一种基于最大相关熵准则的多维信号特征融合方法
文献发布时间:2023-06-19 12:02:28
技术领域
本发明属于机器学习和数据挖掘领域,具体涉及一种引入最大相 关熵准则作为深度神经网络算法的损失函数实现多维信号的特征融 合。
背景技术
通常多维数据集中存在大量不相关和冗余的信息,增加了数据处 理、知识挖掘和模式识别的难度。特征融合作为解决这一问题的关键 方法,将原有的多维数据利用深度神经网络进行特征融合,滤除噪声 和冗余信息,保留具有代表性的敏感特征,是较为常用的策略。避免 了传统人工特征提取与选择所带来的繁琐性和不确定性,同时也可以 提高分类器的准确率。最大相关熵作为一个局部相似性度量准则,在 处理非高斯噪声和距离较远的离群点方面,具有较好的鲁棒性。目前 已被成功应用于信号的滤波、降维和机器学习等多个领域。
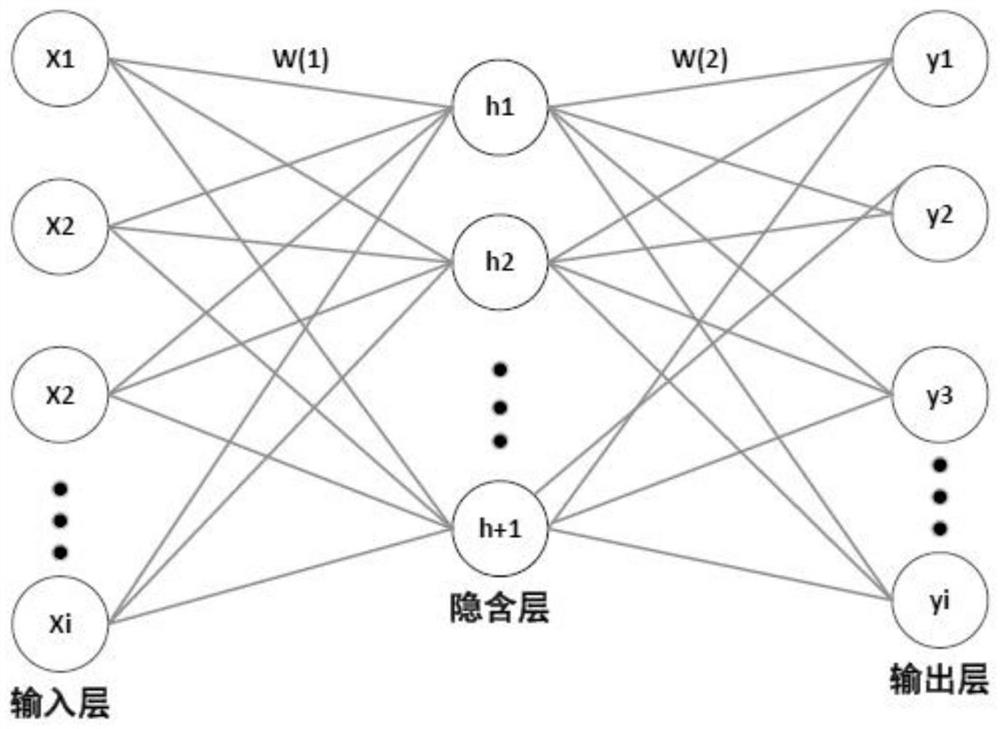
自编码器是一种具有三层的无监督神经网络,第一层是输入层, 中间层是隐含层,最后一层是输出层。如图1所示。可以在没有标签 向量的情况下学习数据的内在特征,属于无监督学习。不同于传统的 单隐层神经网络,自编码器的学习过程包括编码和解码两个阶段。数 据通过自编码器的输入层到隐含层,将多维空间的输入数据映射到低 维空间进行编码,最后由隐含层到输出层重新构造输入数据进行解码。 隐含层的作用是在编码和解码过程中尽可能确保输出的数据和输入 的数据一致,用尽量少的维度提取输入数据和输出数据主要特征。通 过最小化重构误差,使目标输出值接近于输入值。最小化均方误差(MSE)被广泛用于自编码器的损失函数,在没有复杂噪声干扰的情况 下,自编码器通常有很好的性能表现。但是,在实际应用中,测量数 据受工作条件和环境变化的影响,掺杂了大量噪声的异常数据,使得 传统自编码器的性能下降。此外,传统自编码器采用梯度下降法训练 网络参数,使损失函数最小化,有监督情况下,以数据的标签作为监 督信号计算网络误差。在梯度下降法完成各层权重和偏置的反向微调 过程中,不仅容易陷入局部最优解,而且增加了网络的训练时间。
超限学习机(Extreme LearningMachine,ELM)算法是一种简单易用、 有效的单隐层前馈神经网络学习算法,如图2所示。传统的神经网络 学习算法(如BP算法)需要人为设置大量的网络训练参数,采用梯 度下降法求解过程中容易产生局部最优解。而ELM在确定网络参数的 过程中,只需要设置网络的隐含层节点个数,在算法执行过程中不需 要调整网络的输入权值以及隐元的偏置,并且产生唯一的最优解。 ELM的输出为
发明内容
本发明的目的是针对现有最小均方误差作为传统自编码器的损 失函数存在的不足,提出一种基于最大相关熵准则的深度神经网络算 法,是一种更高效的特征融合方法。
本发明主要实现流程如下:首先,总结了ELM算法和最小均方 误差原理;其次,引入核函数理论,提出用最大相关熵准则代替最小 均方误差,作为ELM-AE的损失函数,将多个ELM-AE堆栈构成多 层深度神经网络;再次,针对某轴流压气机发生旋转失速的振动信号, 对信号等步长分窗截取,提取每个窗口信号的多维时域统计指标和非 线性特征熵;最后,将提取的多维信号特征作为所提方法的输入数据, 特征输出通过特征可视化分析,进一步验证了所提方法在特征融合方 面的有效性。
