一种基于Spring框架的大数据日志分析的方法和系统
文献发布时间:2023-06-19 12:18:04
技术领域
本发明涉及一种基于Spring框架的大数据日志分析的方法和系统,属于信息安全技术领域。
背景技术
在如今复杂多样的企业WEB服务中,不仅集成了Spring MVC、Spring Boot、SpringCloud各种服务框架,同时记录日志方式也是多种多样、千差万别。不仅缺失了日志的归档、管理的功能,而且对各个WEB服务无法做出统一的告警管理、风险预警;无论是开发人员还是运维人员都无法准确的定位服务、服务器上面出现的种种问题,也没有高效搜索日志内容从而快速定位问题的方式;同时无法提前预知和及时处理问题,极大的影响的客户的感知体验,因此需要一个集中式、独立的、搜集管理各个服务和服务器上的日志信息,集中管理、及时预警,并提供良好的UI界面进行数据展示,处理分析,同时对客户行为进行数据挖掘,提炼出更大的商业价值。
发明内容
本发明的主要目的是为了解决现有技术的不足,而提供一种基于Spring框架的大数据日志分析的方法和系统。
本发明的目的可以通过采用如下技术方案达到:
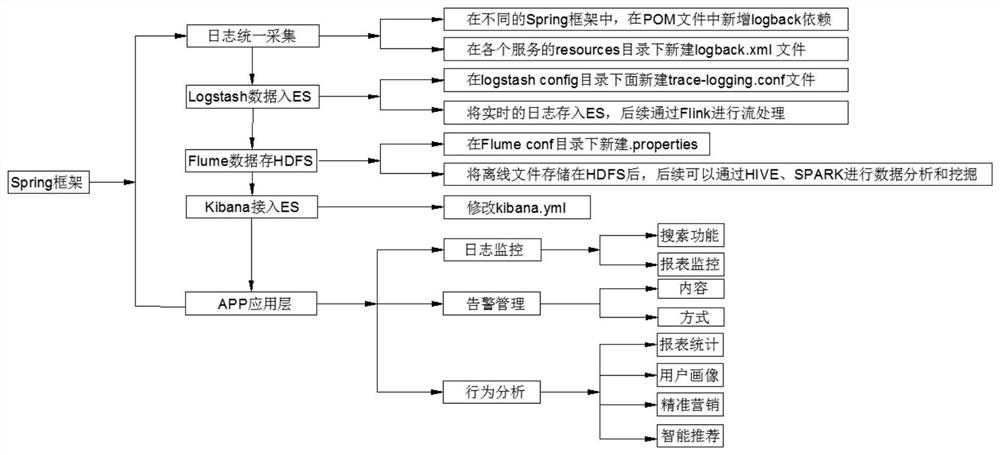
一种基于Spring框架的大数据日志分析的方法,该方法包括如下步骤:
步骤1:日志统一采集,在不同的Spring框架中,在POM文件中新增logback依赖,同时在各个服务的resources目录下新建logback.xml文件;
步骤2:Logstash数据入ES,在logstash config目录下面新建trace-logging.conf文件,将实时的日志存入ES,后续通过Flink进行流处理;
步骤3:Flume数据存HDFS,在Flume conf目录下新建properties文件,将离线文件存储在HDFS后,后续可以通过HIVE、SPARK进行数据分析和挖掘;
步骤4:Kibana接入ES,修改kibana.yml,将离线实时数据已全接入大数据平台中。
优选的,在步骤1中,所述新增logback依赖如下:
优选的,在步骤1中,在各个服务的resources目录下新建logback.xml文件如下:
优选的,在步骤2中,新建trace-logging.conf文件如下:
优选的,所述9601是logstash接收数据的端口,在logback必须配置此端口,codec=>json_lines是一个json解析器,接收json的数据,需要安装logstash-codec-json_lines插件;ouput elasticsearch指向我们安装的集群的ip地址和端口;stdout会打印收到的消息。
优选的,和系统,所述Flume数据采集架构为Web Server.依次经过到Source、Channel、Sink和HDFS。
优选的,在步骤3中,Flume conf目录下新建.properties文件如下:
#agent1 name
agent1.sources source1
agent1.sinks=sink1
agent1.channels=channel1
#Spooling Directory
#set source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir=/usr/app/flumelog/dir/logdfs
agent1.sources.source1.channe ls:channel1
agent1.sources.source1.fileHeader=false
agent1.sources.source1.interceptors=i1.
