一种基于转录组测序的微卫星不稳定性检测方法
文献发布时间:2023-06-19 11:57:35
技术领域
本发明属于微卫星检测技术领域,具体涉及一种基于转录组测序的微卫星不稳定性检测方法。
背景技术
转录组测序广泛应用于科学研究和临床检测:[Stark,R.,Grzelak,M.&Hadfield,J.RNA sequencing:the teenage years.Nat Rev Genet 20,631-656,doi:10.1038/s41576-019-0150-2(2019).]
近年来,随着高通量测序的不断发展,RNA测序(RNA-Seq)技术已经日趋成熟,并广泛应用与生命科学和临床医学的研究中。RNA-seq可以鉴定差异表达基因,探究基因转录的剪接差异,检测融合基因等。近几年,随着单细胞技术的发展,转录组技术则可在单个细胞的水平上对生命体进行研究。目前单细胞转录组已经被广泛应用于人类生长发育和疾病演化的研究。除此之外,第三代测序技术,通过对单个RNA分子进行测序,可以获得基因的全长转录本,这使转录组测序技术可以全面鉴定可变剪切,发现更多新基因,准确定位融合基因。
微卫星不稳定性作为肿瘤的重要标志物已经广泛应用
微卫星(Microsatellite,也叫短串联重复,Short Tandem Repeat,STR)一般指在基因组中以1-5个碱为基本单元的重复。当细胞中与DNA错配修复系统(Mismatch RepairSystem,MMR)通路的相关基因发生失活,基因组复制产生的错配将无法得到修复。随着传代次数的增加,就会产生微卫星不稳定性(Microsatellite Instability,MSI)的表型。大量研究表明,微卫星不稳定性与肿瘤的发生有关,并在肿瘤的治疗和预后的过程中具有重要的作用。近年来,微卫星不稳定性成为了肿瘤免疫治疗中不可或缺的标志物。
现有临床的MSI检测方法的缺陷
鉴于微卫星不稳定性在临床上的重要作用,目前有大量方法用于微卫星不稳定性检测。微卫星不稳定性检测的金标准主要有MSI-PCR和MSI-IHC两种。MSI-PCR指是美国肿瘤研究所指定的检测标准,即检测两个单核苷酸重复位点(BAT-25,BAT-26)和三个二核苷酸重复位点(D2S123,D5S346,D17S250)共五个基因组微卫星位点的稳定性。MSI-PCR通过PCR扩增然后通过毛细管电泳试验对比肿瘤样本和正常对照样本在目标重复区域的拷贝数来决定微卫星位点的稳定性。根据检测样本中不稳定性位点占比(变异频率)可以将样本微卫星不稳定性状态确定为不稳定性高(MSI-H),不稳定性低(MSI-L)和稳定(MSS)三种状状态。MSI-PCR本质上是对微卫星不稳定性的超突变现象进行采样检测。MSI-IHC则通过免疫组化的方法对微卫星不稳定性相关基因,即错配修复系统基因进行检测,单这种方法试验复杂,需要又经验的专家进行实验和结果判读。这一方法本质上是对微卫星不稳定性的发生源头进行检测。
