一种基于时序神经网络模型的欺诈用户检测系统
文献发布时间:2023-06-19 11:52:33
技术领域
本发明涉及互联网金融领域反欺诈领域,具体来说,涉及一种基于时序神经网络模型的欺诈用户检测系统。
背景技术
随着互联网的发展和普及,与互联网相结合的新兴产业也呈现出快速发展的态势。尤其是近年出现的互联网金融行业发展更是迅速。与此相伴的各种互联网金融平台和互联网金融系统也应运而生,蓬勃发展。像P2P互联网金融平台、众筹金融平台、电商小贷互联网金融平台、供应链金融互联网金融平台等等,这些平台对于优化金融游资配置,提高游资配置效率,解决中小企业融资难、融资贵的问题和中低收入散户的资产配置问题都起到了一定的积极作用。由于互联网金融平台的风险控制体系不规范、欺诈用户识别模块效果不佳,就给了“黑产”伪装成正常用户的机会。“黑产”借此来欺诈互联网金融平台,造成平台的巨大损失。
目前传统的欺诈用户识别方法大致可分为逻辑回归、GBDT、GBDT+LR 三类。上述模型将用户属性信息视为对象,将用户欺诈与否视为预测变量,提取用户年龄、用户职业情况、用户年平均收入、用户固定资产数额、以及分箱后的weight of evidence值等作为特征,然后选择随机森林、支持向量机、神经网络等构建模型。概括而言,现有方法主要基于客户的信用属性和基于专家经验的构造特征训练模型。然而,在互联网金融领域,存在着大量用户上网行为数据和通话行为数据。这些数据组成部分复杂,且所包含的信息量巨大,有产品页面停留时间、国际移动设备识别码、产品查看停留时间、IP地址、地理位置等等。面对这么大量且复杂的数据,传统的机器学习模型要想取得更好的效果,不仅需要耗费大量的时间和人力物力进行数据分析进而生成特征,而且也无法有效地学习用户行为之间的关联信息。
针对相关技术中的问题,目前尚未提出有效的解决方案。
发明内容
针对相关技术中的问题,本发明提出一种基于时序神经网络模型的欺诈用户检测系统及其挖掘方法,以克服现有相关技术所存在的上述技术问题。
本发明的技术方案是这样实现的:
根据本发明的一个方面,提供了一种基于时序神经网络模型的欺诈用户检测系统,包括:
处理模块,用于面向用户上网行为的数据处理;
提取模块,基于历史通话行为数据的特征提取;
检测模块,基于时序神经网络模型的欺诈用户检测;
修正模块,用于欺诈用户检测及修正。
优选的,上述面向用户上网行为的数据处理包括构建用户点击产品行为序列和提取反欺诈领域的传统特征。
优选的,所述构建用户点击产品行为序列基于存储于数据库的用户上网行为中,提取原始用户点击行为序列,同时丢弃最后行为不是点击产品的用户点击行为序列;
需要注意的是,每个用户点击序列的序列长度k必须是一致的(长度 k=50),对于长度小于k的点击序列在序列后面补上空点击,对于长度小于k的点击序列截取最后的k次点击行为。
优选的,所述提取反欺诈领域的传统特征基于存储于数据库的用户上网行为中,提取反欺诈领域的传统特征,特征如下:
数值型特征:页面停留时长,页面加载时长;
类别型特征:浏览器语言,文本编码设置,操作系统,设备识别码。处理方法是做one-hot和提取相对应的weight of evidence特征;
IP:找到IP对应的地理位置,对IP和位置信息做one-hot并提取相对应的K-foldmean-target编码特征;
设备识别码:提取imei码的前2、前4、前6、前8位,并进行one-hot 化;
地理信息:GPS坐标,GPS坐标聚类结果,GPS坐标与聚类中心GPS 坐标之间的欧式距离、马氏距离;
URL信息:将URL分成6块,分别是URL类型,三级类别和产品以及请求http协议头携带的IP,这有可能是下游服务器的IP;
产品类别:产品类别可能过多,one-hot会导致维度爆炸。因此,本专利先对产品类别进行one-hot化之后使用PCA、NMF、LDA等方法压缩产品类别信息。
优选的,上述基于历史通话行为数据的特征提取包括构建移动通话用户行为网络、构建移动通话用户行为矩阵和基于复杂网络理论提取特征。
优选的,所述基于时序神经网络模型的欺诈用户检测包括数据集重采样、特征选择;
