一种基于知识蒸馏和情绪集成模型的抑郁症检测方法
文献发布时间:2023-06-19 11:49:09
技术领域
本发明涉及抑郁症模型技术领域,尤其涉及一种基于知识蒸馏和情绪集成模型的抑郁症检测方法。
背景技术
随着现代社会的快速发展,人们的生活压力越来越大,非常多的人在都市生活中因为工作、家庭和经济的压力患上了抑郁症,抑郁症是一种破坏性极强的精神疾病,患有抑郁症的人对生活失去了兴趣,甚至失去了生的欲望,据不完全统计,全国抑郁患者已经达到3亿,单单在中国就有接近5000万人患有抑郁症。
随着患有抑郁症的患者越来越多,对于抑郁症的检测机制却依旧落后,现有的抑郁症检测方法主要包括基于问卷量表的方法、基于社交媒体的方法以及基于眼动仪或者脑成像等设备的检测方法;例如,Ay等人提出使用长短期记忆网络(LSTM)和卷积神经网络(CNN)来处理脑电波数据,用于抑郁症检测;然而,基于眼动仪和脑电波的方法设备成本高昂,导致病人检测的费用较高;Kohrt等人探究了基于PHQ-9抑郁症诊断标准的问卷量表对于检测抑郁症的效果;Islam等人从用户在社交媒体上发表的文本提取了词典特征,并使用决策树模型进行抑郁症检测;然而,基于问卷量表的抑郁症检测方法由于信息量不高,用户填写不够客观,导致准确率不高;基于社交媒体的抑郁症检测方法要求用户在社交媒体上需要有足够的发布内容和行为,无法处理新用户和行为稀疏的用户;另外,在现实中高质量的抑郁症数据集十分缺乏,给准确的抑郁症检测带来了挑战。
发明内容
本发明的目的是为了解决基于社交媒体的抑郁症检测方法要求用户在社交媒体上需要有足够的发布内容和行为,无法处理新用户和行为稀疏的用户的问题,而提出的一种基于知识蒸馏和情绪集成模型的抑郁症检测方法。
为了实现上述目的,本发明采用了如下技术方案:一种基于知识蒸馏和情绪集成模型的抑郁症检测方法,包括以下步骤:
(1)、对若干抑郁症相关问题的回答文本以及外部的数据集进行预处理;所述数据集为微波数据集,微博数据集根据用户在微博上填写的问答来获取用户信息,从而得到预处理好的微博文本和用户问题回答的文本。
(2)、基于步骤(1)预处理完毕的微博文本和预训练语言模型训练情绪分类模型;所述预训练语言模型为中文预训练BERT语言模型,中文预训练BERT语言模型用以预测情绪概率向量。
(3)、利用知识蒸馏将较大的情绪分类模型转化为较小的情绪分类模型;
(4)、对步骤(3)得到的情绪分类模型进一步在问答数据集训练得到抑郁检测模型;
(5)、基于步骤(3)得到的情绪模型给出的情绪得分分布,使用逻辑回归训练后得到基于情绪的抑郁分数;
(6)、基于步骤(4)得到的抑郁检测模型给出的抑郁分数和基于情绪的抑郁分数,得到最终的抑郁症检测结果。
优选的,抑郁问答数据用以计算较小的情绪模型,较小的情绪模型用以计算抑郁检测模型。
优选的,所述情绪概率向量利用逻辑回归预测抑郁标签。
与现有技术相比,本发明的优点和积极效果在于,
