基于领域注意力机制的终身朴素贝叶斯文本分类方法
文献发布时间:2023-06-19 11:39:06
技术领域
本发明涉及计算机技术领域,具体来说,本发明涉及一种基于领域注意力机制的终身朴素贝叶斯文本分类方法。
背景技术
目前的主流情感分类技术由于灾难遗忘的存在无法持续学习。本文将能够持续学习的方法LNB用于中文情感分类任务,同时在LNB方法的知识库和知识挖掘器之间加入领域注意力机制进一步提升性能。目前的主流情感分类技术的缺点:LNB方法对忽略了任务间的差异,在不同任务知识利用时赋予相同的权重。而实际上较为相似的领域间,可共享的知识较多,反之较少。例如在手机和电视是较为相似的领域,他们的评价较为相似,而冷冻食品和化妆品之间并不相似,对应的评论差异也很大。
发明内容
本发明所要解决的技术问题是提供一种基于领域注意力机制的终身朴素贝叶斯文本分类方法,在KB和KM之间加入了领域注意力模块(domain attention,DA),知识库将知识传递给注意力模块,注意力模块分别计算当前任务知识和每个历史任务知识的相似度,并以此为每个历史任务知识分配权重,改进后的方法记为LNB-att。利用这样的方式进一步提升知识的利用效率。
为实现上述目的,本发明提供以下的技术方案:
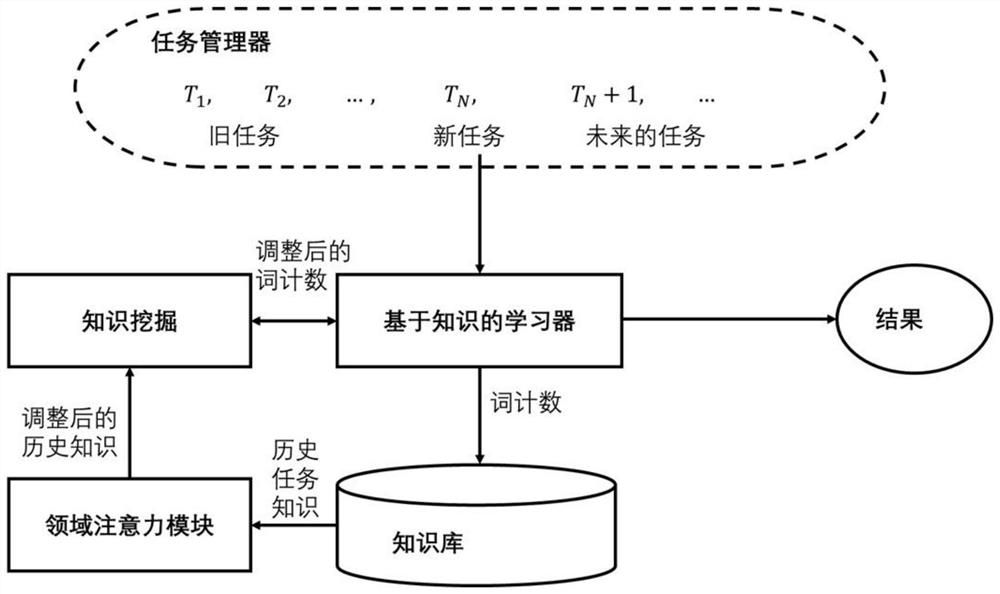
该基于领域注意力机制的终身朴素贝叶斯文本分类方法是在LNB的基础上提出一种基于领域注意力机制的改进方法LNB-att,根据任务间的情感相似度为知识库中的知识赋予不同权重,改进知识迁移能力,将各品类的商品评价视为不同的情感分类任务依次学习,重点研究任务间的知识迁移,使用终身学习架构来解决知识的获取、存储、搜索、利用。包含三个组件:基于知识的学习器、知识库、知识挖掘器,其中学习器实现知识获取使用,知识库负责存储,知识挖掘器搜寻对当前学习有帮助的知识,在KB和KM之间加入了领域注意力模块(domain attention,DA),KB将知识传递给DA,DA分别计算当前任务知识和每个历史任务知识的相似度,并以此为每个历史任务知识分配权重,改进后的方法记为LNB-att,首先定义任务内每个词的情感特征:任务t中词
最后,两个任务SD间的余弦相似度就可以最为相似度如下式:
将知识库中当前任务知识与历史任务知识分别比较相似度,若某个历史任务SD与当前任务SD差较大,那么这个历史任的参考价值较小;反之某个历史任务SD与当前任务SD相差较小,那么这个历史任务的参考价值较大,因此根据SD相似度为每个历史任务知识分配一个权重α
α
在将知识库的历史知识传递给知识挖掘器之前,领域注意力模块会根据权重对每个历史任务知识进行调整,得到
采用以上技术方案的有益效果是:该基于领域注意力机制的终身朴素贝叶斯文本分类方法在LNB架构中加入领域注意力机制,提升模型在中文商品评价情感分类上的性能。在KB和KM之间加入了领域注意力模块(domain attention,DA),知识库将知识传递给注意力模块,注意力模块分别计算当前任务知识和每个历史任务知识的相似度,并以此为每个历史任务知识分配权重,改进后的方法记为LNB-att。利用这样的方式进一步提升知识的利用效率。
附图说明
下面结合附图对本发明的具体实施方式作进一步详细的描述。
图1是LNB框架中文图;
图2是LNB框架英文图;
图3是KM算法过程展示图;
图4是领域注意力机制展示图;
图5是语料库评论字数分布图;
图6是旧任务评估实验结果展示图。
具体实施方式
下面结合附图详细说明本发明基于领域注意力机制的终身朴素贝叶斯文本分类方法的优选实施方式。
图1至图6出示本发明基于领域注意力机制的终身朴素贝叶斯文本分类方法的具体实施方式:
LNB是一种任务增加的终身学习方法,将各品类的商品评价视为不同的情感分类任务依次学习,重点研究任务间的知识迁移,使用终身学习架构来解决知识的获取、存储、搜索、利用。包含三个组件:基于知识的学习器、知识库、知识挖掘器。其中学习器实现知识获取使用,知识库负责存储,知识挖掘器搜寻对当前学习有帮助的知识。
1任务管理器
现有任务序列{S
2基于知识的学习器
基于知识的学习器(KBL)采用朴素贝叶斯文本分类算法,与终身学习有着天然的契合。通过计算每个词w∈V在情感类别c中的条件概率P(w|c
上式中条件概率P(w|c
其中λ用于平滑以解决零频词问题,N
3知识库
知识库(KB)是LNB的关键组件,每个任务在训练时学到的知识被存储在知识库,知识库中包含了当前任务知识和历史任务知识。当前任务S
4知识挖掘器
知识挖掘器(KM)需要在KB中搜寻有用知识来帮助当前任务学习。KM根据历史任务知识和当前任务知识对
KM在知识库的基础上进一步搜寻三种知识:(1)知识库词频
KM将利用以上三种知识找出两类情感词:(1)若词w能够在当前任务中良好的区分正负类样本,称这样的词为领域情感词记为V
KM需要在学习过程中权衡哪些词计数需要调整; 哪些参数需要保留。这与人类认知过程相似,需要在知识的可塑性和稳定性之间进行权衡。利用上述知识, KM开始对词计数进行调整,过程如图3所示,其中V
整体学习过程如图1和图2所示,任务序列中不同领域的情感分类任务依次作为当前任务传递KBL进行训练,KBL将任务训练集中正负样本的数量、每一个词在积极评论和消极评论中出现的次数统计出来,作为当前任务知识存入KB。KM对KB中的历史知识进一步搜索,挖掘更多的情感信息,并将调整后的词计数
在知识挖掘时LNB为每个领域(不同领域的情感分类任务)的知识赋予相同的权重,但在实际中领域间的相似度也存在差异,而相似的领域间可共享的知识较多,反之较少。例如手机和电视较为相似,其评价的用词与表达也较为相似,而冷冻食品和化妆品间不相似,二者评论差异较大。因此可以在知识挖掘时为每个领域的知识根据与当前领域的相似度分配对应权重,这种做法类似于注意力机制, 因此我们称其为领域注意力机制。
对LNB方法进行改进:在KB和KM之间加入了领域注意力模块(domain attention,DA),KB将知识传递给DA,DA分别计算当前任务知识和每个历史任务知识的相似度,并以此为每个历史任务知识分配权重,改进后的方法记为LNB-att,总体结构如图4所示。
LNB中任务知识大都记录的是词汇的情感信息,为方便度量任务之间的差异,首先定义任务内每个词的情感特征:任务t中词
最后,两个任务SD间的余弦相似度就可以最为相似度如下式:
将知识库中当前任务知识与历史任务知识分别比较相似度,若某个历史任务SD与当前任务SD差较大,那么这个历史任的参考价值较小;反之某个历史任务SD与当前任务SD相差较小,那么这个历史任务的参考价值较大,因此根据SD相似度为每个历史任务知识分配一个权重α
α
在将知识库的历史知识传递给知识挖掘器之前,领域注意力模块会根据权重对每个历史任务知识进行调整,得到
1数据集
目前在中文领域有关终身学习研究较少,为此本文构建了一个适用于终身学习设定的中文情感分类数据集。数据采集自京东网不同品类的商品评论和评分。评分范围为一至五星,根据中国网民的评分特点,将一至三星评价归类为消极,四星和五星评价归类为积极。其中包含21个不同的商品品类,作为21个情感分类任务,每个任务数据集每个种类的评论条数,差评占比见(表1、图5)。数据集预处理使用jieba工具分词,去除标点、英文、数字,只保留汉语。训练集、测试集比例为80%、20%。
表1语料库信息
2实验设置
使用NB、SVM[36]、LLV作对比。为全面对比LNB的学习效果,本文对NB和SVM的训练数据做了三种不同的划分:
NB-S、SVM-S:仅使用当前任务的训练集。
