一种基于MAP算法的卷积Turbo码译码器及译码方法
文献发布时间:2023-06-19 12:11:54
技术领域
本发明涉及通信领域硬件实现技术领域,更具体地说,涉及一种基于MAP算法的卷积Turbo码译码器及译码方法。
背景技术
Turbo码又称并行级联卷积码(Parallel Concatenated Convolutional Code,PCCC),它在实现随机编码思想的同时,通过交织器实现了由短码构造长码的方法,并采用软输出迭代译码来逼近最大似然译码。Turbo码充分利用了Shannon信道编码定理的基本条件,因此得到了接近Shannon极限的性能。
在802.16e协议中,引入了一种卷积Turbo码(Convolutional Turbo Code,CTC)作为一种可选的信道编码。CTC是一种并行双二进制输入的Turbo码,它不需要结尾比特使编码器状态归零,而只是保证编码器的首尾状态相同。与传统的Turbo码相比,CTC具有迭代收敛性强、码字最小距离特性被改善、码率提高的特点。
最大后验概率(Maximum A Posterori,MAP)算法是一种用来估计无记忆噪声下的马尔可夫过程的最优算法。1993年Turbo码被提出后,MAP算法得到了广泛的应用。MAP算法不仅可以译出序列的比特值,同时还能输出关于每比特译出的可靠性信息,非常符合Turbo码的迭代译码特性。
MAP算法的运算中包含大量的乘法和加法,还有数字电路中较难实现的指数和对数运算,不适合应用。Koch和Baier及Erfanian等人提出的Max-Log-MAP算法,在计算中进行了一定的近似,省去了指数和对数运算,大大地简化了MAP算法的复杂性。在Turbo硬件译码器中被广泛的使用。
同时,专用集成电路(Application-Specific Integrated Circuit,ASIC)是为特定用户和电子系统的需求而设计和制造的集成电路,与通用的架构相比具有高性能、低成本、硬件开销小的优势。如何在保证算法性能与硬件可靠性的条件下,降低硬件功耗,减小开销,且能具有较好的算法适应性成为了ASIC领域的重要研究方向之一。
现有的卷积Turbo译码硬件实现在实际中存在着以下几个问题:
1、现有的卷积Turbo译码器的主频通常不高,导致吞吐率有限,且不便在高主频SoC中集成;
2、现有的卷积Turbo译码器的交织方法较为固定,无法兼容不同的交织标准;
3、现有的Turbo译码器多采用滑窗结构,对卷积Turbo码的衔尾比特特性支持不好。
发明内容
1.要解决的技术问题
针对现有技术中存在的CTC译码器不便在高频集成、无法兼容不同的交织标准、对卷积Turbo码的衔尾比特特性支持不好等问题,本发明提供一种基于MAP算法的卷积Turbo码译码器及译码方法,综合考虑硬件实现的精度、面积功耗和迭代周期方面,设计高主频、可变交织的高性能CTC译码器,提出硬件友好的CTC译码方案并进行对应的硬件实现,提高通信系统的性能。
2.技术方案
本发明的目的通过以下技术方案实现。
本发明提出一种基于MAP算法的卷积Turbo码译码器及译码方法,可以有效降低译码的复杂度,提升硬件实现的主频和吞吐率,进而提高整个系统的性能。
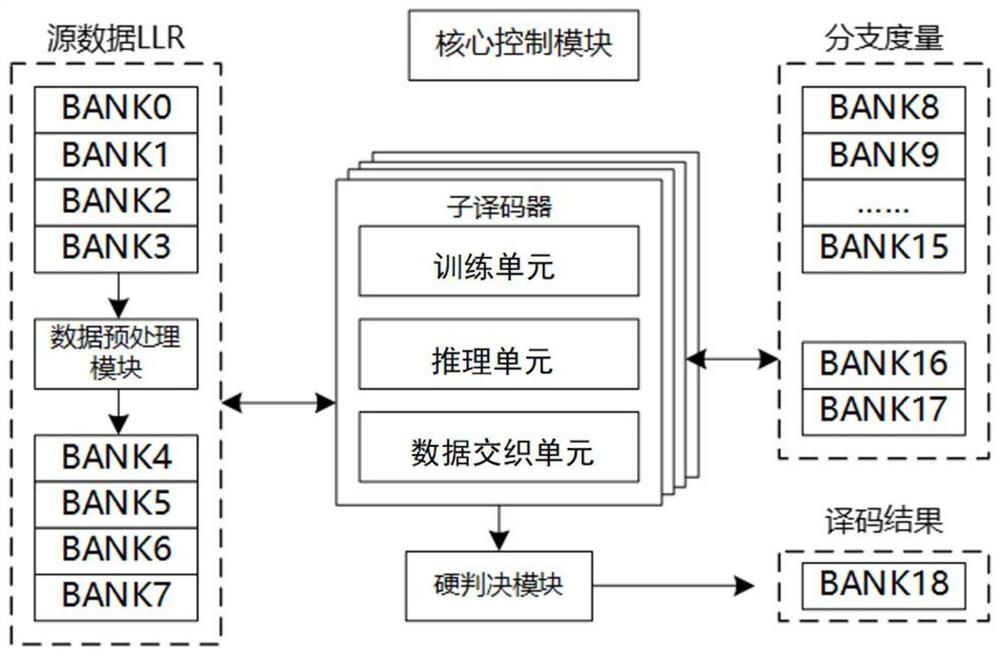