所述数据集重采样由于反欺诈领域常见的正负样本不平衡,同时对样本使用过采样与欠采样来减轻数据的不平衡程度和生产新的训练集;
所述特征选择本专利对那些传统反欺诈特征的特征选择的思路是“劣汰优胜”,先基于独立性检验剔除关联弱的特征,再从剩余特征中选择重要性高的特征;
对于数值型特征,本专利使用[Cui,Hengjian&Zhong,Wei.(2018).ADistribution-Free Test of Independence and Its Application to VariableSelection.]所提出的Mean Variance Test做“劣汰”;该方法可检验一个离散型变量与一个连续型变量间是否独立,对变量的分布无假定。对于类别型特征,本专利使用卡方拟合优度检验进行特征选择。该方法可检验一个离散型变量与一个离散型变量间是否独立,同样对变量的分布无假定。
根据本发明的另一方面,提供了一种基于时序神经网络模型的欺诈用户检测方法。
包括以下步骤:
步骤S201,基于存储于数据库的用户上网行为中,提取固定序列长度k 的用户点击产品行为序列和页面停留时长和加载时长等特征。在所提取序列中,最后的行为应当为点击产品;
步骤S203,以移动通话用户为节点,基于历史通话行为数据构建动态移动通话用户行为网络。根据复杂网络理论和提取的移动通话用户行为网络,生成特征;
步骤S205,由于正负样本的不平衡,对样本进行重采样和特征选择生产训练集。基于多种时序神经网络模型学习历史数据,从而检测欺诈用户;
步骤S207,为了提高稳健性,依次采用了调和平均值、几何平均值、算数平均值、Blending(模型混合)等方法对多个时序神经网络模型结果进行模型融合。
进一步的,上述检测欺诈用户中为了提高稳健性和模型效果,本专利步骤S105得到的多种预测概率依次采用了调和平均值、几何平均值、算数平均值、Blending(模型混合)等方法对进行模型融合。
进一步的,对于“优胜”,本专利采用随机森林模型进行特征选择;随机森林模型通过bootstrap重抽样和随机特征选择机制生成多棵决策树,基于投票、加权平均等方式进行集成多棵决策树的预测结果;在进行特征选择时,具体步骤如下:
评估特征j在第i棵决策树中的重要性;先选择袋外数据评估决策树的预测错误率为e
评估特征j在随机森林模型中的重要得分;设定随机森林中有B棵树,记特征j的得分
数据归一化,将步骤S101和步骤S103的数据进行归一化处理,得到归一化后的历史数据,以便于通过归一化数据对时序神经网络进行训练。
其中,对特征X
时序神经网络模型,本专利采取了六种时序神经网络模型进行建模。其中一种时序神经网络模型包含输入层、输出层和隐含层,输入层节点数为50,输出层包含2个节点;输出层包含的2个节点分别输出欺诈用户和正常用户的概率;隐含层包含一个将点击序列encoding的Encoding层、再将Encoding的特征采用FC层embedding成1000维向量和一个RNN层;本专利选取batch size=128,将128×50×1000维矩阵输入一个LSTM层,最终通过Softmax激活函数输出欺诈概率。
其中,使用的损失函数是交叉熵损失函数:
本发明的有益效果为:考虑到欺诈用户的点击序列和正常用户的点击序列之间的显著区别,本专利提取数据库中的用户上网行为,生成固定序列长度的用户点击网页序列。为了学习历史通话行为中的信息,本发明根据复杂网络理论从历史通话行为数据提取相应的特征。进而,基于多种时序神经网络模型预测用户欺诈的概率。最终,依次采用了模型混合、调和平均值、几何平均值和算数平均值等方法对多个时序神经网络模型结果进行模型融合。克服现有技术存在的缺陷,本发明考虑了用户上网行为序列和移动通话用户网络的拓扑关联,充分利用了用户历史上网行为、用户通话行为、用户地理位置等数据,提出了一种基于时序神经网络模型的欺诈用户检测方法,有效提升了预测效果。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
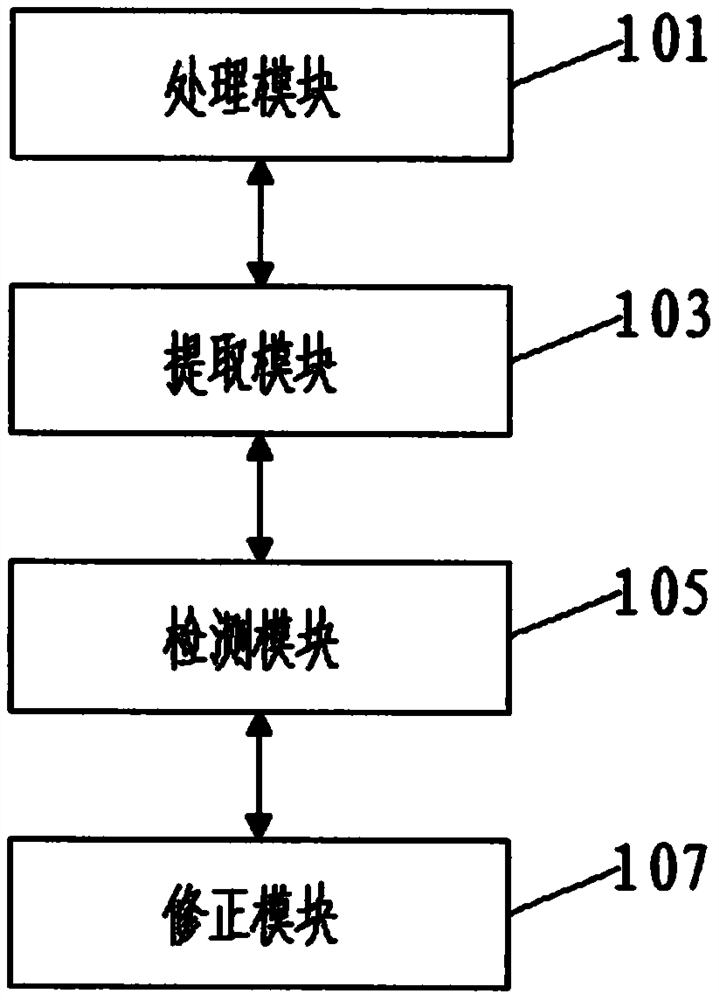
图1是根据本发明实施例的一种基于时序神经网络模型的欺诈用户检测系统的系统框图;
