异构数据库之间数据同步方法、系统、设备及存储介质
文献发布时间:2023-06-19 11:39:06
技术领域
本发明涉及数据库,尤其涉及异构数据库之间数据同步方法、系统、设备及存储介质。
背景技术
近年来随着开源数据库的持续发展和在实际生产活动中的广泛应用,开源数据库的稳定性和生态环境都得到了极大的提高,在此背景下商业数据库Oracle不再是大家一成不变的选择。与此同时,Oracle数据库笨重,闭源,收费昂贵,周边开发不够灵活的缺点被无限放大,引入新的开源数据库后,数据从传统Oracle流向开源数据库,抑或是生产系统从Oracle直接迁移到开源数据库是势在必行的,那么就需要一种可靠的数据同步方法。
发明内容
本申请实施例通过提供一种异构数据库之间数据同步方法的方法、系统、存储介质,解决了现有技术中异构数据库之间数据同步方法的可靠性问题。
一种异构数据库之间数据同步方法,所述方法包括:
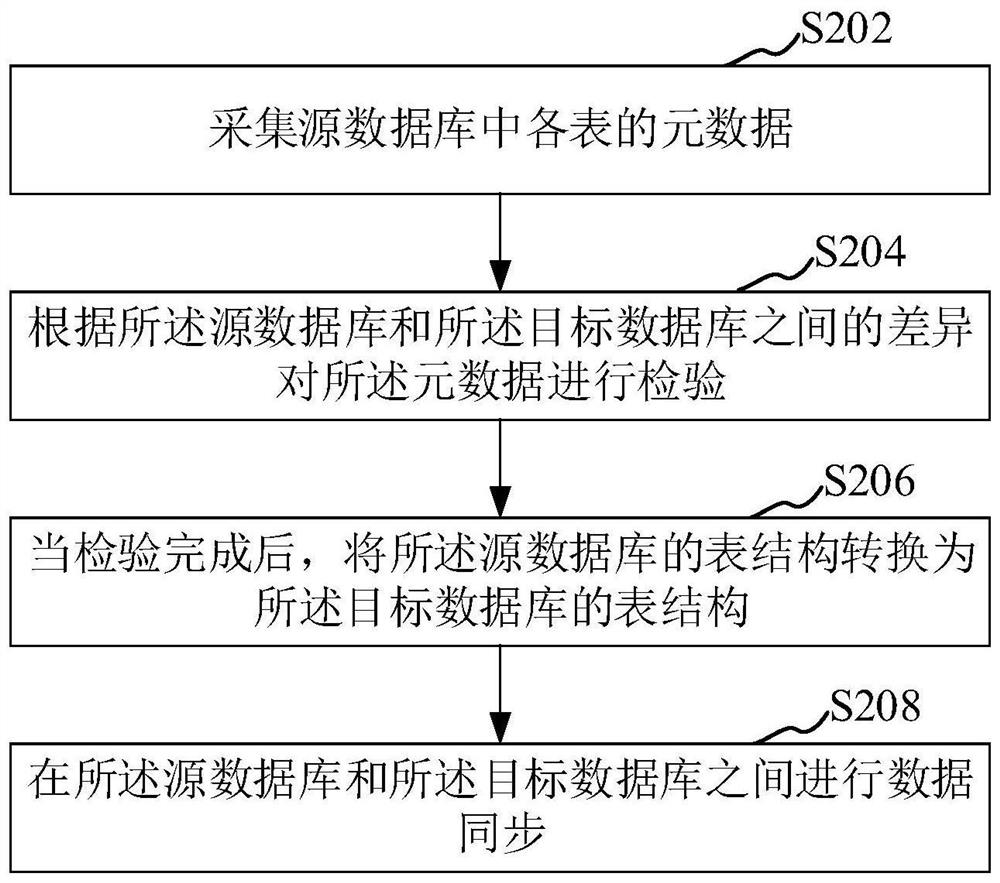
采集源数据库中各表的元数据;
根据所述源数据库和所述目标数据库之间的差异对所述元数据进行检验;其中,所述源数据库和所述目标数据库为异构数据库;
当检验完成后,将所述源数据库的表结构转换为所述目标数据库的表结构;
在所述源数据库和所述目标数据库之间进行数据同步。
在其中一个实施例中,所述元数据包括表级别信息、列信息、索引和约束信息。
在其中一个实施例中,所述根据源数据库和目标数据库之间的差异对元数据进行检验,包括:
检验源数据库和目标数据库之间是否存在唯一键约束差异,以将源数据库中重复的数据删除。
在其中一个实施例中,所述当检验完成后,将源数据库的表结构转换为目标数据库的表结构,包括:
获取源数据库和目标数据库之间数据类型的映射关系;
对源数据库中的每一源表,根据其表级别信息在目标数据库中创建目标表,并将表级别信息写入目标表;
根据源表的列信息在目标表中创建列,并根据所述映射关系设置目标表各列的数据类型;
根据源表的索引和约束信息,在目标表中添加索引和约束。
在其中一个实施例中,所述在源数据库和目标数据库之间进行数据同步,包括:
设置增量数据记录点;
对所述增量数据记录点之前的所有历史数据进行全量数据同步;
对所述增量数据记录点之后的数据进行增量数据追踪得到增量数据;
在所述全量数据同步完成后,对所述增量数据进行同步。
在其中一个实施例中,所述对增量数据进行同步包括:
在进行增量数据追踪时,将源数据库中的数据变化封装为正向增量消息加入消息队列;
在对目标数据库进行增量数据同步时,从所述消息队列中取出所述正向增量消息,并解析为增量数据后进行数据融合;
在对目标数据库进行增量数据同步时,记录工作检查点以保障断点续传;
在对目标数据库进行增量数据同步时,进行目标数据库的增量数据追踪,并将目标数据库中的数据变化封装为反向增量消息加入消息队列;
从所述消息队列中取出所述反向增量消息,并解析为增量数据后进行数据融合以将目标数据库的增量数据同步到源数据库;
在对源数据库进行增量数据同步时,记录工作检查点以保障断点续传。
在其中一个实施例中,所述在所述源数据库和所述目标数据库之间进行数据同步,还包括:
对源数据库中的每一条数据,将各列内容拼接为第一字符串,并计算md5值;
对同步至目标数据库的相应数据,将各列内容拼接为第二字符串,并计算md5值;
当第一字符串的md5值和第二字符串的md5值匹配时,校验通过。
