一种数据处理方法、装置、设备及存储介质
文献发布时间:2023-06-19 12:18:04
技术领域
本发明涉及计算机应用技术领域,特别是涉及一种数据处理方法、装置、设备及存储介质。
背景技术
随着大数据时代的到来,传统的数据存储和分析工具(典型代表MySQL技术体系)已经很难满足企业分析业务需求了。但是,传统的数据存储和分析工具也有着大数据领域工具不具备的特性,比如,使用范围的广泛性,保持数据的一致性(事务处理),数据更新高效性等等。因此,为了满足分析业务需求,一般都需要传统数据存储系统和大数据存储平台两者的结合。但是这两种模式下的数据天然的存在着割裂的情况,故如何将传统数据存储系统中的同步至大数据存储平台,是传统数据存储系统和大数据存储平台结合的重要内容也是难点内容。
发明内容
本发明实施例的目的在于提供一种数据处理方法、装置、设备及存储介质,以实现将传统数据存储系统中的同步至大数据存储平台。具体技术方案如下:
在本发明实施的第一方面,首先提供了一种数据处理方法,包括:
通过流处理框架Flink,读取传统数据存储系统中的存量数据,所述存量数据包括当前时刻所述传统数据存储系统中已经存在的数据;
将所述存量数据写入大数据存储组件,所述大数据存储组件为大数据存储平台中的存储组件;
获取所述传统数据存储系统中的增量数据,所述增量数据为针对所述存量数据发生变化的数据;
将所述增量数据发送至消息系统Kafka;
通过Flink,将Kafka中的数据写入所述大数据存储组件。
可选的,所述传统数据存储系统为关系型数据库管理系统MySQL;所述大数据存储组件为分布式文件系统中的大数据存储介质Hive。
可选的,所述获取所述传统数据存储系统中的增量数据,包括:
采集所述传统数据存储系统中的二进制日志Binary Log,所述Binary Log用于记录数据库MySQL的变化情况;
解析所述Binary Log得到所述增量数据。
可选的,所述采集所述传统数据存储系统中的二进制日志Binary Log,包括:
通过基于MySQL二进制的高性能数据同步系统Canal,向MySQL Master服务器发送dump请求,以使所述MySQL Master收到所述dump请求后,向所述Canal推送所述BinaryLog;
所述解析所述Binary Log得到所述增量数据,包括:
解析所述Binary Log,得到FlatMessage格式的数据。
可选的,所述通过流处理框架Flink,读取传统数据存储系统中的存量数据,包括:
通过Flink的MySQL Connector组件连接所述MySQL;
读取所述MySQL中的存量数据;
所述通过Flink,将Kafka中的数据写入所述大数据存储组件,包括:
通过Flink的Kafka Connector组件连接所述Kafka;
读取所述Kafka中的数据;
将读取的所述Kafka中的数据写入Hive中。
可选的,所述读取所述MySQL中的存量数据,包括:
获取第一配置信息,所述第一配置信息用于配置数据过滤规则;
通过Flink,结合所述第一配置信息,读取所述MySQL中满足所述第一配置信息的存量数据;
所述读取所述Kafka中的数据,包括:
获取第二配置信息,所述第二配置信息用于配置数据过滤规则;
通过Flink,结合所述第二配置信息,读取所述Kafka中满足所述第二配置信息的数据。
可选的,在所述通过Flink,将Kafka中的数据写入所述大数据存储组件之后,所述方法还包括:
通过预设分析算法,针对写入所述大数据存储组件中的所述存量数据和所述增量数据进行分析。
在本发明实施的第二方面,还提供了一种数据处理装置,包括:
读取模块,用于通过流处理框架Flink,读取传统数据存储系统中的存量数据,所述存量数据包括当前时刻所述传统数据存储系统中已经存在的数据;
第一写入模块,用于将所述存量数据写入大数据存储组件,所述大数据存储组件为大数据存储平台中的存储组件;
获取模块,用于获取所述传统数据存储系统中的增量数据,所述增量数据为针对所述存量数据发生变化的数据;
发送模块,用于将所述增量数据发送至消息系统Kafka;
第二写入模块,用于通过Flink,将Kafka中的数据写入所述大数据存储组件。
可选的,所述传统数据存储系统为关系型数据库管理系统MySQL;所述大数据存储组件为分布式文件系统中的大数据存储介质Hive。
可选的,所述获取模块,具体用于采集所述传统数据存储系统中的二进制日志Binary Log,所述Binary Log用于记录MySQL数据库的变化情况;解析所述Binary Log得到所述增量数据。
