一种新的数据空间离散化算法
文献发布时间:2023-06-19 12:02:28
技术领域
本发明涉及空间数据转换技术领域,具体为一种新的数据空间离散化算法。
背景技术
地理探测器模型是基于空间分层异质性原理来揭示空间分异性背后的驱动因子。现在许多学者将该模型应用于生态环境、区域经济、土地利用、旅游、气象等领域的研究,然而这些领域还有许多如环境因子、社会经济因子等连续型因子数据,例如温度、降水、植被覆盖度、高程、坡度、人口、旅游业总收入等,而地理探测器模型擅长处理的是离散类型因子数据,例如土壤类型、土地利用类型、植被类型、流域类型等,所以连续型因子数据作为空间数据就需要通过数据离散化算法转换为离散型空间数据之后才能导入地理探测器模型进行分析。
现在常用的数据离散化算法有自然断点法、等间距法、几何断点法、分位数法、标准差距离法等,这些算法虽然也能够用于空间数据属性特征的离散化,但均未考虑空间数据的空间特征以及空间实体之间的相关性,空间实体所形成格局的空间分异性,而且各种算法也有各自最适合应用的技术领域,比如分位数法适用于样本容量较大且样本呈线性分布的情况,目前来讲医学领域应用较多,几何断点法是专门为制图而设计的一种数据离散化算法,等间距法对于服从正态分布的数据,该算法效果较好。
目前针对地理探测器模型并且考虑空间特征的数据离散化算法的研究很少,因此从空间数据表现出的空间特征出发,专门为地理探测器模型设计一种空间数据离散化算法,一是能有效弥补传统数据离散化算法的不足,二是能达到提升地理探测器模型精度并降低其应用过程中的不确定性的目的。
发明内容
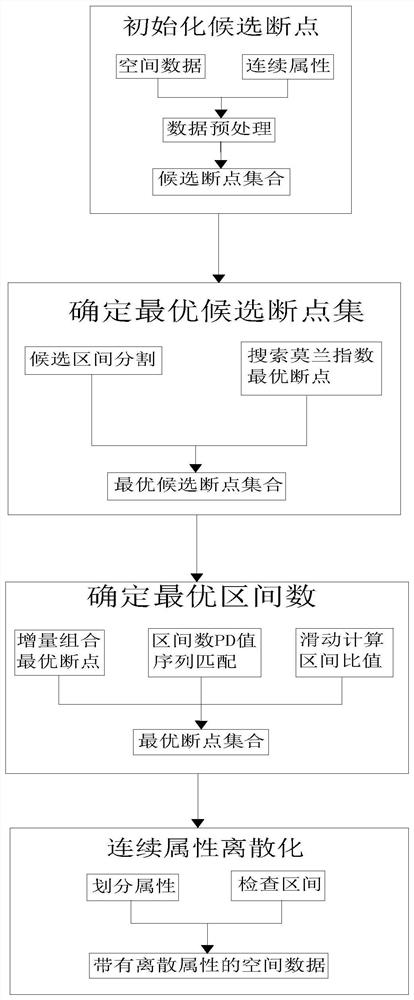
本发明一种新的数据空间离散化算法,包括初始化候选断点、确定最优候选断点集、确定最优区间数、连续属性离散化等步骤,其将空间数据的空间特征引入到空间数据的离散化过程中,同时兼顾了空间数据的空间特征和属性特征,与传统的离散化算法相比,是一种专门针对地理探测器模型并且充分考虑空间特征的数据离散化算法,弥补传统数据离散化算法的不足且提升了地理探测器q值的精准度,有效解决了上述问题。
本发明采用的技术方案:
1、一种新的数据空间离散化算法,其特征在于,包括以下步骤:
(Ⅰ)初始化候选断点:输入已经处理好的空间数据,指定需要离散化的连续属性,对连续属性的所有取值进行数据预处理,得到候选断点集合;
(Ⅱ)确定最优候选断点集:包括候选区间分割和搜索莫兰指数最优断点两个步骤,根据叠置断点法,用候选断点将连续属性取值集合分割为左右两个区间,分别计算分割后左右两个区间的平均值,再用左右区间各自的平均值代替各自区间的所有属性的取值,则空间数据的连续属性取值集合只包含左右区间的两个平均值,然后计算集合的全局莫兰指数,取莫兰指数最大值对应的分割点作为最优离散化断点,再将分割后的左右区间重复上述过程直至满足叠置断点法的终止条件,最后收集所有最优候选断点,得到最优候选断点集合;
(Ⅲ)确定最优区间数:对于最优候选断点集合,经增量组合最优断点、区间数PD值序列匹配、滑动计算区间比值后可确定最优区间数,即根据每个断点分割的区间长度进行降序排序,将集合中的第一个点作为起点,每次从起点开始增量截取断点,直到从起点截取至最后一个断点,得到与最优断点集合的长度相同的断点组合的集合,计算集合中每个断点组合的因子探测值,按照断点组合长度的降序顺序构造与其对应的因子探测值的序列,计算因子探测值与区间长度的比值,由前向后查找,如果遇到后面比值小于前面比值的,则前面位置对应的组合长度值加一为最优区间数,对应的断点组合为最优断点集合;
(Ⅳ)连续属性离散化:对于步骤(Ⅲ)得到的最优断点集合,将指定的连续属性按照断点进行划分并检查区间是否正常,进而得到带有离散属性的空间数据。
