一种可配置矩阵乘法装置及算法
文献发布时间:2023-06-19 11:49:09
技术领域
本发明涉及计算技术领域,尤其是一种可配置矩阵乘法装置及算法。
背景技术
矩阵乘法运算广泛存在于图像处理、深度学习、信号处理等领域。深度学习中的卷积神经网络主要包括卷积层和全连接层,这两层的计算均可以转化为矩阵乘法运算。
现有技术中,专利CN109992743B提出了一种矩阵乘法器,包含存储器、运算电路、控制器。上述矩阵乘法器在生产或出厂之后,其所包括的M行N列的矩阵数据计算已经固定,其中的乘积累加计算器(Multiply Accumulate,MAC)中乘法器数量L也固定,计算过程中需要进行矩阵分块及数据填充补齐操作;所述矩阵乘法器设计过程中若M*N数值太小,则不能提高矩阵运算性能,即一个周期内完成矩阵乘法单元数量有限;若M*N数值太大,则增加功耗,对于较低功耗环境需求难以满足,不能动态调节,且存在数据填充补齐过程中的计算资源浪费。而且对于全连接层,结果矩阵是单列或单行,属于矩阵和向量的计算,M*N矩阵计算实际是M*1的数据计算,一个周期内只能完成M*1*L个乘法计算,即只能利用运算电路中一列来计算,不能充分利用全部乘法器,上述矩阵乘法器存在资源浪费,不适合进行全连接层的计算。
发明内容
针对上述现有矩阵计算存在的技术问题,本发明提出一种可配置矩阵乘法装置及算法。
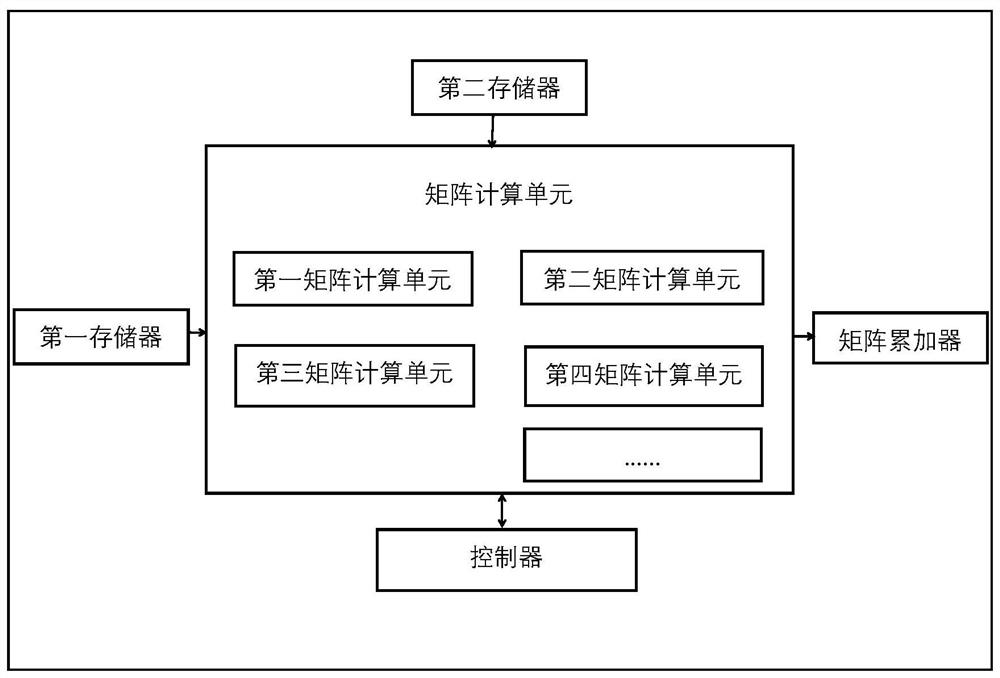
本发明保护一种可配置矩阵乘法装置,包括:运算电路、第一存储器、第二存储器和控制器,所述运算电路包括P个矩阵计算单元,并配备有矩阵累加器。所述第一存储器和所述第二存储器分别与矩阵计算单元连接,所述矩阵计算单元与矩阵累加器连接,所述控制器与矩阵计算单元双向连接。
所述第一存储器用于存储第一矩阵;所述第二存储器用于存储第二矩阵;
所述矩阵计算单元用于提取所述第一存储器和所述第二存储器中的矩阵数据并进行向量的乘法和加法运算,其包含多个乘积累加计算器,每个乘积累加计算器包含k个乘法器和k-1个加法器;
所述矩阵累加器包含多个累加单元AC,用于矩阵累加器中每个位置、每行或每列数据相加;
所述控制器用于依据预设的程序或者指令控制所述矩阵计算单元和所述矩阵累加器完成运算。
本发明还保护一种可配置矩阵乘法算法,该算法的具体运行步骤为:
步骤S1,输入第一计算矩阵到第一存储器并且输入第二计算矩阵到第二存储器,确定矩阵计算单元的使用数量。
其中,所述矩阵计算单元的使用数量,根据需求动态调整。通过矩阵运算单元组的方式,可以使得控制器根据需求选择需要采用的矩阵运算单元,配置高性能或低功耗模式。
步骤S2,根据第一计算矩阵和第二计算矩阵是否为单列或单行矩阵,第一存储器和第二存储器分别对第一计算矩阵和第二计算矩阵进行分块。
进一步地,对非单行或单列矩阵进行一次或多次分块,具体分块次数根据矩阵大小和矩阵计算单元的使用数量确定。
步骤S3,控制器在一个周期内,将第一存储器和第二存储器内的分块矩阵输入对应的矩阵计算单元,并控制矩阵计算单元进行向量的乘法和加法运算。通过利用矩阵运算单元组中全部乘法器,实现资源利用最大化。
步骤S4,将每个矩阵计算单元对应位置的计算结果送入矩阵累加器的对应位置,完成累加计算,输出最后的运算结果。
进一步地,第一计算矩阵和第二计算矩阵均为非单列或单行矩阵,每个矩阵计算单元对应位置的计算结果输入矩阵累加器的对应位置。例如:将每个矩阵计算单元的第一行第一列数值的计算结果输入矩阵累加器的第一行第一列,完成一次累加计算。
