基于人体骨架和局部图像的工业包装行为识别方法
文献发布时间:2023-06-19 11:54:11
技术领域
本发明属于行为识别领域,特别是涉及基于人体骨架和局部图像的工业包装行为识别方法。
背景技术
随着国家大力倡导制造业智能化,许多大型工厂开始由传统制造向智能制造转型,视频监控是其中的必不可少的一部分,通过对车间的实时监控,收集生产数据,从而可以分析车间内的各种生产活动,以确保员工安全,防止生产步骤错误,提高生产效率。
近年来深度学习迅猛发展,目前已成功应用于计算机视觉,包括图像分类、对象检测和姿态估计等。行为识别是视频分析和智能监控领域的一项基本任务,作用是从视频中检测出正在发生的行为。由于深度学习的发展,它取得了极大的进展。当前主流的模型有基于双流网络的行为识别模型(Two-Stream CNN)和基于3D卷积神经网络是行为识别模型以及基于人体骨架的动作识别模型等。许多研究人员开始尝试如何在工业领域应用这些技术,来统计生产信息,以提高生产水平,促进产业发展。
但由于一些工厂环境复杂,现有的模型无法直接应用至某一特定生产场景,并且现有的公开数据集大多不是基于工业场景,工业数据集缺乏,采集数据集相对困难,导致想要训练一个准确度较高的模型尤为困难,且容易过拟合。而且在视频处理实际上计算效率很低最后,工业实际生产过程中往往由于遮挡、光线变化等原因,导致模型无法很好地识别出生产行为。且对于一些特殊的生产场景,现有主流模型无法做出准确的预测。
在某工厂的一个抽油烟机填料组装线中,工人需放置两种不同的配件(连接管道和纸箱工具,)到抽油烟机包装箱中,但工人在抓取过程中,经常会漏放某个配件,即进行伪装抓取(有抓取的动作却未放置配件)在这种场景下,现有的主流模型大多只能识别出工人的抓取动作,但无法识别出两个配件是否都放置成功,导致模型识别的准确度不高。
发明内容
本发明针对目前的技术的不足,提出一种称为基于人体骨架和局部图像的工业包装行为识别方法。
本发明方法的大体思想是:
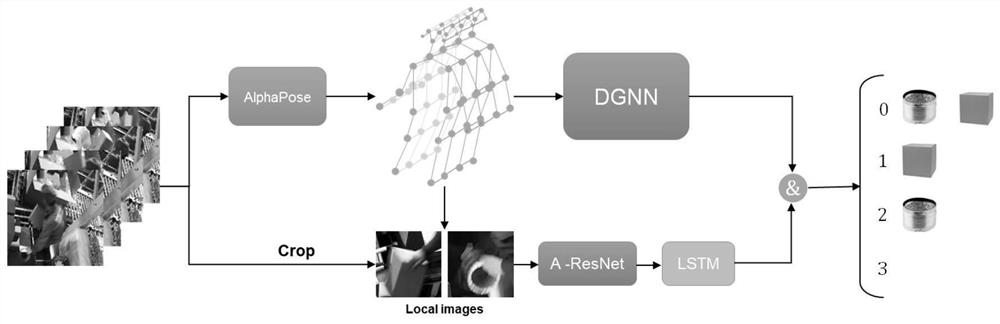
首先使用姿态估计算法模型AlphaPose对监控画面中的工人进行骨架提取,获得含有多个连续骨架信息的骨架序列,再将骨架序列数据输入至一个有向图神经网络(DGNN)来预测当前工人的行为,同时根据AlphaPose估计的骨骼关节中手腕的位置对原图进行裁剪并得到两个局部图像(左手腕周围以及右手腕周围),并分别将对应数量的左右手的局部图像输入至一个融合注意力机制模块的分类网络A-ResNet来获取特征矩阵,再分别将对应数量左右手的特征矩阵输入至长短期记忆网络模型LSTM进行分类。根据DGNN和LSTM的结果来判定两种不同的配件是否都已装箱成功。
本发明方法的具体步骤是:
步骤(1)将从实际生产场景中获取大量生产视频,将这些视频制作为视频数据集。
步骤(2)利用步骤(1)中视频数据集,使用姿态估计算法模型AlphaPose对视频集中的工人进行骨架提取,获取骨架数据集。
步骤(3)利用步骤(2)制作的骨架数据集,对图卷积网络(DGNN)进行训练,使其能够准确地识别工人的生产行为。
步骤(4)根据步骤(2)得到的骨架数据,对骨骼关节中手腕的位置对原视频流中的每帧图像进行裁剪,得到局部图像视频数据集与局部图像数据集。
步骤(5)构建A-ResNet分类网络,利用步骤(4)得到的局部图像数据集,对网络进行训练。
步骤(6)使用步骤(5)构建的A-ResNet分类网络,删除最后一层,将其作为特征提取器,与长短期记忆网络模型LSTM连接,利用步骤(4)得到的局部图像视频数据集对LSTM网络进行训练。
步骤(7)利用训练好的各个模块,构建基于人体骨架和局部图像的识别模型,用于识别工人是否成功完成装箱。
本发明的另一个目的是提供一种电子设备,包括处理器和存储器,所述存储器存储有能够被所述处理器执行的机器可执行指令,所述处理器执行所述机器可执行指令以实现上述的方法。
本发明的又一个目的是提供一种机器可读存储介质,该机器可读存储介质存储有机器可执行指令,该机器可执行指令在被处理器调用和执行时,机器可执行指令促使处理器实现上述的方法。
本发明的有益效果:与现有的各种动作识别模型相比较,本发明所提供的基于人体骨架和局部图像的工业包装行为识别方法主要有几点创新:1)使用姿态估计算法AlphaPose与有向图神经网络(DGNN)来识别工人的行为;2)使用融合通道注意力机制的分类网络A-ResNet来提取局部图像视频的特征矩阵;3)使用长短期记忆网络模型LSTM对局部图像视频特征矩阵进行分类;4)结合工人动作识别和局部图像视频分类结果共同完成行为识别。