随着高通量测序的发展,市场上出现了很多基于高通量测序的微卫星不稳定性检测方法。如MSIsensor提取微卫星的突变特征进行微卫星稳定性的检测,需要肿瘤样本和正常对照样本作为输入,目前广泛应用于MSK-IMPACT等肿瘤解决检测方案中。针对这类方法对正常样本的依赖,MSIsensor-pro提出了一种多项分布模型对单个样本提取特征,实现不依赖正常对照样本的微卫星不稳定检测(文献:Jia,P.et al.MSIsensor-pro:Fast,Accurate,and Matched-normal-sample-free Detection of MicrosatelliteInstability.Genomics,Proteomics&Bioinformatics,doi:https://doi.org/10.1016/j.gpb.2020.02.001(2020).专利:叶凯et al.一种基于基因组测序的微卫星不稳定性检测系统及方法.CN109637590A.)。
以MSIsensor,MSIsensor-pro为代表的基于高通量测序的微卫星不稳定检测方案与MSI-PCR方法类似,都是提取基因突变信息来进行间接的进行MSI检测。基于高通量测序的方法可以提取样本更多的信息,获得更加准确的结果。然而各个基于高通测序的微卫星检测方法目前在阈值确定,检测位点确定方面还没有形成统一,各算法之前互相不可比,暂时无法进行标准化和规范化。
目前以MSIsensor和MSIsensor-pro为代表的基于基因组DNA测序的方法大都需要正常的对照样本,限制了微卫星不稳定性的检测范围,并且需要花费大量的时间成本和金钱成本;同时对基因组DNA测序仅仅从表现型的角度对微卫星不稳定性进行测定,并没有从其发生原因进行研究。由于各个DNA测序方案的不同,选取的微卫星检测位点不同,导致各个测序机构产生的微卫星不稳定性结果不可比,难以形成统一的检测方案,阻碍了微卫星不稳定性的标准化和规范化。
发明内容
本发明的目的是提出的一种基于转录组的微卫星不稳定性检测方法。
为实现上述目的,本发明采用的技术方案如下:
一种基于转录组测序的微卫星不稳定性检测方法,根据待测肿瘤样本获取待测肿瘤样本的特征基因的基因表达量数据,然后将数据导入检测模型进行预测,得到检测微卫星不稳定性结果,包括微卫星不稳定性阴性和微卫星不稳定性阳性。
本发明进一步的改进在于,通过基因芯片、转录组测序和单细胞转录组测序技术得到待测肿瘤样本的特征基因的基因表达量数据。
本发明进一步的改进在于,检测模型通过以下过程得到:获取用于训练检测模型的样本数据,将样本数据处理后分成训练集和测试集,将训练集导入机器学习模型中进行训练,当迭代次数大于设定阈值或损失值小于设定阈值时停止训练,得到训练好的模型;将测试集导入训练好的模型中进行预测,根据模型预测的性能指标,对预测的效果进行性能评估,得到检测模型;其中,模型预测的性能指标包括AUC、准确率、精准率和召回率;机器学习模型包括逻辑回归、随机森林、K邻近、支持向量机、决策树、梯度提升树、感知机、多层感知机和朴素贝叶斯中的一种或多种组合。
本发明进一步的改进在于,用于训练检测模型的样本数据包括样本的所有基因的基因表达量数据和样本的微卫星不稳定性状态;样本所有基因的表达量数据作为用于训练检测模型的特征,样本的微卫星不稳定性状态作为用于训练检测模型的标签。
本发明进一步的改进在于,通过基因芯片、转录组测序和单细胞转录组测序技术测得样本的所有基因的基因表达量数据。
本发明进一步的改进在于,通过毛细管电泳、免疫组化蛋白或MSIsensor方法或MSIsensor-pro方法获取样本的微卫星不稳定性状态,微卫星不稳定性状态包括微卫星不稳定性阳性和微卫星不稳定性阴性。
本发明进一步的改进在于,将样本数据处理后分成训练集和测试集的具体过程如下:首先对样本数据进行数据清洗,再进行类不平衡问题处理,然后分成两部分,对第一部分数据进行标准化操作,然后通过逻辑回归法、AUC法或差异基因法筛选特征基因,得到的特征基因的数据和样本标签作为训练集;对第二部分数据的特征进行数据标准化操作和特征基因筛选操作,得到的特征基因的数据和样本标签作为测试集。