叠置断点法:假设有一个方形的地理空间,里面均匀分布的地理单元既包含自变量的属性值又包含因变量的属性值,对所有地理单元的自变量属性的唯一值进行枚举,如果以某一个唯一值作为断点,自变量属性值小于该断点的地理单元聚集在地理空间的左半部分或右半部分,占空间面积一半的区域,称为1号区域,大于该断点的地理单元聚集在另外一个区域,称为2号区域。如果1号区域内地理单元的因变量同样呈现高度的聚集性,同时2号区域内的因变量也呈现出高度的聚集性,通过计算1号区域内因变量和自变量的莫兰指数的差值为0,2号区域同样的差值也为0,则说明地理单元的因变量和自变量具有高度的空间相关性,则该断点为当前地理空间的最优分割点。通过计算划分出的区域内自变量属性值的莫兰指数,如果小于1 则可以继续划分,否则划分结束。由于通过因变量和自变量进行叠置来获取最优断点,所以这种算法命名为叠置断点法,英文全称为 Overlay Break,简称OB算法。当然这是最理想的状态,实际操作中,地理空间并非是完全符合规则的方形,但OB算法可以通过比较1号区域和2号区域的莫兰指数差值的最小值,接近于理想状态差值的程度来确定最优断点,进而使被划分的地理空间尽可能接近于上述理想状态。
全局莫兰指数作为空间自相关性度量的常用指标,它度量地理空间内某个单元的某种属性值或地理现象,与其空间邻近单元之间的相关程度,其既能处理空间数据的属性值,也能处理空间数据的空间位置,引自《Moran,P.A.P.1950.Notes on continuousstochastic phenomena[J].Biometrika,37(1-2):17-23.》。
进一步的,所述初始化候选断点的具体步骤如下:
(1)首先创建一个存储所有候选断点的数组CdCuts,对于指定需要进行离散化的属性X,读取它的每个属性值X
(2)取templist中所有数值的唯一值即全部的候选断点,每个候选断点值为p
(3)初始化一棵空二叉树DivTree,用于离散化过程中收集和组织最优断点集合O;
(4)创建被分割的区间inval,所述inval的初始值为[X
进一步的,所述确定最优CdCuts候选断点集的具体步骤如下:
(1)如果CdCuts中的候选断点个数i大于1则开始遍历CdCuts,取出候选断点p
如果为空则表明还没有产生最优断点,公式1.1为数学领域常见的分段函数。
(2)计算空间数据图层S中的地理要素属性X和Y,其中X左侧区间inval
dfMi
dfMi
(3)根据公式1.4计算inval
mdfMi=min(dfMi
(4)创建一个数组plist,遍历数组CdCuts的过程中,取出第一个p
其中数组plist用于存储遍历过程中产生的所有mdfMi的低值点。
(5)如果DivTree的ROOT为空,则直接创建CurrNode得到O
如果两个判断条件只成立其中一个,则表示当前的O
(6)对于区间inval,首先判断该区间是否同时满足可分割的三个条件:第一个条件Glmi(inval,X)小于t、第二个条件NondivFlag=False、第三个条件区间inval内的地理要素大于30个,如果不满足则执行步骤(7),如果同时满足上述三个条件则继续对区间inval进行划分,通过公式1.5计算CdCuts
待步骤(7)执行完成后通过公式1.1确定区间inval,通过公式 1.6计算CdCuts
如果区间inval不满足上述可分割的三个条件,则第lev层inval的递归到达出口,然后执行步骤(8),待步骤(8)完成后如果此时lev=0 则确定最优候选断点集的步骤已全部完成,否则lev=lev-1,当前的递归层数又回到lev,然后根据公式1.1确定区间inval,如果 CdCuts=CdCuts
如果CdCuts=CdCuts
