一种神经网络处理方法、加速器及存储介质
文献发布时间:2023-06-19 11:52:33
技术领域
本发明涉及终端应用领域,尤其涉及一种神经网络处理方法、加速器及存储介质。
背景技术
在神经网络的处理过程当中,需要搬动大量的数据,在数据搬动的过程当中,需要包括四个步骤:第一步,从片外存数器件(例如,DDR Memory),搬到input(输入)片内进行缓存;第二步,从片内缓存搬到计算单元进行计算;第三步,将计算结果搬到output(输出)片内进行缓存;第四步,将output片内缓存的数据搬到DDR或片内的主缓存,以进行下一步的操作;因此,数据搬运是神经网络加速处理过程中主要的功耗来源。
随着SOC(System On Chip,系统级芯片)系统的复杂程度越来越高,越来越多的神经网络应用到SOC芯片当中,因此,SOC所需要的网络带宽也随之增加;而且,在不少的应用场景当中,片外数据带宽也成为了神经网络发展的瓶颈;例如,视频类的神经网络应用中,数据带宽的需求大幅度增加,导致SOC芯片封装以及板级Boom的成本也随之增加;在不增加SOC芯片成本的情况下,降低神经网络的片外带宽需求、减少数据搬运量以及提高计算能力,是神经网络应用中需要解决的技术问题。
因此,现有技术还有待于改进和发展。
发明内容
本发明要解决的技术问题在于,针对现有技术缺陷,本发明提供一种神经网络处理方法、加速器及存储介质,通过将数据压缩算法与稀疏算法相结合,以简化神经网络加速器的处理流程,从而减少神经网络加速器片外存储器、片内输入缓存器以及片内输出缓存器的访存数据量,降低神经网络加速器的功耗。
本发明解决技术问题所采用的技术方案如下:
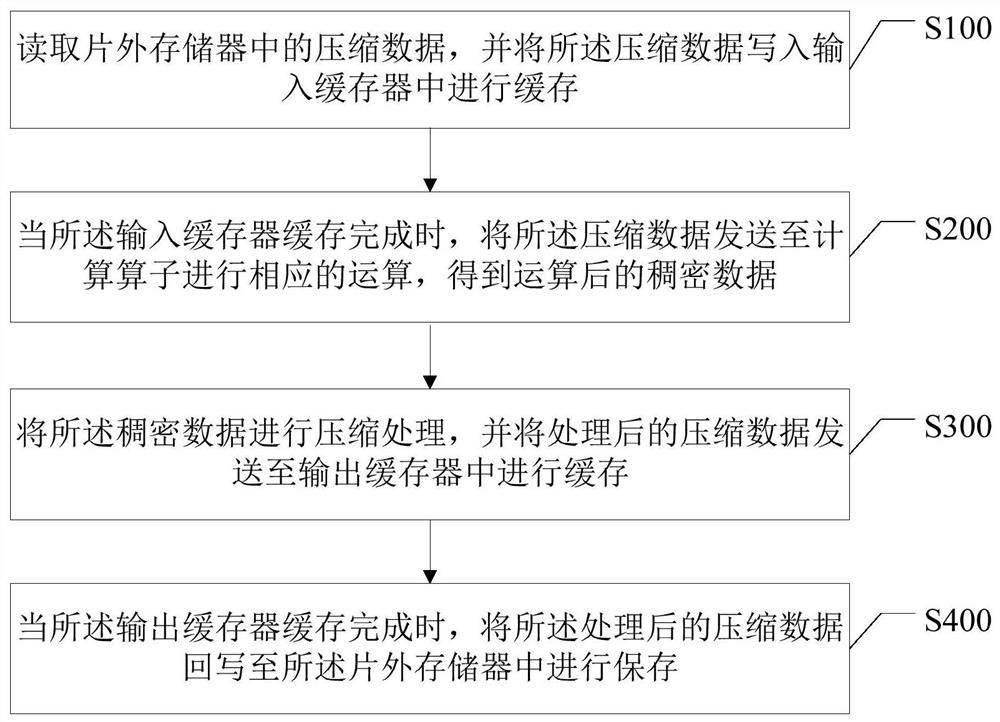
第一方面,本发明提供一种神经网络处理方法,其中,所述神经网络处理方法包括以下步骤:
读取片外存储器中的压缩数据,并将所述压缩数据写入输入缓存器中进行缓存;
当所述输入缓存器缓存完成时,将所述压缩数据发送至计算算子进行相应的运算,得到运算后的稠密数据;
将所述稠密数据进行压缩处理,并将处理后的压缩数据发送至输出缓存器中进行缓存;
当所述输出缓存器缓存完成时,将所述处理后的压缩数据回写至所述片外存储器中进行保存。
进一步地,所述读取片外存储器中的压缩数据,并将所述压缩数据写入输入缓存器中进行缓存,具体包括以下步骤:
当接收到数据读取指令时,向内存存取器发送读取请求;
控制所述内存存取器从所述片外存储器中读取所述压缩数据;
当读取到所述压缩数据时,将所述压缩数据写入所述输入缓存器的缓存区域。
进一步地,所述当所述输入缓存器缓存完成时,将所述压缩数据发送至计算算子进行相应的运算,得到运算后的稠密数据,具体包括以下步骤:
当所述输入缓存器缓存完成时,通过路径控制指令从所述输入缓存器中获取所述压缩数据,并将所述压缩数据发送至所述计算算子;
通过预设算法对所述压缩数据进行运算,并得到与所述压缩数据对应的稠密数据。
进一步地,所述当所述输入缓存器缓存完成时,通过路径控制指令从所述输入缓存器中获取所述压缩数据,并将所述压缩数据发送至所述计算算子,具体包括以下步骤:
通过所述路径控制指令从所述输入缓存器中获取索引数据,并将所述索引数据发送至所述计算算子的第一运算区域;
通过所述路径控制指令从所述输入缓存器中获取权重数据,并将所述权重数据发送至所述计算算子的第二运算区域;
通过所述路径控制指令从所述输入缓存器中获取带宽数据,并将所述带宽数据发送至所述计算算子的第三运算区域;
其中,所述索引数据、所述权重数据以及所述带宽数据均为所述压缩数据中的数据。
进一步地,所述通过预设算法对所述压缩数据进行运算,并得到与所述压缩数据对应的稠密数据,具体包括以下步骤:
根据所述权重数据从所述第三运算区域中读取带宽数据;
通过内核命令行确定所述第一运算区域的读取地址,并从所述第一运算区域中读取第一向量数据;
通过所述索引数据确定所述第二运算区域的读取地址,并从所述第二运算区域中读取第二向量数据;
将所述第一向量数据和所述第二向量数据进行相乘累加计算,得到对应的所述稠密数据。
进一步地,所述将所述稠密数据进行压缩处理,并将处理后的压缩数据发送至输出缓存器中进行缓存,具体包括以下步骤:
当运算完成时,根据压缩算法对所述稠密数据进行压缩处理;
通过缓存指令将所述处理后的压缩数据发送至所述输出缓存器,并将所述处理后的压缩数据缓存至对应的缓存区域。
进一步地,所述当所述输出缓存器缓存完成时,将所述处理后的压缩数据回写至所述片外存储器中进行保存,具体包括以下步骤:
当所述输出缓存器缓存完成时,向内存存取器发送写入请求;
控制所述内存存取器从所述输出缓存器中读取所述处理后的压缩数据;
当读取到所述处理后的压缩数据时,将所述处理后的压缩数据写入所述片外存储器中对应的存储区域。
进一步地,所述读取片外存储器中的压缩数据,并将所述压缩数据写入输入缓存器中进行缓存,之前还包括以下步骤:
预先自定义压缩算法,并根据所述自定义压缩算法对所述片外存储器中的数据进行压缩。
第二方面,本发明提供一种加速器,其中,包括处理器,以及与所述处理器连接的存储器,所述存储器存储有神经网络处理程序,所述神经网络处理程序被所述处理器执行时用于实现如第一方面所述的神经网络处理方法的操作。
第三方面,本发明提供一种存储介质,其中,所述存储介质存储有神经网络处理程序,所述神经网络处理程序被处理器执行时用于实现如第一方面所述的神经网络处理方法的操作。
本发明采用上述技术方案具有以下效果:
本发明提供一种神经网络处理方法、加速器及存储介质,通过将数据压缩算法与稀疏计算相结合,以简化神经网络加速器的处理流程,从而减少神经网络加速器片外存储器、片内输入缓存器以及片内输出缓存器的访存数据量,降低神经网络加速器的功耗,提高处理性能。
附图说明
图1是本发明神经网络处理方法的一种实现方式的流程图。
图2是现有的神经网络数据处理的通路图(方式一)。
图3是现有的神经网络数据处理的通路图(方式二)。
图4是现有的神经网络数据处理的通路图(方式三)。
图5是本发明实施例中神经网络加速器的结构示意图。
图6是本发明实施例中矩阵数据示意图。
图7是图6中矩阵数据压缩后的示意图。
图8是本发明实施例中以NCHW格式排列的示意图。
图9是图8中单行数据压缩后的示意图。
图10是图8中多行数据压缩后的示意图。
图11是图10中分块存放的示意图。
图12是本发明实施例中以2x2卷积计算的示意图。
图13是图12中第一行各点相乘的示意图。
图14是图12中各点乘积相加的示意图。
图15是本发明实施例中矩阵计算处理的示意图。
图16是图15中每个PE单元的结构示意图。
图17是本发明实施例中每个MAC单元的结构示意图。
图18是本发明实施例中每个PE单元的计算示意图。
图19是图18中虚线框中数据的放大示意图。
图20是每个PE单元每列累加的计算示意图。
图21是每个PE单元每列累加的计算示意图。
图22是本发明神经网络加速器的功能原理图。
具体实施方式
为使本发明的目的、技术方案及优点更加清楚、明确,以下参照附图并举实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
实施例一
在神经网络加速器或神经网络处理单元(NPU)中,目前主要处理数据的方式有以下三种:
第一种:稠密片外数据+稠密片上数据+稠密数据计算;