可选的,所述获取模块,具体用于通过基于MySQL二进制的高性能数据同步系统Canal,向MySQL Master服务器发送dump请求,以使所述MySQL Master收到所述dump请求后,向所述Canal推送所述Binary Log;解析所述Binary Log,得到FlatMessage格式的数据。
可选的,所述读取模块,具体用于通过Flink的MySQL Connector组件连接所述MySQL;读取所述MySQL中的存量数据;
所述第二写入模块,具体用于通过Flink的Kafka Connector组件连接所述Kafka;读取所述Kafka中的数据;将读取的所述Kafka中的数据写入Hive中。
可选的,所述读取模块,具体用于获取第一配置信息,所述第一配置信息用于配置数据过滤规则;通过Flink,结合所述第一配置信息,读取所述MySQL中满足所述第一配置信息的存量数据;
所述第二写入模块,具体用于获取第二配置信息,所述第二配置信息用于配置数据过滤规则;通过Flink,结合所述第二配置信息,读取所述Kafka中满足所述第二配置信息的数据。
可选的,所述装置还包括:
分析模块,用于通过预设分析算法,针对写入所述大数据存储组件中的所述存量数据和所述增量数据进行分析。
在本发明实施的又一方面,还提供了一种数据处理设备,包括处理器、通信接口、存储器和通信总线,其中,处理器,通信接口,存储器通过通信总线完成相互间的通信;
存储器,用于存放计算机程序;
处理器,用于执行存储器上所存放的程序时,实现第一方面所述的方法步骤。
在本发明实施的又一方面,还提供了一种计算机可读存储介质,所述计算机可读存储介质内存储有计算机程序,所述计算机程序被处理器执行时实现第一方面所述的方法步骤。
在本发明实施的又一方面,还提供了一种包含指令的计算机程序产品,当其在计算机上运行时,使得计算机执行上述第一方面所述的方法步骤。
本发明实施例提供的数据处理方法、装置、设备及存储介质,通过流处理框架Flink,读取传统数据存储系统中的存量数据,存量数据包括当前时刻传统数据存储系统中已经存在的数据;将存量数据写入大数据存储组件,大数据存储组件为大数据存储平台中的存储组件;获取传统数据存储系统中的增量数据,增量数据为针对存量数据发生变化的数据;将增量数据发送至消息系统Kafka;通过Flink,将Kafka中的数据写入大数据存储组件。如此,可以将传统数据存储系统中的存量数据同步至大数据存储组件,并针对传统数据存储系统中数据的变化,将传统数据存储系统中的增量数据同步至大数据存储组件,能够实现将传统数据存储系统中的同步至大数据存储平台。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。
图1为本发明实施例中数据处理方法的一种流程图;
图2为本发明实施例中获取传统数据存储系统中的增量数据的流程图;
图3为本发明实施例中通过流处理框架Flink,读取传统数据存储系统中的存量数据的流程图;
图4为本发明实施例中通过Flink,将Kafka中的数据写入大数据存储组件的流程图;
图5为本发明实施例中数据处理方法的另一种流程图;
图6为本发明实施例提供的数据处理方法的应用示意图;
图7为本发明实施例中数据处理装置的一种结构示意图;
图8为本发明实施例中数据处理装置的另一种结构示意图;
图9为本发明实施例中数据处理设备的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行描述。
为了满足分析业务需求,一般都需要传统数据存储系统和大数据存储平台两者的结合,以共同作用发现和挖掘数据的价值,利用成熟的大数据技术分析挖掘数据价值,指导企业的智能运营和战略决策,提升企业的核心竞争力等等。
为了满足分析业务需求,如何将传统数据存储系统中的同步至大数据存储平台,是传统数据存储系统和大数据存储平台结合的重要内容也是难点内容。
例如,传统数据存储系统和大数据存储平台这两种模式下的数据天然的存在着割裂的情况。具体地,业务上数据存储和处理方式都存在割裂情况,具体体现举例如下:每天的订单数据量在50G(MySQL存储),那么一个月的数据量就是30*50G=1500G(约等于1.46T),一年的数据量就是12*30*50G=18000G(约17.57T),此时的数据已经超过MySQL存储数据的极限了,业务上的做法是分库分表,最新的表只存储最近10天的数据,这样MySQL能够快速响应订单的各种操作。但是数据分析时要分析最近一年的订单数据,此时如果只是从MySQL存储入手的话就无法分析了,因为数据分散在多个库和表中,而且数据量大大超出了硬件机器的内存了这样的分析需求无法满足。
