一种基于属性动态选择与灰度关联分析的缺失值填补方法
文献发布时间:2023-06-19 11:57:35
技术领域
本发明属于数据处理领域,具体涉及一种基于属性动态选择与灰 度关联分析的缺失值填补方法。
背景技术
随着健康中国战略的推进,以治病为中心转变为以人民健康发展 为中心的新主旨深入人心,人们的健康意识在不断提升,各类健康投 入也在迅猛攀升。越来越多的厂家将目光转向家用医疗检测仪和智慧 移动设备的研发生产,将其作为抢占健康市场的热门产品。医用健康 设备飞速发展不断更新原有健康管理方式,用户依托这些技术设备自 行采集的检测数据也在不断增长,将在国家层面的居民健康战略指导 和个人健康应用服务方面发挥重要作用。然而,这些智能健康检测设 备的某些技术问题,或是用户由于未按时采集、采集方式不当、数据 存储不及时等原因造成的数据缺失,都会导致后续的预测诊断和精准 指导出现偏差,难以达成预期目标。对于此类缺失问题,最好的解决 办法是进行有效的数据填补。
对于现有概念下的检测数据来说,其数据本身具有用户主体上的 同一性和时间上的连续性,数据间亦具有一定的相关性。因此在对此 类数据集上的缺失值进行填补时,可以采用身体状况相似或者时间上 接近的检测数据完成补缺,而这一思想与KNN填补算法高度契合。 同时,由于检测数据尚处于高速增长的过程中,其相应的样本属性会 随着技术的更新而持续变化。若是选择了需要根据数据进行模型训练 的机器学习算法进行缺失填补,则要根据变动后的数据不断的进行模 型训练,计算开销较大,填补效果也难以精准把控。基于以上原因, 本发明将在KNN填补算法的基础上,对检测数据集进行缺失值填补 研究。
在现有的KNN填补算法中,使用灰度距离代替欧式距离进行填 补的GKNN已经被证明在缺失值填补中取得了较好效果,但是GKNN 在距离计算中有两点不足值得进一步研究:第一,GKNN忽略了待填 补属性与其他属性间相关程度对距离的影响,在一定程度上使得近邻 选择出现偏差;第二,GKNN在距离计算中使用了除待填补属性外的 所有其他属性,使得与待填补属性相关性较小的其他属性对距离计算 结果产生影响。FWGKNN和CGKNN在GKNN的基础上引入了属性 间相关性计算结果作为距离计算中的权重,但是这两项工作依旧使用了所有属性进行距离计算,并没有对弱相关属性或是无关属性进行剔 除,难以精准完成近邻选择。
发明内容
针对现有填补算法的局限性,本发明提出一种基于属性动态选择 的缺失数据填补方法FSGKNN,此方法兼顾了GKNN距离计算中的 两处不足之处,对每个待填补算法进行对应的相关属性选择,并且在 后续距离计算中使用选择出的属性与待填补属性的相关系数作为权 重,从而使得填补值更加接近真实值。
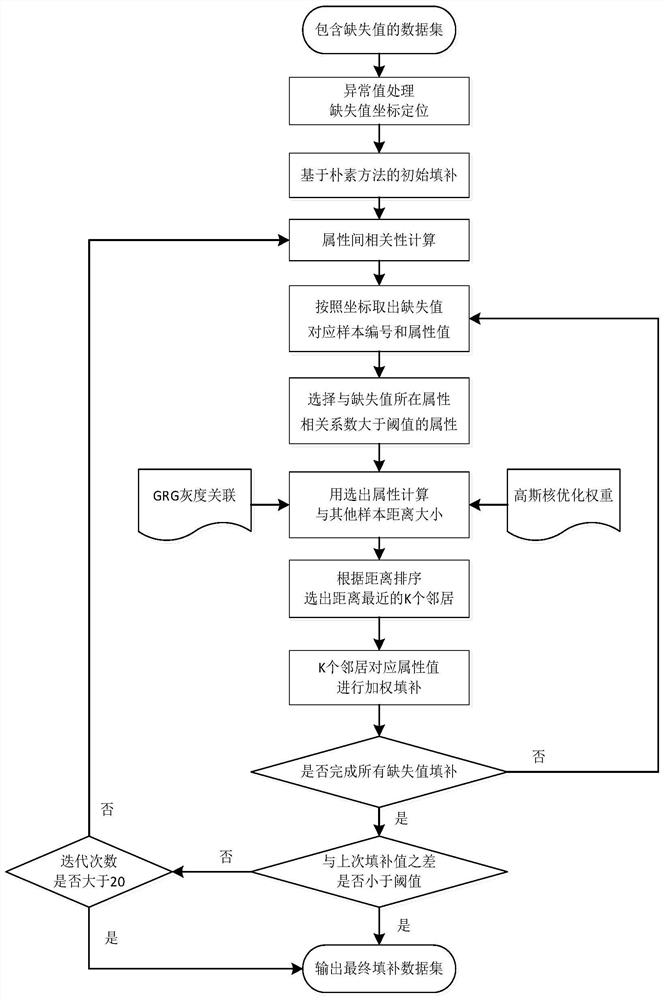
为了实现上述目的,本发明提出一种基于属性动态选择的缺失数 据填补方法FSGKNN,其具体步骤如下:
步骤1:对包含缺失值的原始数据集进行基于朴素方法的初始填 补;
步骤2:在完成初始填补的基础上,执行属性动态选择,对每个 待填补属性只筛选出相关性较大的属性用于后续计算;
步骤3:采用灰度关联度作为样本间距离度量公式执行K近邻计 算,在距离计算中将高斯核函数优化后的属性间关联系数作为相关权 重,得到待填补样本与其他样本间的灰度关联距离,由此距离排序获 得最相近的K个邻居;
步骤4:根据待填补数据的具体属性,对K个邻居的同一属性值 进行加权计算,将其作为下一次填补的初始值并不断迭代,直到前后 两次填补值的差值收敛于某一邻域,此时将最后一次填补值作为最终 填补值保存。
作为进一步优选的,步骤1中的朴素填补方法候选采用均值/众 数填补法、线性回归法与随机填补法。其中,采用均值/众数填补法 时,对于连续待填补属性使用均值完成填补,对于离散待填补属性使 用众数完成填补。同样的,采用众数法进行初步填补时,也只挑选缺 失值所在属性对应最大频数变量完成填补。具体采用的朴素填补方法, 需要根据数据集情况实施实验分析确定。
