恶意网址识别方法及装置、存储介质、电子设备
文献发布时间:2023-06-19 11:39:06
技术领域
本公开涉及互联网技术领域,尤其涉及一种恶意网址识别方法与恶意网址识别装置、计算机可读存储介质及电子设备。
背景技术
URL(Uniform Resource Locator,统一资源定位符)是对可以从互联网上得到的资源的位置和访问方法的一种简洁标识,因此是非常重要的信息载体。但是,由于互联网上的资源爆炸式增长,各种类型的资源都充斥在网络上,尤其存在为数不少的宣扬色情和暴力,以及盗窃用户信息的不良网站。为了呈现健康安全的互联网环境,需要对这些不良网站的恶意网址进行识别。
通常采用网址后缀名,或者URL的解析页面进行检测,也可以通过预设的黑名单进行识别,但是这些方式准确度低,且实时性差。
鉴于此,本领域亟需开发一种新的恶意网址识别方法及装置。
需要说明的是,在上述背景技术部分公开的信息仅用于加强对本公开的背景的理解,因此可以包括不构成对本领域普通技术人员已知的现有技术的信息。
发明内容
本公开的目的在于提供一种恶意网址识别方法、恶意网址识别装置、计算机可读存储介质及电子设备,进而至少在一定程度上克服由于相关技术的限制而导致的准确度低和实时性差的问题。
本公开的其他特性和优点将通过下面的详细描述变得显然,或部分地通过本公开的实践而习得。
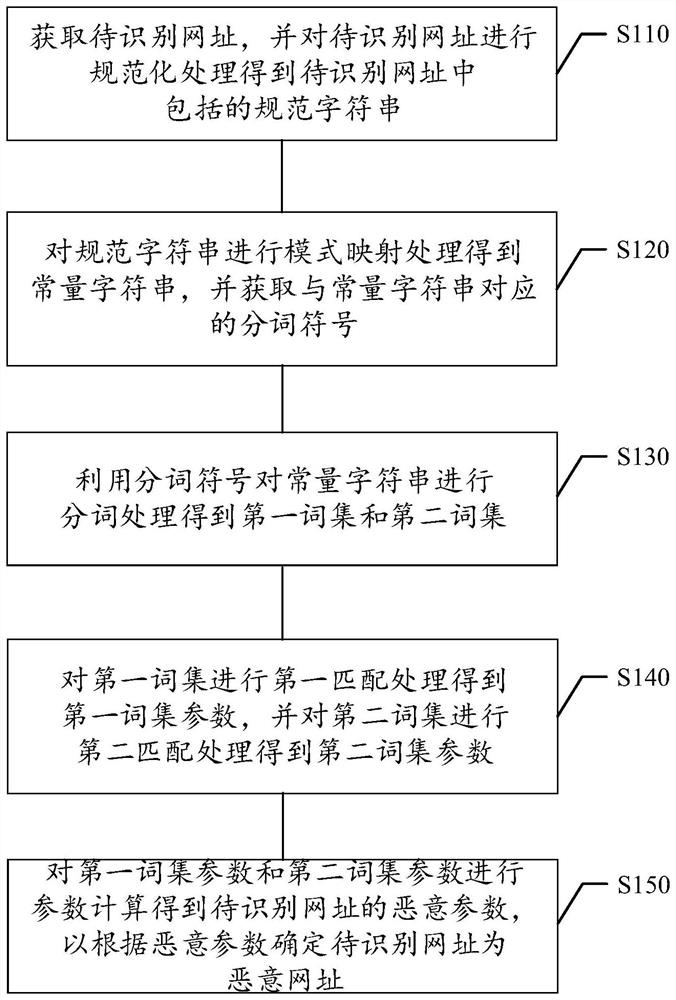
根据本公开的一个方面,提供一种恶意网址识别方法,所述方法包括:获取待识别网址,并对所述待识别网址进行规范化处理得到所述待识别网址中包括的规范字符串;
对所述规范字符串进行模式映射处理得到常量字符串,并获取与所述常量字符串对应的分词符号;
利用所述分词符号对所述常量字符串进行分词处理得到第一词集和第二词集;
对所述第一词集进行第一匹配处理得到第一词集参数,并对所述第二词集进行第二匹配处理得到第二词集参数;
对所述第一词集参数和所述第二词集参数进行参数计算得到所述待识别网址的恶意参数,以根据所述恶意参数确定所述待识别网址为恶意网址。
在本公开的一种示例性实施例中,所述对所述第一词集进行第一匹配处理得到第一词集参数,并对所述第二词集进行第二匹配处理得到第二词集参数,包括:
获取用于识别所述待识别网址的网址样本集合,并确定所述网址样本集合中网址样本的第一样本词集和第二样本词集;
对所述第一词集和所述第一样本词集进行第一匹配处理得到第一词集参数,并对所述第二词集和所述第二样本词集进行第二匹配处理得到第二词集参数。
在本公开的一种示例性实施例中,所述第一词集参数包括第一匹配项数和第一长度参数,第二词集参数包括第二匹配项数和第二长度参数;
所述对所述第一词集和所述第一样本词集进行第一匹配处理得到第一词集参数,并对所述第二词集和所述第二样本词集进行第二匹配处理得到词集参数,包括:
对所述第一词集和所述第一样本词集进行双向匹配处理得到所述第一匹配项数,并对所述第一词集和所述第一样本词集进行长度统计处理得到所述第一长度参数;其中,所述双向匹配处理是对所述第一词集和所述第一样本词集进行从头至尾的匹配处理,并对所述第一词集和所述第一样本词集进行从尾到头的匹配处理的处理过程;
对所述第二词集和所述第二样本词集进行交集计算得到所述第二匹配项数,并对所述第二词集和所述第二样本词集进行长度统计处理得到所述第二长度参数。
在本公开的一种示例性实施例中,所述对所述第一词集参数和所述第二词集参数进行参数计算得到所述待识别网址的恶意参数,包括:
将所述待识别网址与所述网址样本集合中的各个网址样本分别确定相应的多个衰减系数;
根据所述第一匹配项数、所述第二匹配项数、所述第一长度参数、所述第二长度参数以及所述衰减系数计算得到相应的多个待定恶意参数;
对所述多个待定恶意参数进行比较得到参数比较结果,并根据所述参数比较结果在所述多个待定恶意参数中确定所述待识别网址的恶意参数。
在本公开的一种示例性实施例中,所述根据所述待识别网址和所述网址样本中多个网址样本确定多个衰减系数,包括:
获取所述待识别网址的顶级域名和二级域名,并获取所述网址样本集合中各个网址样本的相应的顶级域名样本和相应的二级域名样本;
将所述顶级域名与相应的各个顶级域名样本进行比较得到相应的多个顶级域名比较结果;
将所述二级域名与相应的各个二级域名样本进行比较得到相应的多个二级域名比较结果;
对所述多个顶级域名比较结果和所述多个二级域名比较结果进行汇总处理得到多个汇总比较结果,并根据所述多个汇总比较结果确定相应的多个衰减系数。
在本公开的一种示例性实施例中,所述根据所述恶意参数确定所述待识别网址为恶意网址,包括:
获取与所述恶意参数对应的参数阈值,并将所述恶意参数与所述参数阈值进行比较得到阈值比较结果;
若所述阈值比较结果为所述恶意参数大于所述参数阈值,确定所述待识别网址为恶意网址。
在本公开的一种示例性实施例中,所述对所述规范字符串进行模式映射处理得到常量字符串,包括:
确定所述规范字符串在所述待识别网址中的组成部分,并获取与所述组成部分对应的格式规则;
若所述规范字符串满足所述格式规则,对所述规范字符串进行模式映射处理得到常量字符串。
在本公开的一种示例性实施例中,所述对所述规范字符串进行模式映射处理得到常量字符串,包括:
确定所述规范字符串在所述待识别网址中的组成部分,并获取与所述组成部分对应的多个格式规则以及与所述多个格式规则对应的规则优先级;
按照所述规则优先级在所述多个格式规则中确定一目标格式规则,并按照所述目标格式规则对所述规范字符串进行映射处理得到常量字符串。
在本公开的一种示例性实施例中,所述按照所述目标格式规则对所述规范字符串进行映射处理得到常量字符串,包括:
若所述规范字符串满足所述目标格式规则,对所述规范字符串进行模式映射处理得到常量字符串;
若所述规范字符串未满足所述目标格式规则,按照所述规则优先级在所述多个格式规则中确定所述目标格式规则的下一格式规则,并按照所述下一格式规则对所述规范字符串进行映射处理得到常量字符串。
在本公开的一种示例性实施例中,所述对所述待识别网址进行规范化处理得到所述待识别网址中包括的规范字符串,包括:
对所述待识别网址进行字体转换处理得到字体转换网址;
对所述字体转换网址进行字符填充处理得到完整字符网址;
对所述完整字符网址进行字符去除处理得到待识别网址中包括的规范字符串。
在本公开的一种示例性实施例中,所述方法还包括:
获取用于识别所述待识别网址的正常网址规则;
利用所述正常网址规则对所述待识别网址进行规则过滤处理,以确定所述待识别网址为正常网址。
在本公开的一种示例性实施例中,所述正常网址规则包括网址模板规则、域名规则和高频词规则,
所述利用所述正常网址规则对所述待识别网址进行规则过滤处理,以确定所述待识别网址为正常网址,包括:
当所述待识别网址符合所述网址模板规则时,确定所述待识别网址为正常网址;
当所述待识别网址中的网址域名符合所述域名规则时,确定所述待识别网址为正常网址;
当所述待识别网址中存在所述高频词规则包括的高频词时,利用所述高频词查询所述待识别网址,以确定所述待识别网址为正常网址。
在本公开的一种示例性实施例中,所述方法还包括:
在与所述恶意网址对应的虚拟系统程序中运行所述恶意网址得到运行结果;
若所述运行结果为所述恶意网址存在恶意信息,将所述恶意网址存储至恶意网址数据集。
在本公开的一种示例性实施例中,所述方法还包括:
统计所述恶意网址数据集中的恶意网址的存储时长,并确定所述恶意网址数据集中的恶意网址的样本使用情况;所述样本使用情况表征所述恶意网址数据集中的恶意网址是否已作为用于识别所述待识别网址的网址样本进行使用;
根据所述存储时长和所述样本使用情况对所述恶意网址数据集中的恶意网址进行剔除处理,以对所述恶意网址数据集进行更新。
在本公开的一种示例性实施例中,所述方法还包括:
对所述恶意网址进行标注验证处理得到验证结果;
若所述验证结果为所述恶意网址为误判,对用于识别所述待识别网址的网址样本进行更新;
若所述验证结果为所述恶意网址为误判,对用于识别所述待识别网址的正常网址规则进行更新。
在本公开的一种示例性实施例中,所述方法还包括:
若邮件中包含所述恶意网址,对所述邮件进行拦截处理
根据本公开的一个方面,提供一种恶意网址识别装置,所述装置包括:规范处理模块,被配置为获取待识别网址,并对所述待识别网址进行规范化处理得到所述待识别网址中包括的规范字符串;
映射处理模块,被配置为对所述规范字符串进行模式映射处理得到常量字符串,并获取与所述常量字符串对应的分词符号;