一种异构数据库之间数据同步设备,其特征在于,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的异构数据库之间数据同步程序,所述处理器执行所述异构数据库之间数据同步程序时实现上述的方法的步骤。
一种计算机可读存储介质,其上存储有异构数据库之间数据同步方法的程序,该异构数据库之间数据同步程序被处理器执行时实现上述的方法。
上述方法、系统、设备以及存储介质通过对源数据库的元数据进行采集并检验,消除源数据库转换到目标数据库时的差异,从而能够正确创建目标数据库的表结构,使得数据能够顺利可靠同步。
附图说明
图1为本申请实施例方案涉及的硬件运行环境的异构数据库之间数据同步设备结构示意图;
图2为一实施例的异构数据库之间数据同步方法流程图;
图3为图2中步骤S202的其中一种实现方式的流程图;
图4为图2中步骤S204的其中一种实现方式的流程图;
图5为图2中步骤S206的其中一种实现方式的流程图;
图6为图2中步骤S208的其中一种实现方式的流程图;
图7a为图6中步骤S608中对增量数据进行同步的流程图;
图7b为正向增量同步示意图;
图7c为反向增量同步示意图;
图8为图2中步骤S208中执行数据校验的处理流程图;
图9为一实施例的异构数据库之间数据同步系统模块图。
具体实施方式
本申请涉及一种异构数据库之间数据同步方法,用于在异构的源数据库和目标数据库之间同步数据,所述方法包括:采集源数据库中各表的元数据;根据源数据库和目标数据库之间的差异对元数据进行检验;根据检验结果将源数据库的表结构转换为目标数据库的表结构,并处理所述差异;在源数据库和目标数据库之间进行数据同步。
上述方法通过对源数据库的元数据进行采集并检验,消除源数据库转换到目标数据库时的差异,从而能够正确创建目标数据库的表结构,使得数据能够顺利可靠同步。
为了更好的理解上述技术方案,下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
图1是本申请实施例方案涉及的硬件运行环境的异构数据库之间数据同步设备100结构示意图。
本申请实施例的异构数据库之间数据同步设备,可以是例如服务器、个人计算机,智能手机、平板电脑、便携计算机等。只要其具备一定的通用数据处理能力即可。
如图1所示,所述异构数据库之间数据同步设备100包括:存储器104、处理器102及网络接口106。
处理器102在一些实施例中可以是一中央处理器(Central Processing Unit,CPU)、控制器、微控制器、微处理器或其他数据处理芯片,用于运行存储器104中存储的程序代码或处理数据,例如执行程序等。
存储器104至少包括一种类型的可读存储介质,所述可读存储介质包括闪存、硬盘、多媒体卡、卡型存储器(例如,SD或DX存储器等)、磁性存储器、磁盘、光盘等。存储器104在一些实施例中可以是异构数据库之间数据同步设备100的内部存储单元,例如该异构数据库之间数据同步设备100的硬盘。存储器104在另一些实施例中也可以是异构数据库之间数据同步设备100的外部存储设备,例如该异构数据库之间数据同步设备100上配备的插接式硬盘,智能存储卡(Smart Media Card,SMC),安全数字(Secure Digital,SD)卡,闪存卡(Flash Card)等。
进一步地,存储器104还可以包括异构数据库之间数据同步设备100的内部存储单元。存储器104不仅可以用于存储安装于异构数据库之间数据同步设备100的应用软件及各类数据,例如人脸识别模型训练的代码等,还可以用于暂时地存储已经输出或者将要输出的数据。