如图2所示,这种计算方式是将“非压缩数据”(即原始数据)从片外存储器(即off-chip Memory,比如:片外的DDR Memory)读出,然后进行片内输入缓存、片上稠密计算以及片内输出缓存等操作,最后将片内输出缓存中的稠密数据回写到片外存储器。
在这种计算方式当中,整个过程使用的都是稠密数据,因此,需要搬运的数据量以及计算量非常大,功耗也非常大。
第二种:稀疏数据传输+稠密片上数据+稠密数据计算;
如图3所示,这种计算方式是将压缩数据从片外存储器读出,写到片内的数据解压缩模块进行解压缩处理;然后进行片内输入缓存、片上稠密计算以及片内输出缓存等操作;最后将片内输出缓存的稠密数据进行压缩处理,以及将压缩数据回写到片外存储器。
相比于第一种计算方式,在这种计算方式当中,增加了数据解压和数据压缩的过程,而且片内输入缓存、片上稠密计算以及片内输出缓存等操作均使用的是稠密数据;虽然,降低了一定的计算量,但是,处理过程复杂,导致计算控制复杂度增加。
第三种:稀疏数据传输+稠密片上数据+稀疏数据计算;
如图4所示,这种计算方式是将压缩数据从片外存储器读出,写到片内的数据解压缩模块进行解压缩处理;然后进行片内输入缓存、片上计算以及片内输出缓存等操作;且在片上计算时,先将解压后的稠密数据进行稀疏化处理,再进行相应的运算(得到稠密数据);最后将片内输出缓存的稠密数据进行压缩处理,以及将压缩数据回写到片外存储器。
相比于第二种计算方式,在这种计算方式当中,增加了稀疏化处理的过程,可减少片上的计算量;同时,也增加了处理过程的复杂程度,导致计算控制复杂度增加。
为了简化神经网络的计算过程,降低神经网络加速器的功耗,本实施例提供一种神经网络处理方法;在本实施例中,所述的神经网络处理方法,应用于神经网络加速器或神经网络处理单元(NPU)当中,通过简化神经网络加速器的处理流程,从而减少神经网络加速器片外存储器、片内输入缓存器以及片内输出缓存器的访存数据量,降低神经网络加速器的功耗。
如图1所示,在本实施例的一种实现方式当中,所述神经网络处理方法包括以下步骤:
步骤S100,读取片外存储器中的压缩数据,并将所述压缩数据写入输入缓存器中进行缓存。
在本实施例中,如图5所示,所述神经网络加速器包括:
内存存取器,即DMA,可用于从片外存储器将数据搬到片内输入缓存器中;
矩阵缓存区A(即buf A),可用于存放feature map(特征图)压缩数据的数值,其中,buf A有多个bank(内存数据库),可以支持同时读取多个输入点;
矩阵缓存区B(即buf B),用于存放weight(权重)数据;Buf B有多个bank,可以同时读取多个向量;
矩阵缓存区N(即buf N),用于存放压缩数据的数值,是以fifo(先入先出)的方式存在;
控制单元(即Control Unit),用于控制各模块的工作;
矩阵计算单元(即Matrix Unit),可以包含一个或多个计算阵列;
输出缓存器,用于缓存输出数据。
在本实施例中,所述压缩数据为预先存储在所述片外存储器中的数据;也就是说,在输入待处理的数据之前,需要将所述片外存储器中的数据进行压缩;对于输入的待处理数据(即原始数据),采用自定义的类似CSC/CSR的压缩算法进行压缩,称之为CSCN/CSRN;其中,CSCN表示compressed sparse column with number(带压缩个数的稀疏列压缩),CSRN表示compressed sparse Row with number(带压缩个数的稀疏行压缩);将待处理数据进行压缩处理的目的在于,将待处理数据中的0除去,以减少数据搬运量。
通过CSCN/CSRN对矩阵压缩之后,包括以下三部分内容:
第一部分:Value,表示column(行)/row(列)方向上非0数值;
