他合适的信号处理技术和效果是直截了当的。
根据本发明的实施例可以采取作为指令序列和软件的其他功能构造而被编码在计算机可读介质中的计算机程序产品的形式并且/或者被提供作为该计算机程序产品,该计算机程序产品可以继而在计算系统(诸如iPhone手持设备、移动或便携式计算设备、媒体应用平台、机顶盒、或内容服务器平台)中被执行以执行本文描述的方法。一般而言,机器可读介质可以包括有形物品以及易发生信息传输的非暂时性存储,这些有形物品将信息编码为机器(例如,计算机、移动或便携式计算设备的计算设施、媒体设备或流式传输器等)可读的形式(例如,编码为应用程序、源代码或目标代码、功能描述信息等)。机器可读介质可包括但不限于:磁存储介质(例如,磁盘和/或磁带存储);光存储介质(例如,CD-ROM、DVD等);磁光存储介质;只读存储器(ROM);随机存取存储器(RAM);可擦除可编程存储器(例如,EPROM和EEPROM);闪存;或者适合于存储电子指令、操作序列、功能描述性信息编码等的其他类型的介质。
一般而言,可以为在本文中描述为单个实例的组件、操作或结构提供多个实例。各种组件、操作和数据存储之间的边界在某种程度上是任意的,并且在特定说明性配置的上下文中说明了特定操作。功能的其他分配被设想到,并且可以落入本发明的范围内。一般而言,在示例性配置中呈现为单独组件的结构和功能可被实现为组合的结构或组件。类似地,呈现为单个组件的结构和功能可被实现为单独的组件。这些和其他变化、修改、添加和改进可以落入本发明的范围内。
- 具有种子/加入机制的视听协作系统和方法
- 基于POS机制的新生儿眼底筛查协作学习方法及系统