一种基于门控注意力和交互LSTM的代码生成方法
文献发布时间:2023-06-19 11:52:33
技术领域
本发明涉及自然语言处理领域,具体来说,本发明涉及一种针对python的代码生成方法。
背景技术
互联网技术、人工智能的发展给软件开发带来了新的机遇。开源状态下数以亿计的代码可以快速,免费的获得。基于大规模代码与数据,如何在节约开发成本的同时,保证开发软件的效率与质量成为值得探索的研究方向。研究者将目光放在了从自然语言到程序语言的转换,即代码生成又称为程序自动生成。自动生成代码将减轻开发者的人工工作,也使程序遵循相同规范,可读性与维护性也将大幅提升,因而得到学术界和工业界的广泛关注。
在代码生成的早期,研究者基于语法规则匹配进行了各种尝试,如组合类型语法CCG,依存组合语法DCS等。这些方法的局限性在于只适用于生成特定领域的逻辑生成。随着神经网络在机器翻译,图像识别等各方面取得突破,编码器-解码器(Seq2Seq)框架也同样逐渐崭露头角。基于该框架采用机器翻译方法可实现不同自然语言和目标语言的转换。但与自然语言相比,程序语言间往往包含着更多的结构信息。对于代码结构问题,可引入抽象语法树对代码结构进行表示,先从自然语言生成抽象语法树,结合注意力再通过语法树生成所需代码语言。但在实现不同语言间转换的时候,自然语言信息在生成代码过程中可能逐渐丢失。
发明内容:
针对目前存在的问题,本发明提出基于门控注意力和交互LSTM的代码生成方法。本发明旨在利用改进的注意力和拓展的LSTM提升生成代码的质量和准确度,步骤如下:
步骤1:采用双向GRU网络对输入信息进行编码,对信息进行正向和反向编码;
步骤1.1:GRU在保持LSTM效果的同时,减少约1/3参数量。同时正向和反向的编码方式,可以更完整地捕捉序列间各单元关联。
步骤1.2:若输入信息为(x
步骤1.3:编码器长度根据输入信息长度相应改变,因此使用各个时刻隐状态,编码信息可表示为S=(s
步骤2:采用门控注意力机制,该注意力包含GAT层和ATT层。
步骤2.1:注意力权值的改变不会带来编码信息S任何变化,不变性导致上下文向量间相似性高进而影响生成质量,引入门控注意力通过GAT层将S细分为
步骤2.2:若时间步为j,那么在S被输入到ATT层前将解码中前一单元状态c
步骤2.2.1:上述公式可分解为如下表示:
r
z
其中:c
步骤2.2.2:GAT层通过门控GRU将编码信息S经过被细化为
步骤2.3:ATT层注意力与软注意力保持一致,整体公式如下:
步骤3:采用交互LSTM网络作为模型解码器,交互LSTM为原始LSTM的拓展。
步骤3.1:将Python语法规则:引入到代码生成中,每一时间步即为对语法规则的预测。
步骤3.1.1:编码器最后隐状态作为解码器的是始状态,结合门控注意力计算对应的上下文向量att
步骤3.2:注意到原始LSTM中每个门的输入att
步骤3.3:运用函数sofmax对交互LSTM输出进行动作预测p
步骤3.4:语法树生成按箭头表示生成,虚线框表示GetToken,实线框为ApplyRule。注意到图中有2个t
步骤3.5:随着动作ApplyRule和GetToken的执行,最终模型会扩展完成语法树。
步骤3.6:解码器相应的生成的语法树后,将AST转换为所需的代码表示。
附图说明:
结合附图对本发明的具体实施方式作进一步描述:
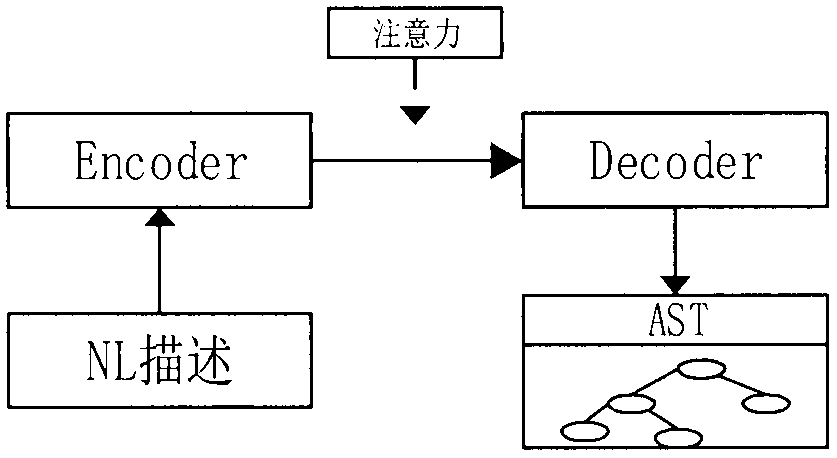
图1是基于注意力的编码器-解码器框架;
图2是python抽象语法树规则示例;
图3是本发明模型框架图;
图4是交互LSTM解码器模型图;
具体实施方式:
以下结合附图说明基于门控注意力和交互LSTM的代码生成方法实施方式。
如图1所示,本发明总体上是结合注意力的编码器-解码器模型。编码器将输入的自然语言序列进行编码,其编码为对应长度的向量。结合注意力解码器将编码后的信息解码抽象语法树的生成。
步骤1:采用双向GRU网络对输入信息进行编码,图3中的左边表示对信息进行正向和反向编码;
步骤1.1:GRU在保持LSTM效果的同时,减少约1/3参数量,同时正向和反向的编码方式,可以更完整地捕捉序列间各单元关联。
步骤1.1.1:采用one-hot编码对输入信息进行向量转换。one-hot编码后,单词将使用二进制代替,向量维度对应全部词汇。第n个词x
步骤1.2:若输入信息为(x
步骤1.3:编码器长度应根据输入信息长度相应改变,因此使用各个时刻隐状态,则编码信息可表示为S=(s
步骤2:采用门控注意力机制,如图3中间部分所示。
步骤2.1:注意权值的改变不会带来编码信息S任何变化,不变性导致上下文向量间相似性高影响生成质量,引入门控注意力通过GAT层将S细分为
步骤2.2:若时间步为j,那么在S被输入到ATT层前将解码中前一单元状态c
步骤2.2.1:上述公式可分解为如下表示:
r
z
其中:c
步骤2.2.2:GAT层通过门控GRU将编码信息S经过被细化为
步骤2.3:ATT层注意力与软注意力保持一致,整体公式如下:
步骤3:采用交互LSTM网络作为模型解码器,图3中的右边表示。
步骤3.1:将Python语法规则:引入到代码生成中,每一时间步即为对语法规则的预测如图2所示。
步骤3.1.1:编码器最后隐状态作为解码器的是始状态,结合门控注意力计算对应的上下文向量att
步骤3.2:注意到原始LSTM中每个门的输入att
步骤3.3:运用函数sofmax对交互LSTM输出进行动作预测p
p
步骤3.4:如图2所示,语法树生成按箭头表示生成,虚线框表示GetToken,实线框为ApplyRule。注意到图中有2个t
步骤3.5:随着动作ApplyRule和GetToken的执行,最终模型会扩展完成语法树。
步骤3.6:解码器相应的生成的语法树后,将AST转换为所需的代码表示。
- 一种基于门控注意力和交互LSTM的代码生成方法
- 一种基于神经网络和自注意力机制的网页截图代码生成方法