一种海量数据质量管理与治理的系统
文献发布时间:2023-06-19 11:35:49
技术领域
本发明涉及大数据治理,特别涉及一种海量数据质量管理与治理的系统。
背景技术
随着信息科技的广泛使用,产生了海量的数据信息,这些数据信息没有完整的、科学的、安全的、高质量的数据管控体系,使得海量离线数据正在侵蚀数据拥有单位工作效率,繁杂的调取流程使得数据价值的释放变得非常困难,数据管理面临诸多困扰,容灾困难、数据孤岛、业务扩张等问题让现有的系统早已不堪重负。
发明内容
为了解决上述现有技术中存在的问题,本发明提供一种海量数据质量管理与治理的系统。
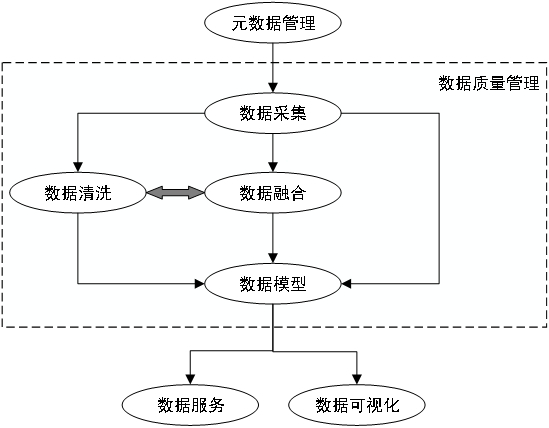
本发明解决其技术问题所采用的技术方案是:一种海量数据质量管理与治理的系统,系统用于将各种数据进行集中管理,对数据进行综合治理,并将治理后的数据采用数据模型服务的方式对外提供数据服务支持;其中,系统包括有元数据管理模块、数据采集模块、数据清洗模块、数据融合模块、数据模型模块、数据服务模块和数据可视化模块;其中,元数据管理模块分别依次连接于数据采集模块、数据融合模块、数据模型模块;数据模型模块分别连接于数据服务模块和数据可视化模块;其中,数据采集模块经由数据清洗模块连接于数据模型模块;数据清洗模块与数据融合模块双向连接。
本发明还具有以下附加技术特征:
作为本发明技术方案进一步具体优化的:元数据管理模块,用于管理系统中所有数据的元数据信息,元数据的来源包括采集和自定义两种途径,数据元用于对元数据进行约束,建立完善的元数据管理体系,为数据治理提供数据约束标准。
作为本发明技术方案进一步具体优化的:数据采集模块,用于采集各种数据资源,包括文件数据、常见结构化数据库数据或接口数据;数据采集涵盖全量采集与增量采集,操作方式提供手动采集与自动定时采集;数据采集后进行统一集中存储,结构化数据存储采用HBase数据库,非结构化数据存储采用HDFS。
作为本发明技术方案进一步具体优化的:数据清洗模块,采用常见的清洗规则,并提供自定义清洗规则以便根据需要进行灵活的扩展,自定义数据清洗规则支持shell脚本扩展和jar包扩展;数据清洗任务的驱动方式为数据驱动,将自动监控数据清洗源表的数据变化,根据数据变化自动按照清洗规则进行数据清洗;清洗后的结果独立存储。
作为本发明技术方案进一步具体优化的:数据融合模块,用于将数据按照定制的规则进行融合,包括数据行融合和数据列融合,融合后的数据将更为完善,数据覆盖面将更大;数据融合采用数据驱动方式,驱动原理与数据清洗一致;数据融合的结果将存储到数据融合目标表。
作为本发明技术方案进一步具体优化的:数据模型模块,用于对外提供标准的数据服务,服务实体模型可根据应用需求灵活构建,实体模型之间可根据业务需求进行灵活关联,从而灵活建立数据模型,通过模型对外提供标准的、可控的、可扩展的数据模型服务;实体模型的数据可由采集的数据、经过清洗的数据和经过融合的数据来提供,可由多种数据同时为一个数据模型提供数据支持。
作为本发明技术方案进一步具体优化的:数据服务模块,是建立在数据模型的基础之上,通过数据服务申请获取数据模型服务支持,管理数据服务的安全或调度,做为数据服务的控制中心为数据使用提供安全控制。
作为本发明技术方案进一步具体优化的:数据可视化模块,是通过图表、列表或数据网络图的方式为数据提供可视化展示。
作为本发明技术方案进一步具体优化的:海量数据质量管理与治理的系统还提供数据血统分析或数据溯源的功能。
本发明和现有技术相比,其优点在于:
优点A:灵活、标准的元数据管理体系,元数据支持从数据库提取和自定义创建,并通过数据元映射进行约束。
优点B:全方位的数据质量跟踪体系,数据治理的任意环节的过程数据均可根据数据标准体系约束进行质量检测分析,提供质量分析报告。
优点C:完善的数据治理体系,涵盖数据采集、清洗、融合、质量检测、血统分析、数据服务及数据可视化的全过程。
优点D:标准的数据模型服务体制,为第三方数据应用提供灵活的模型服务配置。
优点E:丰富的数据展示方式,通过多种方式和技术手段实现不同角度的数据视图,直观简洁的展示数据价值所在。
优点F:高效的数据驱动处理机制,通过监控数据变化根据制定的数据治理规则自动进行数据治理,根据硬件资源情况动态控制资源使用情况,最大限度利用硬件资源提高数据治理效率。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明海量数据质量管理与治理系统的总体流程图。
具体实施方式
下面将参照附图更详细地描述本发明公开的示例性实施例,这些实施例是为了能够更透彻地理解本发明,并且能够将本发明公开的范围完整的传达给本领域的技术人员。虽然附图中显示了本发明公开的示例性实施例,然而应当理解,本发明而不应被这里阐述的实施例所限制。
一种海量数据质量管理与治理的系统,系统用于将各种数据进行集中管理,对数据进行综合治理,并将治理后的数据采用数据模型服务的方式对外提供数据服务支持;数据管理与治理系统同时还提供了数据血统分析、数据溯源的功能,通过数据血统分析和数据溯源直观的反映出数据治理过程,查看数据流向及数据演变的详细路径,是数据疏导的一张图体现。
其中,如图1所示,系统包括有元数据管理模块、数据采集模块、数据清洗模块、数据融合模块、数据模型模块、数据服务模块和数据可视化模块;其中,元数据管理模块分别依次连接于数据采集模块、数据融合模块、数据模型模块;数据模型模块分别连接于数据服务模块和数据可视化模块;其中,数据采集模块经由数据清洗模块连接于数据模型模块;数据清洗模块与数据融合模块双向连接。
具体的,元数据管理模块,用于管理系统中所有数据的元数据信息,元数据的来源包括采集和自定义两种途径,数据元用于对元数据进行约束,以此建立一套完善的元数据管理体系,为数据治理提供数据约束标准。
具体的,数据采集模块,用于采集各种数据资源,包括文件数据、常见结构化数据库数据和接口数据;数据采集涵盖全量采集与增量采集,操作方式提供手动采集与自动定时采集;数据采集后进行统一集中存储,结构化数据存储采用HBase数据库,非结构化数据存储采用HDFS。
具体的,数据清洗模块,采用常见的清洗规则,并提供自定义清洗规则以便根据需要进行灵活的扩展,自定义数据清洗规则支持shell脚本扩展和jar包扩展;数据清洗任务的驱动方式为数据驱动,将自动监控数据清洗源表的数据变化,根据数据变化自动按照清洗规则进行数据清洗,采用这种方式很好的避免了硬件资源的空耗和浪费;清洗后的结果独立存储,原数据不会发生变化,有利于进行清洗回滚和重复清洗。
具体的,数据融合模块,用于将数据按照定制的规则进行融合,包括数据行融合和数据列融合,融合后的数据将更为完善,数据覆盖面将更大;数据融合采用数据驱动方式,驱动原理与数据清洗一致;数据融合的结果将存储到数据融合目标表,融合来源表的数据不会因此而发生变化。
具体的,数据模型模块,用于对外提供标准的数据服务,服务实体模型可根据应用需求灵活构建,实体模型之间可根据业务需求进行灵活关联,从而灵活建立数据模型,通过模型对外提供标准的、可控的、可扩展的数据模型服务;实体模型的数据可由采集的数据、经过清洗的数据和经过融合的数据来提供,可由多种数据同时为一个数据模型提供数据支持。