分词处理模块,被配置为利用所述分词符号对所述常量字符串进行分词处理得到第一词集和第二词集;
匹配处理模块,被配置为对所述第一词集进行第一匹配处理得到第一词集参数,并对所述第二词集进行第二匹配处理得到第二词集参数;
网址识别模块,被配置为对所述第一词集参数和所述第二词集参数进行参数计算得到所述待识别网址的恶意参数,以根据所述恶意参数确定所述待识别网址为恶意网址。
在本公开的一种示例性实施例中,基于以上技术方案,所述匹配处理模块,包括:
样本集合子模块,被配置为获取用于识别所述待识别网址的网址样本集合,并确定所述网址样本集合中网址样本的第一样本词集和第二样本词集;
分别匹配子模块,被配置为对所述第一词集和所述第一样本词集进行第一匹配处理得到第一词集参数,并对所述第二词集和所述第二样本词集进行第二匹配处理得到第二词集参数。
在本公开的一种示例性实施例中,基于以上技术方案,所述第一词集参数包括第一匹配项数和第一长度参数,第二词集参数包括第二匹配项数和第二长度参数;
所述分别匹配子模块,包括:
第一匹配单元,被配置为对所述第一词集和所述第一样本词集进行双向匹配处理得到所述第一匹配项数,并对所述第一词集和所述第一样本词集进行长度统计处理得到所述第一长度参数;其中,所述双向匹配处理是对所述第一词集和所述第一样本词集进行从头至尾的匹配处理,并对所述第一词集和所述第一样本词集进行从尾到头的匹配处理的处理过程;
第二匹配单元,被配置为对所述第二词集和所述第二样本词集进行交集计算得到所述第二匹配项数,并对所述第二词集和所述第二样本词集进行长度统计处理得到所述第二长度参数。
在本公开的一种示例性实施例中,基于以上技术方案,所述网址识别模块,包括:
系数确定子模块,被配置为将所述待识别网址与所述网址样本集合中的各个网址样本分别确定相应的多个衰减系数;
参数计算子模块,被配置为根据所述第一匹配项数、所述第二匹配项数、所述第一长度参数、所述第二长度参数以及所述衰减系数计算得到相应的多个待定恶意参数;
参数比较子模块,被配置为对所述多个待定恶意参数进行比较得到参数比较结果,并根据所述参数比较结果在所述多个待定恶意参数中确定所述待识别网址的恶意参数。
在本公开的一种示例性实施例中,基于以上技术方案,所述系数确定子模块,包括:
域名样本单元,被配置为获取所述待识别网址的顶级域名和二级域名,并获取所述网址样本集合中各个网址样本的相应的顶级域名样本和相应的二级域名样本;
顶级域名单元,被配置为将所述顶级域名与相应的各个顶级域名样本进行比较得到相应的多个顶级域名比较结果;
二级域名单元,被配置为将所述二级域名与相应的各个二级域名样本进行比较得到相应的多个二级域名比较结果;
结果汇总单元,被配置为对所述多个顶级域名比较结果和所述多个二级域名比较结果进行汇总处理得到多个汇总比较结果,并根据所述多个汇总比较结果确定相应的多个衰减系数。
在本公开的一种示例性实施例中,基于以上技术方案,所述网址识别模块,包括:
阈值比较子模块,被配置为获取与所述恶意参数对应的参数阈值,并将所述恶意参数与所述参数阈值进行比较得到阈值比较结果;
网址确定子模块,被配置为若所述阈值比较结果为所述恶意参数大于所述参数阈值,确定所述待识别网址为恶意网址。
在本公开的一种示例性实施例中,基于以上技术方案,所述映射处理模块,包括:
规则获取子模块,被配置为确定所述规范字符串在所述待识别网址中的组成部分,并获取与所述组成部分对应的格式规则;
规则满足子模块,被配置为若所述规范字符串满足所述格式规则,对所述规范字符串进行模式映射处理得到常量字符串。
在本公开的一种示例性实施例中,基于以上技术方案,所述映射处理模块,包括:
部分信息子模块,被配置为确定所述规范字符串在所述待识别网址中的组成部分,并获取与所述组成部分对应的多个格式规则以及与所述多个格式规则对应的规则优先级;
目标确定子模块,被配置为按照所述规则优先级在所述多个格式规则中确定一目标格式规则,并按照所述目标格式规则对所述规范字符串进行模式映射处理得到常量字符串。
在本公开的一种示例性实施例中,基于以上技术方案,所述目标确定子模块,包括:
第一结果单元,被配置为若所述规范字符串满足所述目标格式规则,对所述规范字符串进行模式映射处理得到常量字符串;
第二结果单元,被配置为若所述规范字符串未满足所述目标格式规则,按照所述规则优先级在所述多个格式规则中确定所述目标格式规则的下一格式规则,并按照所述下一格式规则对所述规范字符串进行模式映射处理得到常量字符串。
在本公开的一种示例性实施例中,基于以上技术方案,所述规范处理模块,包括:
转换处理子模块,被配置为对所述待识别网址进行字体转换处理得到字体转换网址;
字符填充子模块,被配置为对所述字体转换网址进行字符填充处理得到完整字符网址;
字符去除子模块,被配置为对所述完整字符网址进行字符去除处理得到待识别网址中包括的规范字符串。
在本公开的一种示例性实施例中,基于以上技术方案,所述恶意网址识别装置,还包括:
规则获取模块,被配置为获取用于识别所述待识别网址的正常网址规则;
规则过滤模块,被配置为利用所述正常网址规则对所述待识别网址进行规则过滤处理,以确定所述待识别网址为正常网址。
在本公开的一种示例性实施例中,基于以上技术方案,所述正常网址规则包括网址模板规则、域名规则和高频词规则,
所述规则过滤模块,包括:
模板规则子模块,被配置为当所述待识别网址符合所述网址模板规则时,确定所述待识别网址为正常网址;
域名规则子模块,被配置为当所述待识别网址中的网址域名符合所述域名规则时,确定所述待识别网址为正常网址;
高频词规则子模块,被配置为当所述待识别网址中存在所述高频词规则包括的高频词时,利用所述高频词查询所述待识别网址,以确定所述待识别网址为正常网址。
在本公开的一种示例性实施例中,基于以上技术方案,所述恶意网址识别装置,还包括:
程序运行模块,被配置为在与所述恶意网址对应的虚拟系统程序中运行所述恶意网址得到运行结果;
数据生成模块,被配置为若所述运行结果为所述恶意网址存在恶意信息,将所述恶意网址存储至恶意网址数据集。
在本公开的一种示例性实施例中,基于以上技术方案,所述恶意网址识别装置,还包括:
情况确定模块,被配置为统计所述恶意网址数据集中的恶意网址的存储时长,并确定所述恶意网址数据集中的恶意网址的样本使用情况;所述样本使用情况表征所述恶意网址数据集中的恶意网址是否已作为用于识别所述待识别网址的网址样本进行使用;
数据更新模块,被配置为根据所述存储时长和所述样本使用情况对所述恶意网址数据集中的恶意网址进行剔除处理,以对所述恶意网址数据集进行更新。
在本公开的一种示例性实施例中,基于以上技术方案,所述恶意网址识别装置,还包括:
标注验证模块,被配置为对所述恶意网址进行标注验证处理得到验证结果;
样本更新模块,被配置为若所述验证结果为所述恶意网址为误判,对用于识别所述待识别网址的网址样本进行更新;
规则更新模块,被配置为若所述验证结果为所述恶意网址为误判,对用于识别所述待识别网址的正常网址规则进行更新。
在本公开的一种示例性实施例中,所述恶意网址识别装置,还包括:
邮件拦截模块,被配置为若邮件中包含所述恶意网址,对所述邮件进行拦截处理。
根据本公开的一个方面,提供一种电子设备,包括:处理器和存储器;其中,存储器上存储有计算机可读指令,所述计算机可读指令被所述处理器执行时实现上述任意示例性实施例的恶意网址识别方法。
根据本公开的一个方面,提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任意示例性实施例中的恶意网址识别方法。
由上述技术方案可知,本公开示例性实施例中的恶意网址识别方法、恶意网址识别装置、计算机存储介质及电子设备至少具备以下优点和积极效果:
在本公开的示例性实施例提供的方法及装置中,本公开一方面,对待识别网址进行规范化处理,能够提取出待识别网址中的关键信息,降低无关信息对恶意网址识别的干扰,提升恶意网址识别的准确度;另一方面,对规范字符串进行模式映射处理,将有规律性的规范字符串转化成常量字符串,使得对第一匹配处理和第二匹配处理的结果进行参数计算时,相比于相关技术中对原本的规范字符串进行计算的方式而言,显然能够更加快速的得到用于识别恶意网址的恶意参数,保证了对恶意网址识别的速度,并进一步对恶意邮件进行有效拦截。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理。显而易见地,下面描述中的附图仅仅是本公开的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1示意性示出本公开示例性实施例中一种恶意网址识别方法的流程示意图;
