一种基于LSTM的农产品品质分类方法
文献发布时间:2023-06-19 12:00:51
技术领域
本发明涉及农产品品质分类方法技术领域,具体是一种基于LSTM的农产品品质分类方法。
背景技术
随着社会的不断进步,农产品的品质与质量越来越受到人们的重视,然而农产品品质的评价受多元化因素的影响,既要考虑外部特征因素也需要考虑内部特征因素,并且农产品在实际运输过程中随着时间的变化会对品质产生影响。因此很难对农产品的品质下以标准化得定义,也鲜有网站与机构对农产品的品质进行分类。
LSTM是深度学习中有效、可靠的算法,适合用于处理与时间序列高度相关的问题。对于分类问题,以CNN为代表的前馈网络拥有着性能上的优势,但由于LSTM具有记忆细胞的特殊单元类似累加器和门控神经元,在解决长远的、更为复杂的任务上具有独特的优势。
业内对于分类问题,大多采用的是传统的数理统计的方法和机器学习中的算法,在分类过程中很难处理大量、多维度的数据并且难以解决多分类的问题。
因此,实际应用中此类模型难以取得理想的效果。
发明内容
本发明的目的在于克服现有技术的缺陷,提出一种可以解决多分类的问题的基于LSTM的农产品品质分类方法。
为实现上述目的,本发明采用了如下技术方案:
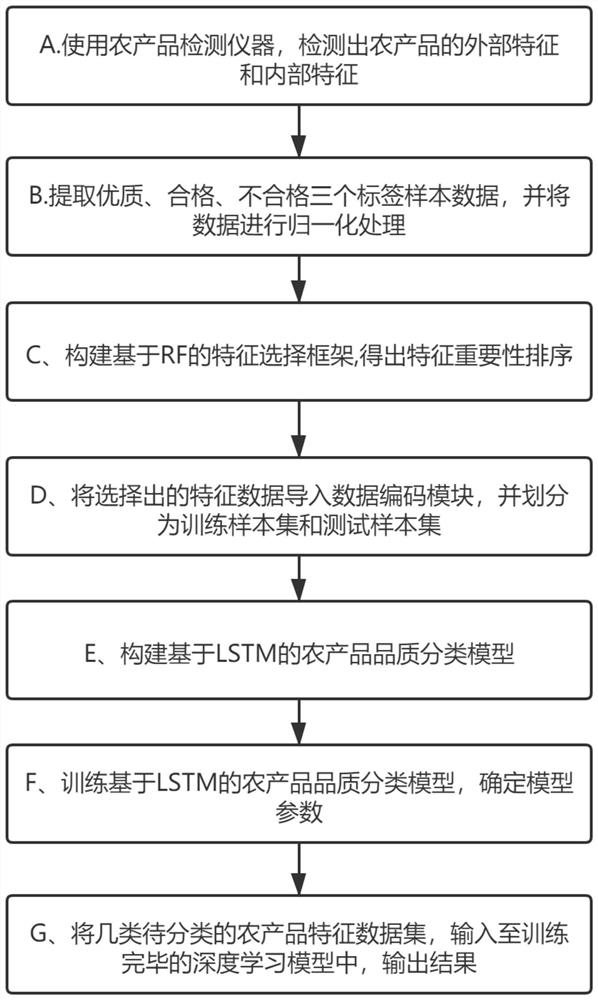
一种基于LSTM的农产品品质分类方法,包括以下步骤:
A、使用农产品检测仪器,检测出农产品的外部特征a
B、从已有的数据中提取优质、合格、不合格三个标签样本数据,并将数据进行归一化处理;
C、构建基于RF的特征选择框架,将处理好的16个特征变量送入基于RF的农产品品质特征选择模型中进行农产品品质的分类预测,得出特征重要性排序;
D、选取16个特征变量中关联度较大的9个特征变量,将数据导入数据编码模块,数据编码模块采用数据处理技术对提取后的数据进行编码,最后划分为训练样本集和测试样本集;
E、构建基于LSTM的农产品品质分类模型;
F、利用已组建的训练样本集和测试样本集,训练基于LSTM的农产品品质分类模型,确定模型参数;
G、将几类待分类的农产品特征数据集,输入至训练完毕的深度学习模型中,深度学习模型输出识别分类结果。
优选的,所述步骤A中,通过仪器检测出酚类含量、可溶性固形物、酒精含量、总酸、单宁等内部影响因素,通过分析天平检测出农产品重量、通过农产品检测仪检测农产品形态指数等外部影响因素。
优选的,所述步骤B中,为了消除不同度量单位和方差对预测结果的不良影响,将训练集中的每一个数据特征的值进行归一化处理,且计算公式如下:
其中,x
优选的,所述步骤C中,构建基于RF的农产品品质特征选择模型方法如下:
C1:从原始训练集中使用Bootstraping方法有放回地重复随机抽取n个样本;
C2:用n组袋外数据(OOB data)分别计算出每一棵决策树的误差值,记作E
C3:保持其他特征不变的情况下,对n组袋外数据的第i个特征进行随机重排,并重新计算误差值,记新的误差值为E
C4:特征重要性排序的计算公式如下:
C5:基于特征对于最终结果的重要性进行排序,根据得到的最佳特征数9择出前9个特征作为特征向量送入新的模型。
优选的,所述步骤D,构建数据编码模块方法如下:
数据的编码方式采用one-hot的编码方式,9个特征在一次热编码过程中被编码,编码符合一下特征:
在上式中,x为一个特征,包含有序集合中有可能的值。
优选的,所述步骤E,构建基于LSTM的农产品品质分类模型方法如下:
D1:构造多层LSTM的复合网络,本网络由两层LSTM层和三层全连接层构成,第一层LSTM层由80个神经元构成,第二层LSTM层由100个神经元构成;
D2:将训练集的数据作为一个整体分别输入到第一层LSTM层的输入门i
i
f
o
g
c
其中,内部状态向量由输入门控制的每个隐藏单元写入,遗忘门决定了先前的内部状态c
D3:模型部分中使用高效的adam优化算法,损失函数采用categorical_crossentropy loss(交叉熵损失函数),并将训练集与测试集数据输入复合网络中;
D4:网络根据得到的数据多次迭代并保存高精度下的模型参数;
优选的,所述步骤F中利用测试集数据对模型进行评估,获得测试集的准确率和损失值;当测试集的准确率和训练集的准确率都很低时,模型存在欠拟合问题,这时需要在模型中添加多项式特征并减少正则化参数;当测试集的准确率和训练集的准确率比其他独立数据集上的测试结果的准确率要高时,模型存在过拟合问题,这时需要在模型中加入l