可以将传统数据存储系统中的同步至大数据存储平台以共同作用发现和挖掘数据的价值,利用成熟的大数据技术分析挖掘数据价值,指导企业的智能运营和战略决策,提升企业的核心竞争力,等等。
本发明实施例提供的数据处理方法可以将传统数据存储系统中的存量数据同步至大数据存储组件,并针对传统数据存储系统中数据的变化,将传统数据存储系统中的增量数据同步至大数据存储组件,能够实现将传统数据存储系统中的同步至大数据存储平台。
可以应用在不同产品线需要数据同步的场景中,在数据分析和挖掘中丰富数据来源,增加数据分析维度,整合挖掘不同存储介质数据的最大价值。
下面对本发明实施例提供的数据处理方法进行详细说明。
本发明实施例提供的数据处理方法可以由电子设备,如数据处理设备执行,电子设备可以包括服务器、终端等等。
本发明实施例提供了一种数据处理方法,可以包括:
通过流处理框架Flink,读取传统数据存储系统中的存量数据,存量数据包括当前时刻传统数据存储系统中已经存在的数据;
将存量数据写入大数据存储组件,大数据存储组件为大数据存储平台中的存储组件;
获取传统数据存储系统中的增量数据,增量数据为针对存量数据发生变化的数据;
将增量数据发送至消息系统Kafka;
通过Flink,将Kafka中的数据写入大数据存储组件。
本发明实施例中,可以将传统数据存储系统中的存量数据同步至大数据存储组件,并针对传统数据存储系统中数据的变化,将传统数据存储系统中的增量数据同步至大数据存储组件,能够实现将传统数据存储系统中的同步至大数据存储平台。
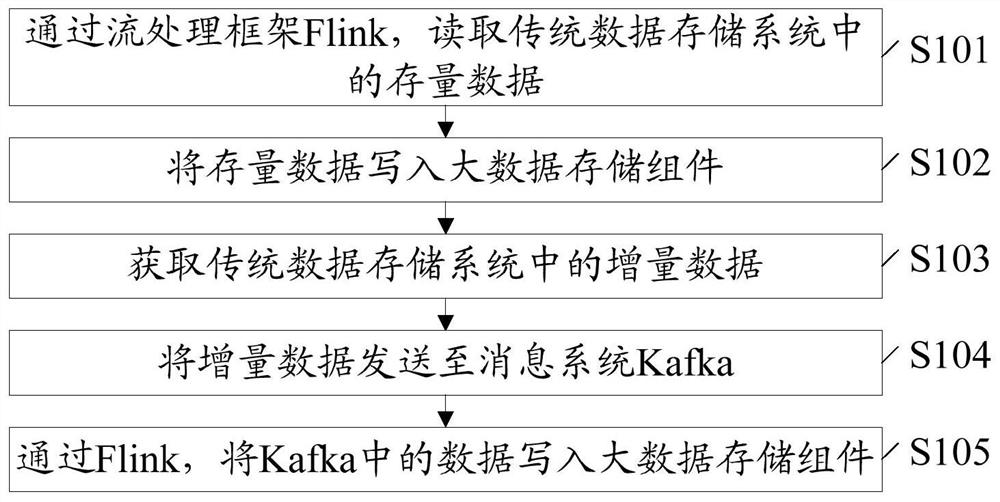
图1为本发明实施例中数据处理方法的流程图。参见图1,本发明实施例提供的数据处理方法,可以包括:
S101,通过流处理框架Flink,读取传统数据存储系统中的存量数据。
存量数据包括当前时刻传统数据存储系统中已经存在的数据。
Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。
传统数据存储系统可以理解为利用传统的数据存储和分析工具的数据存储系统。例如,关系型数据库管理系统(MySQL),等等。
S102,将存量数据写入大数据存储组件。
大数据存储组件为大数据存储平台中的存储组件。
大数据存储平台可以理解为利用大数据领域的数据存储和分析工具的平台。
大数据存储组件可以为Redis,ES等存储组件、分布式文件系统中的大数据存储介质Hive,等等。
在开始同步时,通过Flink读取传统数据存储系统中已经存在的数据,也即存量数据,先将存量数据同步至大数据存储组件。
S103,获取传统数据存储系统中的增量数据。
增量数据为针对存量数据发生变化的数据。
S104,将增量数据发送至消息系统Kafka。
可以在将上述存量数据同步至大数据存储组件后,实时监测传统数据存储系统中是否有数据变化,如新增数据、删除数据和/或变更原有数据等,当有数据变化时,则获取发生变化的数据,并将发生变化的数据发送至Kafka。
S105,通过Flink,将Kafka中的数据写入大数据存储组件。
可以利用Kafka的缓存功能先把数据缓存起来等待消费,再通过Flink消费Kafka中的数据,将Kafka中的数据写入大数据存储组件,即将Kafka中的数据同步至大数据存储组件。
如此,即完成将传统数据存储系统中的增量数据同步至大数据存储组件。
存量数据的同步是指同步开始时已经存在的数据进行同步,增量数据的同步是开始同步后的同步,只要针对存量数据有数据变化就同步。
本发明实施例中,可以将传统数据存储系统中的存量数据同步至大数据存储组件,并针对传统数据存储系统中数据的变化,将传统数据存储系统中的增量数据同步至大数据存储组件,能够实现将传统数据存储系统中的同步至大数据存储平台。
且本发明实施例中已存在的存量数据和实时的增量数据分开同步处理,减少程序之间的耦合性,可以提高数据处理过程的健壮性,进而能够保障数据的准确性。
一种可选的实施例中,传统数据存储系统为关系型数据库管理系统MySQL;大数据存储组件为分布式文件系统中的大数据存储介质Hive。
即本发明实施例提供的数据处理方法完成将MySQL中的数据同步至Hive,进而可以利用大数据技术分析挖掘数据价值,指导企业的智能运营和战略决策,提升企业的核心竞争力,等等。