第二部分:col_index/row_index,表示column/row方向是的索引位置;
第三部分:col_num/row_num,表示column/row方向上非0数值的个数。
如图6所示,假如,一个矩阵包括图6所示数据;在经过CSCN压缩算法之后,则变成图7所示数据(如图7所示);在图7所示数据当中,Val(即Value)数据的位宽,由数据的类型决定,比如,矩阵数据为char(一种矩阵),则位宽为8bit(字节);Col_idx(即columnindex)/nmu(即column nmu)的位宽,由矩阵columnn的元素个数来决定,比如:column方向有16个元素,则col_idx/num的位宽为4bit;如果有n个元素时,则位宽为log2(n)。
具体地,在convolution(卷积运算)的计算中,对于feature Map(特征面),以一个行平面,或者一个列平面为一个压缩单元,进行数据压缩;下面以按行平面进行压缩为例,进行说明:
第一步:如图8所示,将feature Map以NHWC格式排列(如果按列平面进行压缩则以NWHC进行排列),图8为32个channel(通道)时的NHWC的数据排列方式;
第二步:如图9所示,从NHWC的数据里每一个行平面单独按CSCN的格式进行压缩;
第三步:如图10所示,所有行平面都按照第二步的步骤进行压缩,最后将数据进行对齐处理;
第四步:并行处理行平面的数量K,将压缩后的数据以K行为块进行分块存放,比如:K=4时,则如图11所示,每个红框为1块,进行存放;同时,将每个块对齐后,最大的行的元素个数M记录到N一起,供DMA(内存存取器)操作使用。
即在所述步骤S100之前,包括以下步骤:
步骤S001,预先自定义压缩算法,并根据所述自定义压缩算法对所述片外存储器中的数据进行压缩。
在本实施例中,在片外存储器中存储所述压缩数据之后,当所述神经网络加速器接收到数据读取指令时,则会向内存存取器发送读取请求,以控制所述内存存取器从所述片外存储器中读取所述压缩数据;进而,当所述神经网络加速器读取到所述压缩数据时,则会将所述压缩数据写入所述输入缓存器中进行缓存,从而便于计算算子随时从所述输入缓存器读取需要计算的数据。
具体地,在神经网络加速器的Control Unit(控制单元)收到host(主机)发送的任务时,会先向DMA发出请求;当DMA响应请求时,在Control Unit的控制下,会将weight数据搬到buf B,与此同时,还将压缩的val/index搬到buf A,以及将num以及每行最大长度K值搬到buf N,其中buf A、buf B以及buf N为输入缓存器的缓存区域。
需说明的是,在本实施例中,将压缩数据从off-chip Memory(片外存储器,比如:片外的DDR Memory)读出数据,写到片内的input buffer(片内输入缓存器),此步是直接复制的数据,input buffer数据格式与off-chip Memory的数据格式一致,即为压缩数据。
即在所述步骤S100当中,包括以下步骤:
步骤S110,当接收到数据读取指令时,向内存存取器发送读取请求;
步骤S120,控制所述内存存取器从所述片外存储器中读取所述压缩数据;
步骤S130,当读取到所述压缩数据时,将所述压缩数据写入所述输入缓存器的缓存区域。
本发明通过在片外存储器中存储压缩后的数据,降低了从片外存储器搬运到片内输入缓存器的数据搬运量;而且,在压缩原始数据时,通过自定义的压缩算法,使得片外存储器中的压缩数据简单化,方便了从片外存储器搬运到片内输入缓存器,同时,也使得计算算子的计算简便化。