图2示意性示出本公开示例性实施例中规范化处理的方法的流程示意图;
图3示意性示出本公开示例性实施例中一种模式映射处理的方法的流程示意图;
图4示意性示出本公开示例性实施例中另一种模式映射处理的方法的流程示意图;
图5示意性示出本公开示例性实施例中进一步进行模式映射处理的方法的流程示意图;
图6示意性示出本公开示例性实施例中规则过滤处理的方法的流程示意图;
图7示意性示出本公开示例性实施例中进一步进行规则过滤处理的方法的流程示意图;
图8示意性示出本公开示例性实施例中第一匹配处理和第二匹配处理的方法的流程示意图;
图9示意性示出本公开示例性实施例中进一步进行第一匹配处理和第二匹配处理的方法的流程示意图;
图10示意性示出本公开示例性实施例中参数计算的方法的流程示意图;
图11示意性示出本公开示例性实施例中确定衰减系数的方法的流程示意图;
图12示意性示出本公开示例性实施例中确定恶意网址的方法的流程示意图;
图13示意性示出本公开示例性实施例中生成恶意网址数据集的方法的流程示意图;
图14示意性示出本公开示例性实施例中更新恶意网址数据集的方法的流程示意图;
图15示意性示出本公开示例性实施例中标注验证处理的方法的流程示意图;
图16示意性示出本公开示例性实施例中应用场景下恶意网址识别方法的流程示意图;
图17示意性示出本公开示例性实施例中应用场景下规范化处理的流程示意图;
图18示意性示出本公开示例性实施例中应用场景下更新网址样本集合的方法的流程示意图;
图19示意性示出本公开示例性实施例中应用场景下标注验证处理的方法的流程示意图;
图20示意性示出本公开示例性实施例中一种恶意网址识别装置的结构示意图;
图21示意性示出本公开示例性实施例中一种用于实现恶意网址识别方法的电子设备;
图22示意性示出本公开示例性实施例中一种用于实现恶意网址识别方法的计算机可读存储介质。
具体实施方式
下面将参考若干示例性实施方式来描述本公开的原理和精神。应当理解,给出这些实施方式仅仅是为了使本领域技术人员能够更好地理解进而实现本公开,而并非以任何方式限制本公开的范围。相反,提供这些实施方式是为了使本公开更加透彻和完整,并且能够将本公开的范围完整地传达给本领域的技术人员。
本领域技术人员知道,本公开的实施方式可以实现为一种系统、装置、设备、方法或计算机程序产品。因此,本公开可以具体实现为以下形式,即:完全的硬件、完全的软件(包括固件、驻留软件、微代码等),或者硬件和软件结合的形式。
根据本公开的实施方式,提出了一种恶意网址识别方法、介质、装置和电子设备。
此外,附图中的任何元素数量均用于示例而非限制,以及任何命名都仅用于区分,而不具有任何限制含义。
下面参考本公开的若干代表性实施方式,详细阐释本公开的原理和精神。
本发明人发现,在相关技术中,URL是非常重要的信息载体,尤其是邮件中。一般正常的邮件行为,内容和URL等信息是良好一致的,而恶意的邮件的内容可能具有较强的隐蔽性和矛盾性。如内容体是通知类的内容,而URL却是被篡改的钓鱼URL。
其中,URL指的是文件在网上的地址,通俗说就是网址。由三部分组成,分别是协议方式、存放资源的主机域名、资源文件名。最常见的是通过浏览器访问的URL,比如http://www.163.com。如果要访问app中的地址,则必须使用app的协议,比如协议名为“appABC”时,URL就需要以“appABC://”开头。
首先,相关技术中提供了一种利用路由器进行恶意网址提示的方法。
首先,通过路由器获取用户终端访问的网络访问请求中的目标网址。然后,该路由器确定目标网址是否属于恶意网址,具体的检测方式为路由器基于检测目标网址中的域名和/或目标网址包含的文件名的扩展名确定目标网址是否属于潜在恶意网址。若路由器确定目标网址属于潜在恶意网址,则将目标网址与预设的恶意网址数据库中的参考网址进行匹配,该参考网址属于恶意网址。若恶意网址数据库中存在与目标网址相匹配的参考网址,则路由器判定目标网址属于恶意网址,向用户终端发送拦截目标网址的提示信息。
其中,路由器基于目标网址中的域名确定目标网址是否属于潜在恶意网址时,可以将目标网址中的域名与域名白名单中的域名进行匹配实现。因此,该方案比较局限在现有数据库的黑白名单,是比较笼统的通用型方法,在识别上有局限性,且缺少动态更新方案的细分说明。
并且,该技术提供的潜在恶意网址的确定过程中还涉及文本相似、图片检测等技术,而这些技术方案都需要路由器对页面内容进行识别。因此,该方案的响应速度慢,漏判率高,不适合对响应要求高的在线识别场景。
然后,相关技术中还提供了一种违禁网址识别方法。通过提取留言内容中的网址,可以请求并解析网址中的网络页面信息,并获取待检测信息。进一步的,根据违禁识别模型对待检测信息进行分类。若待检测信息的分类存在至少一种违禁分类,对待检测信息对应的网址进行违禁标记,并对含有违禁标记的网址进行掩码或封禁处理。
这种方法主要侧重在获取URL的解析页面后进行违禁信息检测。虽然获取实际的页面信息能提高判断识别的内容准确度,但也有不少弊端。
其一,由于黑产攻击方式会将实际的页面层层重定向,有些会使用JavaScript判断用户环境重定向到不同的页面,所以不能100%的保证获取到的URL的解析页面与用户实际的打开的页面相同。
其二,恶意URL的判断时效性要求高,完全依赖于页面解析内容会在前期造成比较高的漏判率。
最后,相关技术中还提供了一种通过相似度识别恶意网址的方法。
具体的,对于不能被URL匹配黑名单命中的第一URL,可以通过该URL解析页面中的第二URL、文本信息、图像信息、视频信息分别计算URL相似度、本文相似度、图像相似度、视频各帧图像的相似度进行辅助。进而,获取最大相似度确定作为该URL的相似度,以降低漏判。
该方法阐述的识别方式要通过比较文本、图像、视频相似度,由于与前两种方法有一样的漏判性高、响应性低的缺陷,所以不再赘述。
更为重要的是,这并不是完整的URL相似度计算方案,缺少系统性的计算和更新方式。
因此,本公开的实施例提供了一种恶意网址识别方法,包括:获取待识别网址,并对待识别网址进行规范化处理得到待识别网址中包括的规范字符串;对规范字符串进行模式映射处理得到常量字符串,并获取与所述常量字符串对应的分词符号;利用所述分词符号对所述常量字符串进行分词处理得到第一词集和第二词集;对所述第一词集进行第一匹配处理得到第一词集参数,并对所述第二词集进行第二匹配处理得到第二词集参数;对所述第一词集参数和所述第二词集参数进行参数计算得到所述待识别网址的恶意参数,以根据所述恶意参数确定所述待识别网址为恶意网址。
可见,本公开实施例一方面,对待识别网址进行规范化处理,能够提取出待识别网址中的关键信息,降低无关信息对恶意网址识别的干扰,提升恶意网址识别的准确度;另一方面,对规范字符串进行模式映射处理,将有规律性的规范字符串转化成常量字符串,使得对第一匹配处理和第二匹配处理的结果进行参数计算时,相比于相关技术中对原本的规范字符串进行计算的方式而言,显然能够更加快速的得到用于识别恶意网址的恶意参数,保证了对恶意网址识别的速度,并进一步对恶意邮件进行有效拦截。
在介绍了本公开的基本原理之后,下面具体介绍本公开的各种非限制性实施方式。
需要注意的是,下述应用场景仅是为了便于理解本公开的精神和原理而示出,本公开的实施方式在此方面不受任何限制。相反,本公开的实施方式可以适用于适用的任何场景。
本公开实施例通过终端能够对邮件中提取的待识别网址进行规范化处理,以将各种变形的待识别网址固定的一种固定的规范字符串。然后,终端对规范字符串进行模式映射处理得到常量字符串,并获取与常量字符串对应的分词符号。进而,终端利用分词符号对常量字符串进行分词处理得到第一词集和第二词集,并对第一词集进行第一匹配处理得到第一词集参数,对第二词集进行第二匹配处理得到第二词集参数。最后,终端对第一词集参数和第二词集参数进行参数计算得到用于识别恶意网址的恶意参数,并根据恶意参数确定待识别网址为恶意网址。
值得说明的是,本公开实施例可以应用于终端,也可以应用于服务器端,本公开对此不做特殊限定。
显然,将有规律的规范字符串归一到特定的常量字符串,能够最大程度的降低对映射恶意参数的计算结果的影响。而进行参数计算得到用于识别恶意网址的恶意参数,保证了恶意网址识别的时效性,并进一步对恶意邮件进行有效拦截。
下面结合上述的应用场景,参考图1-图19来描述本公开实施方式的恶意网址识别方法。