在图1所示实施例的基础上,S103:获取传统数据存储系统中的增量数据,如图2所示,可以包括:
S1031,采集传统数据存储系统中的二进制日志Binary Log。
Binary Log用于记录数据库MySQL的变化情况。
Binary Log是二进制日志也可叫作变更日志(Update Log),是MySQL中非常重要的日志。主要用于记录数据库的变化情况,即SQL语句的DDL和DML语句,不包含数据记录查询操作,其中,DDL表示数据定义语言(CREATE,ALTER,DROP,DECLARE),DML表示数据操纵语言(SELECT,DELETE,UPDATE,INSERT)。
可以通过基于MySQL二进制的高性能数据同步系统(Canal),向MySQL Master服务器发送dump请求,以使MySQL Master收到dump请求后,向Canal推送Binary Log。
Canal中dump协议主要包含包含参数内容:binlogfilename:binlog文件名称;binlogPosition:在文件中的偏移量;SinkFunction:每解析出一条binlog日志的处理函数。
S1032,解析Binary Log得到增量数据。
可以解析Binary Log得到目标类型的数据,该目标类型根据实际业务需求确定。
一种可实现方式中,可以解析Binary Log,得到FlatMessage格式的数据。如,可以解析得到FlatMessage的JSON数据。
具体地,解析Binary Log的过程可以包括:通过connect函数获取链接;通过getWithoutAck函数获取数据,判断数据是否存在,如果数据存在,则解析封装成FlatMessage格式数据;如果不存在,则继续获取数据。
在图1所示实施例的基础上,S101:通过流处理框架Flink,读取传统数据存储系统中的存量数据,如图3所示,可以包括:
S1011,通过Flink的MySQL Connector组件连接MySQL。
S1012,读取MySQL中的存量数据。
MySQL Connector组件是Flink框架已提供的。
具体地,可以根据链接地址、用户名称和用户密码,通过DriverManager.getConnection(url,user,password)函数建立与MySQL的链接;同步数据的SQL语句;例如:select orderID,orderTime,isVip from order_table,即从表order_table中选择orderID、orderTime、isVip三个字段的数据。然后通过prepareStatement函数预处理SQL。使用Flink进行运行,同步数据。
一种可选的实施例中,可以获取第一配置信息,其中,第一配置信息用于配置数据过滤规则;通过Flink,结合第一配置信息,读取MySQL中满足第一配置信息的存量数据。
即可以理解结合配置信息进行数据处理,然后把结果数据写入到大数据存储介质Hive中。
第一配置信息可以包括待同步的数据的信息或者无需同步数据的信息,等等,如此,可以根据配置信息对数据进行过滤,得到待同步的数据,并将待同步的数据同步至Hive。
第一配置信息可以包括待同步数据的数据类型或或者无需同步数据的数据类型,数据类型可以根据实际业务需求确定,例如动漫业务的订单数据等等。
一种可实现方式中,可以从配置库中获取第一配置信息,将获取的第一配置信息存储在电子设备的内存中。其中,配置库可以是单独的MySQL库,即不同于待同步数据的MySQL,而专门用于存储配置信息。
Flink流式数据处理的时候结合配置信息,也即引入了规则配置策略,使数据能够根据配置规则动态的进行解析和过滤,提高了数据处理的灵活性。
在图1所示实施例的基础上,S105:通过Flink,将Kafka中的数据写入大数据存储组件,如图4所示,可以包括:
S1051,通过Flink的Kafka Connector组件连接Kafka。
Kafka Connector组件是Flink已有的。
S1052,读取Kafka中的数据。
可以获取第二配置信息,第二配置信息用于配置数据过滤规则;通过Flink,结合第二配置信息,读取Kafka中满足第二配置信息的数据。
第二配置信息类似于第一配置信息,参见第一配置信息的描述,这里不再赘述。
S1053,将读取的Kafka中的数据写入Hive中。
