一种人脸反欺诈的深度学习方法
文献发布时间:2023-06-19 11:49:09
技术领域
本发明设计人脸识别领域,具体涉及一种人脸反欺诈的深度学习方法。
背景技术
随着社会信息技术的发展,社会对于安全验证的需求日益增长,行人重识别作为一种新型AI安全系统广泛应用于安防领域,它可以用于快速检索罪犯。而由于很多紧凑表征的行人识别方法需要使用人脸信息,这就给了犯罪嫌疑人可乘之机。犯罪嫌疑人可能使用面具去骗过系统,让系统给出完全不一样的检索结果。这种情况下,我们需要使用人脸反欺诈技术去检测该犯人的脸部的真实性,这样就有人脸反欺诈在行人重识别问题上的应用。
除了行人重识别领域,在其他领域人脸反欺诈也有很多应用,像生物识别技术中的人脸验证,现在已经广泛应用于我们现实生活中的很多场景,比如手机支付,人脸验证门锁,身份验证等。然而不幸的是这些系统有时会遭到假脸攻击,从而引发较大的安全隐患。比如手机人脸验证支付系统如果遭遇到攻击者的欺骗会造成经济上的损失等。而在当今这个信息化时代,获取到对方的”假脸”并不是一个难事,可以通过对方的朋友圈、微博、抖音等社交软件比较轻松地获取。
人脸反欺诈不仅是人脸识别/验证/检索系统的基础工作,而且对于鲁棒的行人重识别系统也很重要,所以我们认为对于该问题的研究是非常有意义的。
发明内容
为了解决现有技术的不足之处,本发明提供了以下技术方案:
一种人脸反欺诈的深度学习方法,包括以下步骤:
搭建MMCNN网络框架,允许多模态数据输入且可以充分融合其信息;
模态扩充,为了提高准确率,将原本的三模态数据通过转换其颜色空间的方式额外扩充两个模态;
计算损失函数;
真假图片不同模态定量分析,通过定量分析CISIA-SURF数据集,来判断每个模态真假脸图片的相似度。
上述的人脸反欺诈的深度学习方法,将RGB图像扩充至HSV和YCbCr两个颜色空间模态,使用ResNet-34分别逐层对几个模态的数据进行特征提取,抽出res2之后的特征,将这些特征进行连接,然后组成一组新的特征,对这组新的特征进行连接卷积。
上述的人脸反欺诈的深度学习方法,将res3之后的特征做一个SElayer,让每一个模态做通道加权;整个SElayer分为压缩和激活两部分,压缩部分对整个特征图在通道维度上做一个平均池化,激活部分通过两层全连接层让通道学习权重。
上述的人脸反欺诈的深度学习方法,所述压缩部分的公式为:
上述的人脸反欺诈的深度学习方法,所述激活部分的公式为:
s=F
其中
上述的人脸反欺诈的深度学习方法,将SEFeature进行连接,并且做连接卷积,获取一组特征为CatSEFeature,并将中层特征CatFrature与高层特征CatSEFeature做残差,之后对该特征按照顺序送入res4和res5中;在res5之后对特征做一个池化拉伸,将特征图变为1*1,之后使用一层全连接层,再对结果进行softmax分类得到真脸和假脸的评分。
上述的人脸反欺诈的深度学习方法,所述模态扩充将原始的可见光图像转变为HSV颜色空间图像和YCbCr图像,将色度和亮度分离,为整个模型提供更细节的纹理特征。
上述的人脸反欺诈的深度学习方法,所述损失函数通过扩大真脸和假脸特征的聚类中心的类间距离,来辅助交叉熵损失。
上述的人脸反欺诈的深度学习方法,所述定量分析通过对待识别人脸的若干个模态做LBP特征提取,计算每种模态LBP特征的直方图,计算直方图的卡方距离。
上述的人脸反欺诈的深度学习方法,所述计算直方图的卡方距离为:
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