agent1.sources.source1.interceptors.i1.type=timestamp
#set sink1
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path=/user/yuhui/flume
agent1.sinks.sink1.hdfs.fileType DataStream
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.rollInterval=1
agent1.sinks.sink1.channel-channel1
agent1.sinks.sink1.hdfs.filePrefix%Y-%m-%d
#set channel1
agent1.channels.channel1.type file
agent1.channe ls.channel1.checkpointDir-/usr/app/flume log/dir/logdfstmp/point
agent1.channe ls.channe 11.dataDirs-/usr/app/f lume log/dir/logdfstmp
优选的,在步骤4中,修改kibana.yml如下:
server.port:5601##服务端口
server.host:"0.0.0.0"
elasticsearch.hosts:["http://11.1.5.69:9200","http://11.1.5.70:9200","http://11.1.5.71:9200"]
一种基于Spring框架的大数据日志分析的方法的系统,所述系统包括日志监控、告警管理和行为分析
日志监控包括搜索功能和报表监控
搜索功能:通过设置时间、服务名称和日志层次维度筛选;
报表监控:通过对错误日志的监控能够及时通知项目运维人员,通过对服务、接口调用次数,接口响应时间维度进行监控;
告警管理,
当WEB服务产生错误日志或者某个服务在某段时间发生不正常的激增时,告警管理系统能够通过邮件、短信、钉钉或微信的方式推送维人员;
行为分析
通过接口的调用频率可以统计出PV/UV,DAU/MAU,新增用户数,访问时长,GMV重用指标;
通过用户的点击行为作为行为特征,同时提取用户的年龄、性别、住址、爱好属性特征建立用户画像,再结合机器学习对用户进行精准营销和智能推荐。
优选的,所述报表统计的数据包括:PV/UV、GMV、DAU/MAU、点击数/访问时长和新增用户数。
本发明的有益技术效果:按照本发明的基于Spring框架的大数据日志分析的方法和系统,针对不同的Spring框架的内部WEB服务提供了统一的管理平台;从离线和实时的维度对数据进行分析和挖掘,保证了数据的准确性和一致性;提供了从时间、服务名称、日志层次,关键字搜索功能,使开发、运维人员快速定位生产环境的问题;提供了风险预警和告警监控的功能,通过邮件、短信、钉钉、微信灵活多样的方式推送维人员;对用户的行为数据做进一步分析和挖掘,为运营人员和数据分析师做运营决策分析。
附图说明
图1为按照本发明的基于Spring框架的大数据日志分析的方法和系统的一优选实施例的Spring整体框架示意图。
图2为按照本发明的基于Spring框架的大数据日志分析的方法和系统的一优选实施例的Flume数据采集架构示意图;
图3为按照本发明的基于Spring框架的大数据日志分析的方法和系统的一优选实施例的日志监控框架图;
图4为按照本发明的基于Spring框架的大数据日志分析的方法和系统的一优选实施例的告警管理框架图;
图5为按照本发明的基于Spring框架的大数据日志分析的方法和系统的行为分析框架图;
图6为按照本发明的基于Spring框架的大数据日志分析的方法和系统的系统框架图。
具体实施方式
为使本领域技术人员更加清楚和明确本发明的技术方案,下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
如图1-图5所示,本实施例提供的基于Spring框架的大数据日志分析的方法和系统,一种基于Spring框架的大数据日志分析的方法,该方法包括如下步骤:
步骤1:日志统一采集,在不同的Spring框架中,在POM文件中新增logback依赖,同时在各个服务的resources目录下新建logback.xml文件;
步骤2:Logstash数据入ES,在logstash config目录下面新建trace-logging.conf文件,将实时的日志存入ES,后续通过Flink进行流处理;
步骤3:Flume数据存HDFS,在Flume conf目录下新建properties文件,将离线文件存储在HDFS后,后续可以通过HIVE、SPARK进行数据分析和挖掘;
步骤4:Kibana接入ES,修改kibana.yml,将离线实时数据已全接入大数据平台中。
在步骤1中,新增logback依赖如下:
在步骤1中,在各个服务的resources目录下新建logback.xml文件如下:
<?xml version=""1.0"encoding="UTF-8"?>
<!--设置变量,下面有用到,含义是日志保存路径-->
<!--输出到控制台-->
<!--级别过滤-->
<!--日志输出格式-->
