深度数据获取方法、装置、存储介质与电子设备
文献发布时间:2023-06-19 12:14:58
技术领域
本公开涉及计算机视觉技术领域,尤其涉及一种深度数据获取方法、深度数据获取装置、计算机可读存储介质与电子设备。
背景技术
在计算机视觉领域中,一项重要的任务是基于双目图像确定深度,以实现三维重建。目前,除了传统的双目立体匹配算法外,一般还采用机器学习模型来对双目图像进行深度估计。为了对机器学习模型进行训练,需要具备较高质量的深度数据集。
相关技术中,为了获取深度数据集中的标注数据(Ground truth),通常采用深度检测相关的传感器及其配套的算法,传感器包括主动式深度传感器与双目相机,主动式深度传感器以TOF(Time Of Flight,飞行时间)传感器,LiDAR(LightLaser Detection andRanging,激光雷达),结构光相机等为主流。然而,采用每种传感器进行深度检测均存在一定的局限性,例如上述所有传感器对超出检测范围的待测对象所检测的深度值准确度较低,双目相机对于物体弱纹理部分所检测的深度值精度较低,激光雷达容易受多径干扰效应的影响,对于物体边缘部分所检测的深度值精度较低,等等,导致仅能在特定的场景下实现较为准确的深度检测,从而限制了深度数据集所适用的场景范围。
发明内容
本公开提供了一种深度数据获取方法、深度数据获取装置、计算机可读存储介质与电子设备,进而至少在一定程度上改善相关技术中深度数据集适用的场景范围较小的问题。
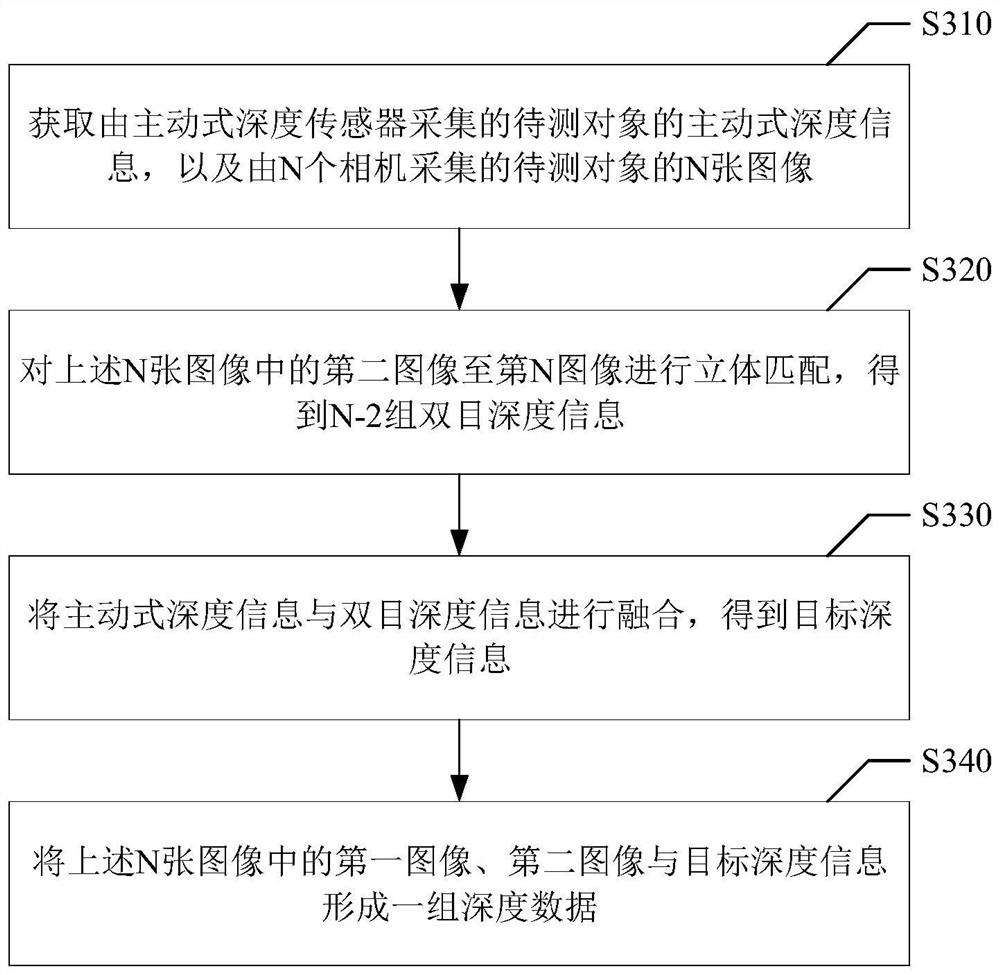
根据本公开的第一方面,提供一种深度数据获取方法,包括:获取由主动式深度传感器采集的待测对象的主动式深度信息,以及由N个相机采集的所述待测对象的N张图像,所述N个相机沿一条基线轴设置,其中的第一相机沿所述基线轴可滑动,第二相机至第N相机固定于所述基线轴上,所述第一相机与所述第二相机的基线长度为目标长度,N为不小于4的正整数;对所述N张图像中的第二图像至第N图像进行立体匹配,得到N-2组双目深度信息,所述第二图像至第N图像为所述第二相机至第N相机分别采集的图像;将所述主动式深度信息与所述双目深度信息进行融合,得到目标深度信息;将所述N张图像中的第一图像、第二图像与所述目标深度信息形成一组深度数据。
根据本公开的第二方面,提供一种深度数据获取装置,包括:数据获取模块,被配置为获取由主动式深度传感器采集的待测对象的主动式深度信息,以及由N个相机采集的所述待测对象的N张图像,所述N个相机沿一条基线轴设置,其中的第一相机沿所述基线轴可滑动,第二相机至第N相机固定于所述基线轴上,所述第一相机与所述第二相机的基线长度为目标长度,N为不小于4的正整数;立体匹配模块,被配置为对所述N张图像中的第二图像至第N图像进行立体匹配,得到N-2组双目深度信息,所述第二图像至第N图像为所述第二相机至第N相机分别采集的图像;深度信息融合模块,被配置为将所述主动式深度信息与所述双目深度信息进行融合,得到目标深度信息;深度数据输出模块,被配置为将所述N张图像中的第一图像、第二图像与所述目标深度信息形成一组深度数据。
根据本公开的第三方面,提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述第一方面的深度数据获取方法及其可能的实现方式。
根据本公开的第四方面,提供一种电子设备,包括:处理器;以及存储器,用于存储所述处理器的可执行指令;其中,所述处理器配置为经由执行所述可执行指令来执行上述第一方面的深度数据获取方法及其可能的实现方式。
本公开的技术方案具有以下有益效果:
一方面,通过融合主动式深度信息与双目深度信息,能够克服单一传感器系统的局限性,扩展所能检测的深度值范围以及所能适用的深度检测场景,并提高深度数据的准确度。另一方面,由于第一相机可滑动,可以将第一相机与第二相机的基线长度调节为所需的目标长度,得到双目图像与对应的目标深度信息,从而构建不同基线长度的深度数据集,满足不同场景下的需求。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
附图说明
图1示出本示例性实施方式中一种系统架构的示意图;
图2示出本示例性实施方式中一种电子设备的结构示意图;
图3示出本示例性实施方式中一种深度数据获取方法的流程图;
图4示出本示例性实施方式中一种确定双目深度信息的流程图;
图5示出本示例性实施方式中一种确定第二置信度的流程图;
图6示出本示例性实施方式中三元组的示意图;
图7示出本示例性实施方式中主动式深度图像与双目深度图像融合的示意图;
图8示出本示例性实施方式中一种深度数据获取方法的流程示意图;
图9示出本示例性实施方式中一种深度数据获取装置的结构示意图。
具体实施方式
现在将参考附图更全面地描述示例实施方式。然而,示例实施方式能够以多种形式实施,且不应被理解为限于在此阐述的范例;相反,提供这些实施方式使得本公开将更加全面和完整,并将示例实施方式的构思全面地传达给本领域的技术人员。所描述的特征、结构或特性可以以任何合适的方式结合在一个或更多实施方式中。在下面的描述中,提供许多具体细节从而给出对本公开的实施方式的充分理解。然而,本领域技术人员将意识到,可以实践本公开的技术方案而省略所述特定细节中的一个或更多,或者可以采用其它的方法、组元、装置、步骤等。在其它情况下,不详细示出或描述公知技术方案以避免喧宾夺主而使得本公开的各方面变得模糊。
此外,附图仅为本公开的示意性图解,并非一定是按比例绘制。图中相同的附图标记表示相同或类似的部分,因而将省略对它们的重复描述。附图中所示的一些方框图是功能实体,不一定必须与物理或逻辑上独立的实体相对应。可以采用软件形式来实现这些功能实体,或在一个或多个硬件模块或集成电路中实现这些功能实体,或在不同网络和/或处理器装置和/或微控制器装置中实现这些功能实体。