本发明进一步的改进在于,数据清洗的具体过程为:计算每个微卫星不稳定性阳性样本和微卫星不稳定性阴性样本中每个基因表达量的平均值、标准差及变异系数,根据设置阈值过滤,过滤基因表达量异常的离群样本。
本发明进一步的改进在于,类不平衡问题处理的具体过程为:根据癌症类型对经过数据清洗处理的微卫星不稳定性阳性样本进行新微卫星不稳定性阳性样本的构造,使得每种癌症类型的微卫星不稳定性阳性样本和微卫星不稳定性阴性样本数量达到平衡;
或者对所有经过数据清洗处理的微卫星不稳定阳性样本进行新微卫星不稳定阳性样本的构造,使得总的微卫星不稳定阳性样本和微卫星不稳定阴性样本数量均衡;
数据标准化操作的具体过程为对样本数据的特征部分进行归一化或z-score标准化。
本发明进一步的改进在于,对预测的效果进行性能评估的具体过程为:设定模型预测性能指标的阈值,若测试集在训练好的模型上预测指标达到阈值,则训练结束得到检测模型;若测试集在训练好的模型上预测指标未达到阈值,则对模型参数进行调整后重新训练,再将测试集导入训练好的模型进行性能评估,直至达到阈值,得到检测模型。
与现有技术相比,本发明具有的有益效果:
本发明通过对肿瘤样本的转录组进行测序,得到的基因表达量数据为输入,再对各基因的表达情况进行分析,提取微卫星相关的基因,然后导入检测模型对微卫星不稳定性进行检测。这种方法不需要对照样本,从微卫星不稳定性发生源头进行检测,实际上是对错配修复通路进行分析,不需要确定微卫星检测位点,不需要确定阈值,可减少正常样本取样过程中给患者带来的痛苦,同时减少对患者遗传物质泄漏的风险,减少成本,检测准确率更高,在实际应用中具有更大的潜力。
附图说明
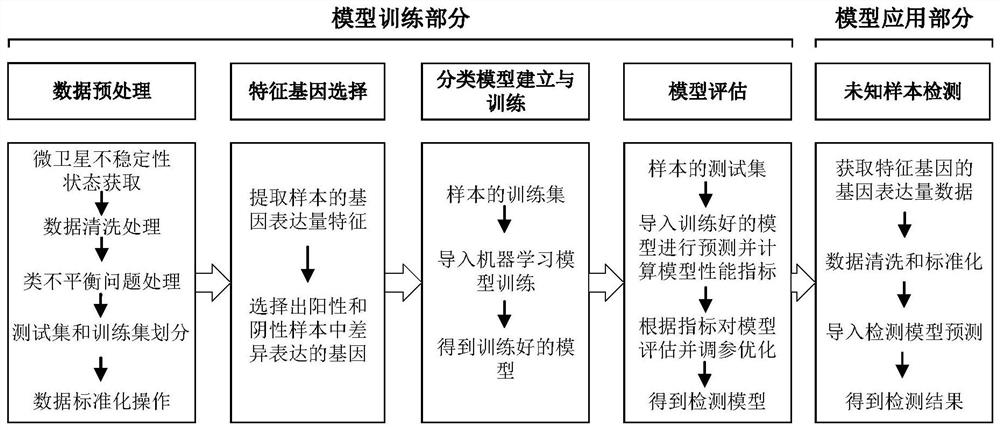
图1为基于转录组测序的微卫星检测流程图。
图2为几种机器学习模型测试集AUC比较图。
图3为调参后模型在测试集上的ROC曲线。
图4为图中方框处的放大图。
具体实施方式
下面结合附图对本发明进行详细说明。
本发明提供一种试验操作简单,成本可控,准确率高的基于转录组测序的微卫星不稳定性检测方法。本发明所述基于转录组的微卫星不稳定性检测方法分为模型训练和模型应用两个部分。
模型训练部分主要包括数据预处理,用于微卫星不稳定性检测的特征基因选择,分类模型建立与训练和模型性能评估几个过程;此部分需要准备样本转录组测序数据作为训练模型的特征和其对应的微卫星不稳定性状态作为训练模型的标签,特征和标签用于检测模型的训练和评估。模型应用部分,指依据模型训练部分得到的微卫星不稳定性检测模型结合待测样本的特征基因的转录组数据对待测样本的微卫星不稳定性状态进行预测,参见图1。
本发明提供的基于转录组测序的微卫星不稳定性检测方法通过对基因表达量的分析确定肿瘤样本的微卫星不稳定性状态。基因表达量可以通过基因芯片,转录组测序和单细胞转录组测序技术得到。其数据格式可以为Read Counts、FPKM、RPKM、TPM,也可以是它们标准化或者校正后的表达数据。在模型训练部分还需要事先获取训练样本的微卫星不稳定性状态。
数据预处理具体过程包括:获取微卫星不稳定性状态,数据清洗处理,类不平衡问题处理和数据标准化操作过程。