如图1所示,在本实施例的一种实现方式当中,所述神经网络处理方法还包括以下步骤:
步骤S200,当所述输入缓存器缓存完成时,将所述压缩数据发送至计算算子进行相应的运算,得到运算后的稠密数据。
在本实施例中,当所述输入缓存器缓存完成时,所述控制单元则会将所述压缩数据发送至计算算子进行相应的运算,即将所述压缩数据送给sparse卷积计算算子模块,进行相应的运算(比如:卷积运算、联营运算等);其中,所述输入缓存器缓存完成可以是bufA、buf B以及buf N数据均缓存完成,也可以是buf A或buf B或buf N其中一个缓存区缓存完成。
在运算之后,所得到的计算结果为稠密数据(本实施例所述的稠密数据为计算后的原始数据,即计算后的带有0的数据);此时,在计算算子模块当中,可直接进行压缩处理,产生处理后的压缩数据。
具体地,Control Unit(控制单元)向RD_CTR(路径控制模块)下发控制指令,包括:en、width、Kernel、Stride、line_offset、line_base_addr、以及N_base_addr等命令行。
而当RD_CTRL收到控制信号时,且在buf A/buf B/buf N数据均缓存完成时,从N_base_addr开始执行命令,并根据Width(带宽)数量,依次从buf N读出width个数;然后,从kernel/stride命令行中获取buf A的读取地址,从而确定从buf A哪个地址开始读取数据,以及确定需要读取的乘数向量;最后,根据从buf A读取的数据中确定buf B的读取地址,并从buf B中读出与buf A相对应的乘数向量。
在得到从buf A读取的乘数向量,以及得到buf B读取的乘数向量之后,将读取的所有的乘数向量输给MAC array进行乘累加操作;其中,MAC array为1xN的矩阵阵列,可同时完成N个kernel命令行的计算。
即在所述步骤S200当中,包括以下步骤:
步骤S210,当所述输入缓存器缓存完成时,通过路径控制指令从所述输入缓存器中获取所述压缩数据,并将所述压缩数据发送至所述计算算子;
步骤S220,通过预设算法对所述压缩数据进行运算,并得到与所述压缩数据对应的稠密数据。
以下以2x2的kernel为例,如图12所示,左边为feature Map,右边为2x2的kernel,Mac Array的卷积运算过程为:
第一步,将feature Map中各个点分别与kernel的4个点相乘,分别得到4个积,如图13所示;
第二步,按feature Map的位置,将feature Map中的各个点与kernel进行排列,如图14所示;然后将相邻的4个点乘积相加,即为输出feature Map在该位置的结果;在图14当中,相同颜色表示同一个feature Map的点与kernel的乘积,r1,r2,r3,r4分别表示该input点与W1/W2/W3/W4的乘积;可见,将一个input点读进时,可与kxk个kernel的所有参数进行乘积,得到kxk个部分和。
需说明的是,在本实施例中,如图15所示,Mac Array的结构中包含N个PE Unit以及一个第二级的加法单元;其中,PE Unit的个数N的数值根据加速器要达到的算力需求来定;L2 Adder主要的作用是将PE间的部分和相加,得到最终的卷积计算结果。
如图16所示,每个PE_Unit包含一定数量的MAC Unit,具体数量根据加速器算力要求以及加速的网络的要求来定;不同的MAC unit处理的是不同的kernel。
每个MAC_Unit的结构如图17所示,图17所示的MAC_Unit主要用于加速2x2的kernel,如果是3x3的kernel则需要9个独立的reg,需要根据最大支持kernel的大小来设置加速器的reg以及MAC的数量。