网络接口106可选的可以包括标准的有线接口、无线接口(如WI-FI接口),通常用于在该异构数据库之间数据同步设备100与其他电子设备之间建立通信连接。
网络可以为互联网、云网络、无线保真(Wi-Fi)网络、个人网(PAN)、局域网(LAN)和/或城域网(MAN)。网络环境中的各种设备可以被配置为根据各种有线和无线通信协议连接到通信网络。这样的有线和无线通信协议的例子可以包括但不限于以下中的至少一个:传输控制协议和互联网协议(TCP/IP)、用户数据报协议(UDP)、超文本传输协议(HTTP)、文件传输协议(FTP)、ZigBee、EDGE、IEEE 802.11、光保真(Li-Fi)、802.16、IEEE 802.11s、IEEE 802.11g、多跳通信、无线接入点(AP)、设备对设备通信、蜂窝通信协议和/或蓝牙(Blue Tooth)通信协议或其组合。
图1仅示出了具有组件102-106的异构数据库之间数据同步设备100,本领域技术人员可以理解的是,图1示出的结构并不构成对异构数据库之间数据同步设备100的限定,可以包括比图示更少或者更多的部件,或者组合某些部件,或者不同的部件布置。
如图2所示,为一实施例的异构数据库之间数据同步方法流程图。所述方法用于在异构的源数据库和目标数据库之间同步数据。异构是指不同服务商的数据库,例如Oracle、MySQL、SQL Server等。源数据库是指其数据要被同步的数据库,目标数据库则是数据要同步至的数据库。所述方法可以包括以下步骤:
步骤S202:采集源数据库中各表的元数据。
数据库包括关系型数据库和非关系型数据库。关系型数据库以实体-关系(E-R)模型为基础建立。数据库中数据以表的形式存储,每个表中都存储实体信息或关系信息。例如,对于学校管理系统,涉及的实体包括老师、学生、课程,涉及的关系则包括老师教的课程、学生选修的课程。则老师、学生、课程、老师教的课程信息、学生选修的课程信息分别用一张表来存储。
数据库中的表具有行和列,每列有一个列名,对应于实体或关系的属性或者其他必要信息,例如仅用于标识数据的ID列。例如,对于老师表,列可以包括姓名、性别、电话、邮箱等。此外,需要包含老师ID列。表中的行则表示一条数据记录,对应于一个具体老师的相关信息。
表1
当数据表中没有记录时,则除了列名称以外,就没有其他行。除了数据记录以外,用于表征表的结构的数据称为元数据。元数据包括表名、表注释、分区信息、列信息、索引信息和约束信息等。
步骤S204:根据所述源数据库和所述目标数据库之间的差异对所述元数据进行检验。其中,所述源数据库和所述目标数据库为异构数据库。
通过步骤S202得到的源数据库的各表的元数据,在向目标数据库的表结构转化之前,需要经过检查。由于数据库不同,在实现方式上也会不一样,比如Oracle和MySQL数据库的UK(Unique Key,唯一键)约束就存在差异。假设在Oracle一边的UK由(a,b)两列组成,假设b字段的非空属性是允许为空,那么在MySQL这边,多组(a,null)数据可以插入到MySQL数据库中,但是这种情况在Oracle不会发生,只能插入一条数据,也就是UK的含义随着数据库的不同带来了转变,如果在转换表结构的时候不考虑这一点,那么会造成业务含义的转变,很可能会造成生产事故,元数据检验做的就是找出所有这种数据库差异对表结构的影响因素。
步骤S206:当检验完成后,将所述源数据库的表结构转换为所述目标数据库的表结构。
主要是将列的数据类型进行对应转换,以及添加表级别信息、索引和约束信息。
步骤S208:在所述源数据库和所述目标数据库之间进行数据同步。