一种基于MAP算法的卷积Turbo码译码器,包括数据预处理模块、子译码器模块和硬判决模块,数据与处理模块与子译码器模块连接,子译码器模块还连接硬判决模块,数据预处理模块用于对输入编码数据进行切分和预交织,子译码器模块对数据预处理模块发送的数据进行训练、推理和数据交织,硬判决模块对子译码器模块多次迭代计算后数据进行硬判决;
所述译码器还包括核心控制模块和存储器,核心控制模块与数据预处理模块、子译码器模块和硬判决模块均连接,用于进行计算任务的调度和数据流的衔接;存储器与数据预处理模块、子译码器模块和硬判决模块均连接,用于存储译码器中各模块数据。
本发明在数据预处理模块输入交织图像用于译码内交织的控制,可以支持到802.16e协议之外非标准的交织器类型。
优选的,子译码器模块包括若干译码器计算单元,每个译码器计算单元均包括训练单元、推理单元和数据交织单元,训练单元的输出端连接推理单元的输入端,推理单元的输出端通过数据交织单元与训练单元的输入端连接,推理单元的输出端同时也是子译码器的输出端;训练单元用于计算分支度量值,推理单元用于计算外信息,数据交织单元用于将计算出的外信息再次送入子译码器模块迭代计算。
优选的,编码数据在数据预处理模块分成的数据子块通道数不大于子译码器模块的译码器计算单元数量。本发明实现卷积Turbo码的分块并行译码,分割的数据子块数不大于子译码器模块的译码器计算单元数量,各译码器计算单元并行处理,提高译码器性能。本发明可根据不同的子块长度N调用不同的并行度,为了保证译码效果,子块长度N不得小于24。
优选的,每个译码器计算单元包括四个加法器,两个比较器和两个选择器;
第一加法器的输出端、第二加法器的输出端和第一选择器的输出端均连接第四加法器,第四加法器的输入信号还包括编码数据的校验位对数似然比,第一加法器的输入信号为编码数据系统位对数似然比,第二加法器的输入信号为编码数据先验信息的对数似然比,第一选择器的输入信号第三加法器的输出信号以及迭代度量值,第三加法器的输入信号为分支度量信号;
第四加法器的输出端连接第二选择器的输入端,第二选择器的输出端连接第一比较器和第二比较器,第二比较器的输出信号归一化操作后反馈至第一选择器的迭代度量值输入。
优选的,选择器包括训练模式和推理模式,在训练单元计算时选择器处于训练模式,在推理单元计算时选择器处于推理模式。
本发明基于MAP的卷积Turbo译码器硬件实现结构简单,易于实现,支持非标准卷积Turbo码的硬件译码,可配置型强,在芯片面积减小的基础上保证译码器译码性能,使用数据交织单元提高译码器的并行度,提升译码器的吞吐率,适于广泛应用。
一种基于MAP算法的卷积Turbo码译码方法,使用所述的一种基于MAP算法的卷积Turbo码译码器,包括以下步骤:
步骤1:在数据预处理模块通过外部配置对译码器配置交织图样,设置译码器的迭代信息,将输入的编码信息拆分为若干通道数据子块并进行预交织处理;
步骤2:子译码器模块根据输入的编码信息训练分支度量值,推理外信息及进行数据交织,通道间边界信息在相邻的译码器计算单元之间双向交换;
步骤3:重复步骤2进行数据迭代计算,当子译码器模块中数据的迭代次数等于设定值时,子译码器模块将软比特输出发送至硬判决模块,完成判决。
经过信道的输入卷积Turbo编码信息拆分为若干通道数据子块送入单一软输入软输出译码器中进行译码,软输入软输出译码器可以保留每个码字的对数似然比信息,进行迭代译码时可以提高性能。
子译码器模块中的通道间边界信息在相邻的译码器计算单元之间双向交换,交换方法为前一个通道的最后一个前向分支度量Alpha赋值给后一个通道的第一个前向分支度量Alpha,后一个通道的第一个后向分支度量Beta赋值给前一个通道的最后一个后向分支度量Beta。
