基于云平台融合多源卫星影像和茶树物候期的茶园自动识别方法
文献发布时间:2023-06-19 12:07:15
技术领域
本发明属于遥感目标识别技术领域,尤其涉及一种基于云平台融合多源卫星影像和茶树物候期的茶园自动识别方法。
背景技术
中国作为世界上主要的茶叶生产国,茶园种植面积和茶叶产量均居世界第一。茶树的种植和生产对农业经济和农业发展起着很大的作用,准确获取茶园种植面积和空间分布可以为政府部门进行茶园规划管理、茶叶估产和灾害预防等处理提供科学支撑。
茶树是常绿阔叶多年生灌木,其在光谱特征上与其他常绿植被十分类似,因此难以将其区分开。目前最常用的茶树提取方法为机器学习(Chuang,Y.-C.M.and Y.-S.Shiu(2016)."A comparative analysis of machine learning with WorldView-2 pan-sharpened imagery for tea crop mapping."Sensors 16(5):594.),通过不同特征组合和算法对茶园进行分类。这类方法的缺陷在于需要大量的本地训练样本,难以制作出一个适用于大区域的精准模型,并且复杂的特征组合和指标可能会出现过拟合的现象,在一定程度上降低结果的准确性,并且这种分类算法,操作复杂,难以推广应用。
发明内容
本发明针对现有遥感识别技术中难以准确区分茶树和常绿植被的技术问题,提出一种基于云平台融合多源卫星影像和茶树物候期的茶园自动识别方法。
为了实现上述目的,本发明采用以下技术方案:
一种基于云平台融合多源卫星影像和茶树物候期的茶园自动识别方法,包括:
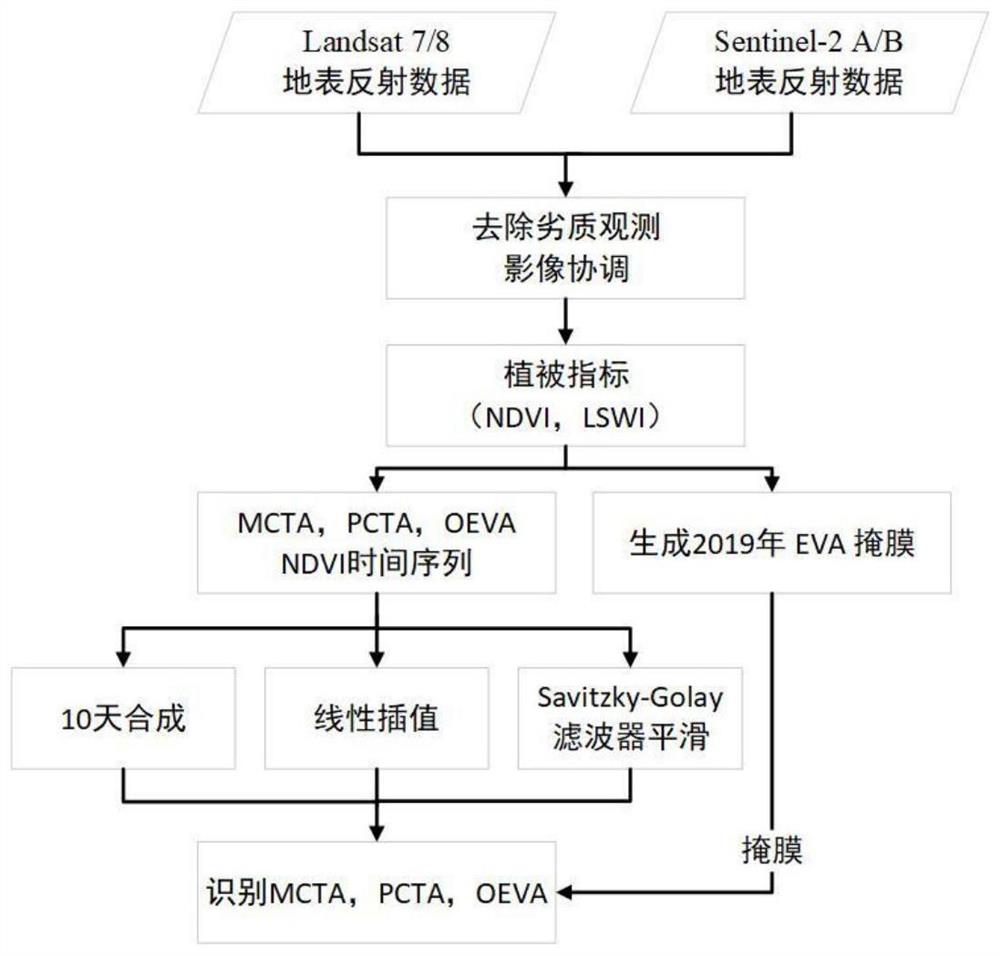
步骤1、基于Google Earth Engine云计算平台获取研究期内研究区域中所有Landsat 7/8和Sentinel-2A/B卫星影像,分别对Landsat 7/8和Sentinel-2A/B卫星影像进行预处理,包括:去云处理和波段协调,得到卫星影像数据集;
步骤2:基于所述卫星影像数据集,获取归一化植被指数和地表水分指数时间序列,即获取NDVI和LSWI时间序列;
步骤3、根据步骤2中得到的NDVI和LSWI时间序列,提取常绿植被区域EVA,得到EVA分布图;
步骤4、结合纯茶园、混合茶园和其他常绿植被的参考样本数据,利用卫星影像数据集,分别创建纯茶园区域MCTA、混合茶园区域PCTA和其他常绿植被区域OEVA的NDVI时间序列数据集;
步骤5、对步骤4得到的MCTA、PCTA和OEVA的NDVI时间序列数据集进行处理,得到MCTA、PCTA和OEVA的平均NDVI时间序列数据集;
步骤6、根据步骤5中得到的平均NDVI时间序列数据集,根据茶树存在人为采摘和修剪的人工管理方式导致的物候特征,提取MCTA与PCTA、OEVA的分类物候指标,生成分类物候指标直方图;
步骤7、根据步骤6中得到的分类物候直方图构建MCTA识别模型;
步骤8、根据步骤7中构建的MCTA识别模型对步骤3中得到的EVA分布图进行分类,得到MCTA分布图;
步骤9、利用步骤8中得到的MCTA分布图对步骤3中得到的EVA分布图进行掩膜处理,得到非MCTA的常绿植被分布图;