一种可实现方式中,将数据写入Hive的过程可以包括:创建HiveCatalog;注册到当前Flink的运行环境中;设置SQL方言是HIVE;为结果数据创建视图;创建hive表;插入SQL语句例如:insert into order_hive_table SELECT orderID,orderTime,isVip,DATE_FORMAT(ts,'yyyy-MM-dd'),DATE_FORMAT(ts,'HH'),DATE_FORMAT(ts,'mm')FROM order_mysql_table,执行SQL语句即可,该语句实现:查询MySQL表order_mysql_table中数据插入到Hive表order_hive_table中。
在图1所示实施例的基础上,在S105:通过Flink,将Kafka中的数据写入大数据存储组件之后,如图5所示,本发明实施例提供的数据处理方法还可以包括:
S106,通过预设分析算法,针对写入大数据存储组件中的存量数据和增量数据进行分析。
预设分析算法可以包括HQL是Hive SQL(Hive Structured Query Language)、TOP-N算法,分组排序算法等根据业务需要的算法。
结合HQL和相关算法(TOP-N算法,分组排序算法等算法)来分析和挖掘Hive中的数据价值,例如:用户在2019年10月1日充值的会员,在2020年10月1日自动送7日会员权益。此时可以通过同步到Hive的订单表进行查询在2019年10月1日充值的会员都有谁,订单包含如下信息:
1:订单号(orderID)
2:订购时间(orderTime)
3:订购金额(orderMoney)
4:是否会员(isVip)
5:订单来源(orderRaw)
6:用户ID(userID)
此时可以使用如下HQL进行查询
Select
userID
From订单表
Where orderTime=’2019-10-01’
Group by userID
此时获取到了用户的ID(userID)业务可以根据这些ID给各个用户添加7日的权益用户召回老会员,增加经离开的会员,再次购买的可能性,提高收入,从而让数据产生价值。
本发明实施例提供的数据处理方法,能够实现将传统数据存储系统中的同步至大数据存储平台,打通了传统数据分析和大数据分析数据割裂的壁垒,丰富了数据分析和挖掘的数据来源。
本发明提供了一个具体的实施例。图6为本发明实施例提供的数据处理方法的应用示意图。
针对已存在的全量数据(也即存量数据)使用Flink直接读取MySQL数据,然后Sink(插入)到Hive中做一次全量数据的同步。
针对实时的增量数据使用Canal采集和解析MySQL的Binary Log日志生成一条条FlatMessage的JSON格式数据,然后发送到大数据消息组件Kafka中,利用Kafka的缓存功能可以先把数据缓存起来等待消费,再通过Flink消费Kafka中的数据,并结合配置管理模块规则过滤,解析等操作后把数据写入到大数据组件Hive中,以此完成增量数据的同步。
最后,可以结合HQL和相关算法来分析和挖掘Hive中的数据价值,从而为企业的智能运营和战略决策提供数据支撑,等等。
本发明实施例提供的数据处理方法实现同步传统数据存储MySQL中的数据到大数据存储组件Hive中,其中,使用Canal技术结合Kafka数据缓存传输技术和Flink实时计算技术。
具体地,先通过Flink,读取MySQL中的存量数据,将存量数据同步至Hive。可以通过全量同步模块(包括Flink程序,即Flink Program)执行一次FullPuller。在存量数据的同步过程中可以结合配置管理模块对待同步的数据进行配置、过滤等,配置管理模块可以包括配置信息,配置信息可以部署在另外单独的MySQL(不同于待同步数据的MySQL,仅用于保存配置信息)中。
可以读取配置库中的配置信息,存储到内存中。建立Flink流式处理环境,通过Flink的MySQL Connector组件连接MySQL,进而批量读取MySQL中的存量数据,结合配置信息进行数据处理,然后把结果数据写入到大数据存储介质Hive中。
通过采集解析模块采集并解析MySQL中的Binary Log,基于Canal从Binary Log解析得到增量数据,将增量数据推送至Kafka,利用Kafka的缓存功能可以先把数据缓存起来等待消费,再通过Flink消费Kafka中的数据,具体地通过增量同步模块(包括FlinkProgram),也可以理解为通过Flink将增量数据同步至Hive。其中,在增量数据的同步过程中也可以结合配置管理模块对待同步的数据进行配置、过滤等。