附图中所示的流程图仅是示例性说明,不是必须包括所有的步骤。例如,有的步骤还可以分解,而有的步骤可以合并或部分合并,因此实际执行的顺序有可能根据实际情况改变。
Middlebury和KITTI是业界常用的两个开源的深度数据集。Middlebury中的深度数据是基于结构光相机获取的,由于结构光相机通常仅能检测近距离深度,因此Middlebury中的图像大多为近距离室内场景,且由于存在遮挡的情况,导致Middlebury中的深度数据存在空洞。KITTI是主要针对自动驾驶的数据集,图像大多是室外道路场景,其深度数据是基于LiDAR获取的,受到LiDAR本身性能的限制,准确度有限。
可见,目前的深度数据集普遍存在场景范围限制与准确度不足的问题。此外,实际应用中可能对双目的基线长度有不同的需求,例如需要获取不同基线长度下的双目图像及其深度数据,而上述深度数据集中双目的基线长度一般是固定的,无法满足该需求。
鉴于上述问题,本公开的示例性实施方式首先提供一种深度数据获取方法。图1示出了本示例性实施方式运行环境的系统架构图。参考图1所示,该系统架构包括数据采集设备110与计算设备120。其中,数据采集设备110包括第一相机111、第二相机112、第三相机113、第四相机114、滑轨115、基线轴116、同步器117、TOF传感器118。
第一相机111、第二相机112、第三相机113、第四相机114、滑轨115、基线轴116组成了相机系统,滑轨115是基线轴116的延长线,可视为基线轴116的一部分。第一相机111至第四相机114均沿基线轴116设置,第二相机112、第三相机113、第四相机114的位置固定,第一相机111可沿滑轨115滑动,因此第一相机111与第二相机112间的基线长度可调,第二相机112与第三相机113间的基线长度固定,第二相机112与第四相机114间的基线长度也固定。可见,第一相机111与第二相机112、第二相机112与第三相机113、第二相机112与第四相机114形成了三组双目系统,分别为基线可调的双目系统、短基线的双目系统、长基线的双目系统。此外,根据实际需要,还可以在基线轴116的不同位置固定设置第五相机、第六相机等,其与第二相机112形成更多组双目系统。例如,在第三相机113与第四相机114中间设置第五相机,其与第二相机112形成中等长度基线的双目系统。
TOF传感器118可用于向待测对象发射主动式信号,并通过解析所接收的反射信号,得到待测对象的深度信息。TOF传感器118可以固定设置,这样与第二相机112至第四相机114的相对几何关系保持固定。在一种实施方式中,TOF传感器118与第二相机112可以在纵向方向上对齐,以便于对TOF传感器118与第二相机112进行标定。
应当理解,图1中的TOF传感器118仅为实例,可以替换为其他的主动式深度传感器,例如LiDAR、结构光相机等。
同步器117可用于对第一相机111至第四相机114以及TOF传感器118进行时间同步,使得每个相机采集图像数据的时间与TOF传感器118采集深度信息的时间同步。
数据采集设备110与计算设备120可以通过有线或无线的通信链路形成连接,使得数据采集设备110将所采集的数据发送至计算设备120。计算设备120包括处理器121与存储器122。存储器122用于存储述处理器121的可执行指令,也可以存储应用数据,如图像数据、视频数据等。处理器121配置为经由执行可执行指令来执行本示例性实施方式的深度数据获取方法,以对数据采集设备110发送的数据进行处理,得到深度数据。
在一种实施方式中,数据采集设备110与计算设备120可以是相互独立的两台设备,例如数据采集设备110是机器人,计算设备120是用于控制机器人的计算机。
在另一种实施方式中,数据采集设备110与计算设备120也可以集成在同一台设备中,例如车载智能设备包括数据采集设备110与计算设备120,通过执行数据采集与数据处理的全过程,实现深度数据的获取。
本示例性实施方式的深度数据获取方法的应用场景包括但不限于:在自动驾驶、室内导航、三维建模等场景中,通过主动式深度传感器采集主动式深度信息,通过相机系统采集N张图像,进而执行本示例性实施方式的深度数据获取方法,得到一组或多组深度数据,以构建深度数据集。
本公开的示例性实施方式还提供一种电子设备,用于执行上述深度数据获取方法。该电子设备可以是上述计算设备120或者包括数据采集设备110的计算设备120。
下面以图2中的移动终端200为例,对上述电子设备的构造进行示例性说明。本领域技术人员应当理解,除了特别用于移动目的的部件之外,图2中的构造也能够应用于固定类型的设备。
如图2所示,移动终端200具体可以包括:处理器210、内部存储器221、外部存储器接口222、USB(Universal Serial Bus,通用串行总线)接口230、充电管理模块240、电源管理模块241、电池242、天线1、天线2、移动通信模块250、无线通信模块260、音频模块270、扬声器271、受话器272、麦克风273、耳机接口274、传感器模块280、显示屏290、相机模组291、指示器292、马达293、按键294以及SIM(Subscriber Identification Module,用户标识模块)卡接口295等。
处理器210可以包括一个或多个处理单元,例如:处理器210可以包括AP(Application Processor,应用处理器)、调制解调处理器、GPU(Graphics ProcessingUnit,图形处理器)、ISP(Image Signal Processor,图像信号处理器)、控制器、编码器、解码器、DSP(Digital Signal Processor,数字信号处理器)、基带处理器和/或NPU(Neural-Network Processing Unit,神经网络处理器)等。