步骤10、根据步骤5中得到的平均NDVI时间序列数据集,根据PCTA区存在落叶林和茶树共存特征的种植模式,提取PCTA与OEVA的分类物候指标,生成PCTA与OEVA分类的物候指标直方图;
步骤11、根据步骤10中得到的PCTA与OEVA分类的物候指标直方图构建PCTA识别模型;
步骤12、根据步骤11中构建的PCTA识别模型对步骤9中得到的非MCTA的常绿植被分布图进行分类,得到PCTA分布图;
步骤13、利用步骤8中得到的MCTA分布图和步骤S11中得到的PCTA分布图对步骤3中得到的EVA分布图进行掩膜处理,得到OEVA分布图。
进一步地,所述对Landsat 7/8和Sentinel-2A/B卫星影像进行预处理包括:
利用FMask算法对所述卫星影像进行观测值提取,去除云、云阴影、卷云和冰/雪覆盖的观测值;再利用最小二乘法将Landsat 7和Sentinel-2A/B的波段反射率协调至Landsat 8标准,获得可相互比对的卫星影像数据集。
进一步地,所述步骤5中,按照如下方式对NDVI时间序列数据集进行处理:
计算每10天NDVI的最大值作为综合NDVI值,获得等时间间隔时间序列NDVI数据集;在缺失10天的观测值的地区,根据10天前、后的观测值进行线性插值;使用Savitzky-Golay滤波器对NDVI数据集进行平滑处理。
进一步地,所述步骤3包括:
按照如下方式提取常绿植被区域EVA:
LSWI>0 and Freq>90%
NDVI
其中Freq为LSWI大于0的观测频率,NDVI
进一步地,所述步骤6包括:
根据茶的生长特征,将一年分为7个时期,分别为1年的第0-50天,第50-120天,第120-180天,第180-240天,第240-290天,第290-330天和第330-360天,按照时间顺序分别命名为TW1~TW7,根据TW1~TW7来提取用于分类的物候指标。
进一步地,所述步骤6中,MCTA与PCTA、OEVA的分类物候指标包括:TW2时期识别到的第一个峰值SDP
进一步地,所述步骤7中,MCTA识别模型为:
50 进一步地,所述步骤10中,PCTA与OEVA的分类物候指标包括:TW5时期的绿色衰退速率GAS;TW6时期识别到的第一个峰值SDP 进一步地,所述绿色衰退速率GAS的计算方式如下: TW5时期第一个NDVI值和TW5时期低谷的NDVI值的差值与二者日期跨度的比值,如果没有识别到TW5时期低谷则将TW5时期最后一个NDVI值进行替换。 进一步地,所述步骤11中,PCTA识别模型为: GAS>0.001&270 与现有技术相比,本发明具有的有益效果: (1)本发明充分利用了茶园存在的人工管理方式和人工种植模式导致的独特物候指标,更符合茶园的真实生长规律,生成的物候指标地图对茶园的生长监测具有指导意义; (2)本发明可以提取过去和预测未来的茶种植面积,为茶园等其他地物的识别提供了一种新的研究思路; (3)本发明融合了研究区和研究期内所有Landsat 7/8和Sentinel-2A/B卫星影像,有利于捕捉茶园的关键物候期,有效提高了茶园识别的精度,实现了基于云计算平台耦合多源卫星影像和茶树物候期的茶园自动化识别。 