进一步地,对于第一计算矩阵是单行矩阵,将第一矩阵计算单元的第一列结果输入累加器,完成一次累加计算,第一矩阵计算单元剩余列执行相同的操作。剩余矩阵计算单元执行上述相同的操作。控制器控制矩阵累加器中的列累加器工作,将矩阵累加器中每列数据相加,完成矩阵运算。
进一步地,若第二计算矩阵为单列矩阵,将第一矩阵计算单元的第一行结果输入累加器,完成一次累加计算,第一矩阵计算单元剩余行执行相同的操作。剩余矩阵计算单元执行上述相同的操作。控制器控制矩阵累加器中的行累加器工作,将矩阵累加器中每行数据相加,完成矩阵运算。
本发明的有益效果:1、本发明通过矩阵运算单元组的方式,可以使得控制器根据需求选择需要采用的矩阵运算单元,配置高性能或低功耗模式;2、本发明可以利用矩阵运算单元组中全部乘法器,实现资源利用最大化。
附图说明
图1为一种可配置矩阵乘法装置结构图;
图2为实施例1中第一计算矩阵存储图;
图3为实施例1中第二计算矩阵存储图;
图4为实施例1中第一矩阵计算单元示意图;
图5为实施例1中乘积累加计算单元示意图;
图6为实施例1中第一计算矩阵和第二计算矩阵存储图;
图7为实施例2中第一矩阵计算单元示意图;
图8为实施例2中矩阵累加器示意图。
具体实施方式
下面结合附图和具体实施方式对本发明作进一步详细的说明。本发明的实施例是为了示例和描述起见而给出的,而并不是无遗漏的或者将本发明限于所公开的形式。很多修改和变化对于本领域的普通技术人员而言是显而易见的。选择和描述实施例是为了更好说明本发明的原理和实际应用,并且使本领域的普通技术人员能够理解本发明从而设计适于特定用途的带有各种修改的各种实施例。
实施例1
本实施例输入任意两个非单行或单列矩阵到矩阵乘法装置(主要结构如图1所示)中进行乘法运算,对本发明技术方案进行具体阐述。
步骤S1,输入第一计算矩阵W到第一存储器并且输入第二计算矩阵H到第二存储器。其中,W为4*7矩阵,H为7*4矩阵,均不是单行和单列矩阵;参见图2和图3。
根据第一计算矩阵和第二计算矩阵的大小,本实施例可以选定矩阵计算单元为2~4个,能充分利用选定的矩阵计算单元内的乘法器;每个矩阵计算单元由4行4列MAC组成;每个MAC由4个乘法器和3个加法器组成。若采用2个矩阵计算单元,配置成低功耗模式;若采用4个矩阵计算单元,配置成高性能模式。本实施例选定的矩阵计算单元的数量为P=4个。
步骤S2,第一存储器和第二存储器对W和H分为4块,分别为:
步骤S3,如图4所示,控制器在一个周期内,将第一存储器内第一分块X
步骤S4,将每个矩阵计算单元对应位置的计算结果送入矩阵累加器的对应位置,例如将每个矩阵计算单元的第一行第一列的计算结果输入矩阵累加器的第一行第一列,完成累加计算,输出最后的运算结果。
对于卷积神经网络中卷积层的运算,可以通过合理的数据调整转化为矩阵乘法运算,通过上述计算方法,能够减少运算时间,提高资源利用率。
实施例2
本实施例输入任意一个非单行或单列矩阵和一个单列矩阵到矩阵乘法装置中进行乘法运算,对本发明技术方案进行具体阐述。
步骤S1,输入第一计算矩阵W到第一存储器并且输入第二计算矩阵H到第二存储器。其中,W为4*64矩阵,H为64*1矩阵,H单列矩阵;参见图6。选定矩阵计算单元P=4个;每个矩阵计算单元由4行4列MAC组成;每个MAC由4个乘法器和3个加法器组成。
其中,矩阵计算单元的数量可以根据需求,动态调整使用数量。
步骤S2,第一存储器和第二存储器对W和H进行分块,分别为:
由于矩阵H为单列矩阵,根据选定的矩阵计算单元的数量和矩阵大小,对上述X
步骤S3,如图7所示,在一个周期内,控制器将V
一个周期内一个矩阵计算单元可以完成4*4*4次乘法计算,P=4个矩阵计算单元可完成4*4*4*4次乘法计算。若不采用该方式,而采用实施例1同样的方式,则一次只可完成4*4*4*1次乘法计算。
步骤S4,将每个矩阵计算单元对应位置的计算结果送入矩阵累加器的对应位置,矩阵计算单元计算完成,控制器将第一矩阵计算单元MAC11、MAC12、MAC13、MAC14结果输入累加器AC11,完成一次累加计算,将MAC21、MAC22、MAC23、MAC24结果输入累加器AC21,完成一次累加计算,将MAC31、MAC32、MAC33、MAC34结果输入累加器AC31,完成一次累加计算,将MAC41、MAC42、MAC43、MAC44结果输入累加器AC41,完成一次累加计算。
将第二矩阵计算单元MAC11、MAC12、MAC13、MAC14结果输入累加器AC12,完成一次累加计算,将MAC21、MAC22、MAC23、MAC24结果输入累加器AC22,完成一次累加计算,将MAC31、MAC32、MAC33、MAC34结果输入累加器AC32,完成一次累加计算,将MAC41、MAC42、MAC43、MAC44结果输入累加器AC42,完成一次累加计算。
将第三矩阵计算单元MAC11、MAC12、MAC13、MAC14结果输入累加器AC13,完成一次累加计算,将MAC21、MAC22、MAC23、MAC24结果输入累加器AC23,完成一次累加计算,将MAC31、MAC32、MAC33、MAC34结果输入累加器AC33,完成一次累加计算,将MAC41、MAC42、MAC43、MAC44结果输入累加器AC43,完成一次累加计算。
将第四矩阵计算单元MAC11、MAC12、MAC13、MAC14结果输入累加器AC14,完成一次累加计算,将MAC21、MAC22、MAC23、MAC24结果输入累加器AC24,完成一次累加计算,将MAC31、MAC32、MAC33、MAC34结果输入累加器AC34,完成一次累加计算,将MAC41、MAC42、MAC43、MAC44结果输入累加器AC44,完成一次累加计算。
控制器控制矩阵累加器中的行累加器工作,将矩阵累加器中每行数据相加,如图8所示,即将累加器AC11、AC12、AC13、AC14中的结果使能行累加器进行累加,完成一次左矩阵一行中16*4个数据和右矩阵一列中对应16*4个数据相乘运算,同理,将累加器AC21、AC22、AC23、AC24中的结果使能行累加器进行累加,将累加器AC31、AC32、AC33、AC34中的结果使能行累加器进行累加,将累加器AC41、AC42、AC43、AC44中的结果使能行累加器进行累加,输出最后的运算结果。
对于卷积神经网络中全连接层的运算,可以通过合理的数据调整转化为矩阵乘法运算,转化后的矩阵是单列或单行,属于矩阵和向量的计算。通过上述计算方法能够充分利用全部乘法器,避免资源浪费的问题,减少全连接层的运算时间。
显然,所描述的实施例仅仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域及相关领域的普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都应属于本发明保护的范围。
- 一种可配置矩阵乘法装置及算法
- 一种PHM系统的可配置算法实现装置、方法及存储介质