编码器可以对图像或视频数据进行编码(即压缩),例如对拍摄的待测对象的图像进行编码,形成对应的码流数据,以减少数据传输所占的带宽;解码器可以对图像或视频的码流数据进行解码(即解压缩),以还原出图像或视频数据,例如对待测对象的图像所对应的码流数据进行解码,得到原始的图像数据。移动终端200可以支持一种或多种编码器和解码器。这样,移动终端200可以处理多种编码格式的图像或视频,例如:JPEG(JointPhotographic Experts Group,联合图像专家组)、PNG(Portable Network Graphics,便携式网络图形)、BMP(Bitmap,位图)等图像格式,MPEG(Moving Picture Experts Group,动态图像专家组)1、MPEG2、H.263、H.264、HEVC(High Efficiency Video Coding,高效率视频编码)等视频格式。
在一种实施方式中,处理器210可以包括一个或多个接口,通过不同的接口和移动终端200的其他部件形成连接。
内部存储器221可以用于存储计算机可执行程序代码,所述可执行程序代码包括指令。内部存储器221可以包括易失性存储器与非易失性存储器。处理器210通过运行存储在内部存储器221的指令,执行移动终端200的各种功能应用以及数据处理。
外部存储器接口222可以用于连接外部存储器,例如Micro SD卡,实现扩展移动终端200的存储能力。外部存储器通过外部存储器接口222与处理器210通信,实现数据存储功能,例如存储图像,视频等文件。
USB接口230是符合USB标准规范的接口,可以用于连接充电器为移动终端200充电,也可以连接耳机或其他电子设备。
充电管理模块240用于从充电器接收充电输入。充电管理模块240为电池242充电的同时,还可以通过电源管理模块241为设备供电;电源管理模块241还可以监测电池的状态。
移动终端200的无线通信功能可以通过天线1、天线2、移动通信模块250、无线通信模块260、调制解调处理器以及基带处理器等实现。天线1和天线2用于发射和接收电磁波信号。移动通信模块250可以提供应用在移动终端200上的包括2G/3G/4G/5G等无线通信的解决方案。无线通信模块260可以提供应用在移动终端200上的包括WLAN(Wireless LocalArea Networks,无线局域网)(如Wi-Fi(Wireless Fidelity,无线保真)网络)、BT(Bluetooth,蓝牙)、GNSS(Global Navigation Satellite System,全球导航卫星系统)、FM(Frequency Modulation,调频)、NFC(Near Field Communication,近距离无线通信技术)、IR(Infrared,红外技术)等无线通信解决方案。
移动终端200可以通过GPU、显示屏290及AP等实现显示功能,显示用户界面。例如,当用户开启拍摄功能时,移动终端200可以在显示屏290中显示拍摄界面和预览图像等。
移动终端200可以通过ISP、相机模组291、编码器、解码器、GPU、显示屏290及AP等实现拍摄功能。在一种实施方式中,相机模组291可以包括N个相机,N为不小于4的正整数。N个相机沿一条基线轴设置,其中的第一相机沿基线轴可滑动,第二相机至第N相机固定于基线轴上。
移动终端200可以通过音频模块270、扬声器271、受话器272、麦克风273、耳机接口274及AP等实现音频功能。
传感器模块280可以包括深度传感器2801、压力传感器2802、陀螺仪传感器2803、气压传感器2804等,以实现相应的感应检测功能。在一种实施方式中,深度传感器2801可以是主动式深度传感器,例如TOF传感器,LiDAR等。
指示器292可以是指示灯,可以用于指示充电状态,电量变化,也可以用于指示消息,未接来电,通知等。马达293可以产生振动提示,也可以用于触摸振动反馈等。按键294包括开机键,音量键等。
移动终端200可以支持一个或多个SIM卡接口295,用于连接SIM卡,以实现通话与移动通信等功能。
下面结合图3对本示例性实施方式的深度数据获取方法进行说明,图3示出深度数据获取方法的示例性流程,可以包括:
步骤S310,获取由主动式深度传感器采集的待测对象的主动式深度信息,以及由N个相机采集的待测对象的N张图像;N个相机沿一条基线轴设置,其中的第一相机沿基线轴可滑动,第二相机至第N相机固定于基线轴上,第一相机与第二相机的基线长度为目标长度,N为不小于4的正整数;
步骤S320,对上述N张图像中的第二图像至第N图像进行立体匹配,得到N-2组双目深度信息;
步骤S330,将主动式深度信息与双目深度信息进行融合,得到目标深度信息;
步骤S340,将上述N张图像中的第一图像、第二图像与目标深度信息形成一组深度数据。
通过上述方法,一方面,通过融合主动式深度信息与双目深度信息,能够克服单一传感器系统的局限性,扩展所能检测的深度值范围以及所能适用的深度检测场景,并提高深度数据的准确度。另一方面,由于第一相机可滑动,可以将第一相机与第二相机的基线长度调节为所需的目标长度,得到双目图像与对应的目标深度信息,从而构建不同基线长度的深度数据集,满足不同场景下的需求。
下面对图3中的每个步骤进行具体说明。
参考图3,在步骤S310中,获取由主动式深度传感器采集的待测对象的主动式深度信息,以及由N个相机采集的待测对象的N张图像。
本示例性实施方式中,主动式深度信息是由主动式深度传感器采集的深度信息,区分于通过双目系统所得到的双目深度信息。待测对象是指主动式深度传感器与相机前方的环境,包括环境中的物体。主动式深度传感器一般包括发射器与接收器,发射器发射红外信号等主动式信号,在待测对象处发生反射后由接收器接收反射信号,通过解析发射与接收的信号之间的时间差、相位差等,可以计算待测对象的深度信息。