作为进一步优选的,步骤2中的属性动态选择细分为如下步骤:
(1)相关性计算
采用灰色关联分析(GRA)以量化各种因素之间的影响以及数据 序列之间的关系,进而构建灰色关联模型,用于度量两个数据集或一 个数据集的两个变量之间的趋势关系。灰色关联系数(GRC)公式如 下所示:
其中x
(2)计算相关系数矩阵
在初始填补后的完整数据集使用上述相关性计算方法得到对应 的相关系数矩阵S,公式如下所示:
其中m代表数据集中总属性的个数,矩阵的每一列数值即为该 属性与其他属性间的相关系数,例如p
(3)属性动态选择阈值设置
对于检测数据集,不同属性间存在的关联性不尽相同。某些属性 间呈现强相关性,某些属性之间也可能关联性较小。部分K近邻填 补算法研究中考虑使用不同权重来减少这些无关属性的影响,但并没 有提出更优解决办法。本发明对每一个包含缺失值的属性,都只选取 与其相关性排序靠前的部分属性用于后续的距离计算,从而减少无关 变量的对距离计算的影响。合适属性选择的关键在于对属性间相关系 数大小分布的把握。对于属性间相关性较强的数据样本,可去除个别 噪声属性,留下相关性强的属性用于后续距离计算,以免丢失有效信 息;而对于属性间相关性较弱的数据样本,只选择总体系数里占比较 高的相关属性用于距离计算。本发明提出对应属性相关系数均值 (F-MEAN),公式如下所示,旨在将每个待填补属性与其他属性的 相关系数均值作为特征选择阈值,只选择相关系数大于F-MEAN的 属性用于后续计算。
作为进一步优选的,步骤3中的距离计算细分为如下步骤:
(1)灰度关联距离计算
本发明使用灰色关联分析中的灰色关联系数(GRC)变体以及灰 色关联等级(GRG)来描述给定数据集中包含缺失值的样本与其他样 本之间的距离值。对于包含n个样本数据集D={x
其中,i,j=1,2,……n;k,p=1,2,……m;ρ是一个区分 系数,取值区间为0-1。在具体的应用中,ρ需要根据整个数据集的 整体分布选择合适的值,在本方法中,将ρ的取值初步设定为0.5。
GRC是用来描述两个样本不同属性在整体属性中的相关趋势的, 而为了整合属性间的趋势,需要将其转变为样本间的相关趋势,计算 两个样本间的灰色关联等级(GRG),以两个样本间所有对应属性的 灰色关联系数均值作为距离度量标准,从而求得与缺失值所在样本距 离最小的K个邻居样本,公式如下所示:
(2)基于高斯核的权重优化
对于缺失值所在属性k,首先从系数矩阵S中取出与属性k相关 系数大于阈值的其他属性的相关系数,形成一维数组;然后,对一维 数组进行取正,以保证后续计算的准确性;接着,根据调整后的高斯 核函数变形公式,计算出相应的权重值,公式如下所示;最后,对各 权重值做归一化处理,得到最终用于计算的权重值。
Max(ρ
(3)加权灰度关联度近邻距离计算
对于包含缺失值的样本x
对于目标属性样本x
作为进一步优选的,步骤4中的近邻加权与迭代填补细分为如下 步骤:
(1)近邻加权
在得到与目标样本x
连续加权填补法进行连续属性缺失填补,具体计算公式如下所示:
其中,M
离散加权填补法,首先遍历K个邻居包含的所有类别来确定总 类别数;接着使用如下公式对每个类别的权重继续计算;最后选择最 高权重所在类别作为缺失填补值。
在K个邻居中,l为待填补离散属性中的某一类别,此类别共有 j个样本;x
(2)加权填补
在完成二次填补后,对数据集进行一次实时更新,将最新的填补 值用于下一轮的缺失值填补计算中,直到两次填补值的均方根误差之 差小于阈值ε=0.0001。为了防止算法陷入无限循环,在20次填补后 若还没有满足迭代条件,仍然使填补算法停止,并以第20次的完整 填补值作为最终填补值。
与现有技术相比,本发明提供了一种基于属性动态选择与灰度关 联分析的缺失值填补方法,具备以下有益效果:
本发明创造性地提出了属性动态选择方法,通过为不同的待填补 属性设计合适的阈值,筛选出与待填补属性呈强相关的属性,删减冗 余属性。使得在后续近邻距离计算中,强相关属性占比提高,冗余属 性造成的噪声干扰减小,为最终缺失值填补提供更可靠更准确的保障。 这一数据处理方法能够在进行后续研究前,对数据进行有效预填充, 使得缺失值更加接近原始值,减少对数据挖掘与分析的影响。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分, 与本发明的实施例一起用于解释本发明,并不构成对本发明的限制, 在附图中:
图1为本发明提出的一种基于属性动态选择的缺失数据填补方 法的操作流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方 案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部 分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普 通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例, 都属于本发明保护的范围。
请参阅图1,本发明提供一种技术方案:一种基于属性动态选择 的缺失数据填补方法,主要以下几个步骤:初始填补、动态属性选择、 灰度关联加权近邻计算、近邻加权与迭代填补。
本实施例采用心脏病实验数据Cardiovascular Disease dataset进 行说明,此数据集来自Kaggle公共数据平台(https://www.kaggle.com), 由Svetlana Ulianova等人在2019年整理而成;数据集包含70000个 用户样本,每个样本由用户ID,由11个异构属性,以及一个二分类 患病判断标签组成。表1展示了12个属性的具体属性名称、数据来 源、类型分布、和数据意义等。
心脏病实验数据Cardiovascular Disease dataset中属性具体情况 介绍如下表所示:
表1 Cardiovascular Disease dataset数据特征信息
参见图1,本实施例提供的基于属性动态选择与灰度关联分析的 缺失值填补方法具体、包括以下步骤:
(1)初始填补
对均值/众数填补法、线性回归法与随机填补法等三种朴素初始 填补方法在10%、20%、30%三种不同缺失率下实施填补实验,以RMSE为评判指标,得到效果对比结果如下表所示:
表2三种初始填补方法在不同缺失率下的RMSE比对
从表格中可以看出,在缺失率为10%时,线性回归填补法略优于均值 /众数填补法,但是在缺失率增大时,均值/众数填补法却表现的更稳 定。在三种算法中,随机填补法的均方根远远大于其他两种方法,不 予考虑。根据以上结果,本实施例选择均值/众数填补法作为初始填 补方法。
(2)动态属性选择
a.相关性计算:采用灰色关联分析(GRA)以量化各种因素之间 的影响以及数据序列之间的关系,进而构建灰色关联模型,用于度量 两个数据集或一个数据集的两个变量之间的趋势关系。灰色关联系数 (GRC)公式如下所示:
其中x
b.计算相关系数矩阵,在初始填补后的完整数据集使用上述相关 性计算方法得到对应的相关系数矩阵S,公式如下所示:
其中m代表数据集中总属性的个数,矩阵的每一列数值即为该 属性与其他属性间的相关系数,例如p
c.属性动态选择阈值设置:对于检测数据集,不同属性间存在 的关联性不尽相同。某些属性间呈现强相关性,某些属性之间也可能 关联性较小。部分K近邻填补算法研究中考虑使用不同权重来减少 这些无关属性的影响,但并没有提出更优解决办法。本发明对每一个 包含缺失值的属性,都只选取与其相关性排序靠前的部分属性用于后 续的距离计算,从而减少无关变量的对距离计算的影响。合适属性选 择的关键在于对属性间相关系数大小分布的把握。对于属性间相关性 较强的数据样本,可去除个别噪声属性,留下相关性强的属性用于后 续距离计算,以免丢失有效信息;而对于属性间相关性较弱的数据样 本,只选择总体系数里占比较高的相关属性用于距离计算。本发明提 出对应属性相关系数均值(F-MEAN),公式如下所示,旨在将每个 待填补属性与其他属性的相关系数均值作为特征选择阈值,只选择相 关系数大于F-MEAN的属性用于后续计算。