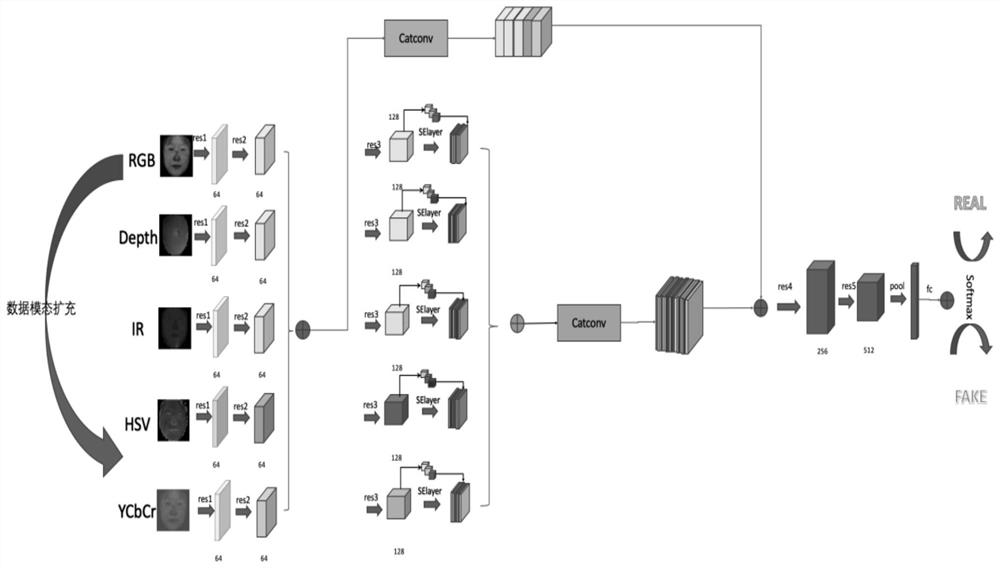
图1为本发明实施例提供的MMCNN的整体架构示意图;
图2为本发明实施例提供的ResNet结构与vgg-19对比的示意图;
图3为本发明实施例提供的SELayer结构示意图;
图4为本发明实施例提供的SELayer用于ResNetDE结构示意图;
图5为本发明实施例提供的RGB数据向HSⅤ和YcbCr模态的扩充示意图;
图6为本发明实施例提供的HSV颜色空间示意图;
图7为本发明实施例提供的HSV图像各个通道对比示意图;
图8为本发明实施例提供的真假脸YcbCr卡方距离示意图;
图9为本发明实施例提供的Push loss原理示意图;
图10为本发明实施例提供的真假脸LBP图像对比示意图;
图11为本发明实施例提供的两张真脸的LBP卡方距离示意图;
图12为本发明实施例提供的不同模态真假脸卡方距离示意图;
图13为本发明实施例提供的HSV和YcbCr各个通道的LBP卡方距离示意图;
图14为本发明实施例提供的特征图可视化示意图;
图15为本发明实施例提供的CISIA-SURF数据集攻击方式示意图;
图16为本发明实施例提供的CISIA-SURF人脸切割示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例提供的一种人脸反欺诈的深度学习方法,应用于人脸识别以及反欺诈识别。
在本发明提供的一个实施例中,所述人脸反欺诈的深度学习方法包括以下步骤:
步骤一:搭建MMCNN网络框架,允许多模态数据输入且可以充分融合其信息。
具体的,MMCNN的整体架构如图1所示,使用ResNet-34作为主体训练框架,并将ResNet-34拆开,将其分为res1-res5五个部分,如图2所示,使得提取中间层的信息让多模态数据有效地融合。
首先,将RGB图像扩充至HSV和YCbCr两个颜色空间模态,使网络更充分地获取纹理信息。之后使用ResNet-34分别逐层对几个模态的数据进行特征提取。抽出res2之后的特征(中层特征),将这些特征进行连接,然后组成一组新的特征,对这组新的特征进行连接卷积,卷积之后的特征为CatFrature。
同时,再将res3(高层特征)之后的特征做一个SElayer,如图4所示,让每一个模态做通道加权,该特征为SEFeature;
进一步的,SElayer结构示意图如3所示:
对于任意变换:U=F
其中F
则有
更进一步的,整个SElayer分为两步压缩(Squeeze)和激活(Excitation)两部分。
压缩部分:对整个特征图在通道维度上做一个平均,也就是做一个平均池化,公式如下:
这样沿着通道做加权平均相当于有了每个通道一个全局的感受野,这个信息是最浓缩的特征图。
激活部分:在得到浓缩的特征之后,SElayer目的是获得每个通道的一个权重值,让模型自动学习到通道的重要性,通过两层全连接层让通道学习权重,公式如下:
s=F
其中
将获得的通道权重值与原本的特征图相乘如下式所示:
x'=F
之后将SEFeature进行连接,并且做连接卷积,获取一组特征为CatSEFeature,并将中层特征CatFrature与高层特征CatSEFeature做残差,之后对该特征按照顺序送入res4和res5中。在res5之后对特征做一个池化拉伸,将特征图变为1*1,之后使用一层全连接层,再对结果进行softmax分类得到真脸和假脸的评分。
进一步的,如图1所示,整个特征图运算流程大小计算结果如下:
将所有输入图像大小都变为image(H*W*C)=112*112*3,送入网络,在经过res1之后,由于卷积和池化的作用,输出尺寸变为res1(H*W*C)=28*28*64;在经历了res2之后,输出为res2(H*W*C)=28*28*64,将五个模态拼接起来后特征变为cat(H*W*C)=28*28*320,之后对连接特征先试用平均池化的方法特征选择,让其特征图变为avgpool(H*W*C)=14*14*320,使用Catconv将特征图通道压缩至128维,让其大小变成CatFeature(H*W*C)=14*14*128。在res3之后,特征图大小变为res3(H*W*C)=14*14*128,由于SElayer仅仅在通道处多一个加权,并没有改变特征图大小。所以SElayer(H*W*C)=14*14*128,我们将五个高层次特征拼接起来Highcat(14*14*128)=14*14*640,经过Catconv之后将其变成CatSEFeature(14*14*128)=14*14*128。
步骤二:模态扩充,为了提高准确率,将原本的三模态(或单模态)数据通过转换其颜色空间的方式额外扩充两个模态。
上述步骤一中搭建的MMCNN网络框架的特点是允许多模态数据输入且可以充分融合其信息,多模态数据对于准确率的估计有着至关重要的作用。因为不同的模态会包含不同的信息和属性,比如可见光图片一般包含了更多的纹理细节信息,深度图片包含了面部细节对于摄像机距离的信息,这在预防图片攻击和视频攻击上非常有用,而近红外图像则提供了人脸的热辐射信息。
数据模态的扩充有助于提高准确率,将原始的可见光图像转变为HSV颜色空间图像和YCbCr图像。这两个模态将色度和亮度分离,为整个模型提供了更细节的纹理特征。如图5所示,HSV和YCbCr两种颜色空间通道可以提供有效的颜色纹理描述。
HSV是一种颜色模型,不同于传统的RGB,该模型的三个通道分别是色相(Hue),饱和度(Saturation),亮度(Value)。如图6所示,整个HSV颜色空间可以使用椎体来表示,其中色相是基本的颜色属性,只是在HSV空间中使用角度来衡量。饱和度是指颜色的艳丽程度,饱和度高表示其光谱色成分大,颜色也更艳丽。亮度表示颜色的明亮程度。使用opencv的库来将原始的RGB空间转化到HSV空间,让其新作为一个模态去给模型提供明确的色度信息和亮度信息。进一步的,如图7所示。将数据集内的真脸和假脸抽出来,并做颜色空间分解的示意图。
YCbCr是一种颜色空间,该模型包括亮度分量(Luma),蓝色色度分量(Cb),红色色度分量(Cr)。这种空间的特点是亮度信号Y与色度信号Cb,Cr分离,而人眼对亮度分量比较敏感,因此在剥离亮度分量后可以对其他两个分量进行降采样,人眼也不会轻易分辨出来,所以这种色度空间可以用作图像压缩。
如图8所示,色度分量的真假脸的卡方距离要远远超过灰度图片和亮度分量的。
步骤三:计算损失函数。
具体的,在MMCNN网络框架中,由于人脸数据反欺诈问题为一个二分类问题,且其类内间距比较小,通过将真脸和假脸特征的聚类中心“推开”,来辅助交叉熵损失,损失函数为push loss。
假设网络的逻辑层的特征F=(f
F
F
计算两个类别的聚类中心C
之后使用两个聚类中心的均方误差来将两个样本“推开”
同一般的任务一样,我们定义交叉熵损失函数来扩大类间距离
最后定义我们的损失函数为
L=a*L
其中a,b为超参数,可以调节两者的比例。
设计L
步骤四:真假图片不同模态定量分析
在此步骤中,通过定量分析CISIA-SURF数据集,来判断每个模态真假脸图片的相似度。
