渐进式学习的单视角CT重建方法
文献发布时间:2023-06-19 11:39:06
技术领域
本发明属于计算机断层图像重建(CT)领域,尤其涉及利用深度学习技术以渐进学习的方式从单张X射线图像重建出目标的CT图像,具体为渐进式学习的单视角CT重建方法。
背景技术
随着CT技术在医学辅助诊断和治疗领域的重要性日益增加,CT已成为了一种很常见的检查技术。然而,检查中X射线给人带来的辐射损伤和风险也越来越引起人们的关注和重视。目前常见的CT扫描重建方式要求获取病人大量的X射线图像,对于更先进的4D CT,需要的X射线图像更多。这在无形中会给病人增加辐射伤害,尤其是对那些需要进行多次CT检查的肿瘤病人还有肺炎患者。为了减少辐射,一些方法获尝试从低剂量的X射线图像中重建CT,但这也同时会降低重建图像的质量。更多的研究是通过减少获取的X射线图像的数量来降低总的辐射量,中国专利“一种基于DTw-SART-TV迭代过程的有限角度 CT图像重建方法”(CN112381904A)提出了相应的有限角度,中国专利“一种稀疏角度X射线CT成像方法”(CN103136773A)提出了稀疏角度的CT重建方法。其中,中国专利CN112381904A结合SART和IRS步骤,通过两个阶段不断地迭代计算,从而从有限角度采集X射线投影中重建CT图像。而中国专利CN103136773A则是需要采集全角度的X射线图像并预先进行CT重建,然后再利用优化模型迭代求解最终的CT图像。这两类CT重建算法需要结合先验模型,通过迭代的方式来重建图像。在重建高分辨率图像时,这两类方法则需要更长的计算时间,在重建效率上也要低于传统解析的CT重建方法。此外,有限角度的方法在一些扫描角度非常受限的场景下会因为数据严重缺失而无法迭代重建出高质量的图像。解决极少角度CT重建问题,从而极大降低病人的辐射风险是本发明的一个目标。
近几年,深度学习技术的快速发展为传统CT技术开辟了新的方向。基于深度学习的有限角度和稀疏角度CT重建方法不断出现。由于基于学习的模型在经过训练后拥有远超过传统CT的重建效率,使得这类方法有着很广阔的发展前景。但这类方法的问题一方面在于需要大量的关于病人的CT数据用于训练模型,而这通常难于获得。另一方面,在一些CT扫描角度受限或者采集投影数量接近极限场景下,上述基于深度学习的方法重建的CT图像质量可能满足不了医学诊断要求。因此这类方法也存在一定局限性。但深度学习技术在提取图像信息和构建非线性模型上的强大能力,使得一些研究者对其进一步研究。实现了在扫描范围和X射线图像数量同时到最小达极限时的CT重建,即从单张X射线图像实现CT图像重建(简称为单视角CT),这极大地降低了辐射总量。然而由于这一极具挑战的问题本身很复杂且存在着求解上的病态,构建一个合适的深度学习网络和设计一个能使网络训练稳定的训练策略并不容易,这使得目前的基于单视角的深度学习方法虽然可以从单张X射线图像重建一个外形比较像的CT结果,但是在重建CT图像质量和结构细节上还有待改善。因此,进一步改善CT重建图像质量是本法明的另一个目标。通过结合CT图像特点本发明构建了更合适的网络,此外本发明还设计了相应的网络训练策略,使网络训练更稳定并有效提高了图像质量。
发明内容
为了提高单视角CT重建图像的质量,本发明设计了一个结合注意力机制和自适应实例归一化的卷积神经网络(CT重建网络)。通过本发明所提的渐进式学习策略来训练该网络,能使网络训练更稳定并有效地提升重建图像质量。
为实现上述发明目的,本发明的技术方案如下:
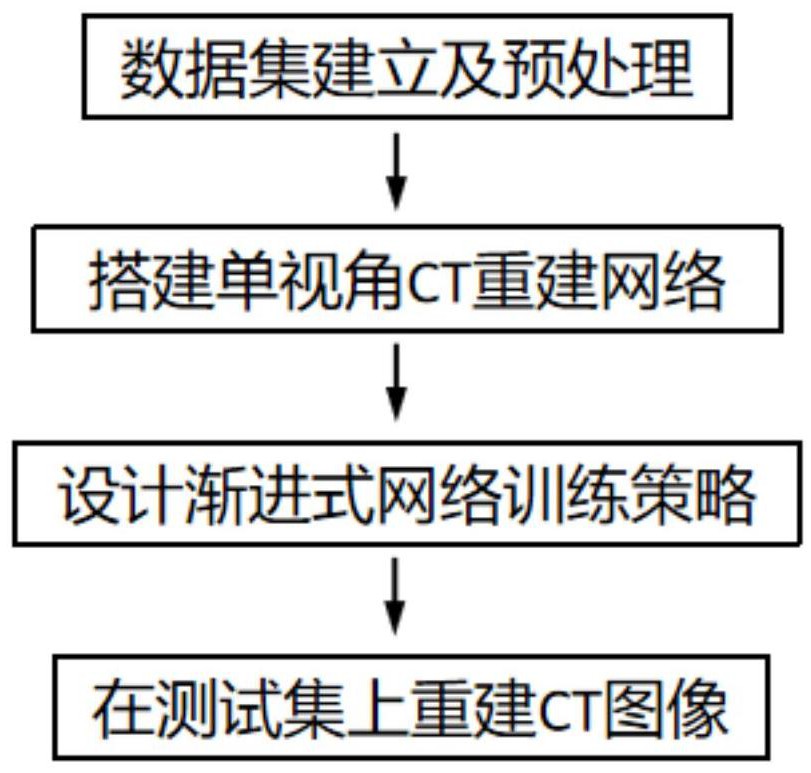
一种渐进式学习的单视角CT重建方法,包括如下步骤:
步骤1、数据集建立及预处理。
数据集包含大量成对的X射线图像和相应的CT体积图像,成对的图像数据通过先分别求取均值μ和方差σ,然后进行标准化(x-μ)/σ的方式进行处理,其中x表示待标准化的X射线图像或者CT体积图像;再将数据集划分为训练集和测试集分别用于网络训练和预测。