本公开提出了一种恶意网址识别方法。图1示出了恶意网址识别方法的流程示意图,如图1所示,恶意网址识别方法至少包括以下步骤:
步骤S110.获取待识别网址,并对待识别网址进行规范化处理得到待识别网址中包括的规范字符串。
步骤S120.对规范字符串进行模式映射处理得到常量字符串,并获取与常量字符串对应的分词符号。
步骤S130.利用分词符号对常量字符串进行分词处理得到第一词集和第二词集。
步骤S140.对第一词集进行第一匹配处理得到第一词集参数,并对第二词集进行第二匹配处理得到第二词集参数。
步骤S150.对第一词集参数和第二词集参数进行参数计算得到待识别网址的恶意参数,以根据恶意参数确定待识别网址为恶意网址。
在本公开的示例性实施例中,本公开一方面,对待识别网址进行规范化处理,能够提取出待识别网址中的关键信息,降低无关信息对恶意网址识别的干扰,提升恶意网址识别的准确度;另一方面,对规范字符串进行模式映射处理,将有规律性的规范字符串转化成常量字符串,使得对第一匹配处理和第二匹配处理的结果进行参数计算时,相比于相关技术中对原本的规范字符串进行计算的方式而言,显然能够更加快速的得到用于识别恶意网址的恶意参数,保证了恶意网址识别的速度,并进一步对恶意邮件进行有效拦截。
下面对恶意网址识别方法的各个步骤进行详细说明。
在步骤S110中,获取待识别网址,并对待识别网址进行规范化处理得到待识别网址中包括的规范字符串。
在本公开的示例性实施例中,该待识别网址可以是待识别是否为恶意网址的未知网址,并且该待识别网址可以是从邮件中提取得到的。例如,待识别网址可以利用jsoup从邮件中提取得到。
其中,jsoup是一款Java的HTML(HyperText Markup Language,超文本标记语言)解析器,可以解析某个URL(Uniform Resource Locator,统一资源定位器)地址和HTML文本内容。它提供了一套非常省力的API(Application Programming Interface,应用程序接口),可通过DOM、CSS以及其他类似于jQuery的操作方法来提取和使用数据。
通过jsoup.parse(String html)方法对http client获取到的html内容进行解析来得到待识别网址。
并且,为了从待识别网址中得到对应的规范字符串,还可以辅助以通过图2所示的方式对待识别网址进行过滤。
因此,在得到待识别网址之后,还可以进一步对待识别网址进行规范化处理。
在可选的实施例中,图2示出了规范化处理的方法的流程示意图,如图2所示,该方法至少包括以下步骤:在步骤S210中,对待识别网址进行字体转换处理得到字体转换网址。
具体的,对待识别网址进行的字体转换处理可以是通过已构建的字典库实现的。在该字典库中存储有繁体字与简体字之间的对应关系。因此,在确定待识别网址中包含的繁体字之后,可以利用该字典库查询与该繁体字具有对应关系的简体字,以将该繁体字转换为对应的简体字得到字体转换网址。
在步骤S220中,对字体转换网址进行字符填充处理得到完整字符网址。
由于完整的待识别网址的格式为protocol://user@host:port/path?query#fragment,因此可以将字体转换网址与该格式进行匹配以自动填充缺少的字符。
举例而言,当字体转换网址为canmple34.domin.net?username@userdomain.com时,可以对该字体转换网址进行字符填充得到canmple34.domin.net/?username@userdomain.com的完整字符网址。
在步骤S230中,对完整字符网址进行字符去除处理得到待识别网址中包括的规范字符串。
在得到完整字符网址之后,还可以去除完整字符网址中对于恶意网址识别无影响的信息,亦即对完整字符网址进行字符去除处理得到待识别网址中包括的规范字符串。
具体的,该字符去除处理可以包括http和https协议这部分信息,还包括user信息、www主机信息、无意义的后缀符和URL路径中连续出现的多个“/”。
其中,由于http和https协议对于正常网址和恶意网址的共有性比例太大,因此可以进行字符去除处理。
而user信息的位置不同并不会改变待识别网址的显示,但会对后续恶意网址识别的准确度造成影响,因此可以去除user信息。
www主机名同样因为区分度不大,并且在字符填充处理过程中可以自动填充上,因此也可以去除。
无意义的后缀符在去除时包含但不限于“/”、“.”和“&”等。
而在URL中,除了前面的http://中有两个“/”之外,后面在分段的时候多个“/”的效果等同于一个“/”,因此可以将URL路径中连续出现的多个“/”进行去重处理,以去除掉多余的“/”字符。
在经过多种方式的字符去除处理之后,待识别网址中剩余的规范字符串包括四种,分别是host、path、query和fragment。
在本示例性实施例中,通过对待识别网址进行规范化处理得到规范字符串,能够将待识别网址统一成固定的字符串内容,保留了待识别网址中的关键信息,保障了恶意网址的识别准确性。
在步骤S120中,对规范字符串进行模式映射处理得到常量字符串,并获取与常量字符串对应的分词符号。
在本公开的示例性实施例中,在得到规范字符串之后,可以对规范字符串进行模式映射处理得到常量字符串。
在可选的实施例中,图3示出了一种模式映射处理的方法的流程示意图,如图3所示,该方法至少包括以下步骤:在步骤S310中,确定规范字符串在待识别网址中的组成部分,并获取与组成部分对应的格式规则。
举例而言,组成部分组成部分当该组成部分为host时,对应的格式规则可以是该组成部分要满足例如127.0.0.1这种样式的规则。
在步骤S320中,若规范字符串满足格式规则,对规范字符串进行模式映射处理得到常量字符串。
举例而言,当规范字符串host也为127.0.0.1时,确定该规范字符串满足对应的格式规则,可以将该规范字符串映射为IP这样的固定字符串,并作为常量字符串。
在本示例性实施例中,通过对规范字符串进行模式映射处理,可以实现多样化的规范字符串映射为具有规律性的常量字符串的目的,为后续恶意网址识别提供了数据基础。
在可选的实施例中,图4示出了另一种模式映射处理的方法的流程示意图,如图4所示,该方法至少包括以下步骤:在步骤S410中,确定规范字符串在待识别网址中的组成部分,并获取与组成部分对应的多个格式规则以及与多个格式规则对应的规则优先级。
举例而言,当组成部分为path时,可以获取到多个对应的格式规则,分别是example@163.com、ZXhhbXBsZUAxNjMuY29t和Dfdhjhjy5yugusb3jhdfhjhjhjei。
并且,其中example@163.com的优先级最高,接下来较高优先级的是ZXhhbXBsZUAxNjMuY29t,最后优先级最低的是Dfdhjhjy5yugusb3jhdfhjhjhjei。
在步骤S420中,按照规则优先级在多个格式规则中确定一目标格式规则,并按照目标格式规则对规范字符串进行模式映射处理得到常量字符串。
在已知example@163.com的优先级最高,接下来较高优先级的是ZXhhbXBsZUAxNjMuY29t,最后优先级最低的是Dfdhjhjy5yugusb3jhdfhjhjhjei的情况下,可以首先选择example@163.com为目标格式规则,以进一步进行模式映射处理。
在可选的实施例中,图5示出了进一步进行模式映射处理的方法的流程示意图,如图5所示,在步骤S510中,若规范字符串满足目标格式规则,对规范字符串进行模式映射处理得到常量字符串。
在确定example@163.com为目标格式规则的情况下,若规范字符串path满足该目标格式规则,可以将规范字符串path映射为EMAIL,即常量字符串。
在步骤S520中,若规范字符串未满足目标格式规则,按照规则优先级在多个格式规则中确定目标格式规则的下一格式规则,并按照下一格式规则对规范字符串进行模式映射处理得到常量字符串。
在确定example@163.com为目标格式规则的情况下,若规范字符串path不满足该目标格式规则,可以按照规则优先级继续确定ZXhhbXBsZUAxNjMuY29t为目标格式规则;当规范字符串path满足该目标格式规则时,可以将该规范字符串path转换为BASE64MAIL;而当规范字符串path不满足该目标格式规则时,可以继续按照规则优先级选择ZXhhbXBsZUAxNjMuY29t的下一格式规则进行模式映射处理。