主动式深度信息包括待测对象的不同点的主动式深度值(此处为便于区分,称为主动式深度值,双目系统中得到的深度值称为双目深度值),待测对象的不同点对应于主动式深度传感器的不同点。具体来说,主动式深度传感器的接收器一般由传感器元件阵列组成,每个元件分别接收待测对象的不同点反射回来的信号,将每个元件表示为一个点,分别对应于待测对象的不同点,则通过解析处理不同元件接收的反射信号得到待测对象的不同点的主动式深度值。
在主动式深度传感器采集主动式深度信息的同时,包括N个相机的相机系统可以采集待测对象的N张图像。N为不小于4的正整数,以N=4为例,第一相机采集第一图像,第二相机采集第二图像,第三相机采集第三图像,第四相机采集第四图像,第一图像、第三图像、第四图像分别与第二图像形成三组双目图像。第一相机与第二相机的基线长度可调,本示例性实施方式将其调节为目标长度,目标长度是所需的基线长度。例如,采集自动驾驶场景下的深度数据时,由于自动驾驶场景下的深度距离一般较大,需要基线长度较长的双目系统,因此可以将目标长度设置为较大的数值;或者,对手机、无人机等设备上的双目系统采集深度数据时,可以将该设备上的双目系统的基线长度作为目标长度。第二相机与第三相机、…、第二相机与第N相机的基线长度固定。
在一种实施方式中,上述获取由主动式深度传感器采集的待测对象的主动式深度信息,可以包括以下步骤:
获取主动式深度传感器在运动过程中所采集的多帧点云数据;
对上述多帧点云数据进行配准,并融合配准后的多帧点云数据,得到待测对象的点云数据,该点云数据包括主动式深度信息。
其中,主动式深度传感器可以根据主动式深度信息与传感器元件阵列的分布输出点云数据,包括所采集的待测对象的不同点的三维坐标。在主动式深度传感器的运动过程中,随着位姿的变化,其自身的坐标系也在变化,在不同位姿下采集得到多帧点云数据,每一帧点云数据是待测对象处于主动式深度传感器的不同坐标系中的三维信息。由此,可以将多帧点云数据进行配准,使配准后的点云数据处于同一坐标系中,进而对多帧点云数据进行融合,以得到相比于单帧更加稠密的点云数据,并可以剔除点云数据中部分错误的点,以提高点云数据的准确性。
在一种实施方式中,可以从上述多帧点云数据中选取一帧为基准帧,将其他帧均向基准帧配准。例如,主动式深度传感器在运动过程中共采集m帧点云数据,以第1帧为基准,将第2帧至第m帧均向第1帧配准。
一般的,待测对象为静态物体,即在主动式深度传感器的运动过程中待测对象的形态不变,因此不同帧点云数据对应于相同形态的待测对象。由此,在进行配准时,对待配准帧确定最优的变换参数,使其变换后与基准帧实现尽可能地重合。
本公开对于具体的配准算法不做限定。例如可以采用ICP算法(IterativeClosest Point,迭代最邻近点),在将第2帧向第1帧配准时,基于初始的变换参数(一般包括旋转矩阵和平移向量)将第2帧点云数据变换至第1帧的坐标系中,并与第1帧点云数据进行最邻近点配对;计算最邻近点对的平均距离,以构建损失函数;通过迭代优化变换参数,使损失函数值不断减小,直到收敛,得到优化后的变换参数;利用优化后的变换参数将第2帧点云数据变换至第1帧的坐标系中,从而完成第2帧向第1帧的配准。
在一种实施方式中,对上述多帧点云数据进行配准,并融合配准后的多帧点云数据,可以通过以下方式实现:
在上述多帧点云数据中确定基准帧,将除基准帧以外的其他帧点云数据配准至基准帧对应的坐标系中,该坐标系为三维坐标系;
在基准帧对应的坐标系中,根据主动式深度传感器的分辨率以及实际需求等划分出正方体或长方体格子;
将配准后的每一帧点云数据中的点按照其x、y、z坐标划分至上述格子内,同一格子内的点视为同名点;
统计每个格子内的点数量,如果点数量小于同名点数量阈值,则判断该格子内的点为错误点,予以剔除,同名点数量阈值可以根据经验确定,也可以结合点云数据的帧数确定,例如在共获取m帧点云数据的情况下,同名点数量阈值可以为s*m,s为小于1的系数,如可以是0.5、0.25等;
将剩余的点形成集合,得到融合后的点云数据。
在得到融合后的点云数据后,可以提取其中深度方向(通常是z轴)的坐标值,得到主动式深度信息。
在一种实施方式中,获取主动式深度信息后,可以对其进行预处理,包括但不限于:深度补全,剔除飞行像素,滤波等。
在一种实施方式中,获取主动式深度信息后,可以基于主动式深度传感器与第二相机间的第一标定参数,将主动式深度信息投影至第二相机的坐标系。
在相机系统中,每个相机具有各自的相机坐标系,通常从中选取一台相机,以其坐标系作为基准,将主动式深度传感器与该相机进行标定,从而实现主动式深度传感器与相机系统的标定。本示例性实施方式以第二相机的坐标系为基准,可以预先对主动式深度传感器与第二相机进行标定,例如可以采用张正友标定法。第一标定参数是主动式深度传感器与第二相机间的标定参数,可以是主动式深度传感器与第二相机的坐标系间的变换参数。由此,在得到主动式深度信息后,可以采用第一标定参数将其从主动式深度传感器的坐标系投影至第二相机的坐标系中,以便于后续与双目深度信息进行融合。
主动式深度信息有多种不同的表示信息。例如,主动式深度信息可以是上述点云数据中深度方向的坐标值,在进行投影时,可以利用第一标定参数对点云数据进行变换,变换后的点云数据中深度方向的坐标值为第二相机的坐标系中的主动式深度信息。主动式深度信息也可以是主动式深度图像,是对所采集的主动式深度值进行可视化表示所形成的图像,在进行投影时,可以利用第一标定参数对主动式深度图像进行变换,变换后的主动式深度图像为第二相机的坐标系中的主动式深度信息。
继续参考图2,在步骤S320中,对上述N张图像中的第二图像至第N图像进行立体匹配,得到N-2组双目深度信息。
双目深度信息是由相机系统所确定的待测对象的深度信息,与上述主动式深度信息属于不同途径得到的深度信息。
第二相机分别与第三相机至第N相机组成N-2个双目系统,因此对应采集的第二图像分别与第三图像至第N图像组成N-2组双目图像,具体地,第二图像与第三图像为一组双目图像,第二图像与第四图像为一组双目图像,等等。通过对每组双目图像进行立体匹配,可以得到对应的一组双目深度信息。