本发明的具体技术方案通过如下步骤实现:
步骤1、ELM算法总结:
1-1、给定训练集{(x
1-2、随机分配隐含层节点的参数(w
1-3、计算隐含层输出矩阵Η;
1-4、计算隐含层节点和输出节点之间的权重β=H
式中,H
步骤2、最小均方误差原理
给定训练样本X={x
h=S
S
式中,X是D维向量,h是d维向量,ω
2-1、将向量h经过解码由z=S
2-2、自编码器的训练阶段旨在优化参数集θ={ω
步骤3、ELM-AE多层深度神经网络
3-1、针对单层ELM-AE在掺杂噪声的复杂异常数据集的表征能 力不足的问题,采用堆栈ELM-AE的多层深度神经网络算法,对于 每一层的ELM-AE,其目标函数为:
式中,C是正则化系数,对深度生成的输入权重ω
3-2、输出权重β
3-3、ELM-AE的编码输出为Y=g(β
步骤4、核函数理论
4-1、满足Mercer理论的函数都可以看作为核函数计算特征空间 的点积,函数必须是连续的、正定的。通过核函数,可以将原始数据 点映射到多维Hilbert空间,计算数据样本在多维空间的内积,其表 达式可以表示为:
K(x
式中,Φ(·)表示多维非线性映射过程。
步骤5、最大相关熵准则
5-1、给定两个深度变量X和Y,其相关熵是定义在核空间上的 相关性测量,可表示为:
V(X,Y)=E[<Φ(X),Φ(Y)>
式中,E[·]表示期望,κ(·,·)是Mercer核函数,即 K(X,Y)=<Φ(X),Φ(Y)>
5-2、非线性核函数采用广泛使用的高斯核函数:
5-3、定义核空间上的损失函数C(X,Y)为:
由上式得,最小化C(X,Y)等同于最大化相关熵κ
步骤6、重新定义损失函数
6-1、使用最大相关熵准则代替最小均方误差原理,ELM-AE的 损失函数可以定义为:
式中,β
6-2、将相关熵取负,因此求最大相关熵等价于最小化负的相关 熵,采用高斯核,式(7)可以重新定义为:
其中,N表示训练样本个数,h
对式(8)求导令其导数为0,求解输出权重,整理得:
记
令
其中,σ是高斯核带宽,
6-3、将上式中含有β
式中,Λ是对角矩阵且
步骤7、深度特征融合
7-1、在某轴流压气机机匣周向均匀布置8个压力传感器,采集 某轴流压气机由正常工况逐渐演变为旋转失速的振动信号,获取8个 振动信号序列,如图4所示。
7-2、将振动信号经滤波预处理之后,利用滑动窗口法,提取每 个窗口信号的时域统计指标和非线性特征熵(样本熵、近似熵、模糊 熵、排列熵),共12个特征值,得到一个96维的特征数据集。时域 统计指标如下表所示:
7-3、设置三个ELM-AE堆叠构成一个基于最大相关熵准则的深 层ELM-AE神经网络,如图5所示。将上一层ELM-AE的输出权重 作为下一层的输入,每个ELM-AE的隐含层神经结点个数分别设置 为60、30和10个。
7-4、设置损失函数的容忍误差为10
7-5、为了验证所提方法的有效性,采用t-SNE对输出特征矩阵 做可视化分析,从聚类性能的角度进行效果评估。将特征融合前后的 所有特征都表示在一个三维特征图上,如图6、7所示。
本发明与现有技术相比,具有如下优点和有益效果:
本发明采用的是最大相关熵代替最小均方误差作为ELM-AE的 损失函数,多个ELM-AE堆栈构成深度神经网络用于多维数据的特 征融合。该算法是一种比传统自编码(AE)算法更为高效的特征融 合算法,可以有效降低输入数据的维度,还可以灵活设置隐含层节点 个数,实现对特征数据集的二次特征融合。通过设置多个ELM-AE 神经网络叠加增强了特征学习能力,不仅适用于小数据集也同样适用 于多维大数据集,具有更好的泛化性能。
本发明采用的是最大相关熵代替最小均方误差作为ELM-AE的 损失函数,解决了复杂情况下,最小均方误差对数据中含有非高斯噪 声,距离较远的离群点不敏感的问题,具有更好的鲁棒性。通过降低 维数实现特征融合的同时,会根据不同的样本误差分配不同的比重, 实现同类样本点更紧凑的聚集,增大不同类样本之间的距离,便于后 期的模式识别。
本发明测试了某轴流压气机从正常工况逐渐演变为旋转失速过 程中振动信号的特征融合效果。将采集的实测振动信号预处理之后, 分别提取正常部分和旋转失速部分的时域统计指标和非线性特征熵, 利用基于最大相关熵的深层神经网络实现特征融合,通过特征可视化, 验证了所提方法的有效性,同时也提高了分类器的准确率。
附图说明
图1:传统自编码器结构示意图;
图2:单隐层前馈神经网络示意图;
图3:单个ELM-AE的网络结构;
图4:某轴流压气机发生旋转失速的实测振动信号;
图5:基于最大相关熵的深层神经网络结构图;
图6:特征融合之前特征空间分布图;
图7:特征融合之后特征空间分布图;
具体实施方式
为了使本发明所要解决的技术问题、技术方案及有益效果更加清 楚、明白,以下结合附图和实施例,对本发明进行进一步详细说明。 应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限 定本发明。
本实施例是一种基于大相关熵准则的深层神经网络,用于多维信 号的特征融合方法。通过最大相关熵准则替换最小均方误差,作为 ELM-AE的损失函数构成深度神经网络,对原始振动信号中提取的多 维特征做特征融合,并将融合之后的特征做可视化分析,验证所提方 法的有效性。
下面结合附图和实例对本发明作进一步说明。
图1为传统的自编码器的结构示意图,第一层是输入层,中间层 是隐含层,最后一层是输出层。利用自编码器的编码和解码过程可以 降低特征维数实现特征级融合。图2为单隐层前馈神经网络的基本结 构,也就是ELM的结构图。ELM的优点是不需要调整网络的输入权 值以及隐含神经元的偏置,并且产生唯一的最优解。图3为单个 ELM-AE的网络结构,也就是自编码器基于ELM作为优化算法,加 快了自编码器的训练速度,避免了梯度下降法陷入局部最优解的缺点。 图4为8个传感器采集轴流压气机从正常转速逐渐演变为旋转失速的 振动信号。图5为本发明采用基于最大相关熵准则的深层神经网络结 构。将上一层ELM-AE的输出权重作为下一层的输入,最后一个 ELM-AE的隐含层输出即为融合之后的特征。图6为特征融合之前的 多维特征空间分布,可以看出融合之前存在一些距离较远的离群点, 同时正常类与异常类之间存在数据掺杂。图7为经过深度神经网络融 合之后的特征空间分布,从聚类性能的角度可以看到,同类数据点达 到更紧凑的聚集,不同类数据之间的空间距离增大,基于最大相关熵 的深度神经网络特征融合方法明显提高了数据聚类性能,后期也有利 于提高分类器的准确率。
本发明主要包括如下步骤:
步骤1、ELM算法总结:
1-1、给定训练集{(x
