基于注意力机制的异构图嵌入学习方法
文献发布时间:2023-06-19 11:45:49
技术领域
本发明涉及一种基于注意力机制的异构图嵌入学习方法,属于图神经网络与人工智能领域。
背景技术
近年来,一种特殊类型的图称为异构信息图(HIN)已成为网络挖掘研究的热点。杂边和节点的异构图形代表了复杂的关系,比如推荐系统,论文引用网络等。HIN最重要的特征是元路径,它反映了节点-边缘元组中的语义关系。以论文引文网络为例,两篇论文的关系可以作为Paper-Author-Paper插图(合著者关系)和Paper-Subject-Paper(同主题关系)。从上面列出的元组中,可以看到在一个异构图中,不同的连接模式包含不同的关系,而传统的同构图深度网络无法处理异构网络中复杂的、跨模式的交互。注意力机制在深度学习中被广泛应用,它可以处理大小可变的数据,并使得模型倾向于关注数据中最显著的部分。图注意力网络(graph attention network,GAT)是一种专门用于处理图结构数据的神经网络模型,但是它只处理单一类型节点或边的非异构图。相比与同构图嵌入学习,异构图更加的复杂。
发明内容
本发明的目的是提供一种基于注意力机制的异构图嵌入学习方法,在基于自注意力以及多头注意力的基础上,结合层次注意力结构,设计了一个新的基于三层注意力机制的异构图嵌入学习模型。
为实现上述目的,本发明采用如下技术方案:
一种基于注意力机制的异构图嵌入学习方法,包括如下步骤:
步骤1,通过类型转换矩阵将异构图中的所有节点转换到统一的特征空间;
步骤2,设计类型级注意力学习给定节点对于不同类别的邻居的注意力权重;
步骤3,设计节点级注意力学习基于元路径的邻居节点注意力权重,并根据注意力权重进行加权聚合得到基于特定元路径的节点嵌入;
步骤4,设计语义级注意力学习不同元路径的注意力权重,并根据注意力权重对基于不同元路径下的节点嵌入进行加权聚合,得到最终的节点嵌入;
步骤5,对节点标签进行预测训练;
步骤6,设计损失函数,利用反向传播算法进行模型优化训练。
所述步骤1中,由于异构图中包含不同类型的节点,通过类型转换矩阵将所有节点转换到统一的特征空间:
h′
其中,M
所述步骤2包括以下步骤:
步骤21,给定节点v
步骤22,基于节点v
其中,||表示连接操作,
步骤23,通过softmax函数对所有类型的注意力分数进行规范化,获得类型级别的注意权重:
所述步骤3包括以下步骤:
步骤31,基于自注意力(self-attention)设计节点级别的注意力系数:给定通过元路径Φ连接的节点对(v
其中,att
步骤32,通过节点级别的聚合操作来学习特定语义的节点嵌入表示,每个节点的嵌入表示都是由其邻居表示加权聚合得到;
其中,
步骤33,将节点级的注意力重复计算R次,并将学习到的嵌入进行连接,学习到基于元路径Φ的嵌入表示
其中,r=1,2…R;
给定元路径集合{Φ
所述步骤4包括以下步骤:
步骤41,给定元路径集合,节点级别注意力用来学习到不同语义下的节点表示,利用语义级别注意力来学习语义的重要性并融合多个语义下的节点表示,语义级别注意力的形式化描述如下:
其中,
步骤42,给定元路径集合{Φ
步骤43,采用自注意力机制将每个节点在不同的元路径上的不同的嵌入进行聚合,首先定义三个矩阵Query Matrix Q,Key Matrix K和Value Matrix V:
依据自注意力模型self-attention model计算基于该元路径的的节点嵌入的重要性:
其中,|V|表示在元路径φ上节点的数量,d指维度大小的平方根,q是语义关系的只注意力向量;
在获得每个元路径的重要性分数后,通过softmax函数对其进行归一化,则元路径φ
所有上述参数对于所有元路径和特定于语义的嵌入都是共享的,
所述步骤5中,使用多层感知机或者是softmax函数对节点标签进行预测。
所述步骤6包括以下步骤:
步骤61,最终的节点嵌入由所有特定语义的嵌入聚合,将最终的节点嵌入应用到特定的任务中,并设计不同的损失函数;对于半监督节点分类,最小化有类标签节点的预测类标签分布与真实类标签的交叉熵:
其中,C是分类器的参数,y
步骤62,在标记数据的引导下,通过反向传播算法和学得的节点嵌入优化模型参数。
有益效果:本发明提出一种基于注意力机制的异构图嵌入学习算法,在基于自注意力以及多头注意力的基础上,结合层次注意力结构,设计了一个新的基于三层注意力机制的异构图嵌入学习模型。该模型遵循一个层次注意结构,包含类型级注意力、节点级注意力和语义级注意力。首先通过类型转换矩阵将所有节点转换到统一的特征空间,接着进入分层注意力模块,分别是类型级注意力、节点级注意力和语义级注意力,从而得到针对特定任务的内含特定语义的节点嵌入。最后通过MLP层预测节点的标签。本发明利用基于层次注意力机制的异构图嵌入模型对ACM数据集和IMDB数据集进行节点分类实验,结果表明,相对于基于深度图神经网络的模型HAN,本模型都取得更好地分类准确率,在ACM数据集上micro-f1和macro-f1分别提升了1.9%和1.85%。另外,本发明的工作为如何将注意力机制应用到异构图提供了新的研究思路。
附图说明
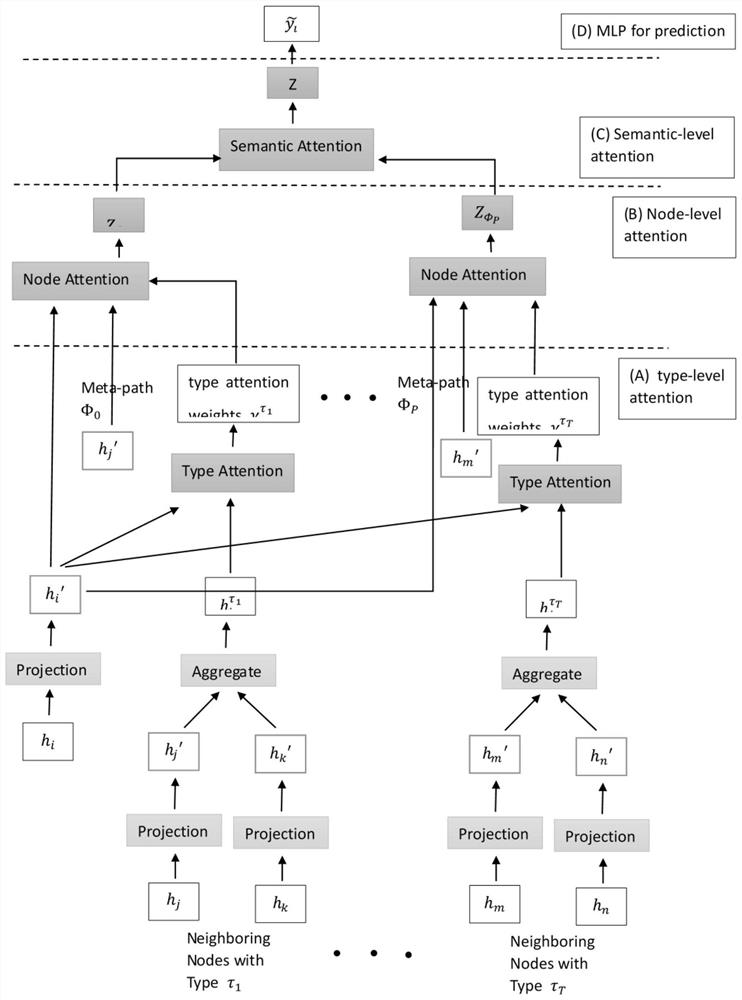
图1为基于注意力机制的异构图嵌入模型整体架构。
具体实施方式
下面结合附图及具体实施方式对本发明做进一步说明。
图1展示了本发明的整体架构。首先通过类型转换矩阵将所有节点转换到统一的特征空间,接着进入分层注意力模块。得到针对特定任务的内含特定语义的节点嵌入后,通过MLP层预测节点的标签。
首先,本发明中使用的符号总结在表1中:
表1符号及相应解释
本发明的一种基于注意力机制的异构图嵌入学习方法,包括以下步骤:
(1)通过类型转换矩阵将异构图中的所有节点转换到统一的特征空间;
由于异构图中包含不同类型的节点,所以首先通过类型转换矩阵将所有节点转换到统一的特征空间:
h′
其中M
(2)设计类型级注意力学习给定节点对于不同类别的邻居的注意力权重;
通常,给定一个特定的节点,不同类型下相邻节点可能会对其产生不同的影响。例如,相同类型的相邻节点可以携带更多有用的信息。此外,同类型下各相邻节点也可能具有不同的重要性。为此,设计了一种新的三层注意力机制。
类型级注意力可以学习到不同类别的邻居的权重系数。首先,给定节点v
之后,基于节点v
其中||表示连接操作,
之后,通过使用softmax函数对所有类型的注意得分进行规范化,获得类型级别的注意权重:
(3)设计节点级注意力学习基于元路径的邻居节点注意力权重,并根据注意力权重进行加权聚合得到基于特定元路径的节点嵌入;
在聚合每个节点的元路径邻居信息之前,可以注意到每个节点的基于元路径的邻居在特定任务的节点嵌入学习中扮演着不同的角色,并显示出不同的重要性。这里引入了节点级注意力,从而可以学习到基于元路径的邻居对于异构图中每个节点的重要性,并将这些有意义的邻居的表示聚合起来形成节点嵌入。
在具体任务中,一个节点在元路径上的邻居节点有不同的重要性。节点级注意力能够学习一个节点基于元路径的邻居节点的表示作为该节点的嵌入。基于自注意力(self-attention)来设计节点级别的注意力系数。给定通过元路径Φ连接的节点对(v
其中,att
结果表明,节点级注意力可以保持非对称性,这是异质图的一个重要性质。最后,通过节点级别的聚合操作来学习特定语义的节点嵌入表示。每个节点的嵌入表示都是由其邻居表示加权聚合得到。
其中,
由于异构图具有无标度特性,因此图数据的方差很大。为了解决上述问题,将节点级注意力扩展成使用多头注意力机制,使训练过程更加稳定。具体来说,将节点级的注意力重复计算R次,并将学习到的嵌入进行连接,学习到基于元路径Φ的嵌入表示
其中,r=1,2…R;
给定元路径集合{Φ
(4)设计语义级注意力学习不同元路径的注意力权重,并根据注意力权重对基于不同元路径下的节点嵌入进行加权聚合,得到最终的节点嵌入;
给定元路径集合,节点级别注意力用来学习到不同语义下的节点表示。进一步,可以利用语义级别注意力来学习语义的重要性并融合多个语义下的节点表示。语义级别注意力的形式化描述如下:
其中,
给定元路径集合{Φ
考虑到每个节点在不同的元路径上有不同的嵌入表示,这里考虑采用自注意力机制将它们进行聚合。首先定义三个矩阵Query Matrix Q,Key Matrix K和Value Matrix V。
依据自注意力模型self-attention model
这里|V|表示在元路径φ上节点的数量,d指维度大小的平方根,q是语义关系的只注意力向量。在获得每个元路径的重要性分数后,通过softmax函数对其进行归一化。则元路径φ
注意,为了进行有意义的比较,所有上述参数对于所有元路径和特定于语义的嵌入都是共享的。
(5)使用多层感知机或者是softmax函数对节点标签进行预测训练;
(6)设计损失函数,利用反向传播算法进行模型优化训练;
最终的嵌入由所有特定语义的嵌入聚合。然后将最终的嵌入应用到特定的任务中,并设计不同的损失函数。对于半监督节点分类,最小化有类标签节点的预测类标签分布与真实类标签的交叉熵:
其中C是分类器的参数,y
基于注意力机制的异构图嵌入学习算法伪代码如表2所示。
表2异构图嵌入模型算法流程
本发明主要使用ACM数据集和IMDB数据集来进行节点分类测试模型的分类准确率。
ACM:将发表在KDD、SIGMOD、SIGCOMM、MobiCOMM以及VLDB上的论文抓取出来,并将它们分为三类(数据库、无线通信和数据挖掘),之后构建一个异构图,其中包含3025篇文章(P),5835个作者(A)和56个主题(S),以及两种类型的元路径:PAP(文章---作者---文章)和PSP(文章---主题---文章)。论文特征为对应于关键词表示的词袋中的元素,将论文发表的会议作为它们的标签。
IMDB:这里提取IMDB的一个子集用于实验,数据集包含4780部电影(M),5841名演员(A)和2269名导演(D),以及三种类型的元路径:MAM(电影---演员---电影)和MDM(电影---导演---电影)。其中,只有电影节点存在标签,电影节点存在三种不同类型:动作片、喜剧片、戏剧。电影特征为情节关键词对应的一组词袋中的元素。
这里将数据集划分为三个部分,分别为训练集、验证集、测试集。其中对于ACM数据集,随机选取600篇论文作为训练集,300篇论文用于验证集,其余都作为测试集。对于IBDM数据集,随机选取300个电影作为训练集,300个电影用于验证集,其余都作为测试集。
对于模型设置,首先随机初始化学习参数,使用Adam算法来优化模型,另外,对于一些超参数的设置:学习速率设为0.005,L2正则化项系数为0.001,语义级注意向量q维度为128,多头注意力机制中多头数量为8,dropout丢失率为0.6,加入早停机制(验证集准确度30epoch不变,则停止训练)。为了公平起见,这里设置所有方法的嵌入为维度都为64。由于图结构数据的方差可能很大,因此重复测试20次并报告平均后的Macro-F1和Micro-F1指标。
至此便完成了基于注意力机制的异构图嵌入学习算法。
使用ACM数据集和IMDB数据集做半监督节点分类实验,首先随机初始化学习参数,使用Adam算法来优化模型,另外,对于一些超参数的设置:学习速率设为0.005,L2正则化项系数为0.001,语义级注意向量q维度为128,多头注意力机制中多头数量为8,dropout丢失率为0.6,加入早停机制(验证集准确度100epoch不变,则停止训练)。为了公平起见,这里设置所有方法的嵌入为维度都为64。由于图结构数据的方差可能很大,因此重复测试20次并报告平均后的Macro-F1和Micro-F1指标。
基于ACM数据集测试结果如表3所示。
表3基于ACM数据集测试结果
基于IMDB数据集测试结果如表4所示。
表4基于IMDB数据集测试结果
至此完成了基于ACM数据集和IMDB数据集的节点分类测试。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 基于注意力机制的异构图嵌入学习方法
- 基于视图的三维模型检索的图嵌入无监督特征学习方法