在表结构同步完成后,开始同步表里的数据。同步数据的过程分为全量数据同步和增量数据同步。对于Oracle数据库而言,全量数据同步可以利用Oracle的一致性读(Consistent Get)获取。本申请中还可以设置数据追踪器,通过解析归档日志实现增量数据同步。数据追踪器会将增量数据记录并落地,做到无论业务如何繁忙,都不会丢失一笔数据。
在其中一个实施例中,所述元数据包括表级别信息、列信息、索引和约束信息,如图3所示,则所述步骤S202:采集源数据库中各表的元数据可以包括:
步骤S302:获取表级别信息。
表级别相关信息可以包括表名、表注释。表名用于在同一个数据库中唯一表示一张表,在进行数据的增删改查时,要指定表名。表名一般具有实际含义,以方便查找。例如老师表可以命名为teacher。表注释是对表中的相关信息进行解释的内容,方便理解数据库的设置,在数据库执行其功能时,表注释被忽略。
若源数据库中的表为分区表,则还获取分区信息;所述分区信息包括:分区键、分区类型以及分区跨度。在关系型数据库中,分区是通过创建单独的物理表(例如为每个月的数据创建一个表)并且定义一个成员表的联合视图来实现的。分区键是数据归属不同物理表的划分依据,每条数据属于哪个表分区是按照分区键的值来决定的;分区类型指的是表分区的方式,比如按照时间维度,按照分区键的范围等;分区跨度则是单个分区包含的数据的边界范围单元,比如按照时间分区的分区表,可以按照每个月一个分区,分区跨度就是一个也,也可以按照每三个月一个分区来设置,那么分区跨度就是三个月。
步骤S304:采集列信息。
列相关信息可以包括列名、列长度、列注释、默认值、非空属性。列名上述已经提及。列长度是指该列中的每条数据能够存储的数据的长度,例如255个字符。列注释与表注释类似,但解释的是列的内容。默认值是指当插入新数据时,若该列对应的属性没有被指定时,默认填入的值。例如ID列的默认值是自增的整数。性别也可以默认为男。非空属性是指列是否能为空值,有些列没有指定默认值,如果也不能为空,当插入数据时,若该列对应的属性没有被指定时,该条数据就不能插入。在上表1中,姓名没有默认值,也不能为空。在登记老师信息时,如果不输入老师姓名,则会出错。
步骤S306:采集索引和约束信息。
一个索引是存储的表中一个特定列的值数据结构(最常见的是B-Tree)。索引是在表的列上创建。所以,索引包含一个表中列的值,并且这些值存储在一个上述数据结构中。索引同时存储了指向表中的相应行的指针,即存储的物理地址。对于没有数据的表来说,索引为空值(但已经实例化)。
约束(constraint)是数据库模式(schema)定义的一部分。约束通常与一个表相关联,并使用CREATE CONSTRAINT或CREATE ASSERTIONSQL语句创建。
约束定义数据库中的数据必须符合的某些属性。可以应用于列、整个表格、多个表格或整个模式。可靠的数据库系统可以确保约束始终保持不变(除了可能在事务内部,对于所谓的延迟约束)。
常见的约束条件包括:not null:列中的每个值都不能为NULL(空);unique-value(s):对于表中的每一行必须是唯一的;primary key:指定列中的值对于表中的每一行必须是唯一的,而不是NULL;通常数据库中的每个表都应该有一个主键-它用于识别单个记录。指定列中的foreign key必须引用另一个表中的现有记录(通过它的主键或其他唯一约束)check:指定一个表达式,为了满足约束条件,它必须计算为真。
可以理解,上述步骤没有先后之分。
在其中一个实施例中,如图4所示,所述步骤S204:根据所述源数据库和所述目标数据库之间的差异对所述元数据进行检验,具体包括:
步骤S402:检验源数据库和目标数据库之间是否存在唯一键约束差异,以将源数据库中重复的数据删除。
若源数据库中组成唯一键的列为空不影响唯一性判断,而目标数据库中组成唯一键的列为空影响唯一性判断,则将源数据库中组成唯一键的列为空的数据按照影响唯一性判断的规则删除重复数据。
以从Oracle数据库向MySQL数据库转换为例,因为Oracle数据库中加UK的时候可以不检查之前数据是否违反唯一性,但是MySQL没有这个功能,所以要提前检查数据。假设在Oracle一边的UK由(a,b)两列组成,假设b字段的非空属性是允许为空,那么在MySQL这边,多组(a,null)数据可以插入到MySQL数据库中,但是这种情况在Oracle不会发生,只能插入一条数据。
进一步地,还包括以下至少一项:
步骤S404:检查源数据库的索引和约束。
检查源数据库的索引数据结构是否与目标数据库的索引数据结构相同,以决定是否需要进行索引的转换。
检查源数据库是否限定了约束,以及限定了哪些约束。另外检查源数据库和目标数据库支持的约束是否相同,以及相同约束代表的含义是否有差别。
步骤S406:检查源数据库的表数据量和存储空间大小。
表的数据可以表示为数据库中表的数量,以及每个表所包含的数据的条数。空间大小指数据库占用的存储空间。在进行数据同步时,需要估算所需要的空间以及同步数据所需要的时间,方便数据库管理员了解。数据库能够直接提供记录的数量,存储空间可以由数据库当前存储的操作系统提供。
步骤S408:检查列信息。
检查列的信息,比如列名是否是关键字,时间类型是日期(date)还是时间戳(timestamp)等。
步骤S410:检查权限。
检查权限包括检查是否存在权限控制以及存在何种权限。将表相关授予的用户的相关增删改查权限查询出来,供目标数据库酌情授予。例如,可以使用角色的概念管理数据库访问权限。根据角色自身的设置不同,一个角色可以看做是一个数据库用户,或者一组数据库用户。角色可以拥有数据库对象(比如表)以及可以把这些对象上的权限赋予其它角色,以控制谁拥有访问哪些对象的权限。一个数据库角色可以有很多权限,这些权限定义了角色和拥有角色的用户可以做的事情,例如查看、修改、删除等权限。在将源数据库的数据同步至目标数据库时,数据库的权限也要进行同步。
上述步骤,将采集的元数据进行逐一检查,以确定数据库之间的差异在元数据层面得到仔细的处理。如果未进行除表级信息和列信息之外的检查,目标数据库的结构也可以转换至目标数据库,但相关的索引、约束等可能会采用默认值,而可能导致出现无法预知的错漏。可以理解,上述步骤没有先后之分。
在其中一个实施例中,如图5所示,所述步骤S206:当检验完成后,将所述源数据库的表结构转换为所述目标数据库的表结构,可以包括:
步骤S502:获取源数据库和目标数据库之间数据类型的映射关系。
完成了表的元数据的校验,后面就需要进行表结构转换,表结构的转换主要包括列上的数据类型的转换。以从Oracle数据库向MySQL数据库转换为例,数据类型之间的映射例如下表2:
表2
表2中所列的是常用数据类型,不代表数据库只包含这些数据类型。
需要说明的是,随着数据库技术的不断更新发展,数据库所支持的数据类型可能是在变化的。根据变化的情况,上述映射表也需要作出响应的调整。
步骤S504:对源数据库中的每一源表,根据其表级别信息在目标数据库中创建目标表,并将表级别信息写入目标表。
在目标数据库中新建目标表,其可以只有表名和表级别相关信息,从之前采集的源表的表级别信息中获取。