具体地,Matrix Unit工作的过程包括以下步骤:
步骤1、Rd_ctrl先从Buf_N里读出1个N值(用N1表示),表示该行第1个点沿C方向是不等于0的元素个数为N1;
步骤2、从buf B里依次读出N1个d(x)以及col_index(x);
步骤3、根据col_index(x)从BUF_B里读出相应通道的一组kernel;
步骤4、将d(x)广播给所有的MAC_unit;
步骤5、将kernel(col_index(x),y)分别输给相应的MAC_Unit,与d(x)进行乘累加计算;
步骤6、循环N1次步骤2-5;
步骤7、如果完成1个kernel在W方向的计算,则将相应的reg值输出,并将reg值清0;reg输出的值将在L2_adder单元里进行行间的部分和相加计算,得到最终的结果;
步骤8、返回步骤1,继续读出N2值,继续2-6步骤,完成乘累加计算;
步骤9、直到所有W个点都参加完计算;
步骤10、下移K行,进行下一组计算。
如图18和19所示,在上述计算的过程当中,每个PE_Unit进行1行像素的计算,如图19中的虚线框。
在MAC_Unit内,每个reg负责r1/r2/r3/r4值在C方向上的累加计算,同时,也负责不同点的部分和的累加计算,如图20所示的部分。
L2_adder负责将每个PE_Unit中不同点的部分进行累加,如21所示的部分。
即在所述步骤S210当中,包括以下步骤:
步骤S211,通过所述路径控制指令从所述输入缓存器中获取索引数据,并将所述索引数据发送至所述计算算子的第一运算区域;
步骤S212,通过所述路径控制指令从所述输入缓存器中获取权重数据,并将所述权重数据发送至所述计算算子的第二运算区域;
步骤S213,通过所述路径控制指令从所述输入缓存器中获取带宽数据,并将所述带宽数据发送至所述计算算子的第三运算区域。
需说明的是,在上述步骤S211-S213当中,可同时进行,也可按照先后顺序进行,其中,所述索引数据、所述权重数据以及所述带宽数据均为所述压缩数据中的数据。
即在所述步骤S220当中,包括以下步骤:
步骤S221,根据所述权重数据从所述第三运算区域中读取带宽数据;
步骤S222,通过内核命令行确定所述第一运算区域的读取地址,并从所述第一运算区域中读取第一向量数据;
步骤S223,通过所述索引数据确定所述第二运算区域的读取地址,并从所述第二运算区域中读取第二向量数据;
步骤S224,将所述第一向量数据和所述第二向量数据进行相乘累加计算,得到对应的所述稠密数据。
本发明通过从输入缓存器中获取压缩数据,并直接进行卷积运算,简化了数据运算量;同时,在卷积运算后,直接将运算后的稠密数据进行压缩处理,使得后续的搬运数据量得到减少,从而提升了数据搬运的效率,降低了数据运算以及数据搬运所需要的功耗。
如图1所示,在本实施例的一种实现方式当中,所述神经网络处理方法还包括以下步骤:
步骤S300,将所述稠密数据进行压缩处理,并将处理后的压缩数据发送至输出缓存器中进行缓存。
在本实施例中,在经过卷积运算之后,所得到的数据为稠密数据(即运算后的原始数据),为了减少后续搬运的数据量,以及为了简化后续的数据处理步骤,需要将该稠密数据进行压缩处理。
具体地,在对卷积运算后的稠密数据进行压缩处理时,所采用的是压缩算法(此处的压缩处理的方式与片外存储器的压缩处理的方式相同),均是对稠密数据去0处理;根据卷积算子结构的不同,数据压缩后的数据内容可能有一些差异,具体的数据格式与卷积算子,以及数据格式有关;而在本实施例中,算子可以是“数据稀疏化算子”,或者是“数据+权重稀疏算子”,无论采用哪种算子,对计算效率都有很大提升;而且对于ANN网络来说,特别是残差网络来说,其数据稀疏率可达到50%以上。