具体的,随机抽取三对人脸,分别对其五个模态做LBP特征特征提取(取像素点8邻域,半径范围取1)。RGB图像提取LBP特征后如图10所示;计算每种模态LBP特征的直方图,(箱数统一为N=50),然后计算直方图的卡方距离:
卡方距离越大说明真假两张脸在该模态上差距越大;
进一步的,使用两张真脸的对比结果作为基线,基线如图11所示,不同模态真假脸卡方距离如图12所示;可以看出,三组实验真假脸直方图差距最大的是深度图,基本卡方距离可以到达1000以上,而RGB图像比较平稳,大约在300左右。
为了进一步探究两个附加模态的作用,我们将两个附加模态通道拆开做了相似的实验,结果如图13所示;分析该组实验可知,亮度通道(V)和明度通道(Y)差异相对比较稳定且和RGB差异相差不大,S通道有比较好的结果。
在本发明提供的另一个实施例中,定义了一种人脸识别真伪性衡量标准,假设当前预测该样本结果为p
若p
若p
若p
若p
攻击表示分类错误率Attack Presentation Classification Error Rate
APCER=FP/(TN+FP)
正常表示分类错误率Normal Presentation Classification Error Rate
NPCER=FN/(TP+FN)
平均分类错误率Average Classification Error Rate
ACER=(APCER+NPCER)/2
假阳性错误率False Positive Rate
FPR=FP/(FP+TN)
真阳性比率True Positive Rate
TPR=TP/(TP+FN)
折半错误率Half Total Error Rate
进一步的,ROC曲线是分类问题的重要评价指标,它衡量了假阳性(Falsepositive rate)概率和真阳性(Ture positive rate)之间的平衡,曲线上的每一个点表示在不同阈值下假阳性和真阳性的值。更进一步的,还用TPR@FPR=10E-2,TPR@FPR=10E-3,TPR@FPR=10E-4来作为衡量标准之一。
在本发明提供的另一个实施例中,通过CISIA-SURF数据集实验验证MMCNN网络结构的性能。
具体的,通过输入多模态数据,包括可见光图像(RGB),深度图像(Depth)以及近红外图像(IR)的人脸数据类型;如图15所示,包含6种打印攻击方式,该数据集的攻击方式为:
Attack1:平整照片挖去眼睛;
Attack2:弯曲照片挖去眼睛;
Attack3:平整照片挖去眼睛和鼻子;
Attack4:弯曲照片挖去眼睛和鼻子;
Attack5:平整照片挖去眼睛,鼻子和嘴;
Attack6:弯曲照片挖去眼睛,鼻子和嘴。
进一步的,该数据集使用了Dlib做人脸检测,并使用PRNet去做3d重建和人脸对齐,使人脸裁剪更加完整且不受背景环境的干扰,检测过程如图16所示。通过使用交叉实验看出PushLoss和增加模态对于整个模型的作用,通过对比第三行和第五行可以看出模态增加两个颜色空间作为模态通道对于模型的精度有提升,通过引入PushLoss不但可以增强模型的精度,而且还有助于增大模型的稳定性。
以上只通过说明的方式描述了本发明的某些示范性实施例,毋庸置疑,对于本领域的普通技术人员,在不偏离本发明的精神和范围的情况下,可以用各种不同的方式对所描述的实施例进行修正。因此,上述附图和描述在本质上是说明性的,不应理解为对本发明权利要求保护范围的限制。
- 一种人脸反欺诈的深度学习方法
- 一种基于深度学习的人脸识别和人脸验证的监督学习方法