Alpha
Beta
其中,i表示子译码器模块中的第i个通道,start表示该通道第一个分支度量,end表示该通道最后一个分支度量。
优选的,子译码器模块训练单元根据输入编码信息的系统位、校验位和软比特输出训练分支度量值,所述分支度量值包括前向分支度量和后向分支度量;
子译码器推理单元根据输入编码信息的系统位、校验位、软比特输出和分支度量值推理得到外信息。
优选的,前向分支度量和后向分支度量在同一硬件流水线上并行计算。前向分支度量和后向分支度量共享第一级与第三级流水,数据以交织的方式送入训练单元,填充了流水线迭代计算的空闲时间。
优选的,子译码器模块训练单元输出的分支度量值进行归一化处理,子译码器模块推理单元输出的外信息使用自适应系数调整。子译码器的训练单元使用定值归一化方法进行归一化处理,当一组分支度量中有某个值大于归一化边界b时,这组分支度量会执行归一化,所有的度量将减去b,抑制译码器中分支度量的增长。
优选的,子译码器模块推理单元使用移位和查找表方法计算外信息。本发明在推理单元使用移位和查找表方法替代定点数乘法,得到更高的时钟频率和更小的面积,避免硬件设计中因为乘法器设置产生较大的面积开销,以及降低对时序有影响。
本发明公开的译码方法基于所述硬件结构,结合该硬件结构实现基于MAP的卷积Turbo码译码,在译码过程中采用自适应并行度,在有限存储的情况下平衡窗口大小与分块的长度,确保通信硬件系统中的性能和精度要求。同时在计算单元中使用交替式流水线迭代方法,极大降低计算资源开销与译码延时,高可配置性符合通信系统中的传输要求,性能好且适配性高。
3.有益效果
相比于现有技术,本发明的优点在于:
本发明公开一种基于MAP的卷积Turbo码译码器硬件实现,硬件设计可配置性强,支持非标准卷积Turbo码的硬件译码。对比目前存在的卷积Turbo码译码器方案,具有面积优势和时序优势,同时可以达到精确度要求,进而提高整个系统的性能。
本发明译码方法基于所述硬件结构,有效地提高芯片主频、提高译码器吞吐率、降低硬件开销和译码复杂度。本发明在硬件结构中使用移位和查找表单元替代乘法器和求模,将计算分割为流水线,优化电路的时序,提高芯片主频。
本发明在子译码器计算时先通过数据预处理模块进行分块和预交织,将分块后的数据并行输入子译码器模块计算,提高译码的并行度,进而提升译码器的吞吐率。同时在硬件上使用外部配置的可变交织器,通过外部配置的交织图样,实现内部交织的可变性以及硬件实现的轻量化。
附图说明
图1是本发明基于MAP的卷积Turbo码译码器硬件模块示意图;
图2是本发明基于MAP的卷积Turbo码译码方法流程图;
图3是本发明子译码器模块运算流水线硬件结构示意图;
图4是本发明子译码器模块的结构示意图。
具体实施方式
下面结合说明书附图和具体的实施例,对本发明作详细描述。
实施例1
本实例公开一种基于MAP算法的卷积Turbo码译码器的硬件实现,如图1所示,所述译码器包括数据预处理模块、子译码器模块和硬判决模块,数据预处理模块对输入数据进行预处理,将预处理后数据发送至子译码器模块,子译码器模块对数据预处理模块发送的数据进行训练、推理和数据交织,多次迭代后将数据发送至硬判决模块进行硬判决,作为译码的结构输出,所述译码器还包括核心控制模块和存储器,核心控制模块与数据预处理模块、子译码器模块和硬判决模块均连接,进行计算任务的调度和数据流的衔接,存储器也与数据预处理模块、子译码器模块和硬判决模块均连接,用于对译码器中各模块数据进行存储。