而在对卷积运算产生的稠密数据进行压缩处理之后,还需要将处理后的数据发送至输出缓存器中进行缓存,以便于将缓存后的数据回写至片外存储器当中。
即在所述步骤S300当中,包括以下步骤:
步骤S310,当运算完成时,根据压缩算法对所述稠密数据进行压缩处理;
步骤S320,通过缓存指令将所述处理后的压缩数据发送至所述输出缓存器,并将所述处理后的压缩数据缓存至对应的缓存区域。
本发明以自定义压缩算法的处理方式将卷积运算后的稠密数据进行简化,让整个处理过程都是简化数据,进一步减少读、写数据的数据量,进一步优化加速器的功耗表现。
如图1所示,在本实施例的一种实现方式当中,所述神经网络处理方法还包括以下步骤:
步骤S400,当所述输出缓存器缓存完成时,将所述处理后的压缩数据回写至所述片外存储器中进行保存。
在本实施例中,当所述输出缓存器缓存完成时,即所述处理后的压缩数据都被搬运至所述输出缓存器时,即可将所述处理后的数据回写至所述片外存储器中,以将所述处理后的数据进行保存;或者,当所述输出缓存器缓存完成时,将所述处理后的数据发送至所述计算算子,以进行下一层的卷积计算。
具体地,当所述输出缓存器缓存完成时,向内存存取器发送写入请求,此过程为读取片外存储器数据的请求的逆过程;在所述内存存取器接收到所述请求时,所述神经网络加速器的控制器则会控制所述内存存取器,并控制所述内存存取器从所述输出缓存器中读取所述处理后的数据;而当读取到所述处理后的数据时,则会将所述处理后的数据写入所述片外存储器中对应的存储区域,以便于下一节点(即下一个神经网络计算节点)从所述片外存储器中获取所述处理后的数据。
即在所述步骤S400当中,包括以下步骤:
步骤S410,当所述输出缓存器缓存完成时,向内存存取器发送写入请求;
步骤S420,控制所述内存存取器从所述输出缓存器中读取所述处理后的压缩数据;
步骤S430,当读取到所述处理后的压缩数据时,将所述处理后的压缩数据写入所述片外存储器中对应的存储区域。
综上所述,本发明通过将数据压缩算法与稀疏计算相结合,以简化神经网络加速器的处理流程,从而减少神经网络加速器片外存储器、片内输入缓存器以及片内输出缓存器的访存数据量,降低神经网络加速器的功耗。
实施例二
如图22所示,本发明实施例提供了一种加速器,其中,包括处理器10,以及与所述处理器10连接的存储器20,所述存储器20存储有神经网络处理程序,所述神经网络处理程序被所述处理器10执行时用于实现如实施例一所述的神经网络处理方法的操作;具体如上所述。
实施例三
本发明实施例提供了一种存储介质,其中,所述存储介质存储有神经网络处理程序,所述神经网络处理程序被处理器执行时用于实现如实施例一所述的神经网络处理方法的操作;具体如上所述。
综上所述,本发明提供一种神经网络处理方法、加速器及存储介质,通过将数据压缩算法与稀疏计算相结合,以简化神经网络加速器的处理流程,从而减少神经网络加速器片外存储器、片内输入缓存器以及片内输出缓存器的访存数据量,降低神经网络加速器的功耗。
当然,本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关硬件(如处理器,控制器等)来完成,所述的程序可存储于一计算机可读取的存储介质中,所述程序在执行时可包括如上述各方法实施例的流程。其中所述的存储介质可为存储器、磁碟、光盘等。
应当理解的是,本发明的应用不限于上述的举例,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 一种神经网络处理方法、加速器及存储介质
- 一种神经网络加速器及数据处理方法