附图说明 图1为本发明实施例一种基于云平台融合多源卫星影像和茶树物候期的茶园自动识别方法的流程图; 图2为本发明实施例生成的EVA分布图; 图3为本发明实施例生成的MCTA、PCTA、OEVA分布图; 图4为本发明实施例生成的分类物候指标直方图。 具体实施方式 下面结合附图和具体的实施例对本发明做进一步的解释说明: 如图1所示,一种基于云平台融合多源卫星影像和茶树物候期的茶园自动识别方法,包括: S1、基于Google Earth Engine云计算平台获取研究期(茶树一个完整生命周期)内研究区域中所有Landsat 7/8和Sentinel-2A/B卫星影像,分别对Landsat 7/8和Sentinel-2A/B卫星影像进行预处理,包括:去云处理和波段协调,得到卫星影像数据集;作为一种可实施方式,以2019年为研究期,以河南省信阳市浉河区为研究区域。 进一步地,所述对Landsat 7/8和Sentinel-2A/B卫星影像进行预处理包括: 利用FMask算法对所述卫星影像进行观测值提取,去除云、云阴影、卷云和冰/雪覆盖的观测值;再利用最小二乘法将Landsat 7和Sentinel-2A/B的波段反射率协调至Landsat 8标准,获得可相互比对的卫星影像数据集。 S2、基于所述卫星影像数据集,获取归一化植被指数和地表水分指数时间序列,即获取NDVI和LSWI时间序列; 具体地,NDVI和LSWI计算公式分别为:
其中ρ S3、根据步骤S2中得到的NDVI,LSWI时间序列数据集,提取常绿植被区域EVA,得到EVA分布图; 进一步地,按照如下方式提取常绿植被区域EVA: LSWI>0 and Freq>90% NDVI 其中Freq为LSWI大于0的观测频率,NDVI S4、结合纯茶园、混合茶园和其他常绿植被的参考样本数据,利用卫星影像数据集,分别创建纯茶园区域MCTA、混合茶园区域PCTA和其他常绿植被区域OEVA的NDVI时间序列数据集;具体地,通过实地调查和谷歌影像目视解译收集了550个EVA样本点和456个Non-EVA地面参考数据样本点,利用样本点分别创建MCTA、PCTA和OEVA的NDVI时间序列数据集。 S5、对步骤S4得到的MCTA、PCTA和OEVA的NDVI时间序列数据集进行处理,得到高质量MCTA、PCTA和OEVA平均NDVI时间序列数据集; 进一步地,处理方式为:首先计算10天所有NDVI最大值作为综合NDVI值,获得等时间间隔时间序列NDVI数据集,其次基于10天前、后的高质量观测值对空隙进行线性插值,最后使用Savitzky-Golay滤波器(S-G滤波器)平滑NDVI时间序列数据集。 S6、根据步骤S5中得到的平均NDVI时间序列数据集,根据茶树存在人为采摘和修剪的人工管理方式导致的物候特征,提取MCTA与PCTA、OEVA的分类物候指标,生成分类物候指标直方图; 具体地,我们计算了处理后MCTA,PCTA和OEVA的平均NDVI时间序列曲线。根据现场调查获取的信息,单独种植的茶在2月下旬开始发芽(NDVI逐渐上升),并于4月份达到生长旺盛期(NDVI达到局部峰值),此时茶进行第一轮采摘(NDVI下降),直到4月下旬进行修剪(NDVI产生一个谷底)。