公式1.5和公式1.6均为分段函数。
(7)对于inval,如果CurrNode的root等于max(CdCuts
(8)对于inval,如果CurrNode的root等于max(CdCuts
(9)对于inval,同时满足以下两个条件NondivFlag=True和 CurrNode的root=max(CdCuts
(10)对于inval,如果满足NondivFlag=True、CurrNode的parentNode 不为空、CurrNode的root=max(CdCuts
在确定最优断点集合的过程中,本方案采用递归算法作为算法的主体结构。
进一步的,所述确定最优区间数的具体步骤如下:
(1)首先通过对DivTree进行中根周游,返回其中保存的最优断点集合O以及每个O
(2)按照区间长度l'对O降序排序,使排序后每个O
(3)增量截取O中的元素,每次截取的断点数量比前一次多1个,得到{O
公式1.7和公式1.8为分段函数,公式1.9引自《Moran,P.A. P.1950.Notes oncontinuous stochastic phenomena[J]. Biometrika,37(1-2):17-23》。
(4)Q为q的集合,对Q降序排序,根据公式2.0计算Q中每个元素的qr值,QR为qr的集合,N
qr=q/N
(5)通过三点滑动查找QR中所有元素的第一个峰值,如果 qr
进一步的,所述连续属性离散化的具体步骤如下:
(1)运用经上述步骤得到的断点集合O对空间数据图层S的属性X 进行划分,首先遍历X,取出X
(2)对于任意的X
公式2.1为分段函数。
(3)把VN写入到空间数据图层S的D属性中;
(4)检查属性D的取值集合中是否存在取值个数小于2的编号值,如果存在将该编号值合并到相邻区间中。
进一步的,所述空间数据为点状矢量数据或面状矢量数据。
进一步的,所述空间数据包含的每个点要素或面要素,同时具有因变量和自变量的属性特征。
综上所述,由于采用了上述技术方案,本发明的有益效果:与传统的离散化算法相比,本申请所提出的一种新的数据空间离散化算法是将空间数据的空间特征引入到空间数据的离散化过程中,同时兼顾了空间数据的空间特征和属性特征,该算法的易实现程度与传统离散化算法相当,但传统的离散化算法需要事先指定离散化的区间数,而本申请提出的算法无需事先指定,通过引入地理探测器q值的优化区间断点组合即可自动计算出最优区间断点,大幅降低了使用地理探测器时空间数据在离散化过程中的不确定性,因此计算结果即地理探测器q值的精准度更高,而且计算更加高效、便捷,是一种专门针对地理探测器模型的数据离散化算法,可在相关领域大规模推广使用。
附图说明
为了更清楚地说明本发明的实例或现有技术中的技术方案,下面将对实施实例或现有技术描述中所需要的附图做简单地介绍,显然,下面描述中的附图仅仅是本发明的一些实例,对于本领域普通技术人员来说,在不付出创造性的前提下,还可以根据这些附图获得其他的附图。
图1一种有效提高地理探测器模型精度的新算法的流程框图;
图2山西和顺县地理位置图;
图3神经管畸形病发病率与本算法得出的高程-坡度图;
图4另外四种常见离散化算法得出的高程图;
图5另外四种常见离散化算法得出的坡度图;
图6坡度与高程根据不同离散化算法得出的q值对比图;
图7坡度与高程在相同区间数根据不同离散化算法得出的q值对比图。
具体实施方式
下面将结合本发明实例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例:
一种新的数据空间离散化算法,如图1所示,包括以下步骤:
(Ⅰ)初始化候选断点:输入已经处理好的空间数据,指定需要离散化的连续属性,对连续属性的所有取值进行数据预处理,得到候选断点集合,具体步骤如下:(1)首先创建一个存储所有候选断点的数组CdCuts,对于指定需要进行离散化的属性X,读取它的每个属性值 X