微卫星不稳定性状态获取主要是针对利用现有金标准方法获取样本的微卫星不稳定性状态,作为模型训练的标签,并根据样本的微卫星不稳定性状态分为微卫星不稳定性阳性样本和微卫星不稳定性阴性样本,对本发明的方法进行监督式训练和性能评估,方便本发明的方法应用于临床实践。本发明中获取微卫星不稳定性状态可采用的方法有MSI-PCR(毛细管电泳),MSI-IHC(免疫组化蛋白),以及基于高通量测序的检测方法MSIsensor方法或MSIsensor-pro方法等。本发明中统一将微卫星稳定性(MSS)和微卫星不稳定性低(MSI-L)视作微卫星稳定性(MSS),即为微卫星不稳定性阴性;将微卫星不稳定性高(MSI-H)视作微卫星不稳定性(MSI),即为微卫星不稳定性阳性。本发明中利用标签One-hot编码指对微卫星不稳定性进行0和1编码,转换为机器学习模型能够识别的计算机编码形式,这里将微卫星稳定性(MSS)编码为0,微卫星不稳定性(MSI)编码为1即可。
数据清洗作处理是对阳性样本和阴性样本进行分析处理,在数据清洗过程,首先计算个样本中每个基因表达量的平均值和标准差及变异系数,去掉平均表达量小,方差小,变异系数小的基因,此处用户根据实际情况确定过滤阈值,用户可根据需求过滤掉一些基因表达量异常的离群样本。
类不平衡问题处理是对微卫星不稳定性阴阳性不平衡造成的机器学习的偏差进行矫正,以提高机器学习模型的检测效果。本发明中用户可以根据样本阴性和阳性的比例决定是否执行类不平衡矫正部分。本发明通过采样虚拟生成阳性样本,具体来说即提取出经过数据清洗处理后的阳性样本(微卫星不稳定阳性样本),根据其数据特点利用过采样算法构建一些新的阳性样本的过程。本发明提供两种方法:
方法一:根据癌症类型对经过数据清洗处理的微卫星不稳定阳性样本进行新阳性样本的构造,使得每种癌症类型的微卫星不稳定阳性样本和微卫星不稳定阴性样本数量达到平衡。
方法二:直接对所有经过数据清洗处理的微卫星不稳定阳性样本进行新微卫星不稳定阳性样本的构造,使得总体微卫星不稳定阳性样本和微卫星不稳定阴性样本数量均衡。
在完成类不平衡问题处理后,将样本数据(即阴性样本和阳性样本的总和)分为训练集和测试集两部分。
数据标准化操作是指对数据清洗和类不平衡处理后的基因表达量进行一定的尺度变换,以消除不同基因,不同样本,不同技术之间的量纲差异以及数量级差异太大对机器学习模型预测产生的影响。这里对训练集进行数据标准化操作,测试集进行与训练集相同的变换即可。
本发明提供两种常规标准化的方法:
方法一:归一化。它能将训练集的特征的值缩放到0至1之间,公式为:
其中,x
方法二:z-score标准化。它可以将训练集的特征的值放成均值为0,方差为1的标准正态分布,公式为:
其中,μ和σ分别表示该训练集的特征在所有样本中的均值和标准差。
特征基因选择,指对数据预处理后得到的基因表达量特征进行筛选,选择出对微卫星不稳定性状态判断有利的基因,即微卫星不稳定阳性样本(MSI)和微卫星稳定阴性样本(MSS)中差异表达基因。
本发明利用一些数理统计的方法对训练集的特征进行进一步筛选,使得导入机器学习模型中的特征个数减少,力求在保证检测效果的同时特征个数尽量少,可以根据使用者意愿选择N个特征基因。这样一方面能够提高模型的运算效率,另一方面可以降低实际检测中的测序成本。这里提供三种特征筛选的方法:
方法一:逻辑回归法筛选。将现有特征和标签导入逻辑回归模型中进行训练,得到每个特征的拟合系数,将系数取绝对值降序排序,绝对值越大代表对模型预测贡献越大。将特征拟合系数的绝对值降序排列,以特征的排序序号为横坐标,拟合系数的绝对值为纵坐标绘制折线图,选取折线图拐点位置的前N个基因为特征基因。