双目深度信息中包括待测对象的不同点的双目深度值,待测对象的不同点对应于双目图像中的不同点,更具体地,对应于第二图像中的特征点。在一种实施方式中,双目深度信息包括第二图像对应的双目深度图像,是对双目深度值进行可视化表示所形成的图像。
在一种实施方式中,参考图4所示,步骤S320可以包括:
步骤S410,基于第二相机至第N相机间的第二标定参数,对第二图像至第N图像进行立体匹配,得到N-2张双目视差图;
步骤S420,根据每张双目视差图确定对应的一组双目深度信息。
可以将预先对第二相机与第三相机至第N相机分别进行标定,例如可以采用张正友标定法。第二标定参数是对第二相机与第三相机至第N相机间的标定参数,可以是第二相机的坐标系与第三相机至第N相机的坐标系间的变换参数。第二标定参数可以包括多组,每组第二标定参数为不同相机间的标定参数,为便于区分,本示例性实施方式将第二相机与第三相机间的第二标定参数记为(2-3)第二标定参数,将第二相机与第N相机间的第二标定参数记为(2-N)第二标定参数。
基于第二标定参数,可以对上述双目图像进行立体匹配。具体地,可以基于(2-3)第二标定参数对第二图像与第三图像进行立体匹配,得到一组双目视差图,记为(2-3)双目视差图;基于(2-N)第二标定参数对第二图像与第N图像进行立体匹配,得到一组双目视差图,记为(2-N)双目视差图。
本公开对于立体匹配的具体算法不做限定,例如可以采用SGM算法(Semi-GlobalMatching,半全局匹配)实现。
双目视差图中包括每个点的视差值,结合相机的参数与第二标定参数(主要是不同相机间的基线长度),可以计算出每个点的双目深度值,一般以第第二图像为基准,计算第二图像中每个点的第二深度值,从而得到双目深度信息。需要说明的是,一张双目视差图对应可以得到一组双目深度信息,例如根据(2-3)双目视差图得到(2-3)双目深度信息,根据(2-N)双目视差图得到(2-N)双目深度信息。由此,利用预先标定的第二标定参数,可以对上述第二图像至第N图像实现较为精确的立体匹配,从而得到质量较高的双目视差图以及较为准确的双目深度信息。
在一种实施方式中,在得到N-2组双目深度信息后,还可以基于第三相机至第N相机与第二相机的基线长度以及目标长度,将N-2组双目深度信息融合为一组双目深度信息。其中,N-2组双目深度信息是基于不同基线长度的双目系统所得到的深度信息,在不同的深度上具有各自的优势。通过将N-2组双目深度信息融合为一组双目深度信息,可以进一步提高双目深度信息的准确度。在融合时,参考目标长度确定每组双目深度信息的权重,使融合后的双目深度信息与目标长度更加匹配。以N=4为例进行说明,目标长度即第二相机与第一相机的基线长度,记为L21,将第二相机与第三相机的基线长度记为L23,第二相机与第四相机的基线长度记为L24,可以根据L21与L23之差、L21与L24之差,确定(2-3)双目深度信息的权重与(2-4)双目深度信息的权重。示例性的,可以参考如下公式(1)计算权重:
其中,w
在得到融合后的一组双目深度信息后,后续可以将主动式深度信息与该组双目深度信息进一步融合,能够降低融合处理的计算量。
继续参考图3,在步骤S330中,将主动式深度信息与双目深度信息进行融合,得到目标深度信息。
主动式深度信息与双目深度信息是通过不同途径得到的深度信息,具有各自的优势,本示例性实施方式将两种深度信息进行融合,可以结合两种深度信息的优势,得到准确性更高的目标深度信息。
在一种实施方式中,步骤S330可以包括:
根据第一置信度与第二置信度中的至少一者,将主动式深度信息与双目深度信息进行融合,得到目标深度信息。
其中,第一置信度为主动式深度信息对应的置信度,第二置信度为双目深度信息对应的置信度。置信度表示深度信息的可信程度,也在一定程度上代表了深度信息的准确度。
第一置信度包括主动式深度信息中每个点的深度值对应的置信度。下面对如何确定第一置信度进行说明。
在一种实施方式中,主动式深度传感器可以输出第一置信度。例如,根据接收器接收到的反射信号的强度,定量计算不同点的深度值对应的第一置信度,一般的,反射信号的强度与第一置信度正相关。
在另一种实施方式中,可以根据上述多帧点云数据的融合结果确定第一置信度。例如,在将配准后的每一帧点云数据中的点按照其x、y、z坐标划分至格子内之后,统计每个格子内的点数量以及每个格子内的不同点之间的深度差(即不同点的深度方向的坐标值之差,如z轴坐标值之差),格子内的点数量越多,点之间的深度差越小,则这些点的第一置信度越高。示例性的,可以采用如下公式(2)计算:
其中,Conf1表示第一置信度。grid
由公式(2)可见,第一置信度由两部分乘积得到。其中,格子内点数量越多,则与帧数m之比越大,第一部分值越大,第一置信度越大;格子内的深度值越集中,标准差越小,与深度值跨度之比越小,第二部分值越大,第一置信度越大。
第二置信度包括双目深度信息中每个点的深度值对应的置信度,一组双目深度信息对应一组第二置信度。下面对如何确定第二置信度进行说明。
在一种实施方式中,可以基于第二图像至第N图像中的三张图像间的三焦点张量,确定第二置信度。其中,可以在第二图像至第N图像中选择两组双目图像,两组双目图像中均包括第二图像,实际上共包括三张图像;两组双目图像对应于两组双目深度信息,基于三张图像间的三焦点张量,确定两组双目深度信息对应的第二置信度。例如,可以基于第二图像、第三图像、第四图像间的三焦点张量,确定(2-3)双目深度信息对应的(2-3)第二置信度与(2-4)双目深度信息对应的(2-4)第二置信度。
上述三张图像可看作是不同视角下观测待测对象的视图,三张图像具有一定的仿射几何关系,利用三焦点张量可以描述该仿射几何关系,对于三张图像中的点、线等产生几何约束。如果三张图像中的点、线等满足三焦点张量的几何约束,则对应的第二置信度最高(例如为1),三张图像中的点、线等与几何约束的偏差越大,则对应的第二置信度越低。
