一种基于余弦空间优化的图像分类损失函数的设计方法
文献发布时间:2023-06-19 11:39:06
技术领域
本发明涉及计算机视觉与人工智能领域,特别是涉及一种基于余弦空间优化的图像分类损失函数的设计方法。
背景技术
目标分类算法是计算机视觉中基础且重要的研究领域,目前的目标分类算法领域随着深度学习技术的发展,已经可以解决绝大部分的简单分类问题,即AlexNet之后涌现了一系列CNN模型如ResNet、GoogleNet、EfficientNet,不断刷新在ImageNet数据集上的成绩,随着采用更加复杂的网络结构与引入深度残差连接,目前最优的图像分类算法在ImageNet数据集上的Top-1精度已经达到了84.4%,然而这些算法模型通常具有巨大的参数量与计算复杂度。对于需要部署算法的边缘移动场景,由于内存受限,计算力受限的问题,难以使用大型网络,因此轻智能网络的需求逐渐增加。为了提高轻量级图象分类算法的精度,在不增加模型复杂度与数据量的情况下,优化损失函数可以有效提升网络的精度,是解决轻量级图像分类网络精度较低的有效方案。
常用于图像分类领域的损失函数为sigmoid交叉熵损失函数与softmax交叉熵损失函数,其监督能力较为有限,只能在欧式空间中将差异较大物体的分类结果拉开,对于相似度较大的类别,分类能力较弱,因此引入在人脸识别领域中的损失函数,并针对图像分类做进一步优化,以达到图像分类更好的效果,具有较大的实用价值。
发明内容
有鉴于此,本发明的目的在于提供一种基于余弦空间优化的图像分类损失函数的设计方法,通过该方法设计的损失函数能够在不增加网络参数量与训练数据量的前提下,提高分类算法的精度,适用于轻智能网络。
为了实现上述目的,本发明采用如下技术方案:
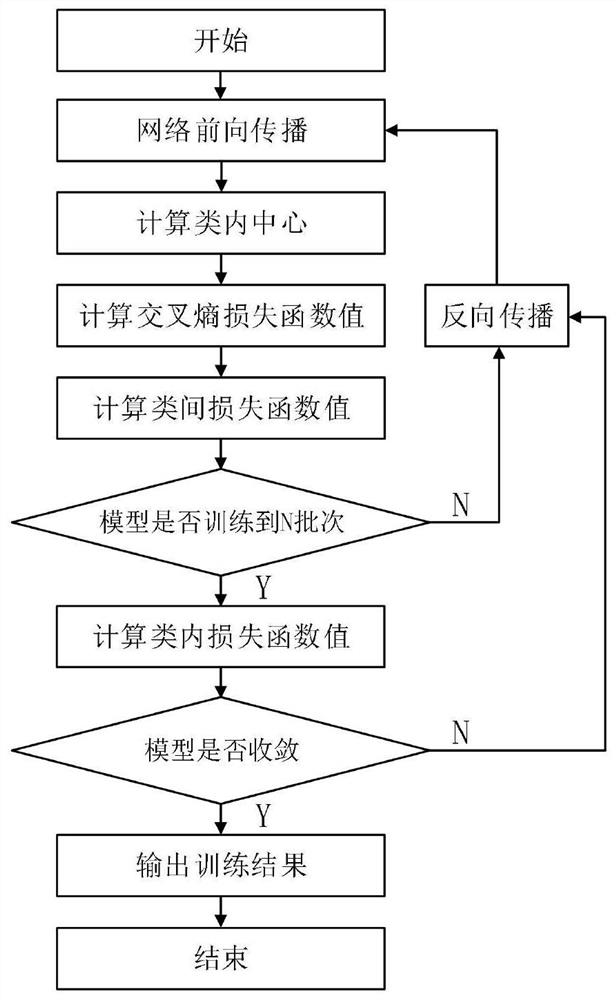
一种基于余弦空间优化的图像分类损失函数的设计方法,包括如下步骤:
步骤S1、获取数据集,设定超参数并初始化深度学习模型;
步骤S2、对所述深度学习模型进行多批次的迭代训练,且在每个迭代批次中依次执行步骤S21-步骤S23;
步骤S21、根据所述深度学习模型在前向传播过程中得到的特征向量,计算当前迭代批次内每一类别物体的类内中心,并累计更新所述类内中心;
步骤S22、计算当前迭代批次的交叉熵损失函数值和类间损失函数值;
步骤S23、判断当前迭代批次是否达到预先设定的批次数N;
若未达到,则计算当前迭代批次的第一总损失函数,并将所述第一总损失函数进行梯度反向传播,更新模型参数,回到步骤S2进行新一轮的训练;
若达到,则计算当前迭代批次的类内损失函数值,并且结合所述第一总损失函数和所述类内损失函数值,计算第二总损失函数值,并将所述第二总损失函数值进行梯度反向传播,更新模型参数,进入步骤S3;
步骤S3、判断所述深度学习模型是否收敛,
若未收敛,则回到步骤S2重新进行迭代训练,直到模型收敛;
若收敛,则输出模型。
进一步的,在所述步骤S1中,所述超参数包括:加权系数α、加权系数β、加权系数γ和紧致系数ε,并且满足:γ>α>β;
所述超参数还包括所述步骤23中的批次数N,所述N∈(0,Epoch
进一步的,所述第一总损失函数的表达式为:
Loss=αLoss
公式(1)中,α和γ表示为加权系数,Loss
进一步的,所述类间损失函数的表达式为:
公式(2)中,n表示为一个批次内样本数量,s表示为缩放系数,m表示为不同类别的决策边界在余弦空间内的距离,cos
进一步的,所述第二总损失函数的表达式为:
Loss=αLoss
公式(3)中,α、β和γ均表示为加权系数,Loss
进一步的,所述类内损失函数的表达式为:
公式(4)中,C
本发明的有益效果是:
本发明在模型训练的前半阶段采用了AM-Softmax损失函数,拉开类间距离,在训练后半阶段加入可以随训练批次动态调节的类内中心,进一步紧致同一类别物体的特征向量,同时拉开不同类别物体特征向量间的余弦距离,能够使得模型更快收敛,既能够充分的区分相似类别,也能进一步提高模型性能。
附图说明
图1为本发明提供的一种基于余弦空间优化的图像分类损失函数的设计方法的流程示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