方法二:AUC法筛选:分别计算每个特征对于标签预测的AUC值,AUC大于0.5的特征为与微卫星不稳定性正相关,AUC小于0.5的特征为与微卫星不稳定性负相关的特征。对于正相关的特征,取AUC代表其对微卫星不稳定性分类的贡献值,对于负相关的特征,取1-AUC作为其对微卫星不稳定性分类的贡献值。将特征按照对微卫星不稳定性分类的贡献降序排序,以特征的排序序号为横坐标,贡献值为纵坐标绘制折线图,选取折线图拐点位置的前N个基因为特征基因。
方法三:差异基因法:将样本分为MSI和MSS两类,利用DESeq,DESeq2,edgeR,limma,Cuffdiff,Ballgown,sleuth等软件对MSI和MSS两类中表达具有显著性差异的基因进行筛选,通过调整q-value的值选择出前N个显著性差异大的差异基因为特征基因。
分类模型建立与训练,指在数据预处理和的数据中选择训练集样本中特征基因的数据(作为特征)和样本对应的微卫星不稳定性状态(作为标签)导入现有机器学习模型中进行训练,以建立微卫星不稳定性状态检测模型。这里用的机器学习模型包括逻辑回归、随机森林、K邻近、支持向量机、决策树、梯度提升树、感知机(神经网络)、多层感知机(深度神经网络)和朴素贝叶斯等,它们中的一种或多种组合。利用训练集的数据对分类模型进行训练,当迭代次数大于设定阈值或损失值小于设定阈值时(具体可以为:当模型准确率达到99%或者训练次数达到1万次时)停止训练,保存训练模型。
分类模型性能评估,指对于训练好的模型,将测试集导入进行预测,根据模型预测的性能指标,对预测的效果进行性能评估,再根据指标进行模型的调参优化。这里提供的模型性能判定的指标有常见的二分类评价指标,包括AUC、准确率(Accuracy)、精准率(Precision)和召回率(Recall)等。最后根据实际情况对模型进行调优。具体来说就是根据模型预测的性能指标对模型进行参数调整。
使用者事先设定一个对模型预测性能指标的阈值,若测试集在训练好的模型上预测指标达到阈值,则保存该模型用于本方法的第二部分模型应用;若测试集再训练好的模型上预测指标未达到阈值,则对模型参数进行调整后重新训练,再将测试集导入训练好的模型进行性能评估,直至达到阈值即可保存模型,模型训练部分完成。
模型应用部分,是对未知样本检测,指对于一个未知的需要微卫星不稳定性检测的样本,根据模型训练部分中选取的特征基因,通过高通量测序手段获取待测样本中各特征基因的基因表达量数据,然后对该基因表达量数据进行模型训练部分特征基因的基因表达量数据相同的数据标准化处理,最后将处理好的未知样本的特征基因的基因表达量数据导入模型训练部分得到的模型,利用模型对该样本的微卫星不稳定性状态进行检测。
下面为具体实施例。
实施例1
模型训练部分:
一、数据预处理
首先从肿瘤基因组图谱(The Cancer Genome Atlas,TCGA)数据库获取了940个样本的数据并整合到一张表中作为模型训练部分的输入,包括每个样本的案例ID,肿瘤类型,通过金标准检测获得的MSI状态,以及基因表达量数据,基因表达量为FPKM-UQ标准化格式。其数据格式如表1所示,数据统计如表2所示。
表1模型训练部分输入样本数据统计
*ALL代表所有类型,STAD代表胃癌,UCEC代表子宫内膜癌,CRC代表结直肠癌,MSI-H代表微卫星不稳定高,MSI-L代表微卫星不稳定性低,MSS代表微卫星稳定