<!--输出到文件--> <!--设置日志隔离级别--> <!--设置具体包的隔离级别--> 在步骤2中,新建trace-logging.conf文件如下: input{ tcp{ port=>9601 codec=>json_lines } output{ action=>"index" hosts=>["11.1.5.69:8088","11.1.5.70:8088","11.1.5.71:8088"]#ES集群的ip地址和端口 index=>"%{[appName]}-%{+YYYY.MM.dd}"#用一个项目名称来做索引 document_type=>"applog” } stdout{codec=>rubydebug} } 9601是logstash接收数据的端口,在logback必须配置此端口,codec=>json_lines是一个json解析器,接收json的数据,需要安装logstash-codec-json_lines插件;ouput elasticsearch指向我们安装的集群的ip地址和端口;stdout会打印收到的消息。 和系统,Flume数据采集架构为Web Server.依次经过到Source、Channel、Sink和HDFS。 在步骤3中,Flume conf目录下新建.properties文件如下: #agent1 name agent1.sources source1 agent1.sinks=sink1 agent1.channels=channel1 #Spooling Directory #set source1 agent1.sources.source1.type=spooldir agent1.sources.source1.spoolDir=/usr/app/flumelog/dir/logdfs agent1.sources.source1.channe ls:channel1 agent1.sources.source1.fileHeader=false agent1.sources.source1.interceptors=i1. agent1.sources.source1.interceptors.i1.type=timestamp #set sink1 agent1.sinks.sink1.type=hdfs agent1.sinks.sink1.hdfs.path=/user/yuhui/flume agent1.sinks.sink1.hdfs.fileType DataStream agent1.sinks.sink1.hdfs.writeFormat=TEXT agent1.sinks.sink1.hdfs.rollInterval=1 agent1.sinks.sink1.channel-channel1 agent1.sinks.sink1.hdfs.filePrefix%Y-%m-%d #set channel1 agent1.channels.channel1.type file agent1.channe ls.channel1.checkpointDir-/usr/app/flume log/dir/logdfstmp/point agent1.channe ls.channe 11.dataDirs-/usr/app/f lume log/dir/logdfstmp 在步骤4中,修改kibana.yml如下: server.port:5601##服务端口 server.host:"0.0.0.0" elasticsearch.hosts:["http://11.1.5.69:9200","http://11.1.5.70:9200","http://11.1.5.71:9200"] 一种基于Spring框架的大数据日志分析的方法的系统,系统包括日志监控、告警管理和行为分析 日志监控包括搜索功能和报表监控 搜索功能:通过设置时间、服务名称、日志层次维度筛选,关键字搜索使运维和开发人员能够快速分析、定位生产环境的问题; 报表监控:通过对错误日志的监控能够及时通知项目运维人员,通过对服务、接口调用次数,接口响应时间维度进行监控,能够提升用户体验,也为后续的扩容、性能优化提供参考; 告警管理, 当WEB服务产生错误日志或者某个服务在某段时间发生不正常的激增时,告警管理系统能够通过邮件、短信、钉钉、微信灵活多样的方式推送维人员,运维人员不仅能及时的发现问题,更能够提前预知问题的发生,及时的扩容; 行为分析 通过接口的调用频率可以统计出PV/UV,DAU/MAU,新增用户数,访问时长,GMV重用指标,为运营人员和数据分析师做运营决策; 通过用户的点击行为作为行为特征,同时提取用户的年龄、性别、住址、爱好属性特征建立用户画像,再结合机器学习对用户进行精准营销和智能推荐。报表统计的数据包括:PV/UV、GMV、DAU/MAU、点击数/访问时长和新增用户数。 综上所述,在本实施例中,按照本实施例的基于Spring框架的大数据日志分析的方法和系统,本实施例提供的基于Spring框架的大数据日志分析的方法和系统,针对不同的Spring框架的内部WEB服务提供了统一的管理平台;从离线和实时的维度对数据进行分析和挖掘,保证了数据的准确性和一致性;提供了从时间、服务名称、日志层次,关键字搜索功能,使开发、运维人员快速定位生产环境的问题;提供了风险预警和告警监控的功能,通过邮件、短信、钉钉、微信灵活多样的方式推送维人员;对用户的行为数据做进一步分析和挖掘,为运营人员和数据分析师做运营决策分析。 以上所述,仅为本发明进一步的实施例,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明所公开的范围内,根据本发明的技术方案及其构思加以同替换或改变,都属于本发明的保护范围。
- 一种基于Spring框架的大数据日志分析的方法和系统
- 基于大数据日志分析的异常检测方法、系统、设备及介质