基于深度学习排序模型的用户行为数据审计方法及系统
文献发布时间:2023-06-19 12:13:22
技术领域
本发明涉及一种基于深度学习排序模型的用户行为数据审计方法及系统。
背景技术
在现在一个计算机技术飞速发展的时代,我们每天都要接触到大大小小不同的系统,其中很多我们可能是使用者,或我们也是其中一部分的管理者,系统中都充斥着目的不同的恶意行为用户,为了保证系统的的安全以及用户的正常使用,本发明利用深度学习算法对系统中的用户行为数据进行分析排名,将恶意行为较高的用户定义为恶意用户,以提高系统的安全性。
作为机器学习的新范式,深度学习能够发现高维数据中的隐性知识,并在科学、商业和政府的许多领域取得了显着的成功,典型的算法之一是深度人工神经网络,其性质允许它按顺序进行训练,并在每一步使用传入数据更新权重。相比之下,传统的批量训练技术通过一次拟合整个训练数据集来训练模型。因此,本发明应用深度学习来克服传统机器学习排序算法批量训练的第一个限制。深度学习的发展为挖掘系统中的恶意用户提供了更多的可能。
虽然学习算法很重要,但如何提取高质量的训练数据也很关键。大多数用户不会随意点击链接,而是根据他们的领域知识进行选择。尽管用户行为数据并不完美并且可能存在噪声,但聚合的点击模式可能会揭示一些有关数据相关性的信息。
发明内容
本发明的目的在于提供一种基于深度学习排序模型的用户行为数据审计方法及系统,适用于检测具有异常行为的恶意用户检测,达到防范恶意用户破坏系统的目的,以防范系统安全问题。
为实现上述目的,本发明的技术方案是:一种基于深度学习排序模型的用户行为数据审计方法,包括:
给定用户查询,首先通过语义相似度计算器转换为语义查询;然后将返回与语义查询相关的前 K 个文档,根据获得的前 K 个文档,为每个搜索结果动态提取排名特征;最后,通过放入预先训练的基于深度学习的排名模型来重新排名前 K 个文档;
当用户与搜索引擎用户界面交互时,会生成新的日志,然后提取新的训练数据以实时或定期更新基于深度学习的排名模型。
在本发明一实施例中,当用户与搜索引擎用户界面交互时,会生成新的日志的具体过程如下:
将 Web 日志集合拆分为会话,每个会话代表单个用户一次访问期间的行为,当一个新的日志进来时,如果相应用户不存在于内存中缓存的所有正在进行的会话中,则会创建一个新会话;如果相应用户存在于内存中缓存的正在进行的会话中,且新的日志与正在进行的会话的最后一个日志的时间间隔小于阈值,则新的日志加入正在进行的会话;如果新的日志与正在进行的会话的最后一个日志的时间间隔大于阈值,则正在进行的会话结束,并开始新的会话;此外,如果正在进行的会话没有收到任何超过时间阈值的新日志,也会结束。
在本发明一实施例中,基于深度学习的排名模型实现排名过程如下:
步骤1、计算每个数据对之间的差距,即将排序问题转化为二元分类,以处理所有可能数据对的差异向量;
步骤2、将深度神经网络应用于步骤1转换后的数据集,并通过重复前向传播和反向传播来校准所有权重;
步骤3、通过排序算法将深度神经网络预测转换回有序列表并呈现给用户。
本发明还提供了一种基于深度学习排序模型的用户行为数据审计系统,包括语义相似度计算器、日志处理器、特征提取器和基于深度学习的排名处理器;
所述语义相似度计算器,对于给定用户查询,语义相似度计算器将其转换为语义查询,然后返回与语义查询相关的前 K 个文档;