图2是根据本发明实施例的一种基于时序神经网络模型的欺诈用户检测方法的流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,根据本发明的实施例,提供了一种基于时序神经网络模型的欺诈用户检测系统,包括:
处理模块101,用于面向用户上网行为的数据处理;
提取模块103,基于历史通话行为数据的特征提取;
检测模块105,基于时序神经网络模型的欺诈用户检测;
修正模块107,用于欺诈用户检测及修正。
另外,在一个实施例中,对于上述面向用户上网行为的数据处理来说,上述面向用户上网行为的数据处理包括构建用户点击产品行为序列和提取反欺诈领域的传统特征。所述构建用户点击产品行为序列基于存储于数据库的用户上网行为中,提取原始用户点击行为序列,同时丢弃最后行为不是点击产品的用户点击行为序列;
需要注意的是,每个用户点击序列的序列长度k必须是一致的(长度k=50),对于长度小于k的点击序列在序列后面补上空点击,对于长度小于k的点击序列截取最后的k次点击行为。
所述提取反欺诈领域的传统特征基于存储于数据库的用户上网行为中,提取反欺诈领域的传统特征,特征如下:
数值型特征:页面停留时长,页面加载时长;
类别型特征:浏览器语言,文本编码设置,操作系统,设备识别码。处理方法是做one-hot和提取相对应的weight of evidence特征;
IP:找到IP对应的地理位置,对IP和位置信息做one-hot并提取相对应的K-foldmean-target编码特征;
设备识别码:提取imei码的前2、前4、前6、前8位,并进行one-hot 化;
地理信息:GPS坐标,GPS坐标聚类结果,GPS坐标与聚类中心GPS 坐标之间的欧式距离、马氏距离;
URL信息:将URL分成6块,分别是URL类型,三级类别和产品以及请求http协议头携带的IP,这有可能是下游服务器的IP;
产品类别:产品类别可能过多,one-hot会导致维度爆炸。因此,本专利先对产品类别进行one-hot化之后使用PCA、NMF、LDA等方法压缩产品类别信息。
另外,在一个实施例中,对于基于历史通话行为数据来说,上述基于历史通话行为数据的特征提取包括构建移动通话用户行为网络、构建移动通话用户行为矩阵和基于复杂网络理论提取特征。
构建移动通话用户行为网络
首先,从历史通话行为数据提取移动通话用户作为节点,并依据历史通话行为连接节点,具体可使用网络G=(V,L)描述。其中,V代表移动通话用户集合,V={v
构建移动通话用户行为矩阵
将所抽取数据的初始时刻作为起始时间,并按固定时段为间隔划分时段,假定有T个时段。
设Y
基于复杂网络理论提取特征包括动态移动通话用户行为网络的周期性特征、动态型移动通话用户行为网络的临时型特征、拓扑型特征反应了建模对象受阈值交互用户的影响程度和传统反欺诈特征。
动态移动通话用户行为网络的周期性特征,周期型特征体现建模对象的周期型规律,具体包括如下特征:
用户i与相关联用户在前m天内t时段通话时长的均值mean
用户i与相关联用户在前m天内t时段通话次数的均值mean
用户i与相关联用户在前m天内t时段平均通话时长的均值mean
用户i与相关联用户在前m天内t时段通话时长的中位数值median
用户i与相关联用户在前m天内t时段通话次数的中位数值median
用户i与相关联用户在前m天内t时段平均通话时长的中位数值median
用户i的median
用户i的median
用户i的median
动态型移动通话用户行为网络的临时型特征,临时型特征为建模对象较短时间内关注的变量,具体包括如下特征:
用户i与相关联用户在从t-a时段(a=1,2,…,q)到t时段通话时长的均值,共包含q个特征;
用户i与相关联用户在从t-a时段(a=1,2,…,q)到t时段通话次数的均值,共包含q个特征;
用户i与相关联用户在从t-a时段(a=1,2,…,q)到t时段平均通话时长的均值,共包含q个特征;
用户i与相关联用户在从t-a时段(a=1,2,…,q)到t时段通话时长的中位数,共包含q个特征;
用户i与相关联用户在从t-a时段(a=1,2,…,q)到t时段通话次数的中位数,共包含q个特征;