在本示例性实施例中,通过对多个格式规则进行模式映射处理,可以确定在这种情况下的常量字符串,为后续恶意网址识别提供了数据基础,并丰富了模式映射处理的方案完整性和应用场景。
在得到常量字符串之后,为了对该常量字符串进行分词处理,可以获取对应的分词符号。具体的,该分词符号可以包括"!","#","$","&","*","+",",","-",".","/",":",";","<","=",">","?","@","_","`","{","}","|","~","[","]","(",")"。
在步骤S130中,利用分词符号对常量字符串进行分词处理得到第一词集和第二词集。
在本公开的示例性实施例中,得到常量字符串和分词符号之后,可以利用该分词符号对常量字符串进行分词处理得到第一词集和第二词集。
但是在分词处理之后,为减少后续的工作量和网址误判,可以将确定为正常网址的待识别网址进行过滤。
在可选的实施例中,图6示出了规则过滤处理的方法的流程示意图,如图6所示,该方法至少包括以下步骤:在步骤S610中,获取用于识别待识别网址的正常网址规则。
其中,正常网址规则包括网址模板规则、域名规则和高频词规则。
在步骤S620中,利用正常网址规则对待识别网址进行规则过滤处理,以确定待识别网址为正常网址。
在可选的实施例中,正常网址规则包括网址模板规则、域名规则和高频词规则,图7示出了进一步进行规则过滤处理的方法的流程示意图,如图7所示,该方法至少包括以下步骤:在步骤S710中,当待识别网址符合网址模板规则时,确定待识别网址为正常网址。
该网址模板规则是一些具有固定模板的论坛或者网站生成网址的规则。而当该待识别网址符合对应的网址模板规则时,可以确定该待识别网址是正常网址。
在步骤S720中,当待识别网址中的网址域名符合域名规则时,确定待识别网址为正常网址。
该域名规则可以是根据大型的互联网公司的域名,或者是权威机构组织的域名、政府网站的域名,还可以是大型公司的官网的域名等可信赖的域名生成的规则。而当待识别网址的网址域名为对应域名时,表明该待识别网址为互联网公司的网址,即正常网址。
在步骤S730中,当待识别网址中存在高频词规则包括的高频词时,利用高频词查询待识别网址,以确定待识别网址为正常网址。
该高频词规则是依据例如user等在网址中经常出现的高频词生成的规则。具体的,当待识别的网址中出现高频词规则中包括的高频词时,能够利用该高频词在已建立好的可靠网址集合中对该待识别网址进行查询。当能够以高频词为key在可靠网址集合中查询到待识别网址时,表明该待识别网址为正常网址。
而在确定待识别网址为正常网址的情况下,无需进行后续的恶意网址识别步骤。但是,在无法确定待识别网址为正常网址时,则不能通过图7所示的规则过滤处理对待识别网址进行过滤,而需要利用分词符号对常量字符串进行分词处理得到第一词集和第二词集,然后再继续进行后续的恶意网址识别步骤。
该第一词集可以是常量字符串中包括的分词符的词集,用s
在步骤S140中,对第一词集进行第一匹配处理得到第一词集参数,并对第二词集进行第二匹配处理得到第二词集参数。
在本公开的示例性实施例中,在得到第一词集和第二词集之后,可以对第一词集进行第一匹配处理,并对第二词集进行第二匹配处理。
在可选的实施例中,图8示出了第一匹配处理和第二匹配处理的方法的流程示意图,如图8所示,该方法至少包括以下步骤:在步骤S810中,获取用于识别待识别网址的网址样本集合,并确定网址样本集合中网址样本的第一样本词集和第二样本词集。
在获取到网址样本集合之后,可以分别获取网址样本集合中包括的各个网址样本对应的第一样本词集和第二样本词集。其中,通过分词符对网址样本进行分词处理后,分别得到对应的第一样本词集和第二样本词集。其中,第一样本词集用s
在步骤S820中,对第一词集和第一样本词集进行第一匹配处理得到第一词集参数,并对第二词集和第二样本词集进行第二匹配处理得到第二词集参数。
第一词集参数包括第一匹配项数和第一长度参数,第二词集参数包括第二项数和第二长度参数,图9示出了进一步进行第一匹配处理和第二匹配处理的方法的流程示意图,如图9所示,该方法至少包括以下步骤:在步骤S910中,对第一词集和第一样本词集进行双向匹配处理得到第一匹配项数,并对第一词集和第一样本词集进行长度统计处理得到第一长度参数。其中,双向匹配处理是对第一词集和第一样本词集进行从头至尾的匹配处理,并对第一词集和第一样本词集进行从尾到头的匹配处理的处理过程。
具体的,对第一词集和第一样本词集按照位置顺序从头到尾进行一次匹配,再从尾到头进行一次匹配,将两次匹配得到的最大相同个数作为第一匹配项数。
举例而言,当第一词集为“!#+&”,且第一样本词集为“!#&”时,对第一词集和第一样本词集进行双向匹配处理可以是按照第一词集与第一样本词集从左至右,即从头到尾的顺序匹配一次,得到匹配的字符为“!#”,即字符个数为2,再按照第一词集与第一样本词集从右至左,即从尾到头的顺序匹配一次,得到匹配的字符为“&”,即字符个数为1。因此,将字符个数2和1进行比较,选择最大的相同个数2作为此时的第一匹配项数。
然后,将第一词集和第一样本词集的字符长度进行比较和统计,将更加长的一个字符长度统计为第一长度参数。
举例而言,当第一词集为“!#+&”,且第一样本词集为“!#&”时,第一词集的字符长度为4,第一样本词集的字符长度为3,对两个字符长度进行比较,将更加长的第一词集的字符长度4作为此时的第一长度参数。
该双向匹配处理和长度统计处理均是以一个待识别网址的第一词集与一个网址样本的第一样本词集为单位处理的,可以得到该待识别网址与该网址样本的第一匹配项数和第一长度参数,而该待识别网址与网址样本集合中的其他网址样本的双向匹配处理与长度统计处理也可以同样执行,以得到对应的第一匹配项数和第一长度参数。
在步骤S920中,对第二词集和第二样本词集进行交集计算处理得到第二匹配项数,并对第二词集和第二样本词集进行长度统计处理得到第二长度参数。
具体的,对第二词集和第二样本词集进行求交集计算,得到二者之间包含的相同字符的个数作为第二匹配项数。
其中,数学上,用两个集合A和B的交集表征含有所有既属于A,又属于B的元素,而没有其他元素的集合,可以写作A∪B。
举例而言,当第二词集为“123c”,且第二样本词集为“123d”时,对第二词集和第二样本词集进行交集计算处理得到二者相匹配的字符串为“123”,因此第二匹配项数为3。
然后,将第二词集和第二样本词集之间的字符长度进行比较,并统计最长的字符长度作为第二长度参数。
举例而言,当第二词集为“123c”,且第二样本词集为“123de”时,对第二词集和第二样本词集进行长度统计处理得到第二词集的字符长度为4,第二样本词集的字符长度为5,因此选择更长的字符长度5作为此时的第二长度参数。
该交集计算处理和长度统计处理均是以一个待识别网址的第二词集与一个网址样本的第二样本词集为单位处理的,可以得到该待识别网址与该网址样本的第二匹配项数和第二长度参数,而该待识别网址与网址样本集合中的其他网址样本的交集计算处理与长度统计处理也可以同样执行,以得到对应的第二匹配项数和第二长度参数。
在本示例性实施例中,对第一词集和第二词集分别进行匹配处理可以得到对应的词集参数,为后续通过计算确定恶意网址提供了数据基础。
在步骤S150中,对第一词集参数和第二词集参数进行参数计算得到待识别网址的恶意参数,以根据恶意参数确定待识别网址为恶意网址。
在本公开的示例性实施例中,得到第一词集参数和第二词集参数之后,可以进行参数计算确定恶意参数。
在可选的实施例中,图10示出了参数计算的方法的流程示意图,如图10所示,该方法至少包括以下步骤:在步骤S1010中,将待识别网址与网址样本集合中的各个网址样本分别确定相应的多个衰减系数。
在可选的实施例中,图11示出了确定衰减系数的方法的流程示意图,如图11所示,该方法至少包括以下步骤:在步骤S1110中,获取待识别网址的顶级域名和二级域名,并获取网址样本集合中各个网址样本的相应的顶级域名样本和相应的二级域名样本。
其中,顶级域名(top-level domain,简称TLD)是域名中.右面的部分,主要有4种类型的顶级域名,分别是通用、国家、赞助和地理。
具体的,通用顶级域名(Generic TLDs or gTLDs)包括.COM,.NET,.ORG及其他很多顶级域,任何人均可注册该类域名。
国家代码顶级域名或ccTLD是属于特定国家的域名。根据ISO3166-1alpha-2,每一个国家都具有自己的国家代码(大部分情况如此,存在着少数例外)。