1、本发明中,使用中文预训练BERT语言模型预测情绪概率向量,对概率向量使用softmax归一化,计算损失函数进行模型优化。
具体而言,如图2所示,在这一步骤中,使用一个具有12层Transformer的BERT-Base模型处理输入的预处理好的文本数据,并获得每个字的隐含表示,记为H=[h
h=Hsoftmax(Hq),
其中q是模型的参数。然后,情绪的概率类别分数向量通过h进行解码,并使用softmax函数归一化如下:
其中W和b是参数。模型的损失函数计算为:
其中e
具体而言,如图2所示,在这一步骤中,本发明的一个实施例使用另一个较小的语言模型,处理同样的输入文本数据,并以类似的方式预测情绪类别分数向量,记为
通过Adam优化器对损失函数
具体而言,如图2所示,在这一步骤中,本发明的一个实施例使用抑郁问答数据进一步训练由步骤(3)得到的较小的情绪模型。该模型将每一条用户回答编码为一个隐含向量,输出一个序列
r=H
其中v是模型的参数。接下来,从该表示中解码抑郁预测概率如下:
其中w和b是模型的参数。模型训练的损失函数为:
其中y为真实的抑郁检测标签。通过Adam优化器对损失函数
具体而言,如图2所示,在这一步骤中,本发明的一个实施例使用步骤(3)得到的情绪模型给出的情绪概率分布向量,利用逻辑回归预测抑郁标签y,其计算方法如下:
其中
通过Liblinear对损失函数
具体而言,如图2所示,在这一步骤中,本发明的一个实施例集成由步骤(4)得到的抑郁检测模型给出的抑郁分数和步骤(5)得到的基于情绪的抑郁分数,其计算方式如下:
y=αz
其中系数α根据模型在验证集上的性能确定。在判决阶段,将0.5作为y的阈值,划分抑郁检测的结果。
附图说明
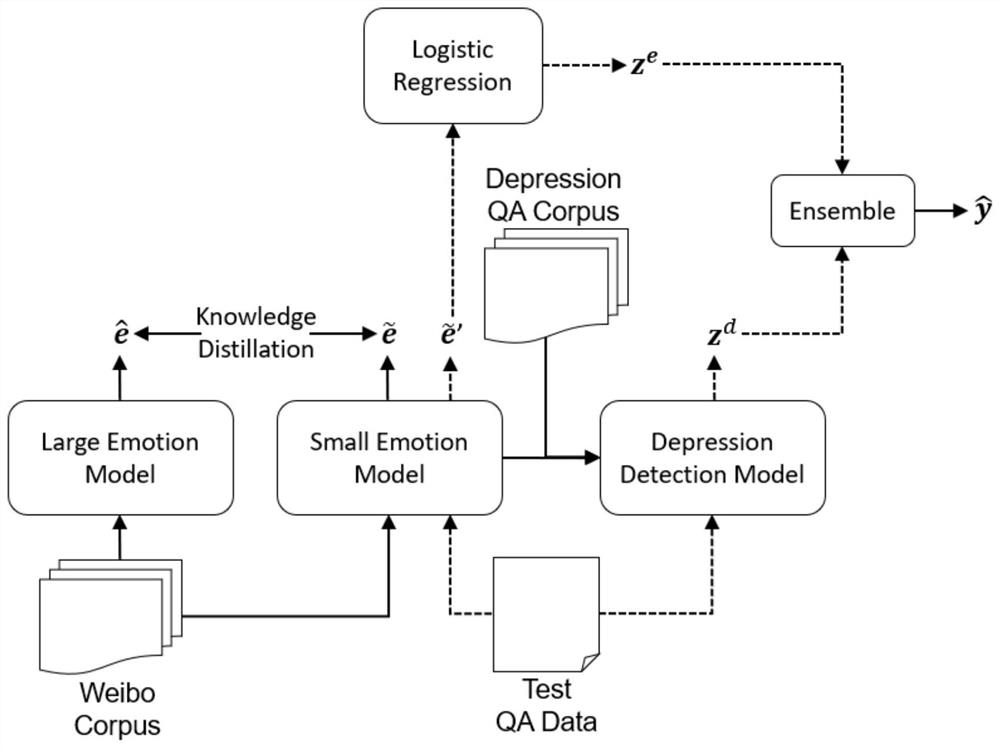
图1为本发明提出一种基于知识蒸馏和情绪集成模型的抑郁症检测方法的整体流程图;
图2为本发明提出一种基于知识蒸馏和情绪集成模型的抑郁症检测方法中实施例的工作原理图;
图3为本发明提出一种基于知识蒸馏和情绪集成模型的抑郁症检测方法的结构框图;
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和实施例对本发明做进一步说明。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用不同于在此描述的其他方式来实施,因此,本发明并不限于下面公开说明书的具体实施例的限制。
实施例1,如图1-3所示,本发明提供了一种基于知识蒸馏和情绪集成模型的抑郁症检测方法,包括以下步骤:
(1)、对若干抑郁症相关问题的回答文本以及外部的数据集进行预处理;
(2)、基于步骤(1)预处理完毕的微博文本和预训练语言模型训练情绪分类模型;
使用中文预训练BERT语言模型预测情绪概率向量,对概率向量使用softmax归一化,计算损失函数进行模型优化。