修剪后的茶继续生长,于8月份再次达到生长旺盛期(NDVI达到局部峰值),此时茶进行第二轮采摘(NDVI下降),此后茶将持续生长至11月下旬,随后进入越冬期。根据茶的生长特征,我们将一年分为7个时期,这7个时期的DOY分别为0-50,50-120,120-180,180-240,240-290,290-330和330-360,按照时间顺序将其命名为TW1~TW7。我们将根据TW1~TW7这7个时间窗口来提取用于分类的物候指标。 根据步骤S5中得到的平均NDVI时间序列数据集,发现在TW2~TW4期间,混合茶园区域PCTA的板栗和OEVA一直处于生长状态,因此NDVI时间序列在视觉上没有明显的下降趋势。此外,MCTA在一年中的峰值个数大于PCTA/OEVA。根据这些特征,通过提取TW2~TW4期间产生的峰值,低谷和TW1~TW7期间的峰值个数建立MCTA、PCTA和OEVA的分类物候指标,生成分类物候指标直方图; 进一步地,MCTA与PCTA、OEVA的分类物候指标为:SDP1,SDV,SDP2和NP。其中TW1~TW7为一年内7个时间窗口,TW1时期识别到的第一个峰值为SDP1(start date of peak1),TW2时期识别到的第一个低谷为SDV(start date of valley),TW3时期识别到的第一个峰值为SDP2(start date of peak2),TW1~TW7时期识别到的峰值个数为NP(number ofpeak)。 具体地,识别峰值和低谷的方法为:识别NDVI时间序列中的局部最大值为峰值,识别NDVI时间序列中的局部最小值为低谷,如果某个时间的NDVI值高于该时间之前和之后的NDVI值,则将其定义为峰值,如果某个时间的NDVI值低于该时间之前和之后的NDVI值,则将其定义为低谷。 S7、根据步骤S6中得到的分类物候直方图构建MCTA识别模型; 进一步地,所述MCTA识别模型为: 50 S8、根据步骤S7中构建的MCTA识别模型对步骤S3中得到的EVA进行分类,得到MCTA分布图。 S9、利用步骤S8中得到的MCTA分布图对步骤S3中得到的EVA分布图进行掩膜处理,得到非MCTA的常绿植被分布图。 S10、根据步骤S5中得到的高质量MCTA、PCTA和OEVA平均NDVI时间序列数据集;发现在TW5时期,板栗落叶造成NDVI大幅下降,而常绿植被则保持稳定或下降缓慢;在TW6时期,PCTA由于茶叶持续生长,因此NDVI会短暂上升;在TW7时期,PCTA由于板栗落叶,NDVI值会低于OEVA;根据这些特征,进一步提取PCTA与OEVA的分类物候指标,生成PCTA与OEVA分类的物候指标直方图; 进一步地,PCTA与OEVA的分类物候指标为:GAS,SDP3和NDVI_median。其中TW1~TW7为一年内7个时间窗口,TW5时期的绿色衰退速率为GAS(green-attenuation speed),TW6时期识别到的第一个峰值为SDP3(start date of peak3),TW7时期的NDVI中位数为NDVI_median; 具体地,所述绿色衰退速率GAS的计算方式如下: TW5时期第一个NDVI值和TW5时期低谷的NDVI值的差值与二者日期跨度的比值,如果没有识别到TW5时期低谷则将TW5时期最后一个NDVI值进行替换。 