可以读取配置库中的配置信息,存储到内存中。建立Flink流式处理环境,通过Flink的Kafka Connector组件连接Kafka进而读取Kafka中的实时数据,结合配置信息进行数据处理,然后把结果数据写入到大数据存储介质Hive中。
其中,基于Canal从Binary Log解析得到增量数据,将增量数据推送至Kafka,利用Kafka的缓存功能可以先把数据缓存起来等待消费,再通过Flink消费Kafka中的数据,即Canal模拟MySQL Slave的交互协议,伪装成一个MySQL的Slave向MySQL Master发送dump协议,MySQL Master收到Canal发送的dump请求后,开始推送Binary Log给Canal然后Canal解析Binary Log对象(原始是byte流),Canal把解析后的Binary Log以特定格式(FlatMessage)的消息发送到Kafka,从而完成MySQL存储数据的采集,解析和传输的过程。
MySQL Slave、MySQL Master是MySQL软件,能够写入的角色称之为Master,读取的角色称之为Slave,业务系统是向Master写入数据,为了减轻Master角色计算机的压力,读取数据都是从Slave读取,从而做到读写分离。本发明中Canal伪装成MySQL Slave发送dump协议命令,从Master同步数据到Canal。可以理解Canal的作用是实时从Master获取增量数据。
为了使得Canal模拟MySQL Slave的交互协议,可以进行配置操作如下:
在需要同步数据的传统存储MySQL Master服务上创建用于Canal数据同步的用户,并且赋予管理员权限,为后续Canal配置做准备。
下载安装Zookeeper并且启动服务,因为消息系统Kafka需要使用Zookeeper进行任务协调和元数据存储。下载安装Kafka并且启动服务,因为Canal采集和解析的数据会写入到Kafka中。下载安装Canal工具,修改instance.property和canal.property配置文件,进行如下配置:a.在文件instance.property中配置Zookeeper相关的地址和端口号以此来获取Kafka中的相关数据状态。b.在文件instance.property中配置需要同步的MySQL实例的地址,端口号,用户名,密码,以及要同步的表等等。c.在文件canal.property中配置Kafka的地址,topic,分区数,分区方式等等,然后启动Canal服务。
可以把MySQL中的数据实时同步到分布式文件系统Hadoop集群使用Hive进行存储和分析,因为分布式文件系统Hadoop集群能够关联成千上万的机器,协调千上万的机器对数据进行存储和计算。业务系统一般都是MySQL存储数据,好处是系统响应快,事务一致性,安全性高。分析一般是把业务系统上线后产生的数据都同步到分布式存储系统中可以长时间保存和大数据量的分析。
对应于上述实施例提供的数据处理方法,本发明实施例还提供了一种数据处理装置,如图7所示,可以包括:
读取模块701,用于通过流处理框架Flink,读取传统数据存储系统中的存量数据,存量数据包括当前时刻传统数据存储系统中已经存在的数据;
第一写入模块702,用于将存量数据写入大数据存储组件,大数据存储组件为大数据存储平台中的存储组件;
获取模块703,用于获取传统数据存储系统中的增量数据,增量数据为针对存量数据发生变化的数据;
发送模块704,用于将增量数据发送至消息系统Kafka;
第二写入模块705,用于通过Flink,将Kafka中的数据写入大数据存储组件。
可选的,传统数据存储系统为关系型数据库管理系统MySQL;大数据存储组件为分布式文件系统中的大数据存储介质Hive。
可选的,获取模块703,具体用于采集传统数据存储系统中的二进制日志BinaryLog,Binary Log用于记录数据库MySQL的变化情况;解析Binary Log得到增量数据。
可选的,获取模块703,具体用于通过基于MySQL二进制的高性能数据同步系统Canal,向MySQL Master服务器发送dump请求,以使MySQL Master收到dump请求后,向Canal推送Binary Log;解析Binary Log,得到FlatMessage格式的数据。
可选的,读取模块701,具体用于通过Flink的MySQL Connector组件连接MySQL;读取MySQL中的存量数据;