具体而言,如图2所示,在这一步骤中,使用一个具有12层Transformer的BERT-Base模型处理输入的预处理好的文本数据,并获得每个字的隐含表示,记为H=[h
h=Hsoftmax(Hq)
其中q是模型的参数。然后,情绪的概率类别分数向量通过h进行解码,并使用softmax函数归一化如下:
其中w和b是参数。模型的损失函数计算为:
其中e
(3)、利用知识蒸馏将较大的情绪分类模型转化为较小的情绪分类模型;具体而言,如图2所示,在这一步骤中,本发明的一个实施例使用另一个较小的语言模型,处理同样的输入文本数据,并以类似的方式预测情绪类别分数向量,记为
通过Adam优化器对损失函数
(4)、对步骤(3)得到的情绪分类模型进一步在问答数据集训练得到抑郁检测模型;
具体而言,如图2所示,在这一步骤中,本发明的一个实施例使用抑郁问答数据进一步训练由步骤(3)得到的较小的情绪模型。该模型将每一条用户回答编码为一个隐含向量,输出一个序列
r=H
其中v是模型的参数。接下来,从该表示中解码抑郁预测概率如下:
其中w和b是模型的参数。模型训练的损失函数为:
其中y为真实的抑郁检测标签。通过Adam优化器对损失函数
(5)、基于步骤(3)得到的情绪模型给出的情绪得分分布,使用逻辑回归训练后得到基于情绪的抑郁分数;
具体而言,如图2所示,在这一步骤中,本发明的一个实施例使用步骤(3)得到的情绪模型给出的情绪概率分布向量,利用逻辑回归预测抑郁标签y,其计算方法如下:
其中
通过Liblinear对损失函数
(6)、基于步骤(4)得到的抑郁检测模型给出的抑郁分数和基于情绪的抑郁分数,得到最终的抑郁症检测结果。
具体而言,如图2所示,在这一步骤中,本发明的一个实施例集成由步骤(4)得到的抑郁检测模型给出的抑郁分数和步骤(5)得到的基于情绪的抑郁分数,其计算方式如下:
y=αz
其中系数
如图1和图2所示,所述数据集为微波数据集,微博数据集根据用户在微博上填写的问答来获取用户信息,从而得到预处理好的微博文本和用户问题回答的文本,所述预训练语言模型为中文预训练BERT语言模型,中文预训练BERT语言模型用以预测情绪概率向量,抑郁问答数据用以计算较小的情绪模型,较小的情绪模型用以计算抑郁检测模型,所述情绪概率向量利用逻辑回归预测抑郁标签。
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作其它形式的限制,任何熟悉本专业的技术人员可能利用上述揭示的技术内容加以变更或改型为等同变化的等效实施例应用于其它领域,但是凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与改型,仍属于本发明技术方案的保护范围。
- 一种基于知识蒸馏和情绪集成模型的抑郁症检测方法
- 一种基于知识蒸馏的多模小目标检测方法