NB-T、SVM-T:使用所有历史任务的训练集。
NB-ST、SVM-ST:使用所有任务的训练集。
其中NB-S、SVM-S只有当前任务训练集,是常规的孤立学习范式;NB-ST、SVM-ST包含历史任务训练集,可视为一种特殊的终身学习方法,LLV是一种基于投票的终身学习方法,LNB-att是本文提出的加入领域注意力机制的改进方法。
经过遍历每一种参数组合我们发现LNB在中文数据集上的最优参数为KBL平滑参数λ=0.1;KM目标领域知识阈值σ=2,源领域知识阈值γ=2。LNB-att参数设置与LNB相同,SVM、LLV参数按LNB原论文设置。
3新任务评估
将数据集中21个任务依次作为当前任务,其余20个任务作为历史任务。分别计算模型在当前任务测试集上的性能取平均值作为结果。因数据集正负样本数不平衡,所以本文以负类F1值作为主要评价指标。结果见表(2)。
表2新任务评估实验结果
分析实验结果可知:(1)LNB与传统学习方法NB-T、SVM-T对比,负类F1分别提升了XX%、xx%,特别是LNB优于NB-T,说明LNB知识库中的知识能够帮助当前任务的学习,实现前向知识迁移。(2)LNB将历史任务的知识存于知识库中,NB-ST、SVM-T则可以视作保存了全部历史任务训练样本的终身学习方法,LNB比NB-ST和SVM-ST的负类F1分别高0.94%、xx%,说明相比NB-ST、SVM-T基于训练样本重复的终身学习方法LNB更优,特别是LNB优于NB-ST,说明LNB的终身学习架构能够在历史任务中积累和挖掘有用知识。(3)NB-S、SVM-S使用了20个历史任务的训练集做训练,虽然样本数量远大于仅使用当前任务训练集的LNB和NB-T、SVM-T,但NB-S、SVM-S弱于LNB,甚至分别弱于NB-T、SVM-T,说明大量的非本领域的数据并不能帮助提升模型在本领域的性能,论文(Gururangan等,2020;Xia等,2017)的实验也印证了这一点。新任务评估中领域注意力组成的矩阵见图(7),易见领域注意力机制能够度量历史任务知识与当前任务知识间的相关性,LNB-att比LNB的负类F1高0.25%,说明领域注意力机制能够进一步提升模型性能。使本文提出的改进方法LNB-att性能最优。
4旧任务评估
为衡量学习新任务时是否影响模型在旧任务上的表现,提出评价指标BWT(backward Transfer)。假设能接触到任务序列中所有任务,每当学习完一个任务后测试该模型在所有任务测试集上的性能表现,直至任务序列中的T个任务全部学习完成,可以得到一个矩阵R∈R
其中R
在孤立学习方法NB和终身学习方法LLV、LNB、LNB-att上进行实验,BWT结果如图6所示。
LNB的BWT为0.21%,LNB-att为0.312%,大于0说明在学习完新任务后,模型能够利新任务知识改善旧任务性能,具备反向知识迁移能力。同时由于领域注意力机制的加入,LNB-att的反向知识迁移能力强于LNB。作为对比,孤立学习方法NB的BWT为-3.179%,LLV方法BWT为-1.052%,说明二者发生了不同程度的灾难遗忘现象,学习新任务影响了模型在旧任务上的表现。相较于孤立学习方法NB,终身学习方法LLV减轻了灾难遗忘现象,LNB和LNB-att则更进一步,实现了反向知识迁移。
通过新任务评估和旧任务评估两组对比实验可以看到:LNB架构能够实现知识的存储与迁移且前向知识迁移、反向知识迁移能力优于比较方法;本文提出的改进方法在领域注意力机制的作用下,表现全面优于LNB-att。
以上的仅是本发明的优选实施方式,应当指出,对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 基于领域注意力机制的终身朴素贝叶斯文本分类方法
- 基于终生学习的增量式朴素贝叶斯文本分类方法