第二写入模块705,具体用于通过Flink的Kafka Connector组件连接Kafka;读取Kafka中的数据;将读取的Kafka中的数据写入Hive中。
可选的,读取模块701,具体用于获取第一配置信息,第一配置信息用于配置数据过滤规则;通过Flink,结合第一配置信息,读取MySQL中满足第一配置信息的存量数据;
第二写入模块705,具体用于获取第二配置信息,第二配置信息用于配置数据过滤规则;通过Flink,结合第二配置信息,读取Kafka中满足第二配置信息的数据。
可选的,如图8所示,该装置还包括:
分析模块706,用于通过预设分析算法,针对写入大数据存储组件中的存量数据和增量数据进行分析。
本发明实施例提供的数据处理装置是应用上述数据处理方法的装置,则上述数据处理方法的所有实施例均适用于该装置,且均能达到相同或相似的有益效果。
本发明实施例还提供了一种数据处理设备,如图9所示,包括处理器901、通信接口902、存储器903和通信总线904,其中,处理器901,通信接口902,存储器903通过通信总线904完成相互间的通信。
存储器903,用于存放计算机程序;
处理器901,用于执行存储器903上所存放的程序时,实现上述数据处理方法的方法步骤。
上述数据处理设备提到的通信总线可以是外设部件互连标准(PeripheralComponent Interconnect,简称PCI)总线或扩展工业标准结构(Extended IndustryStandard Architecture,简称EISA)总线等。该通信总线可以分为地址总线、数据总线、控制总线等。为便于表示,图中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
通信接口用于上述数据处理设备与其他设备之间的通信。
存储器可以包括随机存取存储器(Random Access Memory,简称RAM),也可以包括非易失性存储器(non-volatile memory),例如至少一个磁盘存储器。可选的,存储器还可以是至少一个位于远离前述处理器的存储装置。
上述的处理器可以是通用处理器,包括中央处理器(Central Processing Unit,简称CPU)、网络处理器(Network Processor,简称NP)等;还可以是数字信号处理器(Digital Signal Processor,简称DSP)、专用集成电路(Application SpecificIntegrated Circuit,简称ASIC)、现场可编程门阵列(Field-Programmable Gate Array,简称FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。
在本发明提供的又一实施例中,还提供了一种计算机可读存储介质,计算机可读存储介质内存储有计算机程序,计算机程序被处理器执行时实现上述数据处理方法的方法步骤。
在本发明提供的又一实施例中,还提供了一种包含指令的计算机程序产品,当其在计算机上运行时,使得计算机执行上述数据处理方法的方法步骤。
在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。所述计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行所述计算机程序指令时,全部或部分地产生按照本发明实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(DSL))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,DVD)、或者半导体介质(例如固态硬盘Solid State Disk(SSD))等。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
本说明书中的各个实施例均采用相关的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于装置、设备、计算机可读存储介质以及计算机程序产品实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
以上所述仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
- 一种物联网设备数据处理方法、装置、设备及存储介质
- 穿戴式设备及其数据处理方法、装置、设备、存储介质