1-2、随机分配隐含层节点的参数(w
1-3、计算隐含层输出矩阵Η;
1-4、计算隐含层节点和输出节点之间的权重β=H
式中,H
步骤2、最小均方误差原理
2-1、给定训练样本X={x
h=S
S
式中,X是D维向量,h是d维向量,ω
2-2、将向量h经过解码由z=S
2-3、自编码器的训练阶段旨在优化参数集θ={ω
步骤3、ELM-AE多层深度神经网络
3-1、针对单层ELM-AE在掺杂噪声的复杂异常数据集的表征能 力不足的问题,采用堆栈ELM-AE的多层深度神经网络算法,对于 每一层的ELM-AE,其目标函数为:
式中,C是正则化系数,对深度生成的输入权重ω
3-2、输出权重β
3-3、ELM-AE的编码输出为Y=g(β
步骤4、核函数理论
4-1、满足Mercer理论的函数都可以看作为核函数计算特征空间 的点积,函数必须是连续的、正定的。通过核函数,可以将原始数据 点映射到多维Hilbert空间,计算数据样本在多维空间的内积,其表 达式可以表示为:
K(x
式中,Φ(·)表示多维非线性映射过程。
步骤5、最大相关熵准则
5-1、给定两个深度变量X和Y,其相关熵是定义在核空间上的 相关性测量,可表示为:
V(X,Y)=E[<Φ(X),Φ(Y)>
式中,E[·]表示期望,κ(·,·)是Mercer核函数,即 K(X,Y)=<Φ(X),Φ(Y)>
5-2、非线性核函数采用广泛使用的高斯核函数:
5-3、定义核空间上的损失函数C(X,Y)为:
由上式得,最小化C(X,Y)等同于最大化相关熵κ
步骤6、重新定义损失函数
6-1、使用最大相关熵准则代替最小均方误差原理,ELM-AE的 损失函数可以定义为:
6-2、将相关熵取负,因此求最大相关熵等价于最小化负的相关 熵,采用高斯核,式(7)可以重新定义为:
对式(8)求导令其导数为0,求解输出权重,整理得:
记
令
6-3、将上式中含有β
式中,Λ是对角矩阵且
步骤7、深度特征融合
7-1、在某轴流压气机机匣周向均匀布置8个压力传感器,采集 某轴流压气机由正常工况逐渐演变为旋转失速的振动信号,获取8个 振动信号序列。
7-2、将振动信号经滤波预处理之后,利用滑动窗口法,提取每 个窗口信号的时域统计指标和非线性特征熵(样本熵、近似熵、模糊 熵、排列熵),共12个特征值,得到一个96维的特征数据集。时域 统计指标如下表所示:
7-3、设置三个ELM-AE堆叠构建基于最大相关熵准则的深层 ELM-AE神经网络。将上一层ELM-AE的输出权重作为下一层的输 入,每个ELM-AE的隐含层神经结点个数分别设置为60、30和10 个。
7-4、设置损失函数的容忍误差为10
7-5、为了验证所提方法的有效性,采用t-SNE对输出特征矩阵 做可视化分析,从聚类性能的角度进行效果评估。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不 受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下 所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都 包含在本发明的保护范围之内。
- 一种基于最大相关熵准则的多维信号特征融合方法
- 一种基于最大混合互相关熵准则的鲁棒核学习方法