如图1所示,数据预处理模块用于处理外部输入的交织图样并根据交织图样对输入码字进行预交织,在预交织过程中对码块进行切分,将子码块放置在各通道源数据区。所述数据预处理模块包括若干存储单元,所述存储单元连接输入外部输入的交织图样、迭代信息和经过卷积Turbo编码的LLR序列。数据预处理模块在数据处理时将数据从动态存储器DRAM搬运至静态存储器SRAM,虽然DRAM具有比SRAM更大的存储空间,但是SRAM的存储和读取数据的速度更快,因此本实施例存储器使用SRAM,加快译码器的运算速度。
子译码器模块包括若干译码器计算单元,每个译码器计算单元均包括训练单元、推理单元和数据交织单元,如图4所示译码器计算单元结构示意图,训练单元的输出端连接推理单元的输入端,推理单元的输出端通过数据交织单元与训练单元的输入端连接,推理单元的输出端也连接硬判决模块的输入端。数据预处理模块将编码信息拆分成若干通道数据子块后并行输入子译码器模块,子译码器模块并行译码,提高译码效率。
译码器计算单元流水硬件结构如图3所示,包括四个加法器,两个比较器和两个选择器,选择器在训练单元计算时处于训练模式,选择器在推理单元计算时处于推理模式。
第一加法器的输出端、第二加法器的输出端和第一选择器的输出端均连接第四加法器,第四加法器的输入端还接收编码数据校验位输出的LLR,其中第一加法器为系统位加法器,第一加法器的输入端连接系统位的LLR,第二加法器为先验信息加法器,第二加法器的输入端连接先验信息的LLR,第一选择器为分支度量选择器,第一选择器的输入端为前向分支度量Alpha与后向分支度量Beta之和(通过第三加法器实现),以及迭代度量值,第一选择器在训练模式选通迭代度量值,在推理模式下选通第三加法器的输出端;第四加法器的输出端连接第二选择器的输入端,第二选择器对多个第四加法器的输出值进行比较,输出最大值;第二选择器的输出端分别连接第一比较器和第二比较器,第一比较器为八输入比较器,第二比较器为四输入比较器,第二选择器在训练模式选通第二比较器,在推理模式选通第一比较器,第二比较器的输出端通过归一化单元反馈至第一选择器的迭代度量值输入端。
子译码器模块训练单元控制每个通道数据子块对应的的子译码器读取子块的系统位与校验位,通过MAP算法递推计算前向分支度量与后向分支度量后,将数据发送至中间结果存储器。分支度量的基本计算公式为:
A
B
其中,A
训练单元每算完一次分支度量之后,均进行归一化处理。即将所有的分支度量与归一化边界b做比较之后,如果含有大于b的分支度量,则所有分支度量都减去分支度量边界b。本实施例中分支度量边界b设为8。
子译码器模块推理单元在前向分支度量与后向分支度量计算完成后,使用前向分支度量与后向分支度量联合推理出软比特输出信息L
根据前向分支度量Alpha与后向分支度量Beta推理软比特输出信息L
L
根据L
L
自适应系数根据译码需要进行缩小或增大,本实施例中自适应系数为0.75。
数据交织单元在子译码器一次译码完成后,变更交织或解交织数据,将根据软比特输出信息L
核心控制模块控制将解调后的编码码字发送至译码器,并控制中间结果数据的存取以及译码的迭代,将译码器输入L
硬判决模块用于在子译码器模块迭代结束后对子译码器模块的软比特输出进行硬判决。当迭代次数i达到N
实施例2