所述日志处理器,用于将 Web 日志集合拆分为会话,每个会话代表单个用户一次访问期间的行为;当一个新的网络日志进来时,如果该用户不存在于内存中缓存的所有正在进行的会话中,则会创建一个新会话;
所述特征提取器,用于动态提取前 K 个文档的排名特征;
所述基于深度学习的排名处理器,用于训练基于深度学习的排名模型,以根据排名特征重新排名前 K 个文档,并且可以使用用户行为数据进行增量训练,更新基于深度学习的排名模型。
在本发明一实施例中,基于深度学习的排名模型实现排名过程如下:
步骤1、计算每个数据对之间的差距,即将排序问题转化为二元分类,以处理所有可能数据对的差异向量;
步骤2、将深度神经网络应用于步骤1转换后的数据集,并通过重复前向传播和反向传播来校准所有权重;
步骤3、通过排序算法将深度神经网络预测转换回有序列表并呈现给用户。
在本发明一实施例中,日志处理器通过 Spark Streaming API 实现。
相较于现有技术,本发明具有以下有益效果:本发明适用于检测具有异常行为的恶意用户检测,达到防范恶意用户破坏系统的目的,以防范系统安全问题。
附图说明
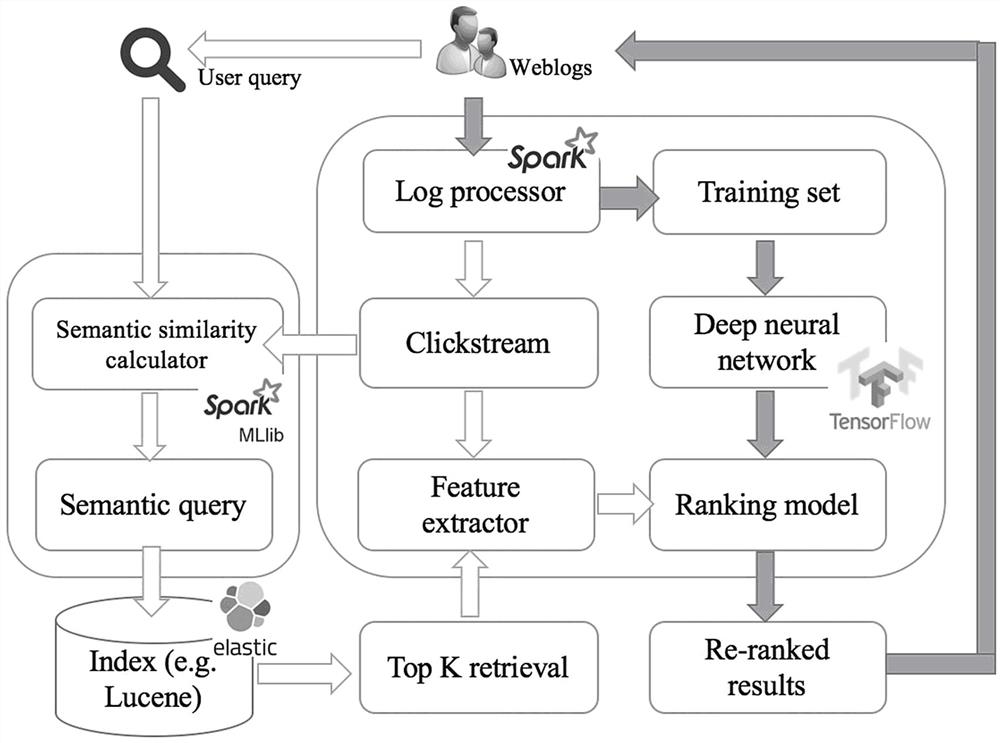
图1为本发明深度学习排名框架图。
图2为本发明在线日志处理的工作流程。
图3为本发明一实例的成对变换的具体例子。
图4为本发明一实例的在小批量训练期间准确度如何变化。
具体实施方式
下面结合附图,对本发明的技术方案进行具体说明。
本发明一种基于深度学习排序模型的用户行为数据审计方法,包括:
给定用户查询,首先通过语义相似度计算器转换为语义查询;然后将返回与语义查询相关的前 K 个文档,根据获得的前 K 个文档,为每个搜索结果动态提取排名特征;最后,通过放入预先训练的基于深度学习的排名模型来重新排名前 K 个文档;
当用户与搜索引擎用户界面交互时,会生成新的日志,然后提取新的训练数据以实时或定期更新基于深度学习的排名模型。
本发明还提供了一种基于深度学习排序模型的用户行为数据审计系统,包括语义相似度计算器、日志处理器、特征提取器和基于深度学习的排名处理器;
所述语义相似度计算器,对于给定用户查询,语义相似度计算器将其转换为语义查询,然后返回与语义查询相关的前 K 个文档;
所述日志处理器,用于将 Web 日志集合拆分为会话,每个会话代表单个用户一次访问期间的行为;当一个新的网络日志进来时,如果该用户不存在于内存中缓存的所有正在进行的会话中,则会创建一个新会话;
所述特征提取器,用于动态提取前 K 个文档的排名特征;
所述基于深度学习的排名处理器,用于训练基于深度学习的排名模型,以根据排名特征重新排名前 K 个文档,并且可以使用用户行为数据进行增量训练,更新基于深度学习的排名模型。
以下为本发明具体实现过程。
本发明提供一种基于深度学习模型的用户行为数据排名系统进行实时恶意用户检测,以防范系统安全问题,该系统包括:
语义相似度计算器,给定用户查询,它首先通过语义相似度计算器转换为语义查询。然后将返回与语义查询相关的前 K 个文档。一旦获得这些前 K 个结果,就会为每个搜索结果动态提取排名特征,这将在下一节中进一步讨论。之后,将通过放入预先训练的基于深度学习的排名模型来重新排名前 K 个结果。当用户与搜索引擎用户界面交互时,会生成新的日志,然后日志处理器会提取新的训练数据以实时或定期更新排名模型。在每一个时间点,系统想要确定数据的行为是否异常必须在时下一个输入之前实时做出决定。也就是说,在下一个输入之前,算法必须考虑当前和以前的状态,以确定数据是否异常,并执行模型更新和再训练。
日志处理器,在线日志处理工作流旨在将 Web 日志集合拆分为会话,每个会话代表单个用户一次访问期间的行为。当一个新的网络日志进来时,如果该用户不存在于内存中缓存的所有正在进行的会话中,则会创建一个新会话。
特征提取器,用于动态提取前 K 个文档的排名特征;
基于深度学习的排名处理器或基于深度学习的排名算法,首先,计算每个数据对之间的差异。其次,将深度神经网络应用于转换后的数据集,并通过重复前向传播和反向传播两个关键步骤来校准所有权重。最后,实现排序算法(例如快速排序)将神经网络预测转换回有序列表并呈现给用户。
如图1所示,本发明提出了深度学习排名框架,基于深度学习的搜索排名框架包括四个主要组件:语义相似度计算器、日志处理器、特征提取器和基于深度学习的排名算法。给定用户查询,它首先通过语义相似度计算器转换为语义查询。然后将返回与语义查询相关的前 K 个文档。一旦获得这些前 K 个结果,就会为每个搜索结果动态提取排名特征,这将在下一节中进一步讨论。之后,将通过放入预先训练的基于深度学习的排名模型来重新排名前 K 个结果。当用户与搜索引擎用户界面交互时,会生成新的日志,然后日志处理器会提取新的训练数据以实时或定期更新排名模型。
在线日志处理的工作流程:
在线日志处理工作流旨在将 Web 日志集合拆分为会话,每个会话代表单个用户一次访问期间的行为。当一个新的网络日志进来时,如果该用户不存在于内存中缓存的所有正在进行的会话中,则会创建一个新会话。唯一用户由 IP 地址和用户代理/浏览器的组合确定。否则,如果它与正在进行的会话的最后一个日志的时间间隔小于阈值,则它加入正在进行的会话。如果时间间隔大于阈值,则正在进行的会话结束,并开始新的会话。此外,如果正在进行的会话没有收到任何超过时间阈值的新日志,它也会结束。如图2所示:
本申请还提出了基于深度学习的排序算法:
该排序算法包括三个主要步骤:
步骤1:计算每个数据对之间的差距。这一步的目标是将排序问题转化为二元分类。如图3所示,通过这种转换,我们开始处理所有可能数据对的差异向量,而不是直接处理初始特征向量。
步骤2:将深度神经网络应用于转换后的数据集,并通过重复前向传播和反向传播两个关键步骤来校准所有权重。
步骤3: 实现排序算法(例如快速排序)将神经网络预测转换回有序列表并呈现给用户。
图4显示了小批量过程中损失和准确度的变化。波动线条代表从H 1导出的训练数据,曲线是测试数据(即人工标记的数据)。当我们迭代训练过程时,测试数据的损失不断下降,准确率不断上升,而训练数据存在振荡。这个结果表明准确率确实可以在小批量训练过程中收敛。在这种情况下,准确率最终收敛于 82.06%。
表
表1显示了 H 1和 H 2使用五种不同机器学习算法的准确性。这些精度是我们使用网格搜索和超参数调整所能达到的最佳精度。可以看出,H 1的精度一般要好于H 2。一个可能的解释是 H 2引入了更多的噪声,尽管它产生了更多的训练数据。同时,作为最灵活的非线性学习算法,深度神经网络在 H 1 的情况下优于所有其他算法。证明了为这项工作选择深度神经网络是合理的。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 基于深度学习排序模型的用户行为数据审计方法及系统
- 一种基于分布式记账的混合型用户行为审计方法及系统