本实施提供一种基于余弦空间优化的图像分类损失函数,该损失函数由三部分组成,具体表达式如下式所示:
Loss=αLoss
式中α为类间损失函数的加权系数,β为类内损失函数的加权系数,γ为交叉熵损失函数的加权系数,采用γ>α>β的比例;Loss
其中超参β为分段函数,当算法模型训练的批次小于超参数N时,β取0值,当训练批次超过N时,则β取大于0值。
其中超参数N取值则根据模型的收敛情况进行确定,当模型已经收敛后,再启用β,即使用类内损失函数进一步优化网络,保证了在模型训练的前期,类内中心不稳定时,类内损失函数不影响网络的收敛。
具体的说,在本实施例中,上述Truc(x)函数的表达式为:
该函数主要用来限制类内损失函数对于整体损失函数的影响,通过超参数ε来控制类内损失函数的紧致,减少因为类内损失函数过于紧致而导致的模型过拟合问题,从而能有效的提升模型的泛化能力,降低其对于训练集图片的过拟合,增加算法模型的鲁棒性。
具体的说,在本实施例中,上述Loss
具体的说,在本实施例中,上述Loss
式中,n为一个批次内样本数量,超参s为缩放系数,超参m为不同类别的决策边界在余弦空间内的距离,cos
具体的说,在本实施例中,上述类内损失函数Loss
更具体的说,在本实施例中,上述类内损失函数Loss
式中,C
需要说明的是,在本实施中所采用的类内损失函数,要求网络在训练过程中,不断随训练批次更新余弦空间内的类内中心c
实施例2
本实施例提供一种基于余弦空间优化的图像分类损失函数的设计方法,包括如下步骤:
步骤S1、获取数据集,设定超参数,并初始化深度学习模型;
具体的说,在本实施例中,上述超参数包括:加权系数α、加权系数β、加权系数γ、紧致系数ε和迭代训练的批次数N,并且满足:γ>α>β。
步骤S2、将获取到的数据集,输入初始化后深度学习模型中,对所述深度学习模型进行多批次的迭代训练,且在每个迭代批次中依次执行步骤S21-步骤S23;
步骤S21、根据所述深度学习模型在前向传播过程中得到的特征向量,计算当前迭代批次内每一类别物体的类内中心c
步骤S22、计算当前迭代批次的交叉熵损失函数值和类间损失函数值;
具体的说,上述类间损失函数,即AM-Softmax函数,其表达式为:
式中,n为一个批次内样本数量,超参s为缩放系数,超参m为不同类别的决策边界在余弦空间内的距离,cos
步骤S23、判断当前迭代批次是否达到预先设定的次数N,所述N∈(0,Epoch
若未达到,则计算当前迭代批次的第一总损失函数,并将所述第一总损失函数进行梯度反向传播,更新模型参数,回到步骤S2进行新一轮的训练;
若达到,则计算当前迭代批次的类内损失函数值,并且结合所述第一总损失函数和所述类内损失函数值,计算第二总损失函数值,并将所述第二总损失函数值进行梯度反向传播,更新模型参数,进入步骤S3;
具体的说,在本实施例中,第一总损失函数的表达式为:
Loss=αLoss
公式中,α和γ表示为加权系数,Loss
类内损失函数的表达式为:
公式中,C
第二总损失函数的表达式为:
Loss=αLoss
公式中,α、β和γ均表示为加权系数,Loss
步骤S3、判断所述深度学习模型是否收敛,
若未收敛,则回到步骤S2重新进行迭代训练,直到模型收敛;
若收敛,则输出模型。
需要说明的是,本实施例中所采用的类内损失函数Loss
综上,本发明提出的一种基于余弦空间优化的图像分类损失函数的设计方法,包含了两个阶段,使用超参数N∈(0,Epoch
在第一阶段采用了AM-Softmax损失函数,拉开类间距离,在第二阶段加入可以随训练批次动态调节的类内中心,进一步紧致同一类别物体的特征向量,同时拉开不同类别物体特征向量间的余弦距离,能够使得模型更快收敛,既能够充分的区分相似类别,也能进一步提高模型性能。
本发明未详述之处,均为本领域技术人员的公知技术。
以上详细描述了本发明的较佳具体实施例。应当理解,本领域的普通技术人员无需创造性劳动就可以根据本发明的构思作出诸多修改和变化。因此,凡本技术领域中技术人员依本发明的构思在现有技术的基础上通过逻辑分析、推理或者有限的实验可以得到的技术方案,皆应在由权利要求书所确定的保护范围内。
- 一种基于余弦空间优化的图像分类损失函数的设计方法
- 一种基于同源余弦损失函数的人物识别方法