(3)灰度关联加权距离计算
a.灰度关联距离计算
本发明使用灰色关联分析中的灰色关联系数(GRC)变体以及灰 色关联等级(GRG)来描述给定数据集中包含缺失值的样本与其他样 本之间的距离值。对于包含n个样本数据集D={x
其中,i,j=1,2,……n;k,p=1,2,……m;ρ是一个区分 系数,取值区间为0-1。在具体的应用中,ρ需要根据整个数据集的 整体分布选择合适的值,在本方法中,将ρ的取值初步设定为0.5。
GRC是用来描述两个样本不同属性在整体属性中的相关趋势的, 而为了整合属性间的趋势,需要将其转变为样本间的相关趋势,计算 两个样本间的灰色关联等级(GRG),以两个样本间所有对应属性的 灰色关联系数均值作为距离度量标准,从而求得与缺失值所在样本距 离最小的K个邻居样本,公式如下所示:
b.基于高斯核的权重优化
对于缺失值所在属性k,首先从系数矩阵S中取出与属性k相关 系数大于阈值的其他属性的相关系数,形成一维数组;然后,对一维 数组进行取正,以保证后续计算的准确性;接着,根据调整后的高斯 核函数变形公式,计算出相应的权重值,公式如下所示;最后,对各 权重值做归一化处理,得到最终用于计算的权重值。
Max(ρ
c.加权灰度关联度近邻距离计算
对于包含缺失值的样本x
对于目标属性样本x
(4)近邻加权与迭代填补
在得到与目标样本x
连续加权填补法进行连续属性缺失填补,具体计算公式如下所示:
其中,M
离散加权填补法,首先遍历K个邻居包含的所有类别来确定总 类别数;接着使用如下公式对每个类别的权重继续计算;最后选择最 高权重所在类别作为缺失填补值。
在K个邻居中,l为待填补离散属性中的某一类别,此类别共有 j个样本;x
在完成二次填补后,对数据集进行一次实时更新,将最新的填补 值用于下一轮的缺失值填补计算中,直到两次填补值的均方根误差之 差小于阈值ε=0.0001。为了防止算法陷入无限循环,在20次填补后 若还没有满足迭代条件,仍然使填补算法停止,并以第20次的完整 填补值作为最终填补值。
按照上述步骤最终确定了本发明提出填补方法的所有细节。将四 种同类填补算法与本发明算法在不同缺失率上进行RMSE比对,结 果如下表所示:
表3其他4种KNN填补算法与FSGKNN算法比对
由表可知,在三种缺失率下,本发明所提出的基于属性动态选择 与灰度关联分析的缺失值填补方法填补后的数据集更接近真实数据 集,拥有更好的填补性能。
本实施例也采用UCI公共数据库进行说明,这些数据集包括三 种不同的类型:连续型、离散型和混合异构型,样本数量在150-958 之间,均为分类型数据集。表4展示了4个公共数据集的名称、样本 数量、属性数量和数据类型等。
表4UCI公共数据集介绍
按照最终步骤中本发明提出填补方法的所有细节。将四种同类填 补算法与本发明算法在以上公共数据集上进行RMSE比对,结果如 下表所示:
表5不同缺失率下UCI数据集RMSE比对值
从实验结果可以看出,FSGKNN算法在大多数情况下都表现出了 最佳的填补性能,并且获得了最小的均方根误差,能够实现有效的数 据填补,达到预期目标和效果。本发明基于属性动态选择和灰度关联 分析的基础上考虑了不同属性间相关性对距离计算与填补的影响,有 效提升了近邻寻找的可靠性,实验测试执行性大,适用性广,缺失值 填补效果较好。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术 人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这 些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权 利要求及其等同物限定。
- 一种基于属性动态选择与灰度关联分析的缺失值填补方法
- 一种基于历史数据辅助场景分析的电压缺失值填补方法