(Ⅱ)确定最优候选断点集:包括候选区间分割和搜索莫兰指数最优断点两个步骤,根据叠置断点法,用候选断点将连续属性取值集合分割为左右两个区间,分别计算分割后左右两个区间的平均值,再用左右区间各自的平均值代替各自区间的所有属性的取值,则空间数据的连续属性取值集合只包含左右区间的两个平均值,然后计算集合的全局莫兰指数,取莫兰指数最大值对应的分割点作为最优离散化断点,再将分割后的左右区间重复上述过程直至满足叠置断点法的终止条件,最后收集所有最优候选断点,得到最优候选断点集合,具体步骤如下:
(1)如果CdCuts中的候选断点个数i大于1则开始遍历CdCuts,取出候选断点p
(2)计算空间数据图层S中的地理要素属性X和Y,其中X左侧区间inval
dfMi
dfMi
(3)根据公式1.4计算inval
mdfMi=min(dfMi
(4)创建一个数组plist用于存储遍历过程中产生的所有mdfMi的低值点遍历数组CdCuts的过程中,取出第一个p
(5)如果DivTree的ROOT为空,则直接创建CurrNode得到O
(6)对于区间inval,首先判断该区间是否同时满足可分割的三个条件:第一个条件Glmi(inval,X)小于t、第二个条件NondivFlag=False、第三个条件区间inval内的地理要素大于30个,如果不满足则执行步骤(7),如果同时满足上述三个条件则继续对区间inval进行划分,通过公式1.5计算CdCuts
待步骤(7)执行完成后通过公式1.1确定区间inval,通过公式 1.6计算CdCuts
如果区间inval不满足上述可分割的三个条件,则第lev层inval的递归到达出口,然后执行步骤(8),待步骤(8)完成后如果此时lev=0 则确定最优候选断点集的步骤已全部完成,否则lev=lev-1,当前的递归层数又回到lev,然后根据公式1.1确定区间inval,如果 CdCuts=CdCuts
如果CdCuts=CdCuts
(7)对于inval,如果CurrNode的root等于max(CdCuts
(8)对于inval,如果CurrNode的root等于max(CdCuts
(9)对于inval,同时满足以下两个条件NondivFlag=True和CurrNode 的root=max(CdCuts
(10)对于inval,如果满足NondivFlag=True、CurrNode的parentNode 不为空、CurrNode的root=max(CdCuts
(Ⅲ)确定最优区间数:对于最优候选断点集合,经增量组合最优断点、区间数PD值序列匹配、滑动计算区间比值后可确定最优区间数,即根据每个断点分割的区间长度进行降序排序,将集合中的第一个点作为起点,每次从起点开始增量截取断点,直到从起点截取至最后一个断点,得到与最优断点集合的长度相同的断点组合的集合,计算集合中每个断点组合的因子探测值,按照断点组合长度的降序顺序构造与其对应的因子探测值的序列,计算因子探测值与区间长度的比值,由前向后查找,如果遇到后面比值小于前面比值的,则前面位置对应的组合长度值加一为最优区间数,对应的断点组合为最优断点集合,具体步骤如下:
(1)首先通过对DivTree进行中根周游,返回其中保存的最优断点集合O以及每个O
(2)按照区间长度l'对O降序排序,使排序后每个O
(3)增量截取O中的元素,每次截取的断点数量比前一次多1个,得到{O
(4)Q为q的集合,对Q降序排序,根据公式2.0计算Q中每个元素的qr值,QR为qr的集合,N
qr=q/N
通过三点滑动查找QR中所有元素的第一个峰值,如果 qr