优选的,所述步骤G中利用训练完成的农产品品质分类模型对待分类的农产品进行分类的方法为:将用农产品检测仪器检测出的数据输入已经训练好的基于LSTM的农产品品质分类模型中,得到农产品品质分类的结果。
与现有技术相比,本发明提供了一种基于LSTM的农产品品质分类方法,具有如下有益效果:
本发明是一种基于LSTM的农产品品质分类方法,利用了RF在大量检测数据中选择出关联度对品质因素影响关联度高的数据,从而降低了繁杂数据对模型参数的干扰,一定程度上可以提高模型的准确率。同时充分利用了LSTM网络对数据的记忆特征,从而解决了在农产品品质分类受时间影响的问题。
附图说明
图1是本发明的整体步骤流程示意图;
图2是本发明中深度学习模型框架图之一;
图3是本发明中深度学习模型框架图之二。
具体实施方式
以下结合附图1-图3,进一步说明本发明一种基于LSTM的农产品品质分类方法的具体实施方式。
本发明一种基于LSTM的农产品品质分类方法不限于以下实施例的描述。
一种基于LSTM的农产品品质分类方法,包括以下步骤:
A、使用农产品检测仪器,检测出农产品的外部特征a
B、从已有的数据中提取优质、合格、不合格三个标签样本数据,并将数据进行归一化处理;
C、构建基于RF的特征选择框架,将处理好的16个特征变量送入基于RF的农产品品质特征选择模型中进行农产品品质的分类预测,得出特征重要性排序;
D、选取16个特征变量中关联度较大的9个特征变量,将数据导入数据编码模块,数据编码模块采用数据处理技术对提取后的数据进行编码,最后划分为训练样本集和测试样本集;
E、构建基于LSTM的农产品品质分类模型;
F、利用已组建的训练样本集和测试样本集,训练基于LSTM的农产品品质分类模型,确定模型参数;
G、将几类待分类的农产品特征数据集,输入至训练完毕的深度学习模型中,深度学习模型输出识别分类结果。
所述步骤A中,通过仪器检测出酚类含量、可溶性固形物、酒精含量、总酸、单宁等内部影响因素,通过分析天平检测出农产品重量、通过农产品检测仪检测农产品形态指数等外部影响因素。
所述步骤B中,为了消除不同度量单位和方差对预测结果的不良影响,将训练集中的每一个数据特征的值进行归一化处理,且计算公式如下:
其中,x
所述步骤C中,构建基于RF的农产品品质特征选择模型方法如下:
C1:从原始训练集中使用Bootstraping方法有放回地重复随机抽取n个样本;
C2:用n组袋外数据(OOB data)分别计算出每一棵决策树的误差值,记作E
C3:保持其他特征不变的情况下,对n组袋外数据的第i个特征进行随机重排,并重新计算误差值,记新的误差值为E
C4:特征重要性排序的计算公式如下:
C5:基于特征对于最终结果的重要性进行排序,根据得到的最佳特征数9择出前9个特征作为特征向量送入新的模型。
所述步骤D,构建数据编码模块方法如下:
数据的编码方式采用one-hot的编码方式,9个特征在一次热编码过程中被编码,编码符合一下特征:
在上式中,x为一个特征,包含有序集合中有可能的值。
所述步骤E,构建基于LSTM的农产品品质分类模型方法如下:
D1:构造多层LSTM的复合网络,本网络由两层LSTM层和三层全连接层构成,第一层LSTM层由80个神经元构成,第二层LSTM层由100个神经元构成;
D2:将训练集的数据作为一个整体分别输入到第一层LSTM层的输入门i
i
f
o
g
c
其中,内部状态向量由输入门控制的每个隐藏单元写入,遗忘门决定了先前的内部状态c
D3:模型部分中使用高效的adam优化算法,损失函数采用categorical_crossentropy loss(交叉熵损失函数),并将训练集与测试集数据输入复合网络中;
D4:网络根据得到的数据多次迭代并保存高精度下的模型参数;
所述步骤F中利用测试集数据对模型进行评估,获得测试集的准确率和损失值;当测试集的准确率和训练集的准确率都很低时,模型存在欠拟合问题,这时需要在模型中添加多项式特征并减少正则化参数;当测试集的准确率和训练集的准确率比其他独立数据集上的测试结果的准确率要高时,模型存在过拟合问题,这时需要在模型中加入l
所述步骤G中利用训练完成的农产品品质分类模型对待分类的农产品进行分类的方法为:将用农产品检测仪器检测出的数据输入已经训练好的基于LSTM的农产品品质分类模型中,得到农产品品质分类的结果。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 一种基于LSTM的农产品品质分类方法
- 一种基于LSTM的流量分类方法