表2模型训练部分输入样本的数据格式
*ENSG为基因的Ensembl ID,每个样本有60483个基因的表达量数据
然后对输入模型训练部分的数据进行特征和标签划分,每个样本的60483个基因表达量数据作为特征,金标准对于样本的微卫星不稳定性检测的结果作为标签。然后对标签进行One-hot编码,将MSI-L和MSS状态统一归类为MSS状态,编码为0,视作微卫星不稳定阴性样本;将MSI-H状态归类为MSI状态,编码为1,视作微卫星不稳定阳性样本。
再进行类不平衡问题处理,利用SMOTE过采样算法根据微卫星不稳定阳性样本,不参考癌症类型直接构造新的微卫星不稳定阳性样本,使得微卫星不稳定阳性和微卫星不稳定阴性样本数量比为1:1,达到平衡。
接着对样本集进行数据清洗处理,即对特征进行低方差噪声过滤和特征标准化,过滤方差阈值设置为0,因此过滤掉方差为0的特征,并判断有没有基因表达量异常的离群样本并进行过滤。
然后对样本集进行训练集和测试集划分,这里随机选择60%的样本作为训练集,40%的样本作为测试集。
最后进行数据标准化操作,对训练集进行标准化,测试集做与训练集相同的变换。选择z-score标准化,使得特征变换到均值为0,方差为1的标准正态分布。经特征处理后,特征个数从60483个减少到58269个。
二、特征基因选择
对处理好的基因表达量特征进行进一步过滤筛选,这里使用的是AUC筛选方法,将每个特征分别作为二分类预测的概率值,计算AUC,若AUC小于0.5则说明预测呈相反趋势,用1减该值作为新的AUC,保证最后所得AUC都在0.5到1之间。将每个特征的AUC降序排序,这里取前20个基因作为特征选择得到的基因。特征基因选择结果表3所示。
表3特征基因选择结果
三、分类模型建立与训练
完成特征基因选择后,将选择的特征和标签对应的训练集导入机器学习模型中进行训练,再把测试集导入训练好的模型计算模型的AUC。粗略对比几种机器学习模型后,选择随机森林模型。几种机器学习模型在训练集上的AUC比较,如图2所示。
四、模型性能评估
第三步中选择了随机森林模型,以测试集在模型中预测时AUC的大小作为评估指标,对该模型进行优化调参,AUC的阈值设置为0.98,调参后该模型AUC在0.99左右,满足阈值要求,因而保存该模型用于模型应用部分。该模型在训练集上的ROC曲线如图3和图4所示。
模型应用部分:
五、未知样本检测
从肿瘤基因组图谱(The Cancer Genome Atlas,TCGA)数据库获取了3个未知样本进行微卫星不稳定性检测,根据模型训练部分选择的特征基因,分别测得各样本的20个特征基因的基因表达量,格式为FPKM-UQ标准化格式。然后对这20个特征基因的基因表达量做与模型训练部分训练集相同的数据标准化变换,再导入模型训练部分得到的模型中进行检测,由模型给出预测的结果,检测结果如表4所示,通过金标准检测结果进行验证,3个样本均检测正确。
表4模型应用部分预测结果
本发明只需要肿瘤患者的肿瘤样本做分析,不需要患者的正常样本作对照,可减少正常样本取样过程中给患者带来的痛苦,同时减少对患者遗传物质泄漏的风险,减少成本。与过往的基于DNA测序数据的微卫星不稳定性检测相比,基于转录组测序的机器学习检测准确率更高。转录组测序相比DNA测序的成本更低,实际情况中只需要测20多种基因的表达质量即可对微卫星不稳定性进行较准确的检测。
- 一种基于转录组测序的微卫星不稳定性检测方法
- 一种基于Pacbio数据的MSI微卫星不稳定性检测方法和系统