步骤S506:根据源表的列信息在目标表中创建列,并根据所述映射关系设置目标表各列的数据类型。
在进行数据表结构转换时,需要对源数据库所使用到的数据类型都对应转换为目标数据库的数据类型。对于目标数据库不支持的数据类型,为避免丢失数据和字段所包含的业务属性,在对这部分数据类型转化时,会给到用户足够的提示,并给与用户极大的自由选择度,可以使用不丢失数据的其它数据类型,但是所包含的业务属性,则需要在开发层面去解决。数据类型之间的对应关系可以存储在映射表中,供转换时调用。
步骤S508:根据源表的索引和约束信息,在目标表中添加索引和约束。
根据目标数据库对索引和约束的规则,将来自源表的索引和约束信息添加至目标表中。
经过上述步骤的处理,源数据库的结构被迁移至目标数据库,并且做到信息不丢失,差异被转化。
在其中一个实施例中,如图6所示,所述步骤S208:在所述源数据库和所述目标数据库之间进行数据同步,可以包括:
步骤S602:设置增量数据记录点。
对于生产数据库而言,其中的数据并非静态的,而是时时刻刻都在发生变化。本实施例中,在执行数据同步开始时的时间点,作为增量数据记录点。在此时间点以前的数据,可以认为是静态的历史数据,将其划分为全量数据。在此时间点以后的数据,则划分为增量数据。可以理解,该时间点也可以更早。
步骤S604:对所述增量数据记录点之前的所有历史数据进行全量数据同步。
在同步正式开始执行的时间点之前的所有数据即为全量数据。这一步主要是进行数据拷贝。将源数据库中的数据读取出来,转换为目标数据库所要求的数据类型,并遵循约束插入目标数据库。
步骤S606:对所述增量数据记录点之后的数据进行增量数据追踪。
可以设置数据追踪器记录数据增量,数据追踪器启动后,会一直运行。在进行全量数据同步时,任何增量数据都被数据追踪器记录。因此不会有数据被遗漏。
步骤S608:在所述全量数据同步完成后,对增量数据进行同步。
为了不丢失数据,全量数据同步结束后,可以设置增量数据同步单元将全量同步时产生的数据融合(merge)到表中。
在其中一个实施例中,如图7a和7b所示,所述步骤S608中所述对增量数据进行同步包括:
步骤S702:在进行增量数据追踪时,将源数据库中的数据变化封装为消息加入消息队列。
数据追踪器会一直运行捕获增量变化,数据追踪器是消息的生产者。
步骤S704:在对目标数据库进行增量数据同步时,从所述消息队列中取出消息,并解析为增量数据后进行数据融合。
增量数据同步单元是消息队列的消费者,会不断的消费数据追踪器生成的数据(消息)。
进一步地,在目标数据库进行增量数据同步时,还包括:
步骤S706:记录工作检查点以保障断点续传。
在消费过程中,增量数据同步单元会不断记录自己的工作检查点,推进检查点的实现是数据断点续传功能的保障。
上述步骤S702~S706为正向增量同步。在一个实施例中,还可以同时采用反向增量同步。如图7c所示,在对目标数据库进行增量数据同步时,还进行目标数据库的增量数据追踪,并将目标数据库中的数据变化封装为反向增量消息加入消息队列;
从所述消息队列中取出反向增量消息,并解析为增量数据后进行数据融合以将目标数据库的增量数据同步到源数据库。
正向同步关系建立后,反向同步的数据追踪器开始工作,解析目标数据库日志(例如MySQL binlog),开始源源不断产生消息,反向增量数据同步单元开始作为消费者不断合并变化,消费数据追踪器的消息,同时在消费过程中,反向增量数据同步单元也会不断记录自己的工作检查点,反向数据同步数据同样实现了断点续传功能。