S11、根据步骤S10中得到的PCTA与OEVA分类的物候指标直方图构建PCTA识别模型; 进一步地,PCTA识别模型为: GAS>0.001&270 S12、根据步骤S11中构建的PCTA识别模型对步骤S9中得到的非MCTA的常绿植被分布图进行分类,得到PCTA分布图; S13、利用步骤S8中得到的MCTA分布图和步骤S12中得到的PCTA分布图对步骤S3中得到的EVA分布图进行掩膜处理,得到OEVA分布图。 为验证本发明效果,通过本发明方法,我们生成了2019年浉河区的30m的常绿植被地图,如图2所示。2019年浉河区常绿植被的面积为59,176ha,主要集中在研究区中部的南湾水库和海拔较高的山区。在图2的a)部分随机抽取4个地区:b、c、d、e,4个区域的Google图像显示在b1)、c1)、d1)和e1)中,本发明的分类结果显示在b2)、c2)、d2)和e2)中。通过本发明方法,我们生成了2019年浉河区30m的MCTA,PCTA和OEVA地图,如图3所示。2019年浉河区MCTA,PCTA和OEVA的面积分别为27,471ha,10,844ha和20,861ha,茶的总种植面积为38,315ha。在图3的a)部分随机抽取4个地区:b、c、d、e,4个区域的Google图像显示在b1、c1、d1和e1中,本发明的分类结果显示在b2、c2、d2和e2中。通过图2,图3可以看出常绿植被和茶园种植区得到了完整识别,同时从局部放大图可以看出地块的边界等纹理信息完整,道路和其他地物被有效区分,说明了本发明对茶园识别的可靠性,准确性。 图4中a)~d)为通过本发明得出的MCTA分类物候指标地图,图4中e)~g)为通过本发明得出的PCTA分类物候指标地图。从MCTA的物候指标地图来看,SDP1有91.77%出现在60~80d内,这个时期的茶叶初冒绿芽,是该地区品种“信阳毛尖”质量最佳时期,因此也是浉河区大部分茶场开始采摘的日期。SDV有69.75%在150d之前,这表明大多数的茶在六月前便完成了修剪。而研究区中部的南湾水库茶场由于环境和地型的优势,采茶周期较其他地区更长,因此修剪日期也更延后。SDP2未展现出空间分布上明显的规律,这表明这个时期的不同地区有着不同的采摘习惯。由于茶叶在三月过后一直处于生长状态,即使由于采摘导致的NDVI下降,也会因为长出新叶而导致NDVI上升,因此可能会在一年中检测到多个峰值,如图4中d)所示,有97.65%的NP超过了2个。从PCTA的物候指标地图来看,由于板栗的落叶和秋季茶叶的采摘,该地区GAS在0.0016之上。在这过后,茶持续生长,92.16%的PCTA在310之前再次达到生长旺盛期。进入越冬期后,由于板栗的落叶缓冲了大部分的绿色,冬季的NDVI_median小于0.6。 具体地,通过实地调查和谷歌影像目视解译来获取地面参考数据作为训练样本和验证样本。首先,我们设定了两条调查路线,分别为南湾水库茶叶种植园和G107国道两边的高山茶种植区。在调查的过程中,收集了常绿植被(包括MCTA、PCTA,OEVA),落叶植被,耕地,水体和不透水面的样本点,并拍摄了他们的地理参考照片。