赞助顶级域名(sTLD)是获得赞助商支持的代表其所服务的特定领域的一种专门的域名后缀。
地理TLD(geoTLD)是为城市或地理区域发布的最新TLD中的一个部分。部分例子包括.NYC、.ASIA、.TOKYO等等。
而二级域名(Second-level domain,简称SLD)是域名的一部分,是互联网DNS等级之中,处于顶级域名之下的域。二级域名是域名的倒数第二个部分。有时,SLD可以被认为是域名后缀的一部分,因为某些域名注册商使用SLD来指定TLD的应用。例如,.UK注册商提供了.CO.UK用作一般/商业用途,.ORG.UK用作非营利用途,.ME.UK用作个人网站用途。这三个例子也称为ccSLD或国家代码二级域名。
对应的,也可以获取网址样本集合中各个网址样本对应的顶级域名和二级域名,亦即顶级域名样本和二级域名样本。
在步骤S1120中,将顶级域名与相应的各个顶级域名样本进行比较得到相应的多个顶级域名比较结果。
将顶级域名与网址样本集合中各个网址样本的顶级域名样本分别进行比较,可以得到多个顶级域名比较结果。该顶级域名比较结果可以是顶级域名与顶级域名样本是否相同的结果。
在步骤S1130中,将二级域名与相应的各个二级域名样本进行比较得到相应的多个二级域名比较结果。
将二级域名与网址样本集合中各个网址样本的二级域名样本分别进行比较,可以得到多个二级域名比较结果。该二级域名比较结果可以是二级域名与二级域名样本是否相同的结果。
在步骤S1140中,对多个顶级域名比较结果和多个二级域名比较结果进行汇总处理得到多个汇总比较结果,并根据多个汇总比较结果确定相应的多个衰减系数。
当汇总比较结果为顶级域名与顶级域名样本相同,且二级域名与二级域名样本相同时,衰减系数为1;当汇总比较结果为顶级域名与顶级域名样本相同,且二级域名与二级域名样本不同时,衰减系数为0.95;汇总比较结果为顶级域名与顶级域名样本不同时,衰减系数为0.9。
当衰减系数越大时,表明该待识别网址和网址样本可能是通过相同的注册商注册的,因此待识别网址与网址样本为批量申请的恶意网址的可能性越大;当衰减系数越小时,表明该待识别网址和网址样本可能是通过不同的注册商注册的,因此待识别网址与网址样本为批量申请的恶意网址的可能性越小。
在本示例性实施例中,通过待识别网址与各个网址样本的域名比较结果可以确定对应的衰减系数,确定方式简单准确,易于执行,且保障了恶意网址的识别准确性。
在步骤S1020中,根据第一匹配项数、第二匹配项数、第一长度参数、第二长度参数以及衰减系数计算得到相应的多个待定恶意参数。
具体的,按照公式(1)可以计算得到对应的待定恶意参数。
其中,λ为衰减系数,max
值得说明的是,按照按照公式(1)可以分别将待识别网址与一个对应的网址样本之间的第一匹配项数、第一长度参数、第二匹配项数和第二长度参数,以及衰减系数进行计算得到对应的待定恶意参数,而将该待识别网址与网址样本集合中的所有网址样本按照公式(1)的计算方式计算,可以得到该待识别网址与各个网址样本的待定恶意参数,亦即可以得到多个待定恶意参数。
在步骤S1030中,对多个待定恶意参数进行比较得到参数比较结果,并根据参数比较结果在多个待定恶意参数中确定待识别网址的恶意参数。
对多个待定恶意参数进行比较,可以是比较多个待定恶意参数的大小,并从中选择一个待定恶意参数最大的作为待识别网址的恶意参数。
在本示例性实施例中,通过对衰减系数进行计算可以得到对应的恶意参数,以进一步确定恶意网址。
在可选的实施例中,图12示出了确定恶意网址的方法的流程示意图,如图12所示,该方法至少包括以下步骤:在步骤S1210中,获取与恶意参数对应的参数阈值,并将恶意参数与参数阈值进行比较得到阈值比较结果。
一般的,该参数阈值可以设置为0.4,也可以设置为其他数值,本示例性实施例对此不做特殊限定。
然后,将恶意参数与该参数阈值进行比较得到阈值比较结果。
在步骤S1220中,若阈值比较结果为恶意参数大于参数阈值,确定待识别网址为恶意网址。
当恶意参数为0.7,且参数阈值为0.4时,确定恶意参数大于参数阈值,确定该待识别网址为恶意网址。
在本示例性实施例中,通过参数阈值可以识别出恶意网址,识别方式简单准确,能够对后续拦截包含恶意网址的邮件发挥作用。
在可选的实施例中,若邮件中包含恶意网址,对邮件进行拦截处理。
由于待识别网址可以是从邮件中提取得到的,因此当该邮件中包括的待识别网址为恶意网址时,对该邮件进行拦截处理,可以实现对垃圾邮件的有效拦截。
进一步的,还可以利用恶意网址生成对应的恶意网址数据集,以对该恶意网址数据集进行更新。
在可选的实施例中,图13示出了生成恶意网址数据集的方法的流程示意图,如图13所示,该方法至少包括以下步骤:在步骤S1310中,在与恶意网址对应的虚拟系统程序中运行恶意网址得到运行结果。
该虚拟系统程序可以是沙箱环境。该沙箱环境可以是提供的远程桌面,允许在该远程桌面中运行浏览器或其他程序得到运行结果,因此运行所产生的变化可以随后删除。它创造了一个类似沙箱的独立作业环境,在其内部运行的程序并不能对硬盘产生永久性的影响。在网络安全中,沙箱指在隔离环境中,用以测试不受信任的文件或应用程序等行为的工具。
在步骤S1320中,若运行结果为恶意网址存在恶意信息,将恶意网址存储至恶意网址数据集。
当该运行结果要求输入用户名和密码、或者杀毒软件生成恶意提示时,表明该恶意网址存在恶意信息,可以将该恶意网址保存至恶意网址数据集。
在可选的实施例中,图14示出了更新恶意网址数据集的方法的流程示意图,如图14所示,该方法至少包括以下步骤:在步骤S1410中,统计恶意网址数据集中的恶意网址的存储时长,并确定恶意网址数据集中的恶意网址的样本使用情况;样本使用情况表征恶意网址数据集中的恶意网址是否已作为用于识别待识别网址的网址样本进行使用。
该存储时长为恶意网址保存至恶意网址数据集的时长,而样本使用情况则是反映在对其他待识别网址进行识别时,是否有使用过该恶意网址的情况。
在步骤S1420中,根据存储时长和样本使用情况对恶意网址数据集中的恶意网址进行剔除处理,以对恶意网址数据集进行更新。
在统计到恶意网址在恶意网址数据集中的存储时长和样本使用情况之后,可以利用LRU(Least Recently Used,最近最少使用)策略对恶意网址进行剔除。
LRU策略是一种常用的页面置换算法,选择最近最久未使用的恶意网址予以淘汰,以对恶意网址已存储至恶意网址数据集中,但是未被作为样本使用的恶意网址进行淘汰更新。
除此之外,为了确定恶意网址是否被误判,还可以对恶意网址进行标注验证处理。
在可选的实施例中,图15示出了标注验证处理的方法的流程示意图,如图15所示,该方法至少包括以下步骤:在步骤S1510中,对恶意网址进行标注验证处理得到验证结果。
该标注验证处理可以是对恶意网址进行是否误判的处理过程,可以得到对应的验证结果。
在步骤S1520中,若验证结果为恶意网址为误判,对用于识别待识别网址的网址样本进行更新。
当验证结果确定恶意网址为误判时,首先对用于识别待识别网址的网址样本进行复核,若该网址样本错误时,需要对网址样本进行更新。
在步骤S1530中,若验证结果为恶意网址为误判,对用于识别待识别网址的正常网址规则进行更新。
当验证结果确定恶意网址为误判,且对用于识别待识别网址的网址样本复核正确时,表明该网址样本没有错误,可以通过将待识别网址的增加至对应的正常网址规则中,以避免下次对同样的待识别网址的识别错误。
在本示例性实施例中,通过对已识别的恶意网址进行标注验证的方式,可以对误判的恶意网址进行纠正,防止恶意网址误判情况的发生,保证了恶意网址的标注准确度和标注方案的完整性。
下面结合一应用场景对本公开实施例中的恶意网址识别方法做出详细说明。
图16示出了应用场景下恶意网址识别方法的流程示意图,如图16所示,在步骤S1610中,提取邮件中所有的URL。
该待识别网址可以是被识别是否为恶意网址的未知网址,并且该待识别网址可以是从邮件中提取得到的。例如,待识别网址可以利用jsoup从邮件中提取得到。
并且,为了从网址中通过jsoup解析出html中的元素,还可以辅助以正则的方式进行过滤,以将网址中需要进行是否是恶意网址的待识别网址过滤出来。
在步骤S1620中,对恶意URL数据集进行规范化处理和分词。
为了更好的约定URL的规范样式,并提供精确的URL的恶意参数的计算,需要对恶意URL数据集中的样本待识别网址都在一致的步骤下进行规范化处理和分词。
图17示出了应用场景下规范化处理的方法的流程示意图,如图17所示,在步骤S1710中,将待识别网址中的繁体字转换成简体字。