如图8所示,在步骤S208:在所述源数据库和所述目标数据库之间进行数据同步,还包括:
步骤S802:对源数据库中的每一条数据,将各列内容拼接为第一字符串,并计算md5值。
步骤S804:对同步至目标数据库的相应数据,将各列内容拼接为第二字符串,并计算md5值。
本实施例中,对于源数据库和目标数据库表里的每一条数据,可以将每条数据拼成字符串,对字符串采用md5生成器计算md5值。例如,对表1中老师ID、姓名、性别、电话以及邮箱拼成字符串,第一条数据即拼为“1张三男133xxxxxxxxxx@xx.com”,当然也可以在每列数据直接增加特定连接符,例如“-”、“.”等,可以达到同样的效果。可以理解,校验的方法也不限于此。例如,也可以计算字符串的哈希值。
步骤S806:当第一字符串的md5值和第二字符串的md5值匹配时,校验通过。
当源数据库和目标数据库中对应的数据所形成的字符串的md5值匹配时,则表示数据同步不存在差错,校验成功。
进一步地,所述数据校验还包括:统计增量数据被追踪的次数;将被追踪的次数超过设定的次数阈值的增量数据标记为热点数据;对所述热点数据进行多次校验。
增量数据一般都是最近时间段的热点数据,在对这部分数据进行数据校验的时候,比如要比较最近一天内变化的数据,MD5生成器会利用数据追踪器的消息,获得最近一天内变化的热点数据,然后计算md5,如果这部分热点数据在数据校验时仍然很“热”,还在频繁变化,那么MD5生成器会尝试多次去校验。为了比较热点数据,需要用到数据追踪器产生的消息。
上述的全量同步校验以及增量同步校验,从多维度保障了数据的一致性,以及同步过程的安全性。
上述异构数据库间数据迁移的方法,保障了如下要求:
实时性:在读写分离场景中必须考虑的一个问题,数据同步的实时性。实时性更体现了数据同步的高效率。同时实时性也意味着在写流量切换的时候,对生产环境的影响可以降到最低,是切换过程用户无感知的基础。
双向性:在以数据流量切换为目的,或者以数据双写为目的的场景下,数据流向的双向性尤为重要,从源端或者目标端任一端流入的数据都需要流转到对端。本申请完整解决了这个问题,而且不会产生数据回环,完美破环保障了数据的一致性。
安全性:数据安全对企业的重要性不言而喻,数据同步带来了数据的安全性和一致性的隐患,本申请数据同步过程安全可靠,解决了同步过程中可能的数据丢失,数据错乱,数据回环等可能造成数据不一致的问题。
断点续传:在数据同步过程中,数据同步可能会由于网络等原因中断,在中断之后,本申请可以实现断点续传,从中断处继续开始数据同步,无需重新执行,更不会造成数据丢失。
可检查性:数据校验的问题虽然在业界有一些成名已久的工具,但是长久以来针对实时变化数据的校验是业界迟迟未能有效解决的一大痛点。本申请彻底性的解决了这一问题。可以按照用户需要,随时发起全量校验和增量校验,是对安全性的有力支持,数据同步更加安心。
如图9所示,为一实施例的异构数据库之间数据同步系统模块图。该系统900包括:
元数据采集模块902,用于采集源数据库中各表的元数据。
元数据检验模块904,用于根据所述源数据库和所述目标数据库之间的差异对所述元数据进行检验;其中,所述源数据库和所述目标数据库为异构数据库。
转换模块906,用于当检验完成后,将所述源数据库的表结构转换为所述目标数据库的表结构。
同步模块908,用于在所述源数据库和所述目标数据库之间进行数据同步。
所述元数据检验模块904具体用于:
若源数据库中组成唯一键的列为空不影响唯一性判断,而目标数据库中组成唯一键的列为空影响唯一性判断,则将源数据库中组成唯一键的列为空的数据按照影响唯一性判断的规则删除重复数据。
