基于字典学习的高分辨率声速剖面稀疏编码及存储方法
文献发布时间:2023-06-19 11:39:06
技术领域
本发明属于三维温盐深数据的海洋声学应用技术领域,具体涉及基于字典学习的高分辨率声速剖面稀疏编码及存储方法。
背景技术
海水中的声速是对海洋中的声传播有重要影响的海洋环境参数。在海洋声学应用技术领域,开展水声场研究、水声目标探测、水声信号传播及声学性能计算评估都需要基于声速剖面所提供的相关数据进行。高精度的声速剖面更利于海洋声学的相关研究,提高各项应用的精确性,为海洋环境的反演及测试提供了有力保障。基于高分辨率海洋再分析产品所获得的高分辨率声速剖面数据量十分庞大,单个数据采样时刻下的数据文件大小为GB量级,普通的个人计算机终端难以满足长时间序列数据存储需求,阻碍了相关研究的展开。
会议论文(李倩倩,史娟.基于字典学习的声速剖面稀疏表示[A].中国声学学会水声学分会.中国声学学会水声学分会2019年学术会议论文集[C].中国声学学会水声学分会:《声学技术》编辑部,2019)聚焦了利用小范围的字典学习产生过完备字典来对声速剖面进行稀疏表示,可以更好的表征一些声速剖面的深层特性。CN110837791A公开了一种利用字典学习对声速剖面进行反演的技术,重点利用字典学习提取内在特征的能力来提高海洋反演的准确性。前述专利或研究内容从声速剖面的表示和特性发掘层面进行了一定的研究,但从前述研究内容以及实际应用分析过程中可以发现,由于海洋面积大、深度变化不规律、参数差异大,这导致在研究分析过程中往往需要面对和处理海量的基础数据,这对前述工作的成本和效率控制造成不利影响,庞大的数量也使系统对数据的读取和使用造成了很大的压力。
发明内容
本申请的目的在于,本发明创造旨在利用字典学习实现对大规模高分辨率声速剖面数据的稀疏编码的方法。该方法从全球高分辨率海洋再分析产品中获得高分辨率、长时间序列的声速剖面数据,在确保数据精度的前提下,利用训练集训练得到的过完备字典对对应海域的声速剖面进行处理得到对应的稀疏编码,从而对大规模的声速剖面数据进行压缩,为数据在海洋声学领域的其他应用提供方便快捷的读取和使用。
为实现上述目的,本申请采用如下技术方案。
基于字典学习的高分辨率声速剖面稀疏编码及存储方法基于全球高分辨率海洋再分析产品;基于全球高分辨率海洋再分析产品,该产品提供了全球海域的经纬度,不同深度的海洋温度、盐度等信息。基于字典学习的高分辨率声速剖面稀疏编码及存储方法的实现流程如下所示:
步骤1,利用全球高分辨率海洋再分析产品提供的基础数据,经过声速公式计算形成全球海域的海水声速剖面数据;
所述基础数据至少包括不同经纬度,不同深度上的海洋温度、盐度数据;
步骤2,为确保字典学习过程中训练过完备字典的精确性,参照典型声速剖面的分层特点对所有经纬度进行遍历将数据深度统一延拓至海底沉积层。
步骤3,将声速剖面数据按照不同经纬网格点下的采样时刻依次排列组合为目标矩阵,并随机选取足够数量的数据组成训练集训练过完备字典。
步骤4,利用过完备字典对原数据矩阵进行稀疏编码,选取合适的稀疏度得到对应的稀疏矩阵。
步骤5,将稀疏矩阵进行CSR存储,完成对高分辨率声速剖面的压缩。
步骤1的具体步骤如下:
步骤1.1基于全球高分辨率海洋再分析产品,对全球范围内的海域按照经纬度等间距,深度非等间距的方式进行网格划分;其中,全球高分辨率海洋再分析产品提供了对应经纬度和深度上的海水温度、盐度的基础数据;
步骤1.2利用全球高分辨率海洋再分析产品提供的基础数据,按照步骤1.1中经纬度和深度的划分结果,采用声速公式对各点的声速进行计算,得到高分辨率海洋声速剖面信息;
步骤1.3以深度作为高分辨率海洋声速剖面信息矩阵的行,以经纬度及时间信息作为高分辨率海洋声速剖面信息矩阵的列,构建待处理的高分辨率海洋声速剖面信息矩阵;
步骤2的具体步骤如下:
步骤2.1结合各列的数据分布情况对高分辨率海洋声速剖面信息矩阵中NaN的位置进行判定;找到NaN所在位置并根据声速变化规律对声速剖面进行延拓至海底沉积层的位置;形成延拓后特定时刻下特定经纬度对应的深度层数K的声速剖面;