第二,将实地调查的样本点定位到谷歌影像中,通过人眼识别不同区域表面的特征和纹理,结合谷歌地球历史影像,目视解译以获得样本点。最终,我们获得了550个EVA验证栅格(36,685个像素)和421个Non-EVA验证栅格(28,501个像素),其中MCTA有279个(18,609个像素),PCTA有106个(7,070像素),OEVA有165个(11,006个像素)。首先,我们使用EVA验证栅格和Non-EVA验证栅格与生成的获得的常绿植被分类结果计算了混淆矩阵,结果如表1所示,其中总精度为95.38%,Kappa系数为0.91,EVA的用户精度和生产精度分别为94.59%和96.40%。从精度评价来看,这表明我们精准的提取出了浉河区的常绿植被,为下一步的算法提供了良好的基础。第二,我们使用MCTA,PCTA和OEVA验证栅格与生成的茶分类结果计算了混淆矩阵,结果如表2所示。其中总精度为87.59%,Kappa系数为0.80,MCTA,PCTA和OEVA的用户精度分别为95.21%,71.24%和85.19%,生产者精度分别为97.90%,71.72%和81.09%。从精度评价来看,MCTA的提取的精度最高,这表明MCTA与PCTA/OEVA之间的差异较大,更容易提取。而PCTA和OEVA的生长曲线较为相似,容易产生混淆,从而导致种植面积被低估或高估。总体而言,本次研究的精度和Kappa系数较高,地面参考数据与分类结果之间具有很强的一致性,证明了本发明的有效性、可靠性和科学性。 表1
表2
综上,本发明以2019年河南省信阳市浉河区为案例,提供了一种可用于提取其他地区,其他年份,其他地物种类的研究思路,分类规则是根据目标作物在不同时期独特的物候表现而建立的。在其他地区,由于不同的环境因素,例如地型,气候,海拔或种植管理活动,茶表现的物候特征可能会有所不同,因此可以通过修正阈值来使模型更贴切研究区域的真实情况。由于茶是多年生的常绿植被,在连续的年份里,茶种植区域的变动极小,因此使用本发明可以提取和预测过去和未来的茶种植面积。这种基于物候的算法也可用于其他作物的识别,例如水稻、小麦、玉米、大豆和甘蔗等。 此外,生成的物候指标地图对茶的生长监测具有指导意义。我们生成这些物候指标地图的意义在于,首先,它可以为地方政府,茶园主提供有关茶的种植信息以更好地制定未来的种植政策茶,或为小户茶农,茶叶作坊提供茶在不同时期的生长特征和季节动态以更好地管理和监测茶的生长过程。第二,它证明了茶在不同种植模式下物候特征的差异,为今后大规模的基于物候茶种植面积的提取提供先行方案和科学依据。 目前有关于茶种植面积提取的研究较少,主要提取的方法是机器学习中的监督分类。需要补充的一点是,机器学习使用的是特征组合和光谱差异,提取这些差异的来源可能是某一幅影像或某一个特定时期。本发明监测的是茶在一年生命周期中的生长状况,分析并提取了每个时期茶的物候特征情况,并基于此建立了识别规则。这相较于其他算法,本发明提取的特征更符合茶的真实生长规律,更能捕捉到茶树的特征。 以上所示仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 基于云平台融合多源卫星影像和茶树物候期的茶园自动识别方法
- 基于云平台融合多源卫星影像和茶树物候期的茶园自动识别方法