所述转换模块906具体用于:
获取源数据库和目标数据库之间数据类型的映射关系;
对源数据库中的每一源表,根据其表级别信息在目标数据库中创建目标表,并将表级别信息写入目标表;
根据源表的列信息在目标表中创建列,并根据所述映射关系设置目标表各列的数据类型;
根据源表的索引和约束信息,在目标表中添加索引和约束。
所述同步模块908具体用于:
设置增量数据记录点;
对所述增量数据记录点之前的所有历史数据进行全量数据同步;
对所述增量数据记录点之后的数据进行增量数据追踪;
在所述全量数据同步完成后,对增量数据进行同步。
所述同步模块908还具体用于:
在进行增量数据追踪时,将源数据库中的数据变化封装为正向增量消息加入消息队列;
在目标数据库进行增量数据同步时,从所述消息队列中取出所述正向增量消息,并解析为增量数据后进行数据融合;
在目标数据库进行增量数据同步时,还不断记录工作检查点;
在目标数据库进行增量数据同步时,还进行自身的增量数据追踪,并将目标数据库中的数据变化封装为反向增量消息加入消息队列;
源数据库从所述消息队列中取出所述反向增量消息,并解析为增量数据后进行数据融合以对目标数据库的增量数据进行同步;
在源数据库进行增量数据同步时,还不断记录工作检查点。
所述同步模块908还具体用于:
在进行数据同步时,还进行数据校验,包括:
对源数据库中的每一条数据,将各列内容拼接为第一字符串,并计算md5值;
对同步至目标数据库的相应数据,将各列内容拼接为第二字符串,并计算md5值;
当第一字符串的md5值和第二字符串的md5值匹配时,校验通过。
所述同步模块908还具体用于:
统计增量数据被追踪的次数;
将被追踪的次数超过设定的次数阈值的增量数据标记为热点数据;
对所述热点数据进行多次校验。
上述系统900为与前述方法一一对应的模块,模块的具体功能的实现方式已在方法实施例中具体阐述,此处不再赘述。应当理解,方法实施例的具体内容可以引入系统900以对系统实施例进行支持。
此外,本申请实施例还提出一种异构数据库之间数据同步设备,其包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的异构数据库之间数据同步程序,所述处理器执行所述异构数据库之间数据同步程序时实现上述的方法的步骤。
此外,本申请实施例还提出一种计算机可读存储介质,所述计算机可读存储介质上存储有上述异构数据库之间数据同步方法的程序,所述异构数据库之间数据同步方法的程序被处理器执行时实现如上所述的异构数据库之间数据同步方法的步骤。
本申请计算机可读存储介质具体实施方式与上述异构数据库之间数据同步方法的方法各实施例基本相同,在此不再赘述。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
应当注意的是,在权利要求中,不应将位于括号之间的任何参考符号构造成对权利要求的限制。单词“包含”不排除存在未列在权利要求中的部件或步骤。位于部件之前的单词“一”或“一个”不排除存在多个这样的部件。本发明可以借助于包括有若干不同部件的硬件以及借助于适当编程的计算机来实现。在列举了若干装置的单元权利要求中,这些装置中的若干个可以是通过同一个硬件项来具体体现。单词第一、第二、以及第三等的使用不表示任何顺序。可将这些单词解释为名称。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 异构数据库之间数据同步方法、系统、设备及存储介质
- 一种异构数据库之间的数据同步方法及系统