步骤2、搭建从单张X射线图像重建CT图像的CT重建网络。
所述网络包括三个结构:特征编解码结构、2D到3D特征转换结构和特征融合结构。
所述特征编解码结构包含编码和解码两个部分。编码部分利用多个卷积模块对输入的单张X射线图像进行特征提取和下采样,同时将提取的特征编码到隐层空间。解码部分利用多个卷积运算模块将隐层空间中编码后的信息进行卷积上采样,最终恢复3D的CT体积图像。
所述2D到3D特征转换结构是所述特征编解码结构的一部分,用于连接编解码结构中同级的特征,从而弥补编码过程中信息的损失。所述2D到3D特征转换结构包含特征通道注意力和特征转换两个部分。特征通道注意力部分对编码过程中不同通道的特征重新赋予不同权重,高权重的特征给与更多的关注。特征转换部分则将经过权重分配后的特征进行转换,使其更接近于CT图像的特征。
所述特征融合结构将所述2D到3D特征转换结构的结果和特征编解码结构中解码部分的中间结果进行特征融合,从而有助于提高重建CT图像的质量。所述特征融合结构中包含三步运算,第一步计算2D到3D特征转换结构输出结果的均值和方差,第二步计算特征编解码结构中编码部分输出的中间结果的均值和方差,第三步根据第一步和第二步计算的均值和方差将前两步中所述结构的输出特征进行融合。
步骤3、设计针对步骤2所述CT重建网络的渐进式学习(训练)策略
所述渐进式训练策略是一种向CT重建网络输入多尺度分辨率图像并对网络进行训练的策略,包含网络扩增和参数转移两个过程。网络训练从低分辨率图像输入开始,直到网络的训练过程收敛,然后进行网络的扩增,通过增加网络层数得到一个更大的新的网络。同时参数转移过程将已经训练过的网络的参数转移到新的网络中,随后向新的网络输入分辨率更大的图像,并继续进行网络训练。通过不断重复所述网络扩增和参数转移过程,使网络从学习小分辨率图像中的大尺度结构逐渐过渡到学习更大分辨率图像中的精细结构,从而有助于提高重建的CT图像质量。
步骤4、使用步骤3中训练好的CT重建网络在测试数据集上进行测试。通过向网络输入单张X射线图像可重建CT体积图像。
本发明的有益效果是:
本发明设计了一种用于从单张X射线图像重建CT体积图像的单视角CT重建方法。通过渐进式学习的方式训练本发明所设计的CT重建网络,一方面能够有效地提高重建的CT图像质量,为未来癌症病人的精准放疗提供有效的图像引导信息。另一方面能够极大降低X射线辐射的总量,减少病人在多次CT检查时受到的辐射损伤和潜在风险。
附图说明
图1是本发明方法步骤流程图。
图2是本发明CT重建网络中的编解码结构。
图3是本发明CT重建网络中的特征转换结构。
图4是本发明渐进式训练策略总体图。
图5(a)~图5(c)是本发明方法的CT重建结果图,其中,图5(a)为输入X射线图像,图5(b)为重建的CT图像,图5(c)为真实的CT图像。
具体实施方式
下面结合附图和技术方案,进一步说明本发明的具体实施方式。
如图1所示,一种渐进式学习的单视角CT重建方法,包括以下步骤:
步骤1、数据获取及预处理。本实施例从公开的医学图像数据集获得了癌症病人肺部、腹部和脑部的CT数据集,通过模拟投影的方式建立了包含成对的X 射线图像和CT体积图像的数据集,并将数据集按照7:3的方式划分出训练集和测试集。对数据集中每一个成对的数据通过先分别求取均值和方差,然后进行标准化的方式进行处理。例如,对于X射线图像,先求取其均值μ和方差σ,然后进行标准化(x-μ)/σ的方式进行处理,其中x表示待标准化的X射线图像。 CT体积图像按相同的方式处理。
步骤2、搭建从单张X射线图像重建CT图像的CT重建网络。所述的网络结构如图2所示。其中包含了特征编解码结构,2D到3D特征转换结构,特征融合结构。该网络充分提取输入单张X射线图像中重要的特征,特别设计的特征转换网络能够弥补特征提取过程中信息的丢失,通过特征融合结构将一些信息融合到输出的CT特征中,从而提高重建CT图像的质量。该过程包含了以下步骤:
(1)所述的特征编解码结构对输入的128×128分辨率的图像通过卷积层和通用的下采样残差块对图像进行编码,从而得到隐层编码特征。在编码过程中特征通道数从输入的1逐渐增长到1280,同时特征分辨率从128x128逐渐下采样到8x8。在上采样过程中,通过上采样残差块和卷积层将隐层编码特征解码,其中通道的数量从1280逐渐下降到128,同时特征分辨率逐渐上采样到128× 128,从而输出CT体积图像(128×128×128)。
(2)在编解码结构中,特征下采样过程因为分辨率不断降低,这导致信息的损失。因此,所述特征转换结构在下采样前就将特征进行转换,并将转换的特征连接到同级的上采样结果中,从而在一定程度上弥补信息的损失。特征转换结构如图3所示,输入的特征的维度为C×W×H,其中C代表通道数量,W 和H分表表示图像的宽和高。输入特征经过通道注意力部分对不同的通道特征赋予不同的权值,该权值在网络训练时由网络自动学习得到,从而使网络关注一些重要的特征。所述通道注意力部分有不同的实现方式,在本实施例中采用自适应实例归一化的方式来实现通道注意力部分。该部分包含了通道压缩、权值激活和加权运算三个过程,分别通过1×1的卷积、全连接和点积运算实现。这些重要特征然后通过特征变换转换到类似于CT的特征。所述特征变换的实现并不唯一,本实施例中该变换包括了2×2大小的卷积下采样、二维的卷积和2×2 大小的卷积上采样三个过程。
(3)所述的特征融合结构将所述特征转换结构的结果x与上采样的结果y进行融合。本实施例中采用通用的自适应实例归一化的方法进行融合。方法如下:
其中,μ(·)表示均值,σ(·)表示标准差。
步骤3、本发明设计的CT重建网络通过所述的渐进式的学习方式在训练集上进行训练。所述的渐进式的学习过程如图4所示。网络的训练从低分辨率输入开始,使网络先关注低分辨率图像中的大尺度结构。训练完成后得到一些学习的模型参数,该模型参数通过参数转移过程向新的网络对应的部分转移。新的网络通过增加一些新的网络层进行网络扩层,从而提高网络学习更大分辨率图像中细节的能力。经过不断的网络训练、网络扩增和参数转移过程最终引导网络一步步地提高重建的CT图像的质量。本实施例中,训练集中成对的X射线图像和CT体积图像的分辨率分别为128×128和128×128×128。X射线图像用于网络输入,CT体积图像用于监督网络生成的结果。在低分辨率图像训练阶段,输入的低分辨率图像(16×16)由高分辨率图像(128×128)通过下采样得到,经过3次的训练、网络扩增和参数转移过程,最终扩增的网络模型输出分辨率为128×128×128的CT体积图像。
步骤4、通过步骤3所述的渐进式的学习策略来训练CT重建网络,最终得到训练好的模型参数。在测试集中,我们向训练好的模型输入未用于网络训练的X射线图像,并与相应的真实的CT体积图像对比来验证本发明的有效性。图5(a)~图5(c)展示了一些重建的CT图像结果,可以看到重建的CT图像和真实CT图像很接近,在细节上的表现也较好。表1展示了网络中的基于注意力机制的特征转换结构、特征融合结构以及渐进式学习的策略的定量评价结果,验证了本发明的有效性。可以看到当所有网络结构和策略都应用时,本发明的重建的CT结果在两个常用的图像质量评价指标(峰值信噪比(PSNR)、结构相似性(SSIM))上的表现最好。此外,训练好的网络模型在实际部署应用时只需要采集病人一张X射线图像就可以实现相应的CT图像重建,完成一次重建的时间大约为0.1秒。
表1定量评价结果
PG.:渐进式训练策略;Ada.:融合结构;Att.:基于注意力的特征转换结构。
- 渐进式学习的单视角CT重建方法
- 集成FDK和深度学习的单视角CT重建方法