下面以第二图像、第E图像、第F图像间的三焦点张量为例,对计算第二置信度的流程进行示例性说明,E、F为[3,N]内的任意两个不同的正整数。参考图5所示,可以通过以下步骤S510至S540确定第二置信度:
步骤S510,基于第二相机与第E相机间的第二标定参数,以及第二相机与第F相机间的第二标定参数,确定第二图像、第E图像、第F图像间的三焦点张量。
将第二相机与第E相机间的第二标定参数记为(2-E)第二标定参数,包括第二相机与第E相机间的旋转矩阵R
归一化后表示如下:
其中,矩阵A=[a
则三个矩阵的集合T={T
步骤S520,对于第二图像的特征点或特征线,在第E图像与第F图像中获取与之匹配的特征点或特征线,得到三元组。
其中,三元组的具体组成情况可以参考表1所示。在进行双目图像的立体匹配时,一般已经对双目图像中的特征点或特征线做过匹配,因此步骤S520可以获取立体匹配的结果,得到三元组。
表1
参考图6举例来说,对于第二图像中的特征点x
步骤S530,利用三焦点张量的几何约束,确定三元组与几何约束的偏离程度。
理想情况下,三元组应当满足三焦点张量的几何约束,可以参考表2。
表2
其中,
当满足几何约束时,表2中的几何约束方程成立,即方程左侧为0(表示零矩阵)。然而,由于实际处理过程中存在误差以及特征点、特征线的误匹配问题,导致表2中的几何约束方程并不成立,即方程左侧不为0。左侧的数值大小可以表征三元组与几何约束的偏离程度,偏离程度越高,表示误差、误匹配越严重,则第二置信度越低。
几何约束方程的左侧为矩阵(一般为3*3矩阵),记为偏离矩阵Dev,具体如下:
其中,Dev(xxx)表示三个特征点的三元组的偏离矩阵,Dev(xxl)表示两个特征点、一条特征线的三元组的偏离矩阵,Dev(xll)表示一个特征点、两条特征线的三元组的偏离矩阵,Dev(lll)表示三条特征线的三元组的偏离矩阵。
可以对Dev取任意范数,以作为Dev的定量数值,也可以对Dev的所有项取其绝对值之和,以作为Dev的定量数值,等等。Dev的定量数值为三元组与几何约束的偏离程度值。
在一种实施方式中,对于第二图像中的每个特征点x
步骤S540,根据上述偏离程度确定三元组中第二图像的特征点或特征线在双目深度信息中的深度值对应的第二置信度。
举例来说,得到第二图像中所有特征点的平均偏离程度值后,进行归一化计算,例如可以根据所有平均偏离程度值中的最大值、最小值进行归一化;再根据归一化的平均偏离程度值与1的差值,确定每个特征点在双目深度信息中的深度值所对应的第二置信度。示例性的,可以参考如下公式(7)计算第二置信度:
Conf2(x
其中,Conf2(x
在另一种实施方式中,可以利用机器学习模型估计第二置信度。例如,预先训练卷积神经网络,将双目图像与对应的双目深度信息(通常可以是第二图像对应的双目深度图像)输入卷积神经网络,经过处理,输出第二置信度的图像,包括第二图像或双目深度图像中每个点的第二置信度。
在再一种实施方式中,可以采用LRC(Left-Right Consistency,左右一致性)检测算法来检测错误的视差匹配,尤其是待测对象深度断层处的遮挡区域,为其赋予较低的第二置信度。
应当理解,还可以结合上述任意多种方式来确定第二置信度,例如通过三焦点张量的方式确定第二置信度,并利用机器学习模型估计第二置信度,再将两种方式得到的第二置信度计算平均值或加权平均值,输出最终的第二置信度。
以上分别说明了如何确定第一置信度与第二置信度。其中,第一置信度与第二置信度是分开计算的。在一种实施方式中,也可以对第一置信度与第二置信度进行统一计算。例如,可以根据待测对象的场景预测结果,确定第一置信度与第二置信度。
其中,可以将待测对象的场景分为两类:主动式深度传感器的最佳场景,与双目系统的最佳场景,分别表示最适合主动式深度传感器工作的场景与最适合双目系统工作的场景。一般的,在近距离、弱光照、稀疏纹理的场景下,主动式深度传感器受到的影响较小,所检测的主动式深度信息可靠性较高,而双目系统受到的影响较大,所检测的双目深度信息可靠性较低,因此可以设置较高的第一置信度与较低的第二置信度;反之,在远距离、强光照、稠密纹理的场景下,主动式深度传感器受到的影响较大,所检测的主动式深度信息可靠性较低,而双目系统受到的影响较小,所检测的双目深度信息可靠性较高,因此可以设置较低的第一置信度与较高的第二置信度。
通常室内场景更接近于主动式深度传感器的最佳场景,室外场景更接近于双目系统的最佳场景,但是采用室内场景与室外场景的划分不够精细。本示例性实施方式中,获取大量的样本图像后,根据样本图像对应的实际场景特点(如属于室内场景还是室外场景,场景中物体的距离远近、光照条件、纹理的稠密程度等)进行人工标注,得到样本图像属于主动式深度传感器的最佳场景或双目系统的最佳场景的标注数据,其中,可以将每张样本图像及其标注数据作为一组训练数据,也可以将每两张或以上样本图像(一般是具有双目或多目关系的两张或以上样本图像)及其标注数据作为一组训练数据,这与所构建的场景预测模型的输入通道数相关;然后利用训练数据训练得到场景预测模型,例如可以是卷积神经网络模型;在获取深度数据时,按照场景预测模型的输入通道数,在上述第一图像至第N图像中选取对应数量的输入图像(一般包括第二图像),输入至场景预测模型中,输出场景预测结果。
需要说明的是,本示例性实施方式采用场景预测结果中的概率值,包括预测待测对象属于主动式深度传感器的最佳场景的第一概率值,以及预测待测对象属于双目系统的最佳场景的第二概率值,第一概率值与第二概率值之和可以为1。进而,可以将第一概率值作为第一置信度,将第二概率值作为第二置信度。
在一种实施方式中,还可以利用场景预测结果中的第一概率值与第二概率值对上述分别计算的第一置信度与第二置信度进行优化。举例来说,根据公式(1)得到第一置信度,将第一置信度乘以第一概率值,得到优化后的第一置信度;根据三焦点张量得到第二置信度,将第二置信度乘以第二概率值,得到优化后的第二置信度。从而结合了不同方面的信息,提高了第一置信度与第二置信度的准确性。