用户i与相关联用户在从t-a时段(a=1,2,…,q)到t时段平均通话时长的中位数,共包含q个特征。
用户i的median
用户i的median
用户i的median
拓扑型特征反应了建模对象受阈值交互用户的影响程度:
用户i的聚类系数;
用户i与之相关联的用户个数;
群体检测后,用户i所处社团个数;
动态移动通话用户行为网络的密度;
动态移动通话用户行为网络的直径;
动态移动通话用户行为网络的平均路径长度。
传统反欺诈特征:
用户i的学历;
用户i的年收入;
用户i的职业状况;
用户i的身体情况;
用户i的固定资产;
用户i所在公司的经营状况;
以上所有特征的weight of evidence值
另外,在一个实施例中,对于所述基于时序神经网络模型的欺诈用户检测来说,所述基于时序神经网络模型的欺诈用户检测包括数据集重采样、特征选择;
所述数据集重采样由于反欺诈领域常见的正负样本不平衡,同时对样本使用过采样与欠采样来减轻数据的不平衡程度和生产新的训练集;
所述特征选择本专利对那些传统反欺诈特征的特征选择的思路是“劣汰优胜”,先基于独立性检验剔除关联弱的特征,再从剩余特征中选择重要性高的特征;
对于数值型特征,本专利使用[Cui,Hengjian&Zhong,Wei.(2018).ADistribution-Free Test of Independence and Its Application to VariableSelection.]所提出的Mean Variance Test做“劣汰”;该方法可检验一个离散型变量与一个连续型变量间是否独立,对变量的分布无假定。对于类别型特征,本专利使用卡方拟合优度检验进行特征选择。该方法可检验一个离散型变量与一个离散型变量间是否独立,同样对变量的分布无假定。
如图2所示,根据本发明的实施例,还提供了一种基于复杂网络模型的欺诈团伙挖掘方法。
包括以下步骤:
步骤S201,基于存储于数据库的用户上网行为中,提取固定序列长度k 的用户点击产品行为序列和页面停留时长和加载时长等特征。在所提取序列中,最后的行为应当为点击产品;
步骤S203,以移动通话用户为节点,基于历史通话行为数据构建动态移动通话用户行为网络。根据复杂网络理论和提取的移动通话用户行为网络,生成特征;
步骤S205,由于正负样本的不平衡,对样本进行重采样和特征选择生产训练集。基于多种时序神经网络模型学习历史数据,从而检测欺诈用户;
步骤S207,为了提高稳健性,依次采用了调和平均值、几何平均值、算数平均值、Blending(模型混合)等方法对多个时序神经网络模型结果进行模型融合。
另外在具体应用的时候,上述检测欺诈用户中为了提高稳健性和模型效果,本专利步骤S105得到的多种预测概率依次采用了调和平均值、几何平均值、算数平均值、Blending(模型混合)等方法对进行模型融合。
如图2所示,根据本发明的实施例,还提供了在进行特征选择方法。
包括以下步骤:
评估特征j在第i棵决策树中的重要性;先选择袋外数据评估决策树的预测错误率为e
评估特征j在随机森林模型中的重要得分;设定随机森林中有B棵树,记特征j的得分
数据归一化,将步骤S101和步骤S103的数据进行归一化处理,得到归一化后的历史数据,以便于通过归一化数据对时序神经网络进行训练。
其中,对特征X
时序神经网络模型,本专利采取了六种时序神经网络模型进行建模。其中一种时序神经网络模型包含输入层、输出层和隐含层,输入层节点数为50,输出层包含2个节点;输出层包含的2个节点分别输出欺诈用户和正常用户的概率;隐含层包含一个将点击序列encoding的Encoding层、再将Encoding的特征采用FC层embedding成1000维向量和一个RNN层;本专利选取batch size=128,将128×50×1000维矩阵输入一个LSTM层,最终通过Softmax激活函数输出欺诈概率。
其中,使用的损失函数是交叉熵损失函数:
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于时序神经网络模型的欺诈用户检测系统
- 基于用户隐私保护的电信欺诈检测系统及方法