本实施例基于实施例1公开的译码器硬件实现方法,详细说明所述译码器的译码流程。如图2所示,所述基于MAP算法的卷积Turbo码译码方法包括以下步骤:
步骤1:设置译码器的交织图样和迭代信息,将编码后的码字比特信息输入数据预处理模块进行数据预交织处理。
译码开始时,将交织图样从外部DRAM配置进入译码器的交织图样存储区中,并将输入的码字子块切分为多通道进行预交织。对于输入的经过信道的卷积Turbo编码,将其按码字顺序输入数据预处理模块,所述码字顺序即协议中固定的从外部输入的编码后顺序。
数据预处理模块根据协议所规定的方法计算出的交织所需要的地址索引,一一对应的地址映射,使交织图样完成数据的预处理和子块的分割,数据预处理模块将预处理后的数据发送至子译码器模块,子译码器模块各译码器并行处理编码码字的子块数据,提高译码的并行度,进而提升译码器的吞吐率。
步骤2:子译码器模块对数据预处理模块输出的数据进行训练、推理和数据交织。
子译码器模块包括若干个译码器计算单元,每个译码器计算单元均包括训练单元、推理单元和数据交织单元,训练单元根据编码数据训练分支度量,推理单元根据训练单元的数据推理出外信息。核心控制模块控制子译码器模块中每个通道数据子块对应译码器计算单元进行训练和推理的迭代,将数据从译码器系统的存储模块中取出,送入对应的通道中,并对中间结果进行通道间的互换。
如图3和图4所示,子译码器模块训练单元接收读取的系统位X
子译码器模块推理单元接收读取的子译码器模块训练单元发送的系统位X
子译码器通道间边界信息在相邻的子译码器之间双向交换,交换方法为前一个通道的最后一个前向分支度量Alpha赋值给后一个通道的第一个前向分支度量Alpha,后一个通道的第一个后向分支度量Beta赋值给前一个通道的最后一个后向分支度量Beta。
Alpha
Beta
其中,i表示子译码器模块第i个通道,start表示该通道第一个分支度量,end表示该通道最后一个分支度量。
子译码器模块的子译码器完成一次计算后,核心控制模块控制子译码器在第一译码器与第二译码器之间切换,定义子译码器从第一译码器变为第二译码器再回到第一译码器的过程为译码的一次迭代。
步骤3:子译码器模块中数据的迭代次数等于设定值时,子译码器模块将数据发送至硬判决模块进行判决。
根据数据处理要求设置迭代次数N
本实施例将编码后的码块切分为多通道由子译码器模块的各译码器计算单元并行译码,结合外部输入的可配交织图样,所述的卷积Turbo译码器的硬件实现可在符合802.16e标准的下的各通信场景中使用,可以用专用集成电路的形式实现,可以通过现场可编程门阵列的形式实现。
以上示意性地对本发明创造及其实施方式进行了描述,该描述没有限制性,在不背离本发明的精神或者基本特征的情况下,能够以其他的具体形式实现本发明。附图中所示的也只是本发明创造的实施方式之一,实际的结构并不局限于此,权利要求中的任何附图标记不应限制所涉及的权利要求。所以,如果本领域的普通技术人员受其启示,在不脱离本创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本专利的保护范围。此外,“包括”一词不排除其他元件或步骤,在元件前的“一个”一词不排除包括“多个”该元件。产品权利要求中陈述的多个元件也可以由一个元件通过软件或者硬件来实现。第一,第二等词语用来表示名称,而并不表示任何特定的顺序。
- 一种基于MAP算法的卷积Turbo码译码器及译码方法
- 一种基于DVB-RCS标准的双二元Turbo码译码方法及译码器