一种基于视网膜模型的低光图像增强方法
文献发布时间:2023-06-19 11:57:35
技术领域
本发明属于图像处理技术领域,特别涉及一种基于视网膜模型的低光图像增强方法。
背景技术
低光图像增强就是将一些弱光环境拍摄的亮度过低的图像增强,目的是得到光照效果较好的图像。如夜晚或者密闭环境内所拍摄的照片,往往存在着亮度过低、不能有效辨认图片具体内容的问题,因此低光图像增强一直是计算机视觉领域的热门研究方向之一。
当前的低光图像增强方法大都是单纯基于视网膜模型的,比如MSR、MSRCR和SIRE以及RRM等,此类方法往往存在增强效果不明显、颜色失真、产生伪影等缺陷,并且现有的低光图像增强方法在处理图像时耗时较多。
发明内容
本发明的目的在于克服现有技术的至少一个缺点,提供一种基于视网膜模型的低光图像增强方法,可以有效解决很亮的地方增强所导致的过曝问题,以及很暗的地方增强所导致的失真问题,从而得到更好的低光图像增强效果。
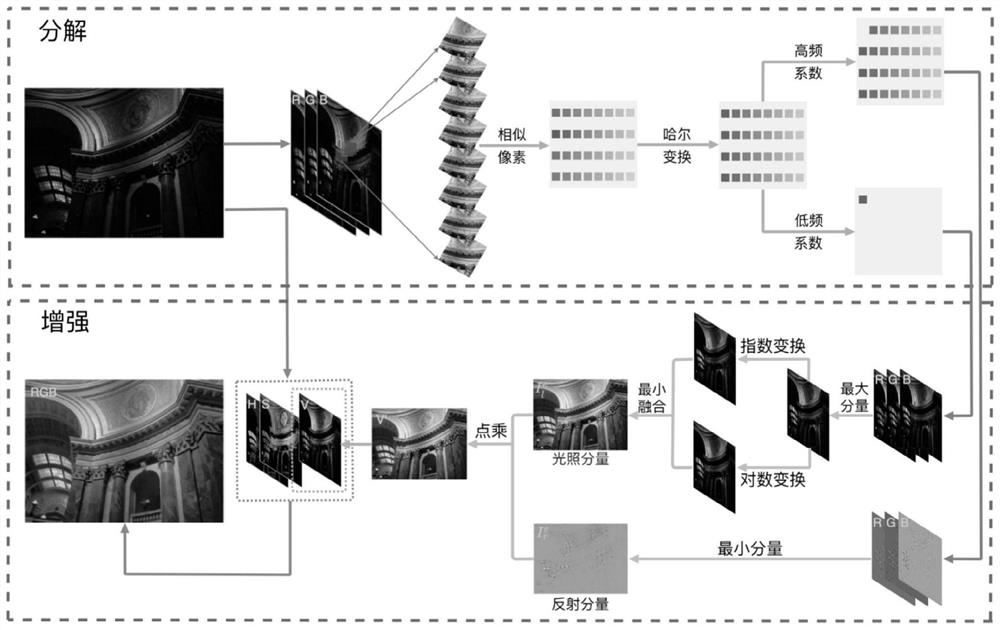
本发明公开一种基于视网膜模型的低光图像增强方法,包括:
步骤S1:获得相似像素群组;
步骤S2:在相似像素群组上执行哈尔变换,利用像素级的非局部哈尔变换的低频系数和高频系数分别在R、G、B三个通道分别获得光照分量和反射分量;
步骤S3:找到R、G、B三个通道反射分量的最小分量作为最终反射分量;
步骤S4:找到R、G、B三个通道光照分量的最大分量,运用指数和对数相结合的方法进行增强,得出增强光照分量;
步骤S5:将增强光照分量的最小分量作为最终光照分量;
步骤S6:将所述最终反射分量与所述最终光照分量应用于视网膜模型,获得增强的图像。
优选的,所述步骤S1具体包括:
步骤S1a:在RGB颜色空间中的R、G、B三个通道中分别执行块匹配与行匹配,按一定滑动步长在其中选取一个尺寸为
步骤S1b:将每一个尺寸为
步骤S1c:选取矩阵M
优选的,所述步骤S1c具体为:
将矩阵M
选择与第i行距离最小的N
优选的,所述步骤S2中所述哈尔变换具体包括:
对相似像素矩阵M
C
其中,C
优选的,所述步骤S2中所述光照分量的获得方法具体包括:
定义C
优选的,所述步骤S2中所述反射分量的获得方法具体包括:
定义C
优选的,所述步骤S4具体包括:
步骤S4a:对于光照分量,通过R、G、B三个通道分别获得3个光照分量
步骤S4b:用不同的指数γ
其中γ
其中γ
如果
则
否则
步骤S4c:获得第一增强光照分量
步骤S4cd:获得第二增强光照分量
优选的,所述步骤S5具体包括:
步骤S5a:获得最终光照分量
其中,
步骤S5b:将图像归一化为灰度值[0,1];
步骤S5c:对图像的灰度范围进行压缩。
优选的,所述步骤S6具体包括:
步骤S6a:将所述最终增强光照分量和所述最终反射分量,应用于视网膜模型,即
其中I
步骤S6b:将I
与现有技术相比,本发明的有益效果:本发明一种基于视网膜模型的低光图像增强方法快速有效,经本方法处理后的图像颜色不会过于鲜艳,能够很好地保留原始图像中的信息,并且能够很好地解决增强后光照不均的问题,不会引入假信号,图像边缘信息保真度非常高。
附图说明
图1为本发明一种基于视网膜模型的低光图像增强方法的流程图;
图2为本发明低光图像增强方法与部分现有低光增强方法处理后图像效果的第一对比图;
图3为本发明低光图像增强方法与部分现有低光增强方法处理后图像效果的第二对比图。
具体实施方式
下面结合附图对本发明做进一步的描述,此描述仅用于解释本发明的具体实施方式,而不能以任何形式理解成是对本发明的限制,具体实施方式如下:
如图1所示,本发明提出了一种基于视网膜模型相结合的低光图像增强方法,包括以下步骤:
步骤S1:获得相似像素群组;
步骤S2:在相似像素群组上执行哈尔变换,利用像素级的非局部哈尔变换的低频系数和高频系数分别在R、G、B三个通道分别获得光照分量和反射分量;
步骤S3:找到R、G、B三个通道反射分量的最小分量作为最终反射分量;
步骤S4:找到R、G、B三个通道光照分量的最大分量,运用指数和对数相结合的方法进行增强,得出增强光照分量;
步骤S5:将增强光照分量的最小分量作为最终光照分量;
步骤S6:将所述最终反射分量与所述最终光照分量应用于视网膜模型,获得增强的图像。
具体包括:
获得相似像素群组。
在一幅RGB颜色空间的低光彩色图像I∈R
在RGB颜色空间中的R、G、B三个通道中分别执行块匹配与行匹配,按一定滑动步长在其中选取一个尺寸为
为了更好地挖掘图像中的自相似性,我们进一步在M
选取其中一行R
具体来说,对于第i行作为参考行,计算第i行与其余所有行的欧式距离为:
然后选择与第i行距离最小的N
在相似像素群组M
分别对M
C
其中,C
由于可分提升哈尔变换的特性,C
对反射分量执行增强操作:
对于反射分量,通过R、G、B三个通道分别获得3个反射分量
对光照分量执行增强操作:
对于光照分量,通过R、G、B三个通道分别获得3个光照分量
γ
如果
则
否则
第一增强光照分量
第二增强光照分量
在实践中发现,如果仅用指数变换来增强图像中低亮度部分的光照分量,则亮度值增长速度过快,会导致亮度不足的问题;如果只用对数变换来增强图像中高亮度部分的光照分量,亮度值的增长速度同样会过快,也会导致亮度不均匀。
因此,为了解决上述问题,本发明通过下面的方式获得最终光照分量I
将图像归一化为灰度值[0,1],然后对图像的灰度范围进行压缩,原始图像中的暗区会有很大程度的亮区,而亮区变化很小,实现了低光图像增强的效果,保证了增强结果在不同光照区域的自适应性。
将最终光照分量与最终反射分量应用于视网膜模型,即
其中I
将I
本发明对CVPR2021UG2+challenge数据集中随机选取的200张低光图像所组成的数据集以及35幅低光图像数据集用MATLAB软件进行了增强实验,执行本发明的算法,得到增强结果图像,并与HE、MSRCR、CVC、NPE、SIRE、MF、WVM、CRM、BIMEF、LIME、Jiep以及STAR这些现有技术中的经典方法进行比较,其图像效果如图2及图3所示。其中CVPR2021UG2+challenge数据集地址为:(
从图2及图3中可以看出,经本发明方法增强的图像颜色不会过于鲜艳,能够很好地保留原始图像中的信息,并且能够很好地解决增强后光照不均的问题,不会引入假信号,图像边缘信息保真度非常高。
经本发明方法增强后图像与现有技术增强后图像的NIQE、LOE、TMQI及FSIM值比较如下表所示:
需要说明的是:NIQE、LOE、TMQI越低,则说明图像质量越高,FSIM越高,则说明图像质量越高。
从表中数据可以看出,经过本发明低光图像增强方法处理后的图像的上述四个指标值对于图像的处理效果均优于现有技术中低光图像增强方法的结果。
至此,本领域技术人员应认识到,虽然本文已详尽示出和描述了本发明的示例性实施例,但是,在不脱离本发明精神和范围的情况下,仍可根据本发明公开的内容直接确定或推导出符合本发明原理的许多其他变型或修改。因此,本发明的范围应被理解和认定为覆盖了所有这些其他变型或修改。
- 一种基于视网膜模型的低光图像增强方法
- 一种基于视网膜大脑皮层理论的深度学习低光照图像增强方法