在进行规范化处理之前需要标注一定样本量的恶意URL,统称为恶意URL样本集。该集合需要保留完整的信息,包括大小写、协议、主机名、域名、路径、参数、锚等。
完整的URL格式为protocol://user@host:port/path?query#fragment。而恶意的URL会在浏览器的兼容下,进行变形。
并且,对待识别网址进行的字体转换处理可以是通过已构建的字典库实现的。
在步骤S1720中,去掉待识别网址中的http和/或https协议的字符串。
由于http和https协议对于正常网址和恶意网址的共有性比例太大,因此可以去除。
在步骤S1730中,填充待识别网址中缺少的符号。
由于完整的待识别网址的格式为protocol://user@host:port/path?query#fragment,因此可以将字体转换网址与该格式进行匹配以自动填充缺少的字符。
在步骤S1740中,去除待识别网址中的user信息。
user信息的不同并不会改变待识别网址的显示,并且还会影响后续对待识别网址的识别准确度,因此可以去除user信息。
在步骤S1750中,去除待识别网址中的www主机名。
www主机名同样因为区分度不大,并且在字符填充处理过程中可以自动填充上,因此也可以去除。
在步骤S1760中,去除待识别网址中的无意义后缀符号。
无意义的后缀符在去除时包含且不限于“/”、“.”和“&”等。
在步骤S1770中,将待识别网址中的多个/合并。
在URL中,除了前面的http://中有两个“/”之外,后面在分段的时候多个“/”的效果等同于一个“/”,因此可以将URL路径中连续出现的多个“/”进行去重方式的字符去除处理。
在分词处理之前,还可以对规范化处理得到的规范字符串进行模式映射处理。
具体的,规范字符串进行模式映射处理得到对应的常量字符串的映射关系如表(1)所示:
表(1)
举例而言,当规范字符串在待识别网址中的组成部分为host时,获取与该组成部分对应的格式规则是例如127.0.0.0这样的显示样式的规则。当规范字符串host也为127.0.0.1时,确定该规范字符串满足对应的格式规则,可以将该规范字符串映射为IP这样的固定字符串,并作为常量字符串。
当规范字符串在待识别网址中的组成部分为path时,获取与该组成部分对应的格式规则分别是example@163.com、ZXhhbXBsZUAxNjMuY29t和Dfdhjhjy5yugusb3jhdfhjhjhjei。
并且,其中example@163.com的优先级最高,接下来较高优先级的是ZXhhbXBsZUAxNjMuY29t,最后优先级最低的是Dfdhjhjy5yugusb3jhdfhjhjhjei。因此,可以首先选择example@163.com为目标格式规则,以进一步进行模式映射处理。在确定example@163.com为目标格式规则的情况下,若规范字符串path满足该目标格式规则,可以将规范字符串path映射为EMAIL,即常量字符串。
在确定example@163.com为目标格式规则的情况下,若规范字符串path不满足该目标格式规则,可以按照规则优先级继续确定ZXhhbXBsZUAxNjMuY29t为目标格式规则。
当规范字符串path满足该目标格式规则时,可以将该规范字符串path转换为BASE64MAIL;而当规范字符串path不满足该目标格式规则时,可以继续按照规则优先级选择ZXhhbXBsZUAxNjMuY29t的下一格式规则进行模式映射处理。
在得到常量字符串之后,为了对该常量字符串进行分词处理,可以获取对应的分词符号。该分词符号是利用长时间对成千上万个样本进行分析制定的。
具体的,该分词符号可以包括"!","#","$","&","*","+",",","-",".","/",":",";","<","=",">","?","@","_","`","{","}","|","~","[","]","(",")"。
利用分词符号对常量字符串进行分词处理得到第一词集和第二词集。该第一词集可以是常量字符串中包括的分词符的词集,用s
在获取到网址样本集合之后,可以分别获取网址样本集合中包括的各个网址样本对应的第一样本词集和第二样本词集。该第一样本词集和第二样本词集也是经过分词符对网址样本进行分词处理得到的。其中,第一样本词集用s
在步骤S1630中,计算URL恶意参数,获取第一相似度样本和恶意参数。
具体的,对第一词集和第一样本词集按照位置顺序从头到尾进行一次匹配,再从尾到头进行一次匹配,将两次匹配得到的最大相同个数作为第一匹配项数。
然后,将第一词集和第一样本词集的字符长度进行比较和统计,将更加长的一个字符长度统计为第一长度参数。
对第二词集和第二样本词集进行求交集计算,得到二者之间最大的相同个数作为第二匹配项数。然后,将第二词集和第二样本词集之间的字符长度进行比较,并统计最长的字符长度作为第二长度参数。
由于域名对例如相似度系数的恶意参数影响较大,因此可以设定衰减系数对不同域名进行衰减。
当待识别网址的顶级域名与网址样本的顶级域名样本相同,且二级域名与二级域名样本相同时,衰减系数为1;当待识别网址的顶级域名与网址样本的为顶级域名与顶级域名样本相同,且二级域名与二级域名样本不同时,衰减系数为0.95;待识别网址的顶级域名与网址样本的为顶级域名与顶级域名样本不同时,衰减系数为0.9。
具体的,可以按照公式(1)计算得到恶意参数,在此不再赘述。
并且,还可以将所有样本的第二样本词集w
在步骤S1640中,邮件的URL正常。
获取与恶意参数对应的参数阈值,并将恶意参数与参数阈值进行比较得到阈值比较结果。若阈值比较结果为恶意参数小于或等于参数阈值,确定待识别网址为正常网址,则该邮件里的URL是正常的。
在步骤S1650中,将包含恶意网址的可疑邮件进行拦截,并将恶意网址放入可疑URL数据集。
若阈值比较结果为恶意参数大于参数阈值,确定待识别网址为恶意网址,并且,可以将该恶意网址存储到对应的网址样本集合中。
图18示出了应用场景下更新网址样本集合的方法的流程示意图,如图18所示,在步骤S1810中,人工标注恶意网址是否有害。
在线识别出的恶意网址可以成功保存至网址样本集合中。进一步的,人工在沙箱环境下判定该恶意网址是否为有害的URL。
具体的,在与恶意网址对应的沙箱环境中运行恶意网址得到运行结果。
在步骤S1820中,URL正常,记录URL与相似样本URL。
若运行结果为恶意网址不存在恶意信息,表明该恶意网址无害,对URL与对应样本进行记录即可。
在步骤S1830中,恶意URL数据集。
若运行结果为恶意网址存在恶意信息,将恶意网址存储至恶意网址数据集。
当该运行结果要求输入用户名和密码、或者杀毒软件生成恶意提示时,表明该恶意网址存在恶意信息,可以将该恶意网址保存至恶意网址数据集。该恶意网址数据集可以保证计算相似度系数时能够更加快速。
除此之外,随着恶意网址数据集的数量的线性增长,在线匹配的响应压力也相应增加,所以可以使用LRU策略将新增时间久且未作为网址样本的恶意网址进行淘汰更新。
图19示出了应用场景下标注验证处理的方法的流程示意图,如图19所示,在步骤S1910中,恶意标注与URL相似判定是否一致。
对相似度系数等恶意参数和标注情况进行判定。
在步骤S1920中,相似度误判。修改样本或者添加白名单。
当相似度系数等恶意参数较高,但是标注正常的恶意网址,认为该恶意网址是误判的,因此需要对对应的网址样本进行复核。如果是样本错误,需要对样本进行更新;否则通过网址模板规则、域名规则和高频词规则将该恶意网址添加进去进行更新,以对该恶意网址的下一次识别进行排除,防止之后的在线误判。
在步骤S1930中,相似度正判。
当相似度系数等恶意参数较高,并且标注有害的恶意网址,认为该恶意网址是正确判定的。
在本公开的示例性实施例中,本公开一方面,对待识别网址进行规范化处理,能够提取出待识别网址中的关键信息,降低无关信息对恶意网址识别的干扰,提升恶意网址识别的准确度;另一方面,通过第一匹配处理和第二匹配处理的结果进行参数计算,快速得到用于识别恶意网址的恶意参数,保证了恶意网址识别的时效性,并进一步对恶意邮件进行有效拦截。
需要说明的是,虽然以上示例性实施例的实施方式以特定顺序描述了本公开中方法的各个步骤,但是,这并非要求或者暗示必须按照该特定顺序来执行这些步骤,或者必须执行全部的步骤才能实现期望的结果。附加地或者备选地,可以省略某些步骤,将多个步骤合并为一个步骤执行,以及/或者将一个步骤分解为多个步骤执行等。