使用姿态估计算法AlphaPose的主要依据是可以提取工人的骨架数据,并配合图卷积网络(DGNN)能够很好地识别工人的行为,并且通过骨架数据获取工人左右手腕坐标来进行图像裁剪。使用融合通道注意力机制模块的分类网络能够增强模型的理解能力,更好地提取图像的特征矩阵,并通过长短期记忆网络模型LSTM对局部图像视频特征矩阵进行分类,在识别工人行为的同时,还能检测到工人手上是否有配件,能够有效识别“假装抓取”这一欺骗性行为。该模型的提出,很好地结合了行为识别和图像视频分类,并且该模型可以端到端的进行。
本发明解决了工业生产包装过程中装箱动作识别困难的问题,利用了局部图像视频,能够准确识别工人的生产行为。
附图说明
图1为本发明提出的模型方法的总体结构图。
图2为本发明提出的A-ResNet的网络结构图。
图3为本发明提出的通道注意力机制模块Atte的网络结构图
具体实施方式
下面结合具体实施例和附图对本发明做进一步的分析。
基于人体骨架和局部图像的工业包装行为识别方法,如图1包括以下步骤:
步骤(1)、将从实际生产场景中获取大量生产视频,将这些视频制作为带有行为标签的视频数据集,具体工作如下:
(1.1)将大量生产视频以一个行为周期为划分,切割为大量的较短的视频片段;
(1.2)对这些视频片段进行行为标签的分类标注,制作为视频数据集;
行为标签主要分为五种:全部抓取(对配件A、B进行包装)、部分抓取1(只对配件A进行包装)、部分抓取2(只对配件B进行包装)、伪装抓取(进行包装动作但未放置配件)、其它动作。配件A、B为相互配对的配件。
步骤(2)、并利用步骤(1)中视频数据集,使用姿态估计算法模型AlphaPose对视频集中的工人进行骨架提取,获取骨架数据集。具体工作如下:
(2.1)将视频数据集中每个数据(即一个视频片段)的所有帧转化为序列化的视频帧;
(2.2)对这些视频帧进行缩放处理,得到视频帧集合v={I
(2.3)把这些视频帧输入至AlphaPose模型进行前向传播,获得一系列骨架序列;
(2.4)按照上述的视频数据集的划分,将骨架序列制作为骨架数据集,并对其进行行为标签的分类标注,行为标签分为抓取、其他动作,其中抓取包括视频数据集行为标签的全部抓取、部分抓取1、部分抓取2与伪装抓取。骨架数据集中一个骨架序列长度为对应视频的总帧数。
(2.5)重复步骤(2.1)至(2.4),将所有的视频数据集制作为骨架数据集。
步骤(3)、利用步骤(2)制作的骨架数据集,对图卷积网络(DGNN)进行训练,使其能够准确地识别工人的生产行为,具体工作如下:
(3.1)载入已在Kinetics-Skeleton数据集上预训练的图卷积网络DGNN;
(3.2)根据步骤(2)制作的骨架数据集,微调图卷积网络DGNN,修改DGNN的最后一层全连接层,将全连接层的输出设定为分类类别数量,此处设为2(抓取和其他动作);
(3.3)使用步骤(2)制作的骨架数据集,对图卷积网络DGNN进行训练。批次大小设为64,使用随机梯度下降(SGD)和动量(0.9)作为优化策略,学习率初始化为0.1,在第30个轮次和第60个轮次减少10倍,共训练150个轮次。
步骤(4)、利用步骤(2)得到的骨架数据集,根据骨骼关节中手腕的位置对步骤(1)视频数据集中的原始图像进行裁剪,得到局部图像数据集与局部图像视频数据集,具体工作如下:
(4.1)根据步骤(2)得到的骨架数据集,获得工人左右手腕关节点在原始图像中的对应坐标(x
(4.2)以坐标(x
(4.3)分别制作局部图像数据集与局部图像视频数据集,局部图像数据集的类别标签标注分为三类:配件A、配件B和其他。局部图像视频数据集与步骤(1)制作的视频数据集相对应,其中每一个数据的视频帧数量为步骤(1)制作的视频数据集的2倍(一张图像被分为两张左右手局部图像),局部图像视频数据集的类别标签标注分为四类:配件A(对应于部分抓取1)、配件B(对应于部分抓取2)、配件A和配件B(对应于全部抓取)、其他。
步骤(5)、构建融合注意力机制模块的分类网络A-ResNet,利用步骤(4)得到的局部图像数据集对网络进行训练,具体工作如下:
(5.1)构建A-ResNet分类网络(见图2),所述的A-ResNet分类网络是在现有ResNet18网络的基础上添加两个通道注意力机制模块;第一个通道注意力机制模块放置在ResNet18网络第一个卷积层之后,第二个通道注意力机制模块放置在ResNet18网络最后一层卷积层之后。
通道注意力机制模块Atte(见图3)构建如下:
设输入Atte模块的特征矩阵的通道数为m,Atte模块分为两个分支和一个融合模块;
第一个分支包括依次级联的平均池化层、卷积层、激活函数层、卷积层;
第一层为平均池化层,步长为1,第二层为卷积层,卷积核大小为1*1,输出通道数为输入通道数的1/16,即m/16,第三层为激活函数层ReLU层,第四层为卷积层,卷积核大小为1*1,输出通道数为m;
第二个分支包括依次级联的最大池化层、卷积层、激活函数层、卷积层;
第一层为最大池化层,步长为1,第二层为卷积层,卷积核大小为1*1,输出通道数为输入通道数的1/16,即m/16,第三层为激活函数层ReLU层,第四层为卷积层,卷积核大小为1*1,输出通道数为m。
融合模块将两个分支输出融合相加,输入至Sigmoid层,再输入至下一层;
(5.2)由于通道注意力模块,不会改变特征图的形状,因此可以将A-ResNet的部分网络模型参数初始化为在ImageNet数据集上预训练过的ResNet18的网络模型参数;
(5.3)根据步骤(4)得到局部图像数据集,微调分类网络A-ResNet,修改A-ResNet的最后一层,设定分类类别数量,此处设为3(配件A、配件B和其他);
(5.4)使用步骤(4)制作的局部图像数据集,对分类网络A-ResNet进行训练,批次大小设为32,使用Adam优化器,学习率初始化为3e-3,衰减因子设为0.7,共训练1000个轮次。
步骤(6)、使用步骤(5)获得的A-ResNet分类网络,删除最后一层,将其作为特征提取器,与长短期记忆网络模型LSTM连接,利用步骤(4)得到的局部图像视频数据集对LSTM网络进行训练,具体工作如下:
(6.1)使用步骤(5)获得的A-ResNet分类网络,删除最后的全连接层,冻结其所有参数,只将其作为特征提取器,在训练中不进行参数的更新;
(6.2)将步骤(6.1)得到的A-ResNet分类网络与长短期记忆网络模型LSTM连接,LSTM再连接一个全连接层,其中全连接层的输入设为LSTM最后一次的输出维度(此处为512),输出设为4(配件A、配件B、配件A和配件B、其他);
(6.3)使用步骤(4)制作的局部图像视频数据集,对步骤(6.2)中的模型进行训练,批次大小设为32,使用Adam优化器,学习率初始化为3e-3,衰减因子设为0.7,共训练1000个轮次。
步骤(7)、利用训练好的各个模块,构建基于人体骨架和局部图像的识别模型,用于识别工人是否成功完成装箱,具体步骤如下:
(7.1)将需要识别的视频片段转化为序列化的视频帧并进行缩放处理,得到视频帧集合;
(7.2)将所有视频帧输入至AlphaPose模型进行前向传播,获得一系列骨架序列S,单个视频帧前向传播过程可以表示为:
s
s
(7.3)将(7.2)得到的骨架序列S输入至训练好的有向图神经网络(DGNN)进行前向传播,得到对应的行为判断P,可表示为:
P=DGNN(S) (2)
其中P是概率分布,可以表示为P={p
(7.4)根据骨架序列中各个骨架的左右手腕关节位置对图像进行裁剪,得到两个固定大小局部图像,大小为224*224,共获取n张左手腕图片LI={li
(7.5)将图像集合{il
IR
其中IR
(7.6)所有图片经过A-ResNet进行前向传播,得到序列{IR
(7.7)将序列{IR
其中IR
取最后的输出O
其中Max(P1)表示P1概率分布中的最大值p1
(7.8)根据DGNN模型的预测结果F(P)以及LSTM的预测结果G(P1),来判断此次装箱是否成功将所有配件装入包装箱中:
OUT=F(P)&&G(P1) (7)
OUT为本模型的最终判定,若F(P)、G(P1)全部为TRUE,则OUT为TRUE,表示此次工人成功将所有配件装入包装箱中,否则OUT为FALSE,表示此次工人并未将所有配件装入包装箱中。
上述实施例并非是对于本发明的限制,本发明并非仅限于上述实施例,只要符合本发明要求,均属于本发明的保护范围。
- 基于人体骨架和局部图像的工业包装行为识别方法
- 骨架序列中基于局部关节点轨迹时空卷的行为识别方法