(Ⅳ)连续属性离散化:对于步骤(Ⅲ)得到的最优断点集合,将指定的连续属性按照断点进行划分并检查区间是否正常,进而得到带有离散属性的空间数据,具体步骤如下:首先运用经上述步骤得到的断点集合O对空间数据图层S的属性X进行划分,首先遍历X,取出 X
神经管出生缺陷(NTD)作为一种出生缺陷疾病,是导致婴儿死亡和残疾的主要原因之一。生理、遗传倾向、自然环境、社会环境都是导致神经管出生缺陷疾病的原因,不同地区由生理、遗传倾向导致的出生缺陷率相差不大,所以自然环境、社会环境可能是影响区域之间神经管出生缺陷疾病发生差异的主要因素,对这些致病的潜在因素进行量化分析,阐明各个因素对疾病发病率的贡献程度,对于神经管出生缺陷的防治具有重要意义。当前地理探测器的分析结果表明,地质岩性、流域类型、土壤类型、高程、坡度等因子均对NTD产生一定的潜在影响,是疾病发生的环境风险因子,而每个环境风险因子都有一个q值,q值为地理探测器的常用函数值。简单点讲,就是通过计算风险因子在地理探测器中的q值,将不同环境风险因子的q值进行比较,q值大的风险因子说明其对导致神经管出生缺陷疾病的影响更大,即找出了哪些环境风险因子是导致神经管出生缺陷疾病的主因,因此q值的精准度就显得至关重要。
本实施例以山西省和顺县为研究对象,该县是世界上NTD高发的地区之一,风险因子选择的是高程和坡度,两者均为连续型风险因子,所述高程和坡度的数据均通过DEM数字高程模型获取。如图2 所示,和顺县位于山西省境内太行山的西侧,地貌主要为山地和丘陵,相对高差在300-500米,平均海拔高度1300米,包含326个行政村,由于难以获得行政村的具体边界,研究人员以泰森多边形作为研究区域各个行政村的边界。
图3中a表示的是山西省和顺县各个区域每1000人当中NTD的发病率,b表示的是连续型风险因子高程经本算法计算后的离散化结果,c表示的是连续型风险因子坡度经本算法计算后的离散化结果。
图4表示的是连续型风险因子高程经另外4种传统离散化算法计算后的结果,图5表示的是连续型风险因子坡度经另外4种传统离散化算法计算后的结果,4种传统离散化算法分别为a几何断点法,b 分位数法,c自然断点法,d等间距法。
将图3的b图与图4的四幅图做对比,明显看到其精度更高,将图3的c图与图5的四幅图做对比,也是c图的精度更高。
图6表示的是风险因子坡度和高程经不同的离散化算法计算后得出的地理探测器q值,由于OB算法无需区分区间数,因此另外4 种算法选择的区间数为2-8。从图中可知坡度的计算中,OB算法计算出的地理探测器q值为0.131,而另外4种传统离散化算法在区间数2-8的计算结果中,仅有两个结果略高于0.131,有两个结果也是 0.131,其余的均小于0.131,高程的计算中,OB算法计算出的地理探测器q值为0.108,而另外4种传统离散化算法在区间数2-8的计算结果全部小于0.108,由此可见OB算法计算出的地理探测器q值相比于另外4种传统离散化算法,精准度明显提高。
图7表示的是风险因子坡度和高程在相同区间数的情况下,经不同的离散化算法计算后得出的地理探测器q值,从图中可知,风险因子坡度在区间数10经OB算法计算出的地理探测器q值为0.131,另外4种传统离散化算法中,只有自然断点法计算出的q值0.132略高出0.001,其余的均小于0.131,而风险因子高程在区间数11经OB 算法计算出的地理探测器q值为0.108,而另外4种传统离散化算法计算出的q值全部小于0.108,由此可见OB算法计算出的地理探测器q值相比于另外4种传统离散化算法,精准度明显提高。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在发明的保护范围之内。
- 一种新的数据空间离散化算法
- 基于RBF神经网络的经济用水数据空间离散化方法