在介绍了本公开示例性实施方式的方法之后,接下来,参考图20对本公开示例性实施方式的装置进行说明。
在本公开的示例性实施例中,还提供一种恶意网址识别装置。图20示出了恶意网址识别装置的结构示意图,如图20所示,恶意网址识别装置2000可以包括:规范处理模块2010、映射处理模块2020、分词处理模块2030、匹配处理模块2040和网址识别模块2050。其中:
规范处理模块2010,被配置为获取待识别网址,并对待识别网址进行规范化处理得到待识别网址中包括的规范字符串;映射处理模块2020,被配置为对规范字符串进行模式映射处理得到常量字符串,并获取与常量字符串对应的分词符号;分词处理模块2030,被配置为利用分词符号对常量字符串进行分词处理得到第一词集和第二词集;匹配处理模块2040,被配置为对第一词集进行第一匹配处理得到第一词集参数,并对第二词集进行第二匹配处理得到第二词集参数;网址识别模块2050,被配置为对第一词集参数和第二词集参数进行参数计算得到待识别网址的恶意参数,以根据恶意参数确定待识别网址为恶意网址。
本公开各实施例中提供的恶意网址识别装置的具体细节已经在对应的方法实施例中进行了详细的描述,因此此处不再赘述。
应当注意,尽管在上文详细描述中提及了恶意网址识别装置2000的若干模块或者单元,但是这种划分并非强制性的。实际上,根据本公开的实施方式,上文描述的两个或更多模块或者单元的特征和功能可以在一个模块或者单元中具体化。反之,上文描述的一个模块或者单元的特征和功能可以进一步划分为由多个模块或者单元来具体化。
此外,尽管在附图中以特定顺序描述了本公开中方法的各个步骤,但是,这并非要求或者暗示必须按照该特定顺序来执行这些步骤,或是必须执行全部所示的步骤才能实现期望的结果。附加的或备选的,可以省略某些步骤,将多个步骤合并为一个步骤执行,以及/或者将一个步骤分解为多个步骤执行等。
通过以上的实施方式的描述,本领域的技术人员易于理解,这里描述的示例实施方式可以通过软件实现,也可以通过软件结合必要的硬件的方式来实现。因此,根据本公开实施方式的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是CD-ROM,U盘,移动硬盘等)中或网络上,包括若干指令以使得一台计算设备(可以是个人计算机、服务器、移动终端、或者网络设备等)执行根据本公开实施方式的方法。
在介绍了本公开示例性实施方式的方法和装置之后,接下来,参考图21对本公开示例性实施方式的电子设备进行说明。
此外,在本公开的示例性实施例中,还提供了一种能够实现上述方法的电子设备。
下面参照图21来描述根据本公开的这种实施例的电子设备2100。图21显示的电子设备2100仅仅是一个示例,不应对本公开实施例的功能和使用范围带来任何限制。
如图21所示,电子设备2100以通用计算设备的形式表现。电子设备2100的组件可以包括但不限于:上述至少一个处理单元2110、上述至少一个存储单元2120、连接不同系统组件(包括存储单元2120和处理单元2110)的总线2130、显示单元2140。
其中,所述存储单元存储有程序代码,所述程序代码可以被所述处理单元2110执行,使得所述处理单元2110执行本说明书上述“示例性方法”部分中描述的根据本公开各种示例性实施例的步骤。
存储单元2120可以包括易失性存储单元形式的可读介质,例如随机存取存储单元(RAM)2121和/或高速缓存存储单元2122,还可以进一步包括只读存储单元(ROM)2123。
存储单元2120还可以包括具有一组(至少一个)程序模块2125的程序/实用工具2124,这样的程序模块2125包括但不限于:操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。
总线2130可以为表示几类总线结构中的一种或多种,包括存储单元总线或者存储单元控制器、外围总线、图形加速端口、处理单元或者使用多种总线结构中的任意总线结构的局域总线。
电子设备2100也可以与一个或多个外部设备2300(例如键盘、指向设备、蓝牙设备等)通信,还可与一个或者多个使得用户能与该电子设备2100交互的设备通信,和/或与使得该电子设备2100能与一个或多个其它计算设备进行通信的任何设备(例如路由器、调制解调器等等)通信。这种通信可以通过输入/输出(I/O)接口2150进行。并且,电子设备2100还可以通过网络适配器2160与一个或者多个网络(例如局域网(LAN),广域网(WAN)和/或公共网络,例如因特网)通信。如图所示,网络适配器2140通过总线2130与电子设备2100的其它模块通信。应当明白,尽管图中未示出,可以结合电子设备2100使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理单元、外部磁盘驱动阵列、RAID系统、磁带驱动器以及数据备份存储系统等。
通过以上的实施例的描述,本领域的技术人员易于理解,这里描述的示例实施例可以通过软件实现,也可以通过软件结合必要的硬件的方式来实现。因此,根据本公开实施例的技术方案可以以软件产品的形式体现出来,该软件产品可以存储在一个非易失性存储介质(可以是CD-ROM,U盘,移动硬盘等)中或网络上,包括若干指令以使得一台计算设备(可以是个人计算机、服务器、终端装置、或者网络设备等)执行根据本公开实施例的方法。
在介绍了本公开示例性实施方式的方法、装置和电子设备之后,接下来,参考图22对本公开示例性实施方式的计算机可读存储介质进行说明。
在本公开的示例性实施例中,还提供了一种计算机可读存储介质,其上存储有能够实现本说明书上述方法的程序产品。在一些可能的实施例中,本公开的各个方面还可以实现为一种程序产品的形式,其包括程序代码,当所述程序产品在终端设备上运行时,所述程序代码用于使所述终端设备执行本说明书上述“示例性方法”部分中描述的根据本公开各种示例性实施例的步骤。
参考图22所示,描述了根据本公开的实施例的用于实现上述方法的程序产品2200,其可以采用便携式紧凑盘只读存储器(CD-ROM)并包括程序代码,并可以在终端设备,例如个人电脑上运行。然而,本公开的程序产品不限于此,在本文件中,可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。
所述程序产品可以采用一个或多个可读介质的任意组合。可读介质可以是可读信号介质或者可读存储介质。可读存储介质例如可以为但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、光纤、便携式紧凑盘只读存储器(CD-ROM)、光存储器件、磁存储器件、或者上述的任意合适的组合。
计算机可读信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了可读程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。可读信号介质还可以是可读存储介质以外的任何可读介质,该可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。
可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于无线、有线、光缆、RF等等,或者上述的任意合适的组合。
可以以一种或多种程序设计语言的任意组合来编写用于执行本公开操作的程序代码,所述程序设计语言包括面向对象的程序设计语言—诸如Java、C++等,还包括常规的过程式程序设计语言—诸如“C”语言或类似的程序设计语言。程序代码可以完全地在用户计算设备上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户计算设备上部分在远程计算设备上执行、或者完全在远程计算设备或服务器上执行。在涉及远程计算设备的情形中,远程计算设备可以通过任意种类的网络,包括局域网(LAN)或广域网(WAN),连接到用户计算设备,或者,可以连接到外部计算设备(例如利用因特网服务提供商来通过因特网连接)。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其他实施例。本申请旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性,本公开的真正范围和精神由权利要求指出。
- 恶意网址识别方法及装置、存储介质、电子设备
- 恶意网址数据库的建立方法、恶意网址的识别方法和装置