具体的,数据服务模块,是建立在数据模型的基础之上,通过数据服务申请获取数据模型服务支持,管理数据服务的安全、调度,做为数据服务的控制中心为数据使用提供安全控制。
具体的,数据可视化模块,是通过图表、列表、数据网络图等方式为数据提供可视化展示,简洁直观的反应出数据价值。
实施例1
一种海量数据质量管理与治理的系统,提供了一套完整的、科学的、安全的、高质量的数据管控体系,满足对异构系统进行元数据管理、数据采集、数据质量检测、数据清洗、数据融合等治理过程,并可以通过对数据组建灵活的数据模型向外提供数据服务,能满足异构数据应用的要求。本发明具有完整的数据监控体系和运维监控体系,可以通过简单的页面操作掌控数据治理的全过程,实时把握系统的运行状况。血统分析是数据质量管理和数据治理的重要功能,通过元数据发展链条追溯数据的发展与演变过程,直观展示数据起源何处、用于何处、去往何处。本发明提供对数据进行通用的可视化分析功能,通过简单的页面配置操作可灵活获取到各种数据资源的统计分析结果。
元数据管理采用元数据采集和元数据自定义方式创建各异构系统的元数据信息,从元数据上为各系统数据的统一管理奠定基础,为数据质量管理建立统一标准。
数据采集满足常见关系型数据库采集、FTP文件采集、接口数据采集三种采集方式,采集适配扩展方便,适应于各种数据采集场景。
数据质量管理根据元数据的质量要求检查数据质量,通过统计图表和数据质量报告及时反馈数据质量情况。采集原数据、清洗数据、融合数据均可通过数据质量管理及时反映数据质量问题,做到全面的质量管理。
数据清洗功能中,系统设置了常见的十余种数据清洗规则,并支持shell脚本和jar脚本两种类型的自定义清洗规则扩展,可满足几乎所有数据清洗的要求,为提升数据质量提供了丰富的手段。
数据融合功能中,提供了通过绘制流程图的方式创建数据融合方案,数据融合支持数据行融合和数据列融合两种方式,数据融合可使数据合并管理,完善了数据链,使数据的完整性和可用性得到进一步提高。
数据建模是数据应用的基础,根据应用需要建立元数据信息,使用元数据建立实体数据模型,通过实体数据模型的关联建立实体数据模型关系,形成完整的数据模型。第三方应用可通过申请使用数据模型服务,对数据模型服务进行数据调用监控,从提供服务、管理服务、数据使用监管方面实现集中式数据模型服务体系,确保数据服务的安全、稳定及标准化。
数据可视化是直观查看数据的一种手段,分为数据可视化查询和数据可视化统计。数据可视化查询是通过数据可视化手段查询并展示数据,可以查询数据的基本信息,并根据基本信息关联查询数据链上的其它数据信息,通过数据关系图谱进行展示。数据统计展示提供了常用的数据统计展示图表,并支持根据需要自定义统计图表,通过简单的配置完成统计结果呈现。
数据溯源是数据质量管理与数据血统分析的过程。通过查询元数据信息,使用关系图谱展示元数据发展、演化过程;通过查询数据,精确定位一条数据的发展、演化过程;通过数据流向图直观展示数据在治理过程中的总体流向,形成数据质量管理与治理的数据地图。
尽管已经对上述各实施例进行了描述,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改,所以以上仅为本发明的实施例,并非因此限制本发明的专利保护范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围之内。
- 一种海量数据质量管理与治理的系统
- 一种基于海量数据处理的数据治理的方法及系统