在一种实施方式中,如果第一置信度与第二置信度的数值范围不统一,还可以进行归一化处理,使第一置信度与第二置信度处于相同的数值范围,一般为[0,1]范围内。
在一种实施方式中,如果仅计算了第一置信度与第二置信度中的一者,例如仅计算了第一置信度,则对第一置信度归一化后,可以按照第二置信度=1-第一置信度来计算对应的第二置信度。
在得到第一置信度与第二置信度后,可以将第一置信度作为主动式深度信息的权重,第二置信度作为双目深度信息的权重,对主动式深度信息与双目深度信息进行加权融合,得到目标深度信息。
在一种实施方式中,可以以深度图像来表示深度信息。具体地,主动式深度信息可以是主动式深度图像,双目深度信息可以是双目深度图像,目标信息可以是目标深度图像。上述第二置信度包括双目深度图像的低置信度区域掩模,用于定位双目深度图像中的低置信度区域。上述根据第一置信度与第二置信度中的至少一者,将主动式深度信息与双目深度信息进行融合,得到目标深度信息,可以包括:
根据低置信度区域掩模,将双目深度图像中的低置信度区域替换为主动式深度图像中的对应区域,得到目标深度图像。
其中,低置信度区域可以是双目深度图像中第二置信度低于置信度阈值的区域。置信度阈值可以根据经验或实际需求设定,例如为0.3、0.5等。参考图7所示,低置信度区域掩膜中低置信度区域为1,其他区域为0。融合主动式深度图像与双目深度图像时,可以将双目深度图像与低置信度区域掩膜的反掩膜相乘,将主动式深度图像与低置信度区域掩膜相乘,再将两部分相乘的结果相加,相当于将双目深度图像中的高置信度区域与主动式深度图像中的互补区域叠加,得到目标深度图像,从而保留了主动式深度图像与双目深度图像中置信度较高的区域,提高目标深度图像的准确度。
应当理解,在实际处理中,还可以采用高置信度区域掩模,高置信度区域可以是双目深度图像中第二置信度不低于置信度阈值的区域,高置信度区域掩模可以是上述低置信度区域掩模的反掩膜,则将双目深度图像与高置信度区域掩膜相乘,将主动式深度图像与高置信度区域掩膜的反掩膜相乘,再将两部分相乘的结果相加,得到目标深度图像。
通过融合主动式深度信息与双目深度信息,可以结合主动式深度传感器与相机系统检测深度的优势,填补主动式深度信息中由于待测对象的材质反射率、多径干扰效应所导致的深度空洞或信息缺失,填补双目深度信息中由于遮挡所导致的深度断层处的深度空洞或信息缺失,同时改善主动式深度信息与双目深度信息中可信程度较低的深度值,提高深度检测的准确性,得到更加准确、可靠的目标深度信息。从深度值检测范围、适用场景上进行了扩展,使方案具有更高的实用性。
在一种实施方式中,还可以对目标深度信息进行滤波处理,例如可以采用BF(Bilateral Filter,双边滤波),GF(Guided Filtering,引导滤波),FBS(Filter BankSummation,滤波器组求和)等保边滤波算法,在实现深度信息平滑处理的同时,可以保留待测对象中的边缘信息。
继续参考图3,在步骤S340中,将上述N张图像中的第一图像、第二图像与目标深度信息形成一组深度数据。
由此,可以得到基线长度为目标长度的一组深度数据,包括一组双目图像以及对应的目标深度信息。其中,将第一图像与第二图像作为训练输入数据,将目标深度信息作为标注数据,可用于训练深度估计的机器学习模型。
在一种实施方式中,还可以将第一相机与第二相机间的标定参数添加至上述深度数据中,使得深度数据的信息更加全面。
图8示出了深度数据获取方法的流程示意图,其中主动式深度传感器为TOF传感器。该方法流程包括:
步骤S801,调节第一相机的位置,使第一相机与第二相机的基线长度为目标长度;
步骤S802,对TOF传感器与第二相机进行标定,得到第一标定参数,对每个相机分别与第二相机进行标定,得到第二标定参数;
步骤S803,通过TOF传感器采集待测对象的TOF深度图像,并输出对应的第一置信度,通过N个相机采集待测对象的N张图像;
步骤S804,对TOF深度图像进行预处理,包括深度补全、剔除飞行像素、滤波等;
步骤S805,基于上述第一标定参数,将TOF深度图像投影至第二相机的坐标系;
步骤S806,基于上述第二标定参数,对上述N张图像中的多组双目图像进行立体匹配,得到多张双目深度图像;
步骤S807,基于第三相机至第N相机与第二相机的基线长度以及目标长度,对上述多张双目深度图像进行加权融合,得到一张双目深度图像;
步骤S808,基于第二图像至第N图像中的三张图像间的三焦点张量,计算双目深度图像对应的第二置信度;
步骤S809,从上述N张图像中选取一张或多张图像,对其进行待测对象的场景预测,得到第一概率值与第二概率值;
步骤S810,利用第一概率值与第二概率值,对第一置信度与第二置信度进行优化;
步骤S811,基于上述优化后的第一置信度与第二置信度,对TOF深度图像与双目深度图像进行融合,得到目标深度图像;
步骤S812,将第一图像、第二图像、目标深度图像,以及第一相机与第二相机的标定参数,形成一组深度数据进行输出。
本公开的示例性实施方式还提供一种深度数据获取装置。参考图9所示,该深度数据获取装置900可以包括:
数据获取模块910,被配置为获取由主动式深度传感器采集的待测对象的主动式深度信息,以及由N个相机采集的待测对象的N张图像;N个相机沿一条基线轴设置,其中的第一相机沿基线轴可滑动,第二相机至第N相机固定于基线轴上,第一相机与第二相机的基线长度为目标长度,N为不小于4的正整数;
立体匹配模块920,被配置为对上述N张图像中的第二图像至第N图像进行立体匹配,得到N-2组双目深度信息,第二图像至第N图像为第二相机至第N相机分别采集的图像;
深度信息融合模块930,被配置为将主动式深度信息与双目深度信息进行融合,得到目标深度信息;
深度数据输出模块940,被配置为将上述N张图像中的第一图像、第二图像与目标深度信息形成一组深度数据。