步骤2.2对所有经纬度及时间上的声速剖面进行遍历,获得统一深度的声速剖面数据;共得到经纬度网格空间I个,数据采样时刻J个。
步骤3的具体步骤如下:
步骤3.1以步骤2.2中统一深度分层水声剖面为对象,构建特定时空维度下的声速剖面数据矩阵;所述声速剖面数据矩阵的矩阵行数为深度层数K,列数为经纬度网格空间I与数据采样时刻J的乘积;
步骤3.2从声速剖面数据矩阵的列向量中随机抽取M个作为训练集;过完备字典学习的目标函数式如下:
从M中再选取N(N>K)个列向量组成初始过完备字典,并对训练集进行OMP编码,得到训练集稀疏矩阵;
步骤3.3利用KSVD对初始过完备字典进行更新获得在训练集对应的过完备字典D,字典D为K×N的矩阵;
步骤3.4继续重复3.2和3.3的步骤直到获得满足指定误差x的过完备字典D。
步骤4的具体步骤如下:
步骤4.1利用过完备字典D对K×(IJ)的海洋声速剖面矩阵进行稀疏编码,采用OMP方法获得稀疏度为t的海洋声速剖面矩阵的稀疏矩阵X,海洋声速剖面矩阵的稀疏矩阵X的大小为N×(IJ);
步骤5具体步骤如下:
步骤5.1对海洋声速剖面矩阵的稀疏矩阵X进行压缩,具体是指:
按行遍历稀疏矩阵X的非零元素,并记录以下数据:
所有非零元素的在海洋声速剖面矩阵的稀疏矩阵X中的列号;
按行遍历稀疏矩阵X非零元素,按顺序对值进行排列;
在B中找到稀疏矩阵X中每行首非零元素所在位置记录下序号;
步骤5.2利用以下三个向量组成存储稀疏矩阵:
第一个向量,形式为为1×(K+1),其中存储步骤5.1的C中所有K个序列号,最后一位存储有非零元素总个数;
第二个向量,形式为1×(tIJ),其中存储步骤5.1的A中所有列号;
第三个向量,形式为1×(tIJ),其中存储步骤5.1的B中所有的值。
其有益效果在于:
本发明提供了基于字典学习的高分辨率声速剖面稀疏编码及存储的方法,其有益效果在于:
1、对基于全球高分辨率海洋再分析产品的大规模声速剖面数据提供了压缩存储的技术,方便数据的运用和交流;
2、通过训练集的选取,控制误差x,稀疏度t以及字典规模N等大小,针对不同运用环境可以任意控制声速剖面压缩的精度;
3、对海域声速剖面进行了字典学习,提取特定海域的相关特征,便于通过对应字典进行该海域的声速预测;
4、在确保数据的误差情况下,极大地压缩了相关数据,获得高分辨率、长时间序列声速剖面数据压缩80%以上的有益效果。
附图说明
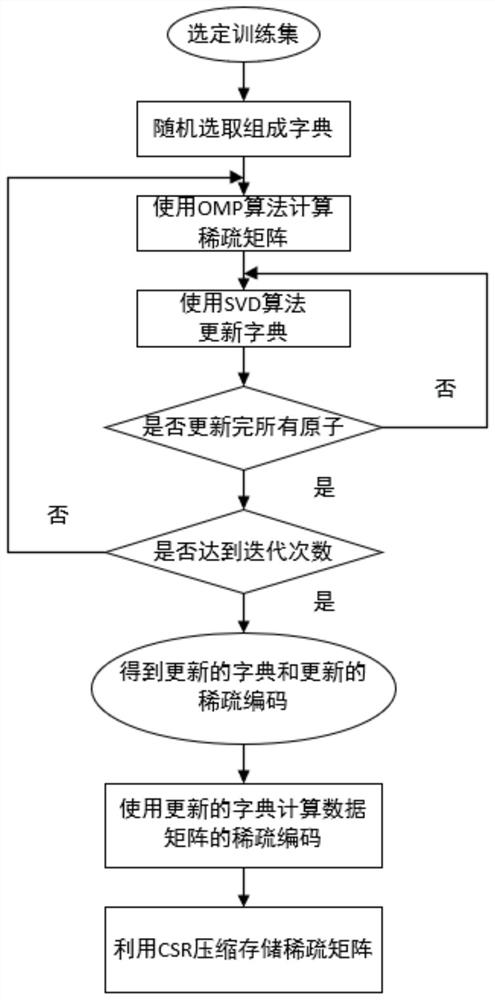
图1是本发明实施例的基于字典学习的稀疏编码及压缩流程图;
图2是本发明实施例的声速剖面原始数据图;
图3是本发明实施例的声速剖面重构数据图。
具体实施方式
以下结合具体实施例对本申请作详细说明。
为了更加直观地展现本发明在解决实际数据问题时的操作过程和展示效果,以下将结合具体数据案例和相关附图来对本发明进行更加详尽的解释说明。
本发明利用基于字典学习的高分辨率声速剖面稀疏编码及存储方法对高分辨率声速剖面数据进行大规模压缩压缩。参考图1,该图为本发明基于字典学习的高分辨率声速剖面稀疏编码及存储方法的总体操作流程图,具体步骤如下所示:
步骤1,利用全球高分辨率海洋再分析产品提供的经纬度,不同深度的海洋温度、盐度等信息,经过声速公式计算形成全球海域的海水声速剖面数据。
步骤2,为确保字典学习过程中训练过完备字典的精确性,将参照典型声速剖面的分层特点对所有经纬度进行遍历将数据深度统一延拓至海底沉积层。
步骤3,将声速剖面数据按照不同经纬网格点下的采样时刻依次排列组合为目标矩阵,并随机选取适当的数量组成训练集训练过完备字典。
步骤4,利用过完备字典对原数据矩阵进行稀疏编码,选取合适的稀疏度得到对应的稀疏矩阵。
步骤5,将稀疏矩阵进行CSR存储,完成对高分辨率声速剖面的压缩。
步骤1的具体步骤如下:
步骤1.1全球高分辨率海洋再分析产品对全球范围内的海域按照经纬度等间距网格划分,深度采用非等间距网格划分;全球高分辨率海洋再分析产品提供了对应经纬度和深度上的海水温度、盐度的相关数据;
步骤1.2通过全球高分辨率海洋再分析产品提供的数据,按照经纬度和深度的划分,采用声速公式对各点的声速进行计算,从而得到高分辨率海洋声速剖面信息;
步骤1.3以深度作为高分辨率海洋声速剖面信息矩阵的行,以经纬度及时间信息作为高分辨率海洋声速剖面信息矩阵的列,构建待处理的高分辨率海洋声速剖面信息矩阵;在陆地和海底沉积层处的声速剖面数据为缺省值状态,此处我们提取2014年176.05°E——179.95°E,41.05°N——44.95°N某海域的声速剖面数据作为分析对象,此片海区的经纬度网格空间共计40×40=1600个;根据每三小时一次测量的时间分辨率,将全年分为2920个时间点,得到1600个对应网格点均有2920个采样时刻,且深度分层共计50层;构造出高分辨率海洋声速剖面矩阵Y,矩阵的行数为垂直方向深度分层数50行,矩阵的列数为经纬度网格点数与单个经纬点采样时刻个数的乘积,即1600×2920=4762000列。
步骤2的具体步骤如下:
步骤2.1典型的声速剖面深度由浅到深,声速总体变化趋势为声速先负梯度减小再正梯度增大,据此对所得数据按列对声速剖面进行插值处理;
步骤2.2结合各列的数据分布情况对缺省位置进行判定;找到缺省值所在位置并根据声速变化规律对声速剖面数据进行延拓至海底沉积层的位置;形成延拓后特定时刻下特定经纬度对应的深度为50层的声速剖面;
步骤2.3对所有经纬度及时间上的声速剖面进行遍历,获得统一深度的声速剖面数据;该数据矩阵Y为大小是50×4762000的稠密矩阵,数据均为该经纬度下的某一深度的某一时刻声速值的大小。
步骤3的具体步骤如下:
步骤3.1以统一深度分层水声剖面为对象,构建特定时空维度下的声速剖面数据矩阵Y;矩阵行数为深度层数50,列数为经纬网格点个数1600与采样时刻数2920的乘积;
步骤3.2从矩阵中随机抽取50000个列向量作为训练集;从50000中再选取10000个列向量组成初始过完备字典D,并对训练集进行OMP编码,设定稀疏度为3,得到训练集稀疏矩阵;
步骤3.3利用KSVD算法对所得字典进行更新获得在训练集对应的过完备字典D,字典D为50×10000的矩阵;
步骤3.4继续重复3.2和3.3的步骤直到获得满足指定误差0.65的过完备字典D。
步骤4的具体步骤如下:
步骤4.1利用过完备字典D对50×10000的海洋声速剖面矩阵进行稀疏编码,获得稀疏度为3的海洋声速剖面矩阵的稀疏矩阵X,矩阵大小为10000×4762000,每列至多只有3个非零元素;
步骤5具体步骤如下:
步骤5.1对声速剖面对应的稀疏矩阵X进行压缩存储,按行遍历非零元素;记录所有非零元素的列号,每行首非零元素在遍历顺序中非零元素的序列号,非零元素的值;
步骤5.2组成三个向量存储稀疏矩阵。一个向量为1×51存储每行首非零元素的序列号,最后一位存储非零元素总个数;一个向量1×(3×非零元素个数)存储每个非零向量对应的列号;向量1×(3×非零元素个数)存储所有非零元素的值;完成对稀疏矩阵的压缩存储。
步骤5.3利用CSR存储的三个向量还原出稀疏编码矩阵X
Y
本实例中各个数据采样时刻下的声速平均误差值普遍集中在1以下,经过绝对值取总平均误差小于0.5,相对误差约为(0.5÷1500)×100%=0.03%;经过字典学习的稀疏编码压缩存储后高精度海洋声速剖面矩阵压缩率大小为88%:
当对该数据矩阵中的数据进行实际应用的时候,应当去除相关经纬度延拓的深度所对应的数据,保证数据的准确性和真实性。
最后应当说明的是,以上实施例仅用以说明本发明的技术方案,而非对本发明保护范围的限制,尽管参照较佳实施例对本发明作了详细地说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的实质和范围。
- 基于字典学习的高分辨率声速剖面稀疏编码及存储方法
- 基于嵌入式DSP的遥感图像稀疏编码字典学习方法