在一种实施方式中,数据获取模块910,还被配置为:
基于主动式深度传感器与第二相机间的第一标定参数,将主动式深度信息投影至第二相机的坐标系。
在一种实施方式中,立体匹配模块920,被配置为:
基于第二相机至第N相机间的第二标定参数,对第二图像至第N图像进行立体匹配,得到N-2张双目视差图;
根据每张双目视差图确定对应的一组双目深度信息。
在一种实施方式中,深度信息融合模块930,被配置为:
根据第一置信度与第二置信度中的至少一者,将主动式深度信息与双目深度信息进行融合,得到目标深度信息。
第一置信度为主动式深度信息对应的置信度,第二置信度为双目深度信息对应的置信度。
在一种实施方式中,深度信息融合模块930,还被配置为:
基于第二图像至第N图像中的三张图像间的三焦点张量,确定第二置信度。
在一种实施方式中,深度信息融合模块930,被配置为:
基于第二相机与第E相机间的第二标定参数,以及第二相机与第F相机间的第二标定参数,确定第二图像、第E图像、第F图像间的三焦点张量;E和F为[3,N]内的任意两个不同的正整数;
对于第二图像的特征点或特征线,在第E图像与第F图像中获取与之匹配的特征点或特征线,得到三元组;
利用三焦点张量的几何约束,确定三元组与几何约束的偏离程度;
根据偏离程度确定三元组中第二图像的特征点或特征线在双目深度信息中的深度值对应的第二置信度。
在一种实施方式中,深度信息融合模块930,被配置为:
根据待测对象的场景预测结果,确定第一置信度与第二置信度。
在一种实施方式中,主动式深度信息包括主动式深度图像,双目深度信息包括双目深度图像,目标信息包括目标深度图像。
第二置信度包括双目深度图像的低置信度区域掩模,用于定位双目深度图像中的低置信度区域。
深度信息融合模块930,被配置为:
根据低置信度区域掩模,将双目深度图像中的低置信度区域替换为主动式深度图像中的对应区域,得到目标深度图像。
在一种实施方式中,立体匹配模块920,还被配置为:
在得到上述N-2组双目深度信息后,基于第三相机至第N相机与第二相机的基线长度以及目标长度,将N-2组双目深度信息融合为一组双目深度信息。
上述装置中各部分的细节在方法部分实施方式中已经详细说明,因而不再赘述。
本公开的示例性实施方式还提供了一种计算机可读存储介质,可以实现为一种程序产品的形式,其包括程序代码,当程序产品在电子设备上运行时,程序代码用于使电子设备执行本说明书上述“示例性方法”部分中描述的根据本公开各种示例性实施方式的步骤。在一种实施方式中,该程序产品可以实现为便携式紧凑盘只读存储器(CD-ROM)并包括程序代码,并可以在电子设备,例如个人电脑上运行。然而,本公开的程序产品不限于此,在本文件中,可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。
程序产品可以采用一个或多个可读介质的任意组合。可读介质可以是可读信号介质或者可读存储介质。可读存储介质例如可以为但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式盘、硬盘、随机存取存储器(RAM)、只读存储器(ROM)、可擦式可编程只读存储器(EPROM或闪存)、光纤、便携式紧凑盘只读存储器(CD-ROM)、光存储器件、磁存储器件、或者上述的任意合适的组合。
计算机可读信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了可读程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。可读信号介质还可以是可读存储介质以外的任何可读介质,该可读介质可以发送、传播或者传输用于由指令执行系统、装置或者器件使用或者与其结合使用的程序。
可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于无线、有线、光缆、RF等等,或者上述的任意合适的组合。
可以以一种或多种程序设计语言的任意组合来编写用于执行本公开操作的程序代码,程序设计语言包括面向对象的程序设计语言—诸如Java、C++等,还包括常规的过程式程序设计语言—诸如“C”语言或类似的程序设计语言。程序代码可以完全地在用户计算设备上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户计算设备上部分在远程计算设备上执行、或者完全在远程计算设备或服务器上执行。在涉及远程计算设备的情形中,远程计算设备可以通过任意种类的网络,包括局域网(LAN)或广域网(WAN),连接到用户计算设备,或者,可以连接到外部计算设备(例如利用因特网服务提供商来通过因特网连接)。
应当注意,尽管在上文详细描述中提及了用于动作执行的设备的若干模块或者单元,但是这种划分并非强制性的。实际上,根据本公开的示例性实施方式,上文描述的两个或更多模块或者单元的特征和功能可以在一个模块或者单元中具体化。反之,上文描述的一个模块或者单元的特征和功能可以进一步划分为由多个模块或者单元来具体化。
所属技术领域的技术人员能够理解,本公开的各个方面可以实现为系统、方法或程序产品。因此,本公开的各个方面可以具体实现为以下形式,即:完全的硬件实施方式、完全的软件实施方式(包括固件、微代码等),或硬件和软件方面结合的实施方式,这里可以统称为“电路”、“模块”或“系统”。本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其他实施方式。本申请旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施方式仅被视为示例性的,本公开的真正范围和精神由权利要求指出。
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限定。
- 深度数据获取方法、装置、存储介